Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Tutorial erfahren Sie, wie Sie den in Log Analytics integrierten Synapse Studio-Connector aktivieren. Anschließend können Sie Anwendungsmetriken und -protokolle von Apache Spark erfassen und an Ihren Log Analytics-Arbeitsbereich senden. Abschließend können Sie eine Azure Monitor-Arbeitsmappe verwenden, um die Metriken und Protokolle zu visualisieren.
Konfigurieren von Arbeitsbereichsinformationen
Führen Sie die folgenden Schritte aus, um die erforderlichen Informationen in Synapse Studio zu konfigurieren.
Schritt 1: Erstellen eines Log Analytics-Arbeitsbereichs
Informationen zum Erstellen dieses Arbeitsbereichs finden Sie in den folgenden Ressourcen:
- Erstellen eines Arbeitsbereichs im Azure-Portal
- Erstellen eines Arbeitsbereichs mit der Azure CLI
- Erstellen und Konfigurieren eines Arbeitsbereichs in Azure Monitor mithilfe von PowerShell
Schritt 2: Erfassen von Konfigurationsinformationen
Verwenden Sie eine der folgenden Optionen, um die Konfiguration vorzubereiten.
Option 1: Konfigurieren mit der ID und dem Schlüssel des Log Analytics-Arbeitsbereichs
Sammeln Sie die folgenden Werte für die Spark-Konfiguration:
-
<LOG_ANALYTICS_WORKSPACE_ID>: ID des Log Analytics-Arbeitsbereichs -
<LOG_ANALYTICS_WORKSPACE_KEY>: Log Analytics-Schlüssel. Diesen Schlüssel finden Sie im Azure-Portal unter Azure Log Analytics-Arbeitsbereich>Agents>Primärschlüssel.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
Alternativ können Sie die folgenden Eigenschaften verwenden:
spark.synapse.diagnostic.emitters: LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret: <LOG_ANALYTICS_WORKSPACE_KEY>
Option 2: Konfigurieren mit Azure Key Vault
Hinweis
Sie müssen den Benutzern, die Apache Spark-Anwendungen einreichen, Leseberechtigung für geheime Daten erteilen. Weitere Informationen finden Sie unter Gewähren des Zugriffs auf Key Vault-Schlüssel, -Zertifikate und -Geheimnisse mit der rollenbasierten Zugriffssteuerung in Azure. Wenn Sie dieses Feature in einer Synapse-Pipeline aktivieren, müssen Sie Option 3 verwenden. Dies ist erforderlich, um das Geheimnis aus Azure Key Vault mit der verwalteten Identität des Arbeitsbereichs abzurufen.
Führen Sie die folgenden Schritte aus, um Azure Key Vault zum Speichern des Arbeitsbereichsschlüssels zu konfigurieren:
Erstellen Sie im Azure-Portal einen Schlüsseltresor, und navigieren Sie dorthin.
Erteilen Sie den Benutzenden oder den verwalteten Identitäten des Arbeitsbereichs die entsprechende Berechtigung.
Wählen Sie auf der Seite mit den Einstellungen des Schlüsseltresors Geheimnisse aus.
Wählen Sie die Option Generieren/Importieren aus.
Wählen Sie auf dem Bildschirm Geheimnis erstellen folgende Werte aus:
-
Name: Geben Sie einen Namen für das Geheimnis ein. Geben Sie als Standardeinstellung
SparkLogAnalyticsSecretein. -
Wert: Geben Sie als Geheimnis
<LOG_ANALYTICS_WORKSPACE_KEY>ein. - Behalten Sie bei den anderen Optionen die Standardwerte bei. Wählen Sie dann Erstellen aus.
-
Name: Geben Sie einen Namen für das Geheimnis ein. Geben Sie als Standardeinstellung
Sammeln Sie die folgenden Werte für die Spark-Konfiguration:
-
<LOG_ANALYTICS_WORKSPACE_ID>: Die ID des Log Analytics-Arbeitsbereichs -
<AZURE_KEY_VAULT_NAME>: Der von Ihnen konfigurierte Name des Schlüsselspeichers -
<AZURE_KEY_VAULT_SECRET_KEY_NAME>(optional): Der Geheimnisname im Schlüsseltresor für den Arbeitsbereichsschlüssel. Der Standardwert istSparkLogAnalyticsSecret.
-
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Alternativ können Sie die folgenden Eigenschaften verwenden:
spark.synapse.diagnostic.emitters LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret.keyVault: <AZURE_KEY_VAULT_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.secretName: <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Hinweis
Sie können auch die Arbeitsbereichs-ID in Key Vault speichern. Gehen Sie wie oben beschrieben vor, und speichern Sie die Arbeitsbereichs-ID mit dem Geheimnisnamen SparkLogAnalyticsWorkspaceId. Alternativ können Sie die Konfiguration spark.synapse.logAnalytics.keyVault.key.workspaceId verwenden, um den Geheimnisnamen der Arbeitsbereichs-ID in Key Vault anzugeben.
Option 3. Konfigurieren mit einem verknüpften Dienst
Hinweis
Bei dieser Option müssen Sie der verwalteten Identität des Arbeitsbereichs Berechtigung zum Lesen von Geheimnissen erteilen. Weitere Informationen finden Sie unter Gewähren des Zugriffs auf Key Vault-Schlüssel, -Zertifikate und -Geheimnisse mit der rollenbasierten Zugriffssteuerung in Azure.
Führen Sie die folgenden Schritte aus, um in Synapse Studio einen mit Key Vault verknüpften Dienst zum Speichern des Arbeitsbereichsschlüssels zu konfigurieren:
Führen Sie alle Schritte im vorherigen Abschnitt unter „Option 2“ aus.
Erstellen Sie in Synapse Studio einen mit Key Vault verknüpften Dienst:
a) Navigieren Sie zu Synapse Studio>Verwalten>Verknüpfte Dienste, und wählen Sie dann Neu aus.
b. Suchen Sie mithilfe des Suchfelds nach Azure Key Vault.
Abschnitt c. Geben Sie einen Namen für den verknüpften Dienst ein.
d. Wählen Sie Ihren Schlüsseltresor und dann Erstellen aus.
Fügen Sie der Apache Spark-Konfiguration ein Element vom Typ
spark.synapse.logAnalytics.keyVault.linkedServiceNamehinzu.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
Alternativ können Sie die folgenden Eigenschaften verwenden:
spark.synapse.diagnostic.emitters LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret.keyVault: <AZURE_KEY_VAULT_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.secretName: <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.linkedService: <AZURE_KEY_VAULT_LINKED_SERVICE>
Eine Liste der Apache Spark-Konfigurationen finden Sie unter Verfügbare Apache Spark-Konfigurationen.
Schritt 3: Erstellen einer Apache Spark-Konfiguration
Sie können eine Apache Spark-Konfiguration für Ihren Arbeitsbereich erstellen. Wenn Sie dann eine Notebook- oder Apache Spark-Auftragsdefinition erstellen, können Sie die Apache Spark-Konfiguration auswählen, die Sie mit Ihrem Apache Spark-Pool verwenden möchten. Wenn Sie die Konfiguration auswählen, werden die Details angezeigt.
Wählen Sie Verwalten>Apache Spark-Konfigurationen aus.
Wählen Sie die Schaltfläche Neu aus, um eine neue Apache Spark-Konfiguration zu erstellen.
Die Seite Neue Apache Spark-Konfiguration wird geöffnet, nachdem Sie die Schaltfläche Neu ausgewählt haben.

Bei Name können Sie Ihren bevorzugten und gültigen Namen eingeben.
Bei Beschreibung können Sie eine Beschreibung eingeben.
Bei Anmerkungen können Sie Anmerkungen hinzufügen, indem Sie auf Neu klicken. Sie können auch vorhandene Anmerkungen löschen, indem Sie auf Löschen klicken.
Fügen Sie für Konfigurationseigenschaften alle Eigenschaften der von Ihnen ausgewählten Konfigurationsoption hinzu, indem Sie die Schaltfläche Hinzufügen auswählen. Fügen Sie für Eigenschaft den Eigenschaftsnamen wie aufgelistet hinzu, und verwenden Sie für Wert den Wert, den Sie in Schritt 2 erfasst haben. Wenn Sie keine Eigenschaft hinzufügen, verwendet Azure Synapse ggf. den entsprechenden Standardwert.

Übermitteln einer Apache Spark-Anwendung und Anzeigen der Protokolle und Metriken
Gehen Sie dazu wie folgt vor:
Übermitteln Sie eine Apache Spark-Anwendung an den im vorherigen Schritt konfigurierten Apache Spark-Pool. Sie können dazu eine der folgenden Methoden verwenden:
- Führen Sie ein Notebook in Synapse Studio aus.
- Übermitteln Sie in Synapse Studio einen Apache Spark-Batchauftrag über eine Apache Spark-Auftragsdefinition.
- Führen Sie eine Pipeline mit einer Apache Spark-Aktivität aus.
Navigieren Sie zum angegebenen Log Analytics-Arbeitsbereich, und sehen Sie sich die Anwendungsmetriken und -protokolle an, wenn die Apache Spark-Anwendung gestartet wird.
Schreiben von benutzerdefinierten Anwendungsprotokollen
Sie können die Apache Log4j-Bibliothek verwenden, um benutzerdefinierte Protokolle zu schreiben.
Ein Beispiel für Scala:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Ein Beispiel für PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Visualisieren der Metriken und Protokolle unter Verwendung der Beispielarbeitsmappe
Öffnen Sie die Arbeitsmappendatei, und kopieren Sie den Inhalt.
Wählen Sie im Azure-Portal die Option Log Analytics-Arbeitsbereich>Arbeitsmappen aus.
Öffnen Sie die Arbeitsmappe namens Leer. Verwenden Sie den Modus Erweiterter Editor, indem Sie das Symbol </> auswählen.
Fügen Sie den gesamten vorhandenen JSON-Code ein.
Wählen Sie Anwenden und dann Bearbeitung abgeschlossen aus.


Übermitteln Sie als Nächstes Ihre Apache Spark-Anwendung an den konfigurierten Apache Spark-Pool. Wenn sich die Anwendung im Ausführungszustand befindet, können Sie die ausgeführte Anwendung in der Dropdownliste der Arbeitsmappen auswählen.
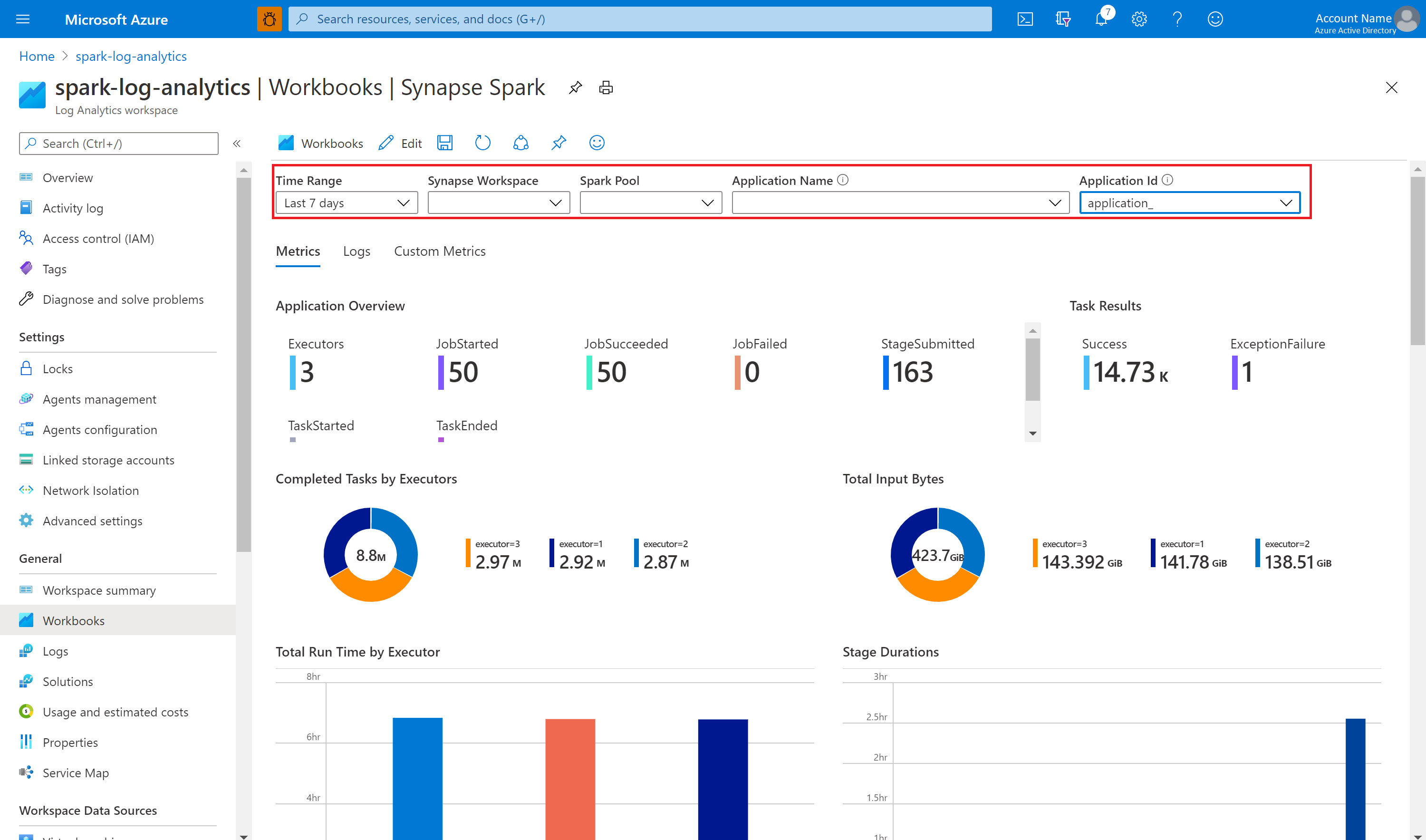
Sie können die Arbeitsmappe anpassen. Beispielsweise können Sie Kusto-Abfragen verwenden und Warnungen konfigurieren.

Abfragen von Daten mit Kusto
Hier sehen Sie ein Beispiel für das Abfragen von Apache Spark-Ereignissen:
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Hier sehen Sie ein Beispiel für das Abfragen von Treiber- und Executor-Protokollen der Apache Spark-Anwendung:
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Und hier sehen Sie ein Beispiel für das Abfragen von Apache Spark-Metriken:
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Erstellen und Verwalten von Warnungen
Benutzer können Abfragen ausführen, um Metriken und Protokolle mit einer bestimmten Häufigkeit auszuwerten und basierend auf den Ergebnissen eine Warnung auszulösen. Weitere Informationen finden Sie unter Erstellen, Anzeigen und Verwalten von Protokollwarnungen mithilfe von Azure Monitor.
Synapse-Arbeitsbereich mit aktiviertem Schutz vor Datenexfiltration
Nachdem der Synapse-Arbeitsbereich mit aktiviertem Schutz vor Datenexfiltration erstellt wurde.
Wenn Sie dieses Feature aktivieren möchten, müssen Sie in den genehmigten Microsoft Entra-Mandanten des Arbeitsbereichs Anforderungen für verwaltete private Endpunktverbindungen mit Azure Monitor Private Link-Bereichen (Azure Monitor Private Link Scopes, AMPLS) erstellen.
Sie können die folgenden Schritte ausführen, um eine verwaltete private Endpunktverbindung zu den Private Link-Bereichen von Azure Monitor (AMPLS) zu erstellen:
- Wenn kein AMPLS vorhanden ist, können Sie die Einrichtungsanleitung für die Azure Monitor Private Link-Verbindung befolgen, um eine zu erstellen.
- Navigieren Sie im Azure-Portal zu Ihrem AMPLS, und wählen Sie auf der Seite Azure Monitor-Ressourcen die Option Hinzufügen aus, um Ihrem Azure Log Analytics-Arbeitsbereich eine Verbindung hinzuzufügen.
- Navigieren Sie zu Synapse Studio > Verwalten > Verwaltete private Endpunkte, wählen Sie die Schaltfläche Neu, die Option Azure Monitor-Private Link-Bereiche und dann Weiter aus.

- Wählen Sie den von Ihnen erstellten Azure Monitor-Private Link-Bereich und dann die Schaltfläche Erstellen aus.

- Bitte warten Sie einige Minuten auf die Bereitstellung des privaten Endpunkts.
- Navigieren Sie im Azure-Portal erneut zu Ihrem AMPLS. Wählen Sie auf der Seite Private Endpunktverbindungen die eingerichtete Verbindung und dann Genehmigen aus.
Hinweis
- Das AMPLS-Objekt weist viele Einschränkungen auf, die Sie beim Planen der Einrichtung von privatem Link berücksichtigen sollten. Weitere Informationen zu diesen Grenzwerten finden Sie unter AMPLS limits für eine ausführlichere Überprüfung dieser Grenzwerte.
- Prüfen Sie, ob Sie die erforderliche Berechtigung zum Erstellen eines verwalteten privaten Endpunkts haben.
Verfügbare Konfigurationen
| Konfiguration | BESCHREIBUNG |
|---|---|
spark.synapse.diagnostic.emitters |
Erforderlich. Kommagetrennte Liste der Zielnamen von Diagnoseemittern. Zum Beispiel, MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Erforderlich. Integrierter Zieltyp Um das Azure Log Analytics-Ziel zu aktivieren, muss AzureLogAnalytics in dieses Feld eingeschlossen werden. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Wahlfrei. Kommagetrennte Liste der ausgewählten Protokollkategorien. Verfügbare Werte: DriverLog, ExecutorLog, EventLog, Metrics. Ist diese Option nicht festgelegt, werden standardmäßig alle Kategorien verwendet. |
spark.synapse.diagnostic.emitter.<destination>.workspaceId |
Erforderlich. Um das Ziel von Azure Log Analytics zu aktivieren, muss die workspaceId in diesem Feld angegeben werden. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Wahlfrei. Der geheime Inhalt (Log Analytics-Schlüssel). Diesen Schlüssel finden Sie im Azure-Portal unter „Azure Log Analytics-Arbeitsbereich“ > „Agents“ > „Primärschlüssel“. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Erforderlich, wenn .secret nicht angegeben wird. Der Name der Azure Key Vault-Instanz, in der das Geheimnis (Zugriffsschlüssel oder SAS) gespeichert ist. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Erforderlich, wenn .secret.keyVault angegeben wird. Der Name des Azure Key Vault-Geheimnisses, in dem das Geheimnis gespeichert ist. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Wahlfrei. Der Name des mit Azure Key Vault verknüpften Diensts. Wenn sie in Synapse-Pipeline aktiviert ist, ist dies erforderlich, um den geheimen Schlüssel aus dem Azure Key Vault abzurufen. (Stellen Sie sicher, dass die MSI Lesezugriff auf den Azure Key Vault hat). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Wahlfrei. Mit den kommagetrennten Log4j-Logger-Namen können Sie angeben, welche Logs gesammelt werden sollen. Beispiel: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Wahlfrei. Die log4j-Logger-Namen, die kommasepariert sind, können Sie verwenden, um anzugeben, welche Protokolle gesammelt werden sollen. Beispiel: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Wahlfrei. Die durch Kommata getrennten Spark-Metriknamensuffixe, mit denen Sie angeben können, welche Metriken gesammelt werden sollen. Beispiel: jvm.heap.used |