Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
gilt für: SQL Server Analysis Services
SQL Server Analysis Services  Azure Analysis Services Fabric/Power BI Premium
Azure Analysis Services Fabric/Power BI Premium
In diesem Artikel werden neue Features, Verbesserungen, veraltete und nicht mehr unterstützte Features sowie Verhaltensweisen und wesentliche Änderungen in den neuesten Versionen von SQL Server Analysis Services (SSAS) zusammengefasst.
SQL Server 2025 Analysis Services
Leistungsverbesserungen
Modelle mit Berechnungsgruppen und Formatzeichenfolgen in Excel
Wir haben erhebliche Leistungsverbesserungen für MDX-Abfragen für Modelle mit Berechnungsgruppen und Formatzeichenfolgen vorgenommen, um die Speicherauslastung zu reduzieren und die Reaktionsfähigkeit zu verbessern. Die neuesten Änderungen verbessern die Leistung und Zuverlässigkeit von Vorgängen in Analyze in Excel auf Modellen, die eins oder beide umfassen:
Dynamische Formatzeichenfolgen für Kennzahlen
Berechnete Elemente mit Formatzeichenfolgen
Weitere Details finden Sie unter Dynamische Formatzeichenfolgen
Parallele Abfrageausführung für DirectQuery
Verbesserte Parallelität im DirectQuery-Modus ermöglicht schnellere Reaktionszeiten für komplexe Abfragen. Die grundlegende Idee besteht darin, die Abfrageleistung zu maximieren, indem mehrere Abfragen zur Datenquelle für eine einzelne DAX-Abfrage parallelisiert werden. Diese Abfrage-Parallelisierung reduziert die Auswirkungen von Datenquellenverzögerungen und Netzwerklatenz auf die Abfrageleistung. Weitere Details finden Sie in diesem Blog.
Horizontale Fusion
SQL Server Analysis Services 2025 enthält die neueste Version von Horizontal Fusion, eine Abfrageleistungsoptimierung, die die Anzahl der von DAX generierten SQL-Abfragen reduziert und die DirectQuery-Effizienz verbessert. Weitere Details finden Sie unter: Ankündigung einer horizontalen Fusion.
DAX-Funktionen und -Fähigkeiten
Visuelle Berechnungen
Die Art und Weise, wie Sie DAX schreiben, ändert sich mit der Einführung von visuellen Berechnungen. Visuelle Berechnungen sind DAX-Berechnungen, die direkt auf einem visuellen Element definiert und ausgeführt werden. Eine visuelle Berechnung kann sich auf alle Daten im Visual beziehen, einschließlich Spalten, Maße oder anderen visuellen Berechnungen. Dieser Ansatz entfernt die Komplexität des Semantikmodells und vereinfacht das Schreiben von DAX. Sie können visuelle Berechnungen verwenden, um allgemeine Geschäftsberechnungen wie laufende Summen oder gleitende Durchschnitte durchzuführen. Weitere Informationen zum Aktivieren und Verwenden visueller Berechnungen finden Sie in der Übersicht über visuelle Berechnungen.
Wertfilterverhalten
Wir führen eine neue Option zum Steuern des Wertfilterverhaltens ein. Durch Aktivieren der Einstellung "Unabhängige Wertefilter" können Benutzer die automatische Kombination mehrerer Filter in derselben Tabelle in einem einzigen zusammengeführten Filter verhindern. Diese Änderung bietet eine größere Flexibilität, indem sie eine präzisere und unabhängigere Filterung ermöglicht, um spezifische Modellierungsanforderungen zu erfüllen und die Genauigkeit und Kontrolle bei Datenabfragen zu verbessern. Um diese Eigenschaft für SSAS festzulegen, können Sie das Tabellarische Objektmodell oder TMSL basierend auf der ValueFilterBehavior-Eigenschaft verwenden. Weitere Informationen finden Sie unter : Wertfilterverhalten.
Auswahlausdrücke für Berechnungsgruppen
Auswahlausdrücke ermöglichen eine fein abgestimmte Kontrolle über das Verhalten von Berechnungen, wenn bestimmte Bedingungen erfüllt sind. Auswahlausdrücke stellen zusätzliche Logik für die Behandlung von Fällen vor, in denen mehrere Berechnungselemente ausgewählt werden oder wenn keine bestimmte Auswahl für eine Berechnungsgruppe erfolgt. Weitere Details finden Sie unter: Berechnungsgruppen.
Verbesserungen bei DAX-Funktionen
SQL Server Analysis Services 2025 umfasst Unterstützung für mehrere neue DAX-Funktionen und Verbesserungen, darunter:
LINEST und LINESTX: Diese beiden Funktionen führen eine lineare Regression mit der Methode "Least Squares" aus, um eine gerade Linie zu berechnen, die am besten zu den angegebenen Daten passt, und eine Tabelle zurückgeben, die diese Linie beschreibt. Diese Funktionen sind besonders nützlich bei der Vorhersage unbekannter Werte (Y), wenn bekannte Werte (X) angegeben werden. Weitere Informationen finden Sie unter : LINEST DAX-Funktion und LINESTX DAX-Funktion.
INFO-Funktionen: Die vorhandenen TMSCHEMA DMVs sind jetzt als neue Familie von DAX-Funktionen verfügbar, die das Abfragen von Metadaten zu semantischen Modellen direkt innerhalb von DAX ermöglicht und die Integration mit anderen DAX-Funktionen für erweiterte Diagnose und Analyse bietet. Weitere Informationen finden Sie unter : Info DAX-Funktionen.
APPROXIMATEDISTINCTCOUNT: Diese Funktion ist derzeit für den DirectQuery-Modus verfügbar und gibt eine geschätzte Anzahl eindeutiger Werte in einer Spalte zurück, indem sie einen entsprechenden Aggregationsvorgang in der Datenquelle aufruft, der für die Abfrageleistung optimiert ist. Weitere Informationen finden Sie in der Approximatedistinctcount DAX-Funktion, die unterstützte Datenquellen auflistet.
Fensterfunktionen: Diese Funktion ruft einen Ausschnitt der Ergebnisse mit absoluter oder relativer Positionierung ab. Die WINDOW-Funktion erleichtert das Ausführen von Berechnungen, z. B. das Hinzufügen einer laufenden Summe, eines gleitenden Mittelwerts oder ähnlicher Berechnungen, die auf der Auswahl eines Wertebereichs basieren. Es enthält auch zwei Hilfsfunktionen namens ORDERBY und PARTITIONBY. Weitere Informationen finden Sie unter :Window DAX-Funktion.
MINX/MAXX: Wir haben den Funktionen MINX und MAXX DAX einen optionalen Variant-Parameter hinzugefügt. Traditionell ignorieren diese Funktionen Text- und boolesche Werte, wenn Varianten oder gemischte Datentypen vorhanden sind, z. B. Text und numerische Werte. Da nun der neue optionale Variant-Parameter auf TRUE festgelegt ist, berücksichtigen die Funktionen die Textwerte. Weitere Informationen finden Sie in der MINX DAX-Funktion und der MAXX DAX-Funktion.
Tipp
INFO-Funktionen können sich in Power BI entwickeln, um die Informationsermittlung in neuen Semantikmodellartefakten zu unterstützen. Siehe [MS-SSAS-T] für den Satz von Artefakten, die möglicherweise über eine entsprechende INFO-Funktion in SQL Server Analysis Services 2025 verfügen.
Neue Entwicklereditionen
Hinweis
Die umfassende Unterstützung der Editionen und Feature-Unterstützung für SQL Server Analysis Services 2025 wird erst in allen Details dokumentiert, wenn das Produkt allgemein verfügbar ist (GA). Die in diesem Artikel beschriebenen Merkmale und Editionen können bis zur allgemeinen Verfügbarkeit geändert werden.
Die folgenden kostenlosen Editionen sind so konzipiert, dass alle Features ihrer entsprechenden kostenpflichtigen Editionen bereitgestellt werden. Sie können zum Entwickeln von SQL Server-Anwendungen verwendet werden, ohne dass eine kostenpflichtige Lizenz erforderlich ist.
