Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. In Microsoft Fabric können Sie alle erforderlichen Aufgaben ausführen, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- oder Azure Synapse Analytics-Pipelines verwenden, um Daten aus Hive zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Von Bedeutung
Der Hive-Connector, Version 1.0, wird entfernt. Sie werden empfohlen, den Hive-Connector von Version 1.0 auf 2.0 zu aktualisieren.
Unterstützte Funktionen
Für den Hive-Connector werden die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | (1) (2) |
| Zuordnungsdatenfluss (Quelle/-) | ① |
| Lookup-Aktivität | (1) (2) |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Der Dienst bietet einen eingebauten Treiber, um die Verbindung zu ermöglichen, so dass Sie keinen Treiber manuell installieren müssen.
Der Connector unterstützt die Windows-Versionen in diesem Artikel.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in Amazon Virtual Private Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Hinweis
Version 2.0 wird mit der selbst gehosteten Integrationslaufzeit Version 5.54 oder höher unterstützt.
Erste Schritte
Zum Ausführen der Kopieraktivität mit einer Pipeline können Sie eines der folgenden Tools oder SDKs verwenden:
- Datenkopier-Werkzeug
- Azure-Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST-API
- Azure Resource Manager-Vorlage
Erstellen eines mit Hive verknüpften Dienstes über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen mit Hive verknüpften Dienst in der Azure-Portal-Benutzeroberfläche zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach „Hive“, und wählen Sie den Hive-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.



Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den Hive-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Der Hive-Connector unterstützt jetzt Version 2.0. Lesen Sie diesen Abschnitt , um die Hive-Connectorversion von Version 1.0 zu aktualisieren. Einzelheiten zur Eigenschaft finden Sie in den entsprechenden Abschnitten.
Version 2.0
Der verknüpfte Hive-Dienst unterstützt die folgenden Eigenschaften, wenn Version 2.0 angewendet wird:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die „type“-Eigenschaft muss auf Hive festgelegt werden. | Ja |
| version | Die von Ihnen angegebene Version. Der Wert ist 2.0. |
Ja |
| Gastgeber | IP-Adresse oder Hostname des Hive-Servers. | Ja |
| Hafen | Der TCP-Port, den der Hive-Server verwendet, um auf Clientverbindungen zu lauschen. Wenn Sie eine Verbindung mit Azure HDInsight herstellen, geben Sie „443“ als Port an. | Ja |
| serverType | Der Typ des Hive-Servers. Zulässiger Wert ist: HiveServer2 |
Nein |
| thriftTransportProtocol | Das auf der Thrift-Ebene zu verwendende Transportprotokoll. Zulässige Werte: Binary, SASL, HTTP |
Nein |
| Authentifizierungstyp | Die Authentifizierungsmethode für den Zugriff auf den Hive-Server. Zulässige Werte sind: Anonymous, UsernameAndPassword, WindowsAzureHDInsightService. Kerberos-Authentifizierung wird derzeit nicht unterstützt. |
Ja |
| Benutzername | Der Benutzername für den Zugriff auf den Hive-Server. | Nein |
| Kennwort | Das Kennwort für den Benutzer. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Nein |
| httpPath | Die Teil-URL, die dem Hive-Server entspricht. Für den Authentifizierungstyp „WindowsAzureHDInsightService“ lautet der Standardwert /hive2. |
Nein |
| SSL aktivieren | Gibt an, ob Verbindungen mit dem Server mit TLS verschlüsselt werden. Der Standardwert ist true. | Nein |
| Aktivierung der Serverzertifikatsvalidierung | Geben Sie an, ob die Ssl-Zertifikatüberprüfung auf dem Server aktiviert werden soll, wenn Sie eine Verbindung herstellen. Verwenden Sie immer den System Trust Store. Der Standardwert ist true. | Nein |
| Speicherreferenz | Ein Verweis auf den verknüpften Dienst des Speicherkontos, das für das Staging von Daten im Zuordnungsdatenfluss verwendet wird. Nur erforderlich, wenn im Zuordnungsdatenfluss der verknüpfte Hive-Dienst verwendet wird. | Nein |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Angabe erfolgt, wird die standardmäßige Azure Integration Runtime verwendet. Sie können die selbst gehostete Integrationslaufzeit verwenden und die Version sollte 5.54 oder höher sein. | Nein |
Beispiel:
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"version": "2.0",
"typeProperties": {
"host" : "<host>",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"serverType": "HiveServer2",
"thriftTransportProtocol": "HTTP",
"enableSsl": true,
"enableServerCertificateValidation": true
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Version 1.0
Die folgenden Eigenschaften werden für den verknüpften Hive-Dienst unterstützt, wenn Version 1.0 angewendet wird:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die „type“-Eigenschaft muss auf Hive festgelegt werden. | Ja |
| Gastgeber | IP-Adresse oder Hostname des Hive-Servers, bei mehreren Hosts durch „;“ getrennt (nur wenn „serviceDiscoveryMode“ aktiviert ist). | Ja |
| Hafen | Der TCP-Port, den der Hive-Server verwendet, um auf Clientverbindungen zu lauschen. Wenn Sie eine Verbindung mit Azure HDInsight herstellen, geben Sie „443“ als Port an. | Ja |
| serverType | Der Typ des Hive-Servers. Zulässige Werte: HiveServer1, HiveServer2, HiveThriftServer |
Nein |
| thriftTransportProtocol | Das auf der Thrift-Ebene zu verwendende Transportprotokoll. Zulässige Werte: Binary, SASL, HTTP |
Nein |
| Authentifizierungstyp | Die Authentifizierungsmethode für den Zugriff auf den Hive-Server. Zulässige Werte sind: Anonym, Benutzername, Benutzername und Kennwort, WindowsAzureHDInsightService. Kerberos-Authentifizierung wird derzeit nicht unterstützt. |
Ja |
| Dienstentdeckungsmodus | „true“, um das Verwenden des Diensts ZooKeeper anzugeben, andernfalls „false“. | Nein |
| zooKeeperNameSpace | Der Namespace für ZooKeeper, unter dem Hive Server 2-Knoten hinzugefügt werden. | Nein |
| useNativeQuery | Gibt an, ob der Treiber native HiveQL-Abfragen verwendet oder diese in eine äquivalente Form in HiveQL konvertiert. | Nein |
| Benutzername | Der Benutzername für den Zugriff auf den Hive-Server. | Nein |
| Kennwort | Das Kennwort für den Benutzer. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Nein |
| httpPath | Die Teil-URL, die dem Hive-Server entspricht. | Nein |
| SSL aktivieren | Gibt an, ob Verbindungen mit dem Server mit TLS verschlüsselt werden. Der Standardwert ist „FALSE“. | Nein |
| VertrauenswürdigerZertifikatspfad | Der vollständige Pfad der PEM-Datei mit vertrauenswürdigen Zertifizierungsstellenzertifikaten zur Überprüfung des Servers beim Verbindungsaufbau über TLS. Diese Eigenschaft kann nur festgelegt werden, wenn TLS in einer selbstgehosteten IR verwendet wird. Der Standardwert ist die Datei „cacerts.pem“, die mit der IR installiert wird. | Nein |
| useSystemTrustStore | Gibt an, ob ein Zertifizierungsstellenzertifikat aus dem Vertrauensspeicher des Systems oder aus einer angegebenen PEM-Datei verwendet werden soll. Der Standardwert ist „FALSE“. | Nein |
| allowHostNameCNMismatch | Gibt an, ob der Name eines von der Zertifizierungsstelle ausgestellten TLS-/SSL-Zertifikats mit dem Hostnamen des Servers übereinstimmen muss, wenn eine Verbindung über TLS hergestellt wird. Der Standardwert ist „FALSE“. | Nein |
| Selbstsigniertes Serverzertifikat zulassen | Gibt an, ob vom Server selbstsignierte Zertifikate zugelassen werden. Der Standardwert ist „FALSE“. | Nein |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Angabe erfolgt, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
| Speicherreferenz | Ein Verweis auf den verknüpften Dienst des Speicherkontos, das für das Staging von Daten im Zuordnungsdatenfluss verwendet wird. Nur erforderlich, wenn im Zuordnungsdatenfluss der verknüpfte Hive-Dienst verwendet wird. | Nein |
Beispiel:
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Hive-Dataset unterstützt werden.
Legen Sie zum Kopieren von Daten aus HTTP die „type“-Eigenschaft des Datasets auf HiveObject fest. Folgende Eigenschaften werden unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft (type) des Datasets muss auf Folgendes festgelegt werden: HiveObject | Ja |
| schema | Name des Schemas. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| Tisch | Der Name der Tabelle. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| Tabellenname | Name der Tabelle einschließlich Schemateil. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie für eine neue Workload schema und table. |
Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel
{
"name": "HiveDataset",
"properties": {
"type": "HiveObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Hive linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Hive-Quelle unterstützt werden.
HiveSource als Quelle
Legen Sie zum Kopieren von Daten aus einem Hive den Quelltyp in der Kopieraktivität auf HiveSource fest. Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die „type“-Eigenschaft der Quelle der Kopieraktivität muss auf HiveSource festgelegt werden. | Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. Beispiel: "SELECT * FROM MyTable". |
Nein (wenn „tableName“ im Dataset angegeben ist) |
Beispiel:
"activities":[
{
"name": "CopyFromHive",
"type": "Copy",
"inputs": [
{
"referenceName": "<Hive input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "HiveSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Eigenschaften von Mapping Data Flow
Der Hive-Connector wird als Quelle vom Typ Inlinedataset in Zuordnungsdatenflüssen unterstützt. Daten können mithilfe einer Abfrage oder direkt aus einer Hive-Tabelle in HDInsight gelesen werden. Hive-Daten werden in einem Speicherkonto als Parquet-Dateien gestaged, bevor sie im Rahmen eines Datenflusses transformiert werden.
Quelleigenschaften
Die folgende Tabelle enthält die von einer Hive-Quelle unterstützten Eigenschaften. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Speichern | Als Speicher muss hive verwendet werden. |
ja | hive |
store |
| Format | Gibt an, ob Daten aus einer Tabelle oder per Abfrage gelesen werden. | ja |
table oder query |
format |
| Schemaname | Das Schema der Quelltabelle (beim Lesen aus einer Tabelle). | Ja, wenn das Format table lautet. |
Schnur | schemaName |
| Tabellenname | Der Tabellenname (beim Lesen aus einer Tabelle). | Ja, wenn das Format table lautet. |
Schnur | Tabellenname |
| Abfrage | Die Quellabfrage für den verknüpften Hive-Dienst, wenn das Format query lautet. |
Ja, wenn das Format query lautet. |
Schnur | Abfrage |
| Gestaffelt | Die Hive-Tabelle wird immer in einem Stagingbereich bereitgestellt. | ja | true |
staged |
| Speichercontainer | Speichercontainer, der vor dem Lesen aus bzw. dem Schreiben in Hive zum Stagen von Daten verwendet wird. Der Hive-Cluster muss Zugriff auf diesen Container haben. | ja | Schnur | Speichercontainer |
| Stagingdatenbank | Das Schema bzw. die Datenbank, auf das bzw. auf die das im verknüpften Dienst angegebene Benutzerkonto Zugriff hat. Dient zum Erstellen externer Tabellen während des Stagings und wird hinterher gelöscht. | nein |
true oder false |
Staging-Datenbankname |
| SQL-Skripts vor Vorgang | SQL-Code, der vor dem Lesen der Daten für die Hive-Tabelle ausgeführt werden soll. | nein | Schnur | preSQLs |
Quellbeispiel
Im Anschluss finden Sie ein Beispiel für eine Hive-Quellkonfiguration:
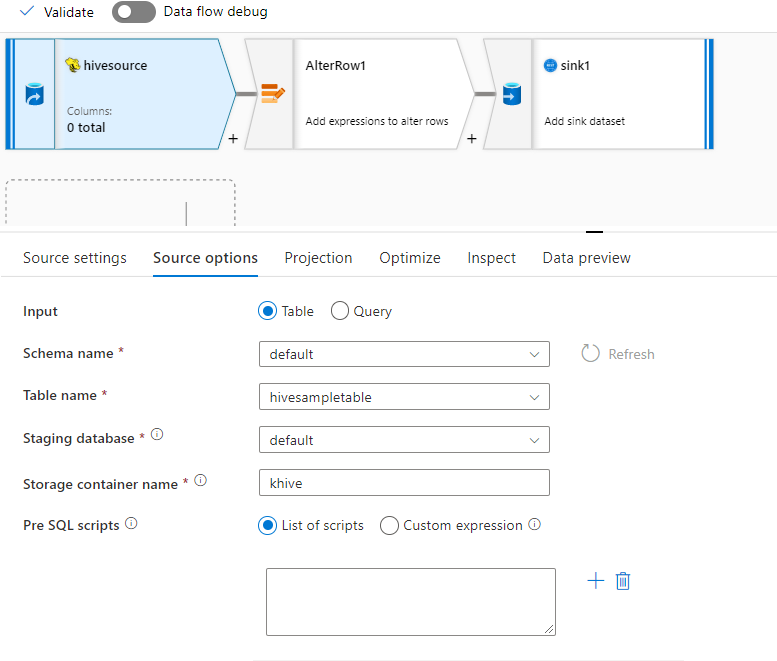
Aus diesen Einstellungen ergibt sich das folgende Datenflussskript:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
format: 'table',
store: 'hive',
schemaName: 'default',
tableName: 'hivesampletable',
staged: true,
storageContainer: 'khive',
storageFolderPath: '',
stagingDatabaseName: 'default') ~> hivesource
Bekannte Einschränkungen
- Komplexe Typen wie Arrays, Zuordnungen, Strukturen und Unions werden für Lesevorgänge nicht unterstützt.
- Der Hive-Connector unterstützt nur Hive-Tabellen in Azure HDInsight ab Version 4.0 (Apache Hive 3.1.0).
- Standardmäßig stellt der Hive-Treiber „tableName.columnName“ in der Senke bereit. Wenn Sie nicht möchten, dass der Tabellenname im Spaltennamen angezeigt wird, gibt es zwei Möglichkeiten, dies zu beheben. a) Überprüfen Sie die Einstellung „hive.resultset.use.unique.column.names“ auf der Hive-Serverseite, und legen Sie sie auf „Falsch“ fest. b. Verwenden Sie die Spaltenzuordnung, um den Spaltennamen umzubenennen.
Datentypzuordnung für Hive
Wenn Sie Daten von und nach Hive kopieren, werden die folgenden Zwischendatentypzuordnungen innerhalb des Dienstes verwendet. Informationen dazu, wie die Kopieraktivität das Quellschema und den Datentyp der Spüle zuordnet, finden Sie unter Schema- und Datentypzuordnungen.
| Hive-Datentyp | Zwischendienstdatentyp (für Version 2.0) | Zwischendienstdatentyp (für Version 1.0) |
|---|---|---|
| TINYINT | Sbyte | Int16 |
| SMALLINT | Int16 | Int16 |
| INT | Int32 | Int32 |
| BIGINT | Int32 | Int64 |
| BOOLEAN | Boolean | Boolean |
| GLEITKOMMAZAHL | Ledig | Ledig |
| Double | Double | Double |
| DECIMAL | Dezimalzahl | Decimal Zeichenfolge (Genauigkeit > 28) |
| STRING | Schnur | Schnur |
| VARCHAR | Schnur | Schnur |
| CHAR | Schnur | Schnur |
| timestamp | DateTimeOffset | Datum/Uhrzeit |
| Datum | Datum/Uhrzeit | Datum/Uhrzeit |
| BINARY | Byte[] | Byte[] |
| ARRAY | Schnur | Schnur |
| KARTE | Schnur | Schnur |
| STRUKTUR | Schnur | Schnur |
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Lebenszyklus und Upgrade des Hive-Connectors
Die folgende Tabelle zeigt die Veröffentlichungsphase und Änderungsprotokolle für verschiedene Versionen des Hive-Connectors:
| Version | Freigabestufe | Änderungsprotokoll |
|---|---|---|
| Version 1.0 | Entfernt | Nicht zutreffend. |
| Version 2.0 | GA-Version verfügbar | • Die selbst gehostete Integrationslaufzeitversion sollte 5.54 oder höher sein. • enableServerCertificateValidation wird unterstützt. • Der Standardwert ist enableSSL true. • Für den Authentifizierungstyp „WindowsAzureHDInsightService“ lautet der Standardwert von httpPath gleich /hive2. • DECIMAL wird als Dezimaldatentyp gelesen. • TINYINT wird als SByte-Datentyp gelesen. • TIMESTAMP wird als DateTimeOffset-Datentyp gelesen. • trustedCertPath, useSystemTrustStore, allowHostNameCNMismatch und allowSelfSignedServerCert werden nicht unterstützt. • Die Verwendung von ';' zum Trennen mehrerer Hosts (nur wenn serviceDiscoveryMode aktiviert ist) wird nicht unterstützt. • HiveServer1 und HiveThriftServer werden für ServerTypenicht unterstützt. • Der Authentifizierungstyp "Benutzername" wird nicht unterstützt. Das SASL-Transportprotokoll unterstützt nur den Authentifizierungstyp UsernameAndPassword. Binäres Transportprotokoll unterstützt nur anonymen Authentifizierungstyp. • serviceDiscoveryMode, zooKeeperNameSpace und useNativeQuery werden nicht unterstützt. |
Aktualisieren des Hive-Connectors von Version 1.0 auf Version 2.0
Wählen Sie auf der Seite "Verknüpften Dienst bearbeiten" Version 2.0 aus, und konfigurieren Sie den verknüpften Dienst, indem Sie auf verknüpfte Diensteigenschaften Version 2.0 verweisen.
Die Datentypzuordnung für den verknüpften Hive-Dienst, Version 2.0, unterscheidet sich von der zuordnung für die Version 1.0. Informationen zur neuesten Datentypzuordnung finden Sie unter "Datentypzuordnung für Hive".
Wenden Sie eine selbst gehostete Integrationslaufzeit mit Version 5.54 oder höher an.
Verwandte Inhalte
Eine Liste der Datenspeicher, die als Quellen und Senken für die Copy-Aktivität unterstützt werden, finden Sie in der Dokumentation zu unterstützten Datenspeichern.