Für Features nach Edition überprüfen Sie features, die von SQL Server Edition unterstützt werden
Die Editionen und unterstützten Features für SQL Server 2025 (17.x) Preview können bis zur allgemeinen Verfügbarkeit des Produkts geändert werden.
Standard Developer Ausgabe
SQL Server 2025 Standard Developer Edition ist eine kostenlose Edition, die für die Entwicklung lizenziert ist. Es enthält alle Features der SQL Server Standard Edition.
- Entwickeln Sie neue Anwendungen für Standard Edition.
- Richten Sie eine Stagingumgebung ein, um das Upgrade einer vorhandenen Anwendung von der Standard Edition auf SQL Server 2025 Standard Edition zu zertifizieren, bevor Sie sie in der Produktion bereitstellen.
Enterprise Developer Edition
SQL Server 2025 Enterprise Developer Edition umfasst SQL Server Enterprise Edition-Features.
- Entwickeln Sie neue Anwendungen für Enterprise Edition.
- Funktionell entspricht der Entwickleredition in früheren Versionen.
Zusätzliche Features
Aktualisierungen der Clientbibliothek
Kunden werden ermutigt, ein Upgrade auf die neuesten Analysis Services-Bibliotheken durchzuführen, um von Leistungs-, Zuverlässigkeits- und Funktionsverbesserungen wie binärer XML-Unterstützung, TMDL-Serialisierung und mehr zu profitieren. Insbesondere haben wir die XMLA-basierte Kommunikation von Nur-Text-XML auf binäre XML umgestellt und die Komprimierung für .NET-Clientbibliotheken aktiviert. Weitere Details finden Sie im Blog zur Verbesserung der Kommunikationsleistung von xmla-basierten Tools . Sie können auch immer die neuesten Clientbibliotheksversionen auf der Downloadseite der Analysis Services-Clientbibliotheken finden.
Verbesserungen bei der Unicode-Zeichenbehandlung
SQL Server Analysis Services 2025 unterstützt jetzt aktualisierte Unicode-Standards durch Bereitstellung von Unicode-Ersatzpaarunterstützung für Zeichenstandards wie den chinesischen Government-Standard GB18030 in DAX.
Ausführungsmetriken für die Diagnostik
Ausführungsmetriken werden jetzt über XEvents- und Profiler-Ablaufverfolgungen verfügbar gemacht, sodass Kunden die Abfrageleistung effektiver analysieren können. Weitere Details finden Sie in diesem Blog.
Failover-Clusterunterstützung
Weitere Informationen finden Sie in diesem Artikel zum Upgrade-Verschlüsselungsschema.
Veraltete Features und Breaking Changes in SQL Server Analysis Services 2025
Excel PowerPivot für SharePoint nicht mehr verfügbar
Wir haben den Excel PowerPivot für SharePoint-Modus aus dem Installationsprogramm entfernt. Dieses Feature war in früheren Versionen veraltet und wird in SQL Server Analysis Services 2025 nicht mehr unterstützt.
SQL-Client-Assembly-Update
SQL Server Analysis Services 2025 verwendet jetzt eine neuere SQL-Clientbibliothek. Kunden müssen möglicherweise Modelldefinitionen aktualisieren, um den neuen Anbieternamen (Microsoft.Data.SqlClient) widerzuspiegeln.
HTTP-Zugriffsänderungen
Ab SQL Server Analysis Services 2025 werden HTTP-Verbindungen über msmdpump.dll standardmäßig deaktiviert. Alle Verbindungen über msmdpump.dll müssen über einen sicheren Kanal wie HTTPS erfolgen. Weitere Informationen finden Sie unter Konfigurieren des HTTP-Zugriffs.
Bekannte Probleme
Windows Arm64 wird nicht unterstützt
SQL Server Analysis Services 2025 wird unter Windows Arm64 nicht unterstützt. Derzeit werden nur Intel und AMD x86-64 CPUs mit bis zu 64 Kernen pro NUMA-Knoten unterstützt.
SQL Server 2022 Analysis Services
Kumulatives Update 1 (CU1)
Verschlüsselungsupgrade
Dieses Update enthält eine Erweiterung des Verschlüsselungsalgorithmus für den Schemaschreibvorgang. Bei dieser Erweiterung müssen Sie möglicherweise tabellarische und mehrdimensionale Modelldatenbanken aktualisieren, um eine ordnungsgemäße Verschlüsselung sicherzustellen. Weitere Informationen finden Sie unter Verschlüsselung upgraden.
Allgemein verfügbar (Generally Available, GA)
Horizontale Fusion
Diese Version führt Horizontal Fusion ein, eine Optimierung des Abfrageausführungsplans, die darauf abzielt, die Anzahl der Datenquellenabfragen zu reduzieren, die zum Generieren und Zurückgeben von Ergebnissen erforderlich sind. Mehrere kleinere Datenquellenabfragen werden in eine größere Datenquellenabfrage zusammengeführt. Weniger Datenquellenabfragen bedeuten weniger Roundtrips und weniger teure Scans über große Datenquellen, was zu größenmäßigen DAX-Leistungssteigerungen und geringerer Verarbeitungsbedarf an der Datenquelle führt. DAX-Abfragen werden mit horizontaler Fusion schneller ausgeführt, insbesondere im DirectQuery-Modus. Darüber hinaus steigt auch die Skalierbarkeit.
Parallele Ausführungspläne für DirectQuery
Diese Verbesserung ermöglicht es dem Analysis Services-Modul, DAX-Abfragen anhand einer DirectQuery-Datenquelle zu analysieren und unabhängige Speichermodulvorgänge zu identifizieren. Die Engine kann diese Operationen dann parallel zur Datenquelle ausführen. Durch die parallele Ausführung von Vorgängen kann das Analysis Services-Modul die Abfrageleistung verbessern, indem sie die Vorteile der Skalierbarkeit großer Datenquellen nutzen kann. Um sicherzustellen, dass die Abfrageverarbeitung Ihre Datenquelle nicht überlastet, verwenden Sie die Einstellung der MaxParallelism-Eigenschaft , um eine feste Anzahl von Threads anzugeben, die für parallele Vorgänge verwendet werden können.
Unterstützung für Power BI DirectQuery-Semantikmodelle
In dieser Version wird unterstützung für Power BI-Modelle mit DirectQuery-Verbindungen zu SQL Server 2022 Analysis Services-Modellen eingeführt. Datenmodellierer und Berichtsautoren, die die Versionen vom Mai 2022 und höher von Power BI Desktop verwenden, können jetzt andere importierte und DirectQuery-Daten aus Power BI-Modellen, Azure Analysis Services und jetzt SSAS 2022 kombinieren.
Weitere Informationen finden Sie unter Verwenden von DirectQuery für semantische Modelle und Analysis Services | Power BI-Dokumentation.
MDX-Abfrageleistung
Die erste Einführung in Power BI und jetzt in SSAS 2022 umfasst MDX Fusion die Optimierung des Formelmoduls (FE), wodurch die Anzahl der SE-Abfragen pro MDX-Abfrage reduziert wird. Clientanwendungen, die Multidimensional Expressions (MDX) zum Abfragen von Modell-/Datasetdaten wie Microsoft Excel verwenden, sehen eine verbesserte Abfrageleistung. Allgemeine MDX-Abfragemuster erfordern jetzt weniger SE-Abfragen, bei denen zuvor zahlreiche SE-Abfragen erforderlich waren, um unterschiedliche Granularität zu unterstützen. Weniger SE-Abfragen bedeuten weniger teure Scans über große Modelle, was zu erheblichen Leistungssteigerungen führt, insbesondere beim Herstellen einer Verbindung mit tabellarischen Modellen im Direct Query-Modus.
Weitere Informationen finden Sie unter Ankündigung verbesserter MDX-Abfrageleistung in Power BI | Microsoft Power BI-Blog.
Ressourcenverwaltung
Diese Version enthält eine verbesserte Genauigkeit für die QueryMemoryLimit-Serverspeichereigenschaft und die DbpropMsmdRequestMemoryLimit-Verbindungszeichenfolgeneigenschaft.
Erstmals in SSAS 2019 eingeführt, wird die QueryMemoryLimit-Serverspeichereigenschaft nur auf speicherintensive Vorgänge angewendet, bei denen während der Abfrageverarbeitung zwischengelagerte DAX-Abfrageergebnisse erstellt werden. Jetzt in SSAS 2022 gilt sie auch für MDX-Abfragen, die alle Abfragen effektiv abdecken. Sie können teure Abfragen, die zu erheblichen physischen Materialisierungen führen, besser verarbeiten. Wenn die Abfrage den angegebenen Grenzwert erreicht, bricht das Modul die Abfrage ab und gibt einen Fehler an den Aufrufer zurück, wodurch die Auswirkungen auf andere gleichzeitige Benutzer reduziert werden.
Clientanwendungen können den pro Abfrage zulässigen Arbeitsspeicher weiter reduzieren, indem sie die DbpropMsmdRequestMemoryLimit-Verbindungszeichenfolgeneigenschaft angeben. In Kilobytes angegeben, überschreibt diese Eigenschaft den Wert der QueryMemoryLimit-Serverspeichereigenschaft für eine Verbindung.
Interleaving von Abfragen – Verzerrung durch kurze Abfragen mit schnellem Abbruch
Diese Version führt einen neuen Wert ein, der eine kurze Abfrageabweichung mit schneller Abbruch für die Einstellung der Threadpool\SchedulingBehavior-Eigenschaft angibt. Diese Eigenschaftseinstellung verbessert die Reaktionszeiten von Benutzerabfragen in Szenarien mit hoher Parallelität. Weitere Informationen finden Sie unter "Abfrageinterleaving – Konfigurieren".
Tabellarmodell-Kompatibilitätsstufe 1600
In dieser Version wird die Kompatibilitätsstufe 1600 für tabellarische Modelle eingeführt. Die Kompatibilitätsstufe 1600 fällt mit der neuesten Funktionalität in Power BI und Azure Analysis Services zusammen.
Veraltete Features in SSAS 2022
Es gibt keine veralteten Features, die mit dieser Version angekündigt wurden.
Nicht mehr vorhandene Features in SSAS 2022
Die folgenden Features werden in dieser Version nicht mehr unterstützt :
| Modus/Kategorie | Merkmal |
|---|---|
| Tabellarisch | 1100 und 1103 Kompatibilitätsstufen |
| Mehrdimensional | Data-Mining |
| Power Pivot-Modus | Power Pivot für SharePoint |
Unterbrechen von Änderungen in SSAS 2022
Tabellarische Modell 1100- und 1103-Kompatibilitätsstufen werden in dieser Version nicht mehr unterstützt. Um eine bahnbrechende Änderung zu verhindern, aktualisieren Sie Modelle auf die Kompatibilitätsstufe 1200, bevor Sie eine frühere SSAS-Version auf SSAS 2022 aktualisieren.
Verhaltensänderungen in SSAS 2022
In dieser Version gibt es keine Verhaltensänderungen .
SQL Server 2019 Analysis Services
SQL Server 2019 Analysis Services CU 5
Kumulative Updates für SQL Server Analysis Services sind in kumulativen SQL Server-Updates enthalten. Weitere Informationen zum aktuellen kumulativen Update finden Sie unter SQL Server 2019, dem neuesten kumulativen Update. Kb-Seiten für kumulative Updates fassen bekannte Probleme, Verbesserungen und Korrekturen für alle SQL Server-Features zusammen, einschließlich SSAS. Weitere Details zu wichtigen Featureupdates für SSAS werden hier beschrieben.
SuperDAX für mehrdimensionale Modelle (SuperDAXMD)
Mit CU5 können DAX-basierte Clients jetzt SuperDAX-Funktionen und Abfragemuster für multidimensionale Modelle verwenden und eine verbesserte Leistung beim Abfragen von Modelldaten bieten. SuperDAX führte zunächst DAX-Abfrageoptimierungen für tabellarische Modelle mit Power BI und SQL Server Analysis Services 2016 ein. SuperDAXMD bringt diese Verbesserungen nun zu mehrdimensionalen Modellen.
Eine separate Ankündigung im Power BI-Blog zeigt, wie Power BI-Benutzer von dieser multidimensionalen Modellleistungsverbesserung profitieren können, indem Sie die neueste Version von Power BI Desktop herunterladen. Vorhandene interaktive Berichte im Power BI-Dienst können ohne zusätzliche Schritte profitieren, da Power BI die optimierten SuperDAX-Abfragen automatisch generiert. Power BI erkennt automatisch Verbindungen mit mehrdimensionalen Modellen mit SuperDAX-Unterstützung und verwendet dieselben optimierten DAX-Funktionen und Abfragemuster, die sie bereits für tabellarische Modelle verwendet. Während Power BI automatisch zu SuperDAXMD wechseln kann, müssen Sie in Ihren eigenen Business Intelligence-Lösungen möglicherweise DAX-Abfragemuster manuell optimieren.
Optimierte Abfragemuster sollten DIE SUMMARIZECOLUMNS-Funktion verwenden, um die weniger effiziente Standardfunktion SUMMARIZE zu ersetzen. Verwenden Sie DAX-Variablen , VAR, um Ausdrücke nur einmal an der Stelle der Definition zu berechnen und dann die Ergebnisse in anderen DAX-Ausdrücken wiederzuverwenden, ohne die Berechnung erneut ausführen zu müssen. Andere und vielleicht weniger häufige SuperDAX-Funktionen sind SUBSTITUTEWITHINDEX, ADDMISSINGITEMS sowie NATURALLEFTOUTERJOIN und NATURALINNERJOIN, ISONORAFTER und GROUPBY. SELECTCOLUMNS und UNION sind auch SuperDAX-Funktionen.
Wenn Sie mehr darüber erfahren möchten, wie DAX mit multidimensionalen Modellen funktioniert, und wichtige Muster und Einschränkungen, die Sie kennen sollten, sollten Sie UNBEDINGT DAX für multidimensionale Modelle anzeigen.
SQL Server 2019 Analysis Services GA (allgemein verfügbar)
Kompatibilitätsstufe für tabellarische Modelle
In dieser Version wird die Kompatibilitätsstufe 1500 für tabellarische Modelle eingeführt.
Interleaving der Abfrage
Die Abfrageüberlappung ist eine Systemkonfiguration im tabellarischen Modus, mit der die Antwortzeiten für Benutzerabfragen in Szenarios mit hoher Parallelität verbessert werden können. Durch das Interleaving von Abfragen mit Kurzanfrage-Bias können gleichzeitige Abfragen die gemeinsame Nutzung von CPU-Ressourcen ermöglichen. Weitere Informationen finden Sie unter Abfrageüberlappung.
Berechnungsgruppen in tabellarischen Modellen
Berechnungsgruppen können die Anzahl der redundanten Measures deutlich reduzieren, indem sie gängige Measure-Ausdrücke als Berechnungselemente gruppieren. Berechnungsgruppen werden in Berichtsclients als Tabelle mit einer einzelnen Spalte angezeigt. Jeder Wert in der Spalte stellt eine wiederverwendbare Berechnung oder ein Berechnungselement dar, das auf beliebige Measures angewendet werden kann. Eine Berechnungsgruppe kann eine beliebige Anzahl von Berechnungselementen enthalten. Jedes Berechnungselement wird durch einen DAX-Ausdruck definiert. Weitere Informationen finden Sie unter Berechnungsgruppen.
Governanceeinstellung für Power BI-Cacheaktualisierungen
Die Eigenschaftseinstellung "ClientCacheRefreshPolicy " wird jetzt in SSAS 2019 und höher unterstützt. Diese Eigenschaftseinstellung ist bereits für Azure Analysis Services verfügbar. Der Power BI-Dienst speichert Dashboardkacheldaten und Berichtsdaten zwischen, um den Live Connect-Bericht initial zu laden, was zu einer übermäßigen Anzahl von Cacheabfragen führt, die an die Engine übermittelt werden und in extremen Fällen den Server überlasten können. Mit der ClientCacheRefreshPolicy-Eigenschaft können Sie dieses Verhalten auf Serverebene außer Kraft setzen. Weitere Informationen finden Sie unter Allgemeine Eigenschaften.
Online anfügen
Dieses Feature bietet die Möglichkeit, ein tabellarisches Modell als Onlinevorgang anzufügen. Onlineanfügen kann für die Synchronisierung schreibgeschützter Replikate in horizontal skalierten Umgebungen für lokale Abfragen verwendet werden. Verwenden Sie zum Ausführen eines Onlineanfügungsvorgangs die AllowOverwrite-Option des Befehls "XMLA anfügen".

Für diesen Vorgang ist möglicherweise ein doppelter Speicher erforderlich , um die alte Version online zu halten, während die neue Version geladen wird.
Ein typisches Verwendungsmuster könnte wie folgt sein:
DB1 (Version 1) ist bereits mit dem schreibgeschützten Server B verbunden.
DB1 (Version 2) wird auf dem Schreibserver A verarbeitet.
DB1 (Version 2) wird getrennt und an einem Ort platziert, der für Server B zugänglich ist (entweder über einen freigegebenen Standort oder mithilfe von Robocopy usw.).
Der Befehl "Anfügen" mit AllowOverwrite=True wird auf Server B mit dem neuen Speicherort von DB1 (Version 2) ausgeführt.
Ohne dieses Feature müssen Administratoren zuerst die Datenbank trennen und dann die neue Version der Datenbank anfügen. Dies führt zu Ausfallzeiten, wenn die Datenbank für Benutzer nicht verfügbar ist und Abfragen daran fehlschlagen.
Wenn diese neue Kennzeichnung angegeben wird, wird Version 1 der Datenbank atomisch innerhalb derselben Transaktion ohne Ausfallzeiten gelöscht. Es geschieht jedoch auf Kosten, dass beide Datenbanken gleichzeitig in den Arbeitsspeicher geladen werden müssen.
M:n-Beziehungen in tabellarischen Modellen
Diese Verbesserung ermöglicht m:n-Beziehungen zwischen Tabellen, bei denen beide Spalten nicht eindeutig sind. Eine Beziehung kann zwischen einer Dimension und einer Faktentabelle mit einer Granularität definiert werden, die höher als die Schlüsselspalte der Dimension ist. Dies verhindert, dass Bemaßungstabellen normalisiert und die Benutzererfahrung verbessert werden kann, da das resultierende Modell eine kleinere Anzahl von Tabellen mit logisch gruppierten Spalten aufweist.
Viele-zu-viele-Beziehungen erfordern Modelle auf der Kompatibilitätsebene 1500 oder höher. Sie können m:n-Beziehungen erstellen, indem Sie Visual Studio 2019 mit dem VSIX-Update 2.9.2 oder höher für Analysis Services-Projekte, das Tabular Object Model (TOM) API, die Tabular Model Scripting Language (TMSL) und das Open-Source-Tool "Tabular Editor" verwenden.
Speichereinstellungen für die Ressourcenverwaltung
Die folgenden Eigenschafteneinstellungen bieten eine verbesserte Ressourcengovernance:
- Memory\QueryMemoryLimit – Diese Speichereigenschaft kann verwendet werden, um Arbeitsspeicherpools einzuschränken, die von an das Modell übermittelten DAX-Abfragen erstellt wurden.
- DbpropMsmdRequestMemoryLimit – Diese XMLA-Eigenschaft kann verwendet werden, um den Servereigenschaftswert "Memory\QueryMemoryLimit" für eine Verbindung außer Kraft zu setzen.
- OLAP\Query\RowsetSerializationLimit – Diese Servereigenschaft beschränkt die Anzahl der zeilen, die in einem Rowset zurückgegeben werden, und schützt Serverressourcen vor einer umfangreichen Datenexportverwendung. Diese Eigenschaft gilt sowohl für DAX- als auch für MDX-Abfragen.
Diese Eigenschaften können mithilfe der neuesten Version von SQL Server Management Studio (SSMS) festgelegt werden. Diese Einstellungen sind bereits für Azure Analysis Services verfügbar.
Veraltete Features in SSAS 2019
Es gibt keine veralteten Features, die mit dieser Version angekündigt wurden.
Nicht mehr unterstützte Features in SSAS 2019
Es gibt keine nicht mehr verfügbaren Features, die mit dieser Version angekündigt wurden.
Kompatibilitätsbrechende Änderungen in SSAS 2019
In dieser Version gibt es keine Breaking Changes.
Verhaltensänderungen in SSAS 2019
In dieser Version gibt es keine Verhaltensänderungen .
SQL Server 2017 Analysis Services
SQL Server 2017 Analysis Services sehen einige der wichtigsten Verbesserungen seit SQL Server 2012. Basierend auf dem Erfolg des Tabellarischen Modus (erstmals in SQL Server 2012 Analysis Services eingeführt) macht diese Version tabellarische Modelle leistungsstärker als je zuvor.
Der mehrdimensionale Modus und der Power Pivot für den SharePoint-Modus sind ein zentraler Bestandteil vieler Analysis Services-Implementierungen. Im Analysis Services-Produktlebenszyklus sind diese Modi reif. In dieser Version gibt es keine neuen Features für einen dieser Modi. Fehlerkorrekturen und Leistungsverbesserungen sind jedoch enthalten.
Die hier beschriebenen Features sind in SQL Server 2017 Analysis Services enthalten. Um sie jedoch nutzen zu können, müssen Sie auch die neuesten Versionen von Visual Studio mit Analysis Services-Projekten und SQL Server Management Studio (SSMS) verwenden. Analysis Services-Projekte und SSMS werden monatlich mit neuen und verbesserten Features aktualisiert, die in der Regel mit neuen Funktionen in SQL Server übereinstimmen.
Obwohl es wichtig ist, über alle neuen Features zu erfahren, ist es auch wichtig zu wissen, was in dieser Version und zukünftigen Versionen veraltet und nicht mehr unterstützt wird. Weitere Informationen finden Sie unter veraltete Features in SSAS 2017.
Sehen wir uns einige der wichtigsten neuen Features in dieser Version an.
1400 Kompatibilitätsebene für tabellarische Modelle
Um viele der hier beschriebenen neuen Features und Funktionen nutzen zu können, müssen neue oder vorhandene tabellarische Modelle auf die Kompatibilitätsstufe 1400 festgelegt oder aktualisiert werden. Modelle auf der Kompatibilitätsebene 1400 können nicht in SQL Server 2016 SP1 oder früher bereitgestellt oder auf niedrigere Kompatibilitätsstufen herabgestuft werden. Weitere Informationen finden Sie unter Kompatibilitätsebene für tabellarische Analysis Services-Modelle.
In Visual Studio können Sie beim Erstellen neuer Tabellenmodellprojekte die neue Kompatibilitätsstufe 1400 auswählen.

Um ein vorhandenes tabellarisches Modell in Visual Studio zu aktualisieren, klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf "Model.bim", und legen Sie dann in "Eigenschaften" die Eigenschaft "Kompatibilitätsebene " auf SQL Server 2017 (1400) fest.

Es ist wichtig zu beachten, nachdem Sie ein vorhandenes Modell auf 1400 aktualisiert haben, können Sie kein Downgrade durchführen. Achten Sie darauf, eine Sicherung Ihrer 1200-Modelldatenbank beizubehalten.
Moderne Datenabruf-Erfahrung
Wenn es darum geht, Daten aus Datenquellen in Ihre tabellarischen Modelle zu importieren, führt SSDT die moderne Get Data Experience für Modelle auf der Kompatibilitätsebene von 1400 ein. Dieses neue Feature basiert auf ähnlichen Funktionen in Power BI Desktop und Microsoft Excel 2016. Die moderne Benutzeroberfläche zum Abrufen von Daten bietet immense Datentransformations- und Datenmashupfunktionen mithilfe des Generators zum Abrufen von Datenabfragen und M-Ausdrücken.
Die moderne Benutzeroberfläche zum Abrufen von Daten bietet Unterstützung für eine vielzahl von Datenquellen. In Zukunft werden Updates unterstützung für noch mehr umfassen.

Dank einer leistungsstarken und intuitiven Benutzeroberfläche können Sie Ihre Daten- und Datentransformations-/Mashupfunktionen einfacher als je zuvor auswählen.
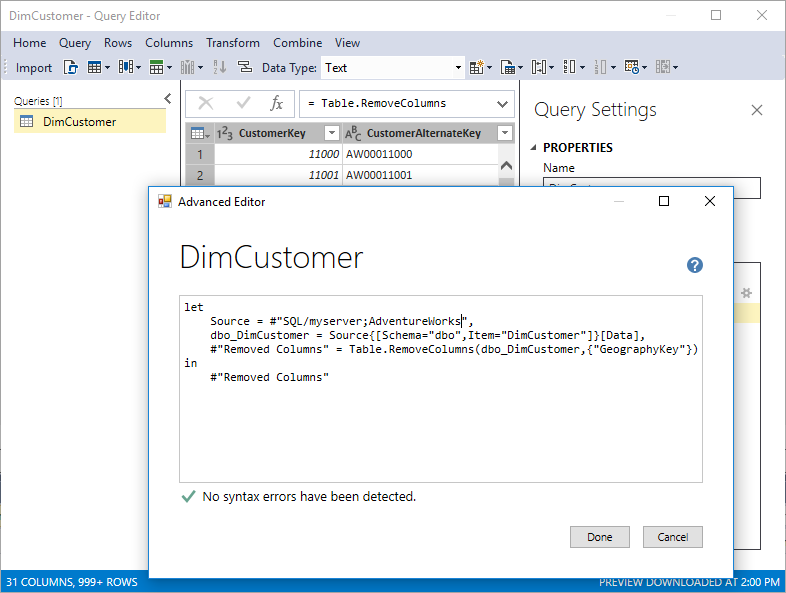
Die modernen Funktionen zum Abrufen von Daten und M-Mashup gelten nicht für vorhandene tabellarische Modelle, die von der Kompatibilitätsstufe 1200 auf 1400 aktualisiert wurden. Die neue Erfahrung gilt nur für neue Modelle, die auf der Kompatibilitätsebene 1400 erstellt wurden.
Codierungshinweise
In dieser Version werden Codierungshinweise eingeführt, ein erweitertes Feature zum Optimieren der Verarbeitung (Datenaktualisierung) großer im Arbeitsspeicher tabellarischer Modelle. Informationen zum besseren Verständnis der Codierung finden Sie im Whitepaper zur Leistungsoptimierung von tabellarischen Modellen in SQL Server 2012 Analysis Services , um die Codierung besser zu verstehen.
Die Wertcodierung bietet eine bessere Abfrageleistung für Spalten, die in der Regel nur für Aggregationen verwendet werden.
Hashcodierung wird bei Gruppierungsspalten (häufig Dimensionstabellenwerte) und Fremdschlüsseln bevorzugt. Zeichenfolgenspalten sind immer per Hash kodiert.
Numerische Spalten können eine dieser Codierungsmethoden verwenden. Wenn Analysis Services mit der Verarbeitung einer Tabelle beginnt, wenn entweder die Tabelle leer (mit oder ohne Partitionen) oder ein Vorgang für die Vollständige Tabellenverarbeitung ausgeführt wird, werden Stichprobenwerte für jede numerische Spalte verwendet, um zu bestimmen, ob Wert- oder Hashcodierung angewendet werden soll. Standardmäßig wird die Wertcodierung ausgewählt, wenn das Beispiel von unterschiedlichen Werten in der Spalte groß genug ist – andernfalls bietet die Hashcodierung normalerweise eine bessere Komprimierung. Es ist möglich, dass Analysis Services die Codierungsmethode ändern kann, nachdem die Spalte teilweise basierend auf weiteren Informationen zur Datenverteilung verarbeitet und den Codierungsprozess neu gestartet wird; Dies erhöht jedoch die Verarbeitungszeit und ist ineffizient. Das Whitepaper zur Leistungsoptimierung erläutert die erneute Codierung ausführlicher und beschreibt, wie sie mithilfe von SQL Server Profiler erkannt wird.
Mit Codierungshinweisen kann der Modellierer eine Präferenz für die Codierungsmethode angeben, basierend auf vorheriger Kenntnis aus der Datenprofilerstellung und/oder als Reaktion auf Ereignisse des erneuten Codierens von Ablaufverfolgungen. Da die Aggregation über hashcodierte Spalten langsamer als wertcodierte Spalten ist, kann die Wertcodierung als Hinweis für solche Spalten angegeben werden. Es wird nicht garantiert, dass die Präferenz angewendet wird. Es handelt sich um einen Hinweis, nicht um eine Einstellung. Um einen Codierungshinweis anzugeben, legen Sie die EncodingHint-Eigenschaft für die Spalte fest. Mögliche Werte sind "Default", "Value" und "Hash". Der folgende Codeausschnitt von JSON-basierten Metadaten aus der Datei Model.bim gibt die Wertcodierung für die Spalte "Sales Amount" an.
{
"name": "Sales Amount",
"dataType": "decimal",
"sourceColumn": "SalesAmount",
"formatString": "\\$#,0.00;(\\$#,0.00);\\$#,0.00",
"sourceProviderType": "Currency",
"encodingHint": "Value"
}
Unregelmäßige Hierarchien
In den tabellarischen Modellen können Sie Eltern-Kind-Hierarchien modellieren. Hierarchien mit einer unterschiedlichen Anzahl von Ebenen werden häufig als unregelmäßige Hierarchien bezeichnet. Standardmäßig werden unregelmäßige Hierarchien mit Leerzeichen für Ebenen unterhalb des niedrigsten untergeordneten Elements angezeigt. Hier ist ein Beispiel für eine unvollständige Hierarchie in einem Organigramm:

In dieser Version wird die Eigenschaft "Members ausblenden" eingeführt. Sie können die Eigenschaft " Elemente ausblenden" für eine Hierarchie auf " Leere Elemente ausblenden" festlegen.

Hinweis
Leere Elemente im Modell werden durch einen leeren DAX-Wert dargestellt, keine leere Zeichenfolge.
Wenn dieser Wert auf " Leere Elemente ausblenden" und das bereitgestellte Modell festgelegt ist, wird eine einfacher zu lesende Version der Hierarchie in Berichtsclients wie Excel angezeigt.

Detailzeilen
Sie können jetzt einen benutzerdefinierten Zeilensatz definieren, der zu einem Messwert beiträgt. Detail-Zeilen ähneln der standardmäßigen Drillthrough-Aktion in mehrdimensionalen Modellen. Auf diese Weise können Endbenutzer Informationen ausführlicher anzeigen als die aggregierte Ebene.
Die folgende Pivot-Tabelle zeigt den Gesamtumsatz im Internet nach Jahr gemäß dem Adventure Works-Beispiel Tabellenmodell. Sie können mit der rechten Maustaste auf eine Zelle mit einem aggregierten Wert aus dem Measure klicken und dann auf " Details anzeigen" klicken, um die Detailzeilen anzuzeigen.

Standardmäßig werden die zugehörigen Daten in der Tabelle "Internetverkauf" angezeigt. Dieses eingeschränkte Verhalten ist für den Benutzer häufig nicht sinnvoll, da die Tabelle möglicherweise nicht über die erforderlichen Spalten verfügt, um nützliche Informationen wie Kundenname und Bestellinformationen anzuzeigen. Mit Detailzeilen können Sie eine Detailzeilenausdruck-Eigenschaft für Measures angeben.
Eigenschaft des Detailzeilen-Ausdrucks für Messwerte
Die Eigenschaft "Detail Rows Expression " für Measures ermöglicht Modellautoren das Anpassen der Spalten und Zeilen, die an den Endbenutzer zurückgegeben werden.

Die SELECTCOLUMNS DAX-Funktion wird häufig in einem Detailzeilenausdruck verwendet. Im folgenden Beispiel werden die Spalten definiert, die für Zeilen in der Tabelle "Internet Sales" im Tabellarischen Beispielmodell "Adventure Works" zurückgegeben werden sollen:
SELECTCOLUMNS(
'Internet Sales',
"Customer First Name", RELATED( Customer[Last Name]),
"Customer Last Name", RELATED( Customer[First Name]),
"Order Date", 'Internet Sales'[Order Date],
"Internet Total Sales", [Internet Total Sales]
)
Nachdem die Eigenschaft definiert und das Modell bereitgestellt wurde, wird ein benutzerdefinierter Zeilensatz zurückgegeben, wenn der Benutzer " Details anzeigen" auswählt. Er berücksichtigt automatisch den Filterkontext der zelle, die ausgewählt wurde. In diesem Beispiel werden nur die Zeilen für den Wert 2010 angezeigt:

Standardeigenschaft für Detailzeilenausdruck für Tabellen
Zusätzlich zu Maße verfügen Tabellen auch über eine Eigenschaft zum Definieren eines Ausdrucks für Detailzeilen. Die Standardeigenschaft für den Ausdruck von Detailzeilen fungiert als Standardwert für alle Messgrößen innerhalb der Tabelle. Measures, die keinen eigenen Ausdruck definiert haben, erben den Ausdruck aus der Tabelle und zeigen den für die Tabelle definierten Zeilensatz an. Dies ermöglicht die Wiederverwendung von Ausdrücken, und wenn später neue Maßnahmen der Tabelle hinzugefügt werden, erben sie den Ausdruck automatisch.

DETAILROWS DAX-Funktion
In dieser Version ist eine neue DETAILROWS DAX-Funktion enthalten, die den durch den Ausdruck der Detailzeilen definierten Zeilensatz zurückgibt. Es funktioniert ähnlich wie die DRILLTHROUGH Anweisung in MDX, die auch mit Detailzeilenausdrücken kompatibel ist, die in tabellarischen Modellen definiert sind.
Die folgende DAX-Abfrage gibt die Zeilenmenge zurück, die durch den ausgedrückten Detailzeilenausdruck für die Maßnahme oder deren Tabelle definiert wurde. Wenn kein Ausdruck definiert ist, werden die Daten der Tabelle "Internet Sales" zurückgegeben, da es sich um die Tabelle handelt, die den Messwert enthält.
EVALUATE DETAILROWS([Internet Total Sales])
Sicherheit auf Objektebene
In dieser Version wird die Sicherheit auf Objektebene für Tabellen und Spalten eingeführt. Zusätzlich zum Einschränken des Zugriffs auf Tabellen- und Spaltendaten können vertrauliche Tabellen- und Spaltennamen gesichert werden. Dadurch wird verhindert, dass ein böswilliger Benutzer eine solche Tabelle erkennt.
Die Sicherheit auf Objektebene muss mithilfe der JSON-basierten Metadaten, der Skriptsprache für tabellarische Modelle (TABSL) oder des Tabellarischen Objektmodells (TOM) festgelegt werden.
Mit dem folgenden Code wird beispielsweise die Tabelle "Product" im tabellarischen Beispielmodell "Adventure Works" gesichert, indem die MetadataPermission-Eigenschaft der TablePermission-Klasse auf "None" festgelegt wird.
//Find the Users role in Adventure Works and secure the Product table
ModelRole role = db.Model.Roles.Find("Users");
Table productTable = db.Model.Tables.Find("Product");
if (role != null && productTable != null)
{
TablePermission tablePermission;
if (role.TablePermissions.Contains(productTable.Name))
{
tablePermission = role.TablePermissions[productTable.Name];
}
else
{
tablePermission = new TablePermission();
role.TablePermissions.Add(tablePermission);
tablePermission.Table = productTable;
}
tablePermission.MetadataPermission = MetadataPermission.None;
}
db.Update(UpdateOptions.ExpandFull);
Dynamische Verwaltungsansichten (Dynamic Management Views, DMVs)
DMVs sind Abfragen in SQL Server Profiler, die Informationen zu lokalen Servervorgängen und Serverintegrität zurückgeben. Diese Version enthält Verbesserungen an dynamischen Verwaltungsansichten (DMV) für tabellarische Modelle auf den Kompatibilitätsstufen 1200 und 1400.
DISCOVER_CALC_DEPENDENCY Funktioniert jetzt mit tabellarischen Modellen ab Version 1200 und höher. Tabellarische 1400- und höhere Modelle zeigen Abhängigkeiten zwischen M-Partitionen, M-Ausdrücken und strukturierten Datenquellen an. Weitere Informationen finden Sie im Analysis Services-Blog.
MDSCHEMA_MEASUREGROUP_DIMENSIONS Verbesserungen sind für diesen DMV enthalten, der von verschiedenen Clienttools verwendet wird, um die Maßdimensionalität anzuzeigen. Das Feature "Durchsuchen" in Excel-Pivot-Tabellen ermöglicht es dem Benutzer, z. B. einen Drilldown zu Dimensionen im Zusammenhang mit den ausgewählten Kennzahlen auszuführen. Diese Version korrigiert die Kardinalitätsspalten, die zuvor falsche Werte anzeigten.
DAX-Verbesserungen
Einer der wichtigsten Teile der neuen DAX-Funktionalität ist die neue IN-Operator/CONTAINSROW-Funktion für DAX-Ausdrücke. Dieser ähnelt dem TSQL IN-Operator, der häufig verwendet wird, um mehrere Werte in einer WHERE-Klausel anzugeben.
Bisher war es üblich, mithilfe des logischen OR Operators mehrfachwertige Filter anzugeben, z. B. im folgenden Measureausdruck:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
'Product'[Color] = "Red"
|| 'Product'[Color] = "Blue"
|| 'Product'[Color] = "Black"
)
Dies wird mit dem IN Operator vereinfacht:
Filtered Sales:=CALCULATE (
[Internet Total Sales], 'Product'[Color] IN { "Red", "Blue", "Black" }
)
In diesem Fall bezieht sich der IN Operator auf eine einspaltige Tabelle mit 3 Zeilen; eine für jede der angegebenen Farben. Beachten Sie, dass die Tabellenkonstruktorsyntax geschweifte Klammern verwendet.
Der IN Operator ist funktionell gleichbedeutend mit der CONTAINSROW Funktion:
Filtered Sales:=CALCULATE (
[Internet Total Sales], CONTAINSROW({ "Red", "Blue", "Black" }, 'Product'[Color])
)
Der IN Operator kann auch effektiv mit Tabellenkonstruktoren verwendet werden. Zum Beispiel filtert das folgende Maß nach Kombinationen aus Produktfarbe und Kategorie:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
( 'Product'[Color] = "Red" && Product[Product Category Name] = "Accessories" )
|| ( 'Product'[Color] = "Blue" && Product[Product Category Name] = "Bikes" )
|| ( 'Product'[Color] = "Black" && Product[Product Category Name] = "Clothing" )
)
)
Mit dem neuen IN Operator entspricht der obige Measureausdruck nun dem folgenden:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
('Product'[Color], Product[Product Category Name]) IN
{ ( "Red", "Accessories" ), ( "Blue", "Bikes" ), ( "Black", "Clothing" ) }
)
)
Weitere Verbesserungen
Zusätzlich zu allen neuen Features umfassen Analysis Services, SSDT und SSMS auch die folgenden Verbesserungen:
- Hierarchie und Spaltenwiederverwendung werden an hilfreicheren Stellen in der Power BI-Feldliste angezeigt.
- Datumsbeziehungen zur einfachen Erstellung von Beziehungen zu Datumsdimensionen auf Grundlage von Datumsfeldern.
- Die Standardinstallationsoption für Analysis Services ist jetzt für den tabellarischen Modus vorgesehen.
- Neue Datenquellen zum Abrufen von Daten (Power Query).
- DAX-Editor für SSDT.
- Vorhandene DirectQuery-Datenquellen unterstützen M-Abfragen.
- SSMS-Verbesserungen, z. B. Anzeigen, Bearbeiten und Skriptunterstützung für strukturierte Datenquellen.
Veraltete Features in SSAS 2017
Die folgenden Features sind in dieser Version veraltet :
| Modus/Kategorie | Merkmal |
|---|---|
| Mehrdimensional | Datenanalyse |
| Mehrdimensional | Verknüpfte Remote-Maßgruppen |
| Tabellarisch | Modelle auf der Kompatibilitätsebene 1100 und 1103 |
| Tabellarisch | Eigenschaften des tabellarischen Objektmodells - Column.TableDetailPosition, Column.IsDefaultLabel, Column.IsDefaultImage |
| Werkzeuge | SQL Server Profiler für die Ablaufverfolgungserfassung Der Ersatz besteht darin, den in SQL Server Management Studio eingebetteten Profiler für erweiterte Ereignisse zu verwenden. Siehe Überwachung von Analysis Services mit SQL Server Extended Events. |
| Werkzeuge | Server-Profil-Tool für Ablaufverfolgungswiedergabe Ersatz. Es gibt keinen Ersatz. |
| Ablaufverfolgungsverwaltungsobjekte und Ablaufverfolgungs-APIs | Microsoft.AnalysisServices.Trace-Objekte (enthält die APIs für Analysis Services Trace- und Replay-Objekte). Der Austausch ist mehrteilig: - Ablaufverfolgungskonfiguration: Microsoft.SqlServer.Management.XEvent - Ablaufverfolgungslesevorgang: Microsoft.SqlServer.XEvent.Linq - Ablaufverfolgungswiedergabe: Keine |
Nicht mehr unterstützte Features in SSAS 2017
Die folgenden Features werden in dieser Version nicht mehr unterstützt :
| Modus/Kategorie | Merkmal |
|---|---|
| Tabellarisch | Der Wert der VertiPaqPagingPolicy-Speichereigenschaft (2) ermöglicht das Auslagern auf den Datenträger mithilfe von speicherabbildbasierten Dateien. |
| Mehrdimensional | Remotepartitionen |
| Mehrdimensional | Verknüpfte Remote-Maßgruppen |
| Mehrdimensional | Dimensionaler Rückschreibvorgang |
| Mehrdimensional | Verknüpfte Dimensionen |
Einschneidende Änderungen in SSAS 2017
In dieser Version gibt es keine Breaking Changes.
Verhaltensänderungen in SSAS 2017
Änderungen an MDSCHEMA_MEASUREGROUP_DIMENSIONS und DISCOVER_CALC_DEPENDENCY, die in der Ankündigung Was ist neu in SQL Server 2017 CTP 2.1 für Analysis Services beschrieben sind.
SQL Server 2016 Analysis Services
SQL Server 2016 Analysis Services umfasst viele neue Verbesserungen, die eine verbesserte Leistung, einfachere Lösungserstellung, automatisierte Datenbankverwaltung, erweiterte Beziehungen mit bidirektionaler Kreuzfilterung, parallele Partitionsverarbeitung und vieles mehr bieten. Das Herzstück der meisten Verbesserungen für diese Version ist die neue Kompatibilitätsstufe 1200 für Tabellenmodelldatenbanken.
SQL Server 2016 Service Pack 1 (SP1) Analysis Services
SQL Server 2016 SP1 herunterladen
SQL Server 2016 Service SP1 Analysis Services bietet verbesserte Leistung und Skalierbarkeit durch Sensibilisierung für nicht einheitliche Speicherzugriffe (NUMA) und optimierte Speicherzuweisung basierend auf Intel Threading Building Blocks (Intel TBB). Diese neue Funktionalität trägt dazu bei, die Gesamtbetriebskosten (Total Cost of Ownership, TCO) zu senken, indem mehr Benutzer auf weniger leistungsfähigen Unternehmensservern unterstützt werden.
Insbesondere weisen die SQL Server 2016 SP1 Analysis Services-Features Verbesserungen in den folgenden Schlüsselbereichen auf:
- NUMA-Bewusstsein – Für eine bessere NUMA-Unterstützung verwaltet die In-Memory-Engine (VertiPaq) in Analysis Services jetzt eine separate Auftragswarteschlange auf jedem NUMA-Knoten. Dadurch wird sichergestellt, dass die Segmentscanaufträge auf demselben Knoten ausgeführt werden, auf dem der Speicher für die Segmentdaten zugeordnet ist. Beachten Sie, dass NUMA-Sensibilisierung nur auf Systemen mit mindestens vier NUMA-Knoten standardmäßig aktiviert ist. Bei Zwei-Knoten-Systemen rechtfertigen die Kosten für den Zugriff auf entfernt zugewiesenen Speicher in der Regel nicht den Aufwand für die Verwaltung von NUMA-Spezifika.
- Speicherzuweisung – Analysis Services wurde mit Intel Threading Building Blocks beschleunigt, einem skalierbaren Allocator, der separate Speicherpools für jeden Kern bereitstellt. Da sich die Anzahl der Kerne erhöht, kann das System fast linear skaliert werden.
- Heap-Fragmentierung – Der auf Intel TBB basierende skalierbare Allocator hilft auch, Leistungsprobleme aufgrund der Heap-Fragmentierung zu minimieren, die mit dem Windows Heap auftreten.
Leistungs- und Skalierbarkeitstests zeigten erhebliche Verbesserungen beim Abfragedurchsatz beim Ausführen von SQL Server 2016 SP1 Analysis Services auf großen Enterprise-Servern mit mehreren Knoten.
Während die meisten Verbesserungen in dieser Version spezifisch für tabellarische Modelle sind, wurden einige Verbesserungen an mehrdimensionalen Modellen vorgenommen. Beispielsweise die ROLAP-Optimierung für unterschiedliche Anzahlen für Datenquellen wie DB2 und Oracle, Drill-Through-Multiauswahlunterstützung mit Excel 2016 und Excel-Abfrageoptimierungen.
SQL Server 2016 General Availability (GA) Analysis Services
Modellierung
Verbesserte Modellierungsleistung für tabellarische 1200-Modelle
Bei tabellarischen 1200-Modellen sind Metadatenvorgänge in SSDT wesentlich schneller als tabellarische 1100- oder 1103-Modelle. Im Vergleich dazu dauert das Erstellen einer Beziehung für ein Modell, das auf die SQL Server 2014-Kompatibilitätsebene (1103) mit 23 Tabellen festgelegt ist, 3 Sekunden, während die gleiche Beziehung zu einem Modell, das auf Kompatibilitätsebene 1200 erstellt wurde, knapp eine Sekunde dauert.
Projektvorlagen für tabellarische 1200 Modelle in SSDT hinzugefügt
Mit dieser Version benötigen Sie nicht mehr zwei Versionen von SSDT zum Erstellen relationaler und BI-Projekte. SQL Server Data Tools für Visual Studio 2015 fügt Projektvorlagen für Analysis Services-Lösungen hinzu, darunter Tabellarische Analysis Services-Projekte , die zum Erstellen von Modellen auf der Kompatibilitätsebene von 1200 verwendet werden. Andere Analysis Services-Projektvorlagen für multidimensionale und Data Mining-Lösungen sind ebenfalls enthalten, aber auf derselben Funktionalen Ebene (1100 oder 1103) wie in früheren Versionen.
Anzeigen von Ordnern
Anzeigeordner sind jetzt für tabellarische 1200-Modelle verfügbar. In SQL Server-Datentools definiert und in Clientanwendungen wie Excel oder Power BI Desktop gerendert, helfen Anzeigeordnern, große Mengen von Measures in einzelnen Ordnern zu organisieren und eine visuelle Hierarchie für eine einfachere Navigation in Feldlisten hinzuzufügen.
Bidirektionale Kreuzfilterung
Neu in dieser Version ist ein integrierter Ansatz zum Aktivieren bidirektionaler Kreuzfilter in tabellarischen Modellen, wodurch die Notwendigkeit handgemachter DAX-Problemumgehungen für die Verteilung des Filterkontexts über Tabellenbeziehungen hinweg eliminiert wird. Filter werden nur automatisch generiert, wenn die Richtung mit einem hohen Maß an Sicherheit hergestellt werden kann. Wenn in Form mehrerer Abfragepfade über Tabellenbeziehungen hinweg Mehrdeutigkeit besteht, wird kein Filter automatisch erstellt. Ausführliche Informationen finden Sie unter bidirektionale Kreuzfilter für tabellarische Modelle in SQL Server 2016 Analysis Services .
Übersetzungen
Sie können jetzt übersetzte Metadaten in einem tabellarischen 1200-Modell speichern. Metadaten im Modell umfassen Felder für Kultur, übersetzte Beschriftungen und übersetzte Beschreibungen. Verwenden Sie zum Hinzufügen von Übersetzungen den Befehl "Modellübersetzungen>" in SQL Server-Datentools. Ausführliche Informationen finden Sie unter Übersetzungen in tabellarischen Modellen (Analysis Services ).
Eingefügte Tabellen
Sie können jetzt ein Tabellarisches Modell von 1100 oder 1103 auf 1200 aktualisieren, wenn das Modell eingefügte Tabellen enthält. Wir empfehlen die Verwendung von SQL Server Data Tools. Legen Sie in SSDT CompatibilityLevel auf 1200 fest, und stellen Sie dann eine SQL Server 2017-Instanz von SQL Server Analysis Services bereit. Ausführliche Informationen finden Sie unter Kompatibilitätsebene für Tabellarische Modelle in Analysis Services .
Berechnete Tabellen in SQL Server Data Tools (SSDT)
Eine berechnete Tabelle ist eine ausschließlich modellbasierte Konstruktion basierend auf einer Abfrage oder einem DAX-Ausdruck in SSDT. Wenn sie in einer Datenbank bereitgestellt wird, kann eine berechnete Tabelle nicht von regulären Tabellen unterschieden werden.
Es gibt mehrere Verwendungsmöglichkeiten für berechnete Tabellen, einschließlich der Erstellung neuer Tabellen, um eine vorhandene Tabelle in einer bestimmten Rolle verfügbar zu machen. Das klassische Beispiel ist eine Datumstabelle, die in mehreren Kontexten (Bestelldatum, Lieferdatum usw.) ausgeführt wird. Durch Erstellen einer berechneten Tabelle für eine bestimmte Rolle können Sie nun eine Tabellenbeziehung aktivieren, um Abfragen oder Dateninteraktionen mithilfe der berechneten Tabelle zu vereinfachen. Eine weitere Verwendung für berechnete Tabellen besteht darin, Teile vorhandener Tabellen in einer völlig neuen Tabelle zu kombinieren, die nur im Modell vorhanden ist. Weitere Informationen finden Sie unter Erstellen einer berechneten Tabelle .
Formelkorrektur
Bei der Formelkorrektur für ein tabellarisches 1200-Modell aktualisiert SSDT automatisch alle Measures, die auf eine Spalte oder Tabelle verweisen, die umbenannt wurde.
Unterstützung für Visual Studio-Konfigurations-Manager
Um mehrere Umgebungen wie Test- und Vorproduktionsumgebungen zu unterstützen, ermöglicht Visual Studio Entwicklern das Erstellen mehrerer Projektkonfigurationen mithilfe des Konfigurations-Managers. Multidimensionale Modelle nutzen dies bereits, aber tabellarische Modelle nutzen dies nicht. Mit dieser Version können Sie jetzt den Konfigurations-Manager verwenden, um sie auf verschiedenen Servern bereitzustellen.
Instanzverwaltung
Verwalten von Tabellarischen 1200-Modellen in SSMS
In dieser Version kann eine Analysis Services-Instanz im Tabellarischen Servermodus tabellarische Modelle auf jeder Kompatibilitätsebene ausführen (1100, 1103, 1200). Das neueste SQL Server Management Studio wird aktualisiert, um Eigenschaften anzuzeigen und datenbankmodellverwaltung für tabellarische Modelle auf 1200-Kompatibilitätsebene bereitzustellen.
Parallele Verarbeitung für mehrere Tabellenpartitionen in tabellarischen Modellen
Diese Version enthält neue Parallelverarbeitungsfunktionen für Tabellen mit zwei oder mehr Partitionen, wodurch die Verarbeitungsleistung erhöht wird. Für dieses Feature gibt es keine Konfigurationseinstellungen. Weitere Informationen zum Konfigurieren von Partitionen und Verarbeitungstabellen finden Sie unter Tabellarische Modellpartitionen.
Hinzufügen von Computerkonten als Administratoren in SSMS
SQL Server Analysis Services-Administratoren können jetzt SQL Server Management Studio verwenden, um Computerkonten als Mitglieder der SQL Server Analysis Services-Administratorgruppe zu konfigurieren. Legen Sie im Dialogfeld "Benutzer oder Gruppen auswählen " die Speicherorte für die Computerdomäne fest, und fügen Sie dann den Objekttyp "Computers" hinzu. Weitere Informationen finden Sie unter Erteilen von Serveradministratorrechten für eine Analysis Services-Instanz.
DBCC für Analysis Services
Die Datenbankkonsistenzprüfung (Database Consistency Checker, DBCC) wird intern ausgeführt, um potenzielle Datenbeschädigungsprobleme beim Laden der Datenbank zu erkennen, können aber auch bei Bedarf ausgeführt werden, wenn Sie Probleme in Ihren Daten oder Modell vermuten. DBCC führt unterschiedliche Prüfungen aus, je nachdem, ob das Modell tabellarisch oder multidimensional ist. Ausführliche Informationen finden Sie unter Database Consistency Checker (DBCC) für tabellarische und multidimensionale Analysis Services-Datenbanken .
Updates für erweiterte Ereignisse
Diese Version fügt SQL Server Management Studio eine grafische Benutzeroberfläche hinzu, um erweiterte Ereignisse von SQL Server Analysis Services zu konfigurieren und zu verwalten. Sie können Livedatenströme einrichten, um die Serveraktivität in Echtzeit zu überwachen, Sitzungsdaten im Arbeitsspeicher für eine schnellere Analyse zu laden oder Datenströme für die Offlineanalyse in einer Datei zu speichern. Weitere Informationen finden Sie unter Überwachen von Analysis Services mit den erweiterten Ereignissen von SQL Server.
Skripterstellung
PowerShell für Tabellarische Modelle
Diese Version enthält PowerShell-Verbesserungen für tabellarische Modelle auf Kompatibilitätsebene 1200. Sie können alle anwendbaren Cmdlets sowie Cmdlets verwenden, die für den tabellarischen Modus spezifisch sind: Invoke-ProcessASDatabase und Invoke-ProcessTable Cmdlet.
SSMS-Skriptdatenbankvorgänge
Im neuesten SQL Server Management Studio (SSMS) ist das Skript jetzt für Datenbankbefehle aktiviert, einschließlich "Erstellen", "Alter", "Löschen", "Sicherung", "Wiederherstellen", "Anfügen", "Trennen". Die Ausgabe ist die Tabular Model Scripting Language (TMSL) in JSON. Weitere Informationen finden Sie in der Tabular Model Scripting Language (TMSL) Reference.
Analysis Services führen DDL-Aufgabe aus
Analysis Services Execute DDL Task akzeptiert jetzt auch Tabular Model Scripting Language (TMSL)-Befehle.
SSAS PowerShell-Cmdlet
SSAS PowerShell-Cmdlet Invoke-ASCmd akzeptiert jetzt Befehle der Tabular Modell-Skriptsprachen (TMSL). Andere SSAS PowerShell-Cmdlets können in einer zukünftigen Version aktualisiert werden, um die neuen tabellarischen Metadaten zu verwenden (Ausnahmen werden in den Versionshinweisen aufgerufen). Details finden Sie in der PowerShell-Referenz zu Analysis Services.
Tabulare Modellsprache zum Skripting (TMSL) unterstützt in SSMS
Mit der neuesten Version von SSMS können Sie jetzt Skripts erstellen, um die meisten administrativen Aufgaben für tabellarische 1200-Modelle zu automatisieren. Derzeit können die folgenden Aufgaben skripted werden: Prozess auf jeder Ebene sowie CREATE, ALTER, DELETE auf Datenbankebene.
Funktionell entspricht TMSL der XMLA ASSL-Erweiterung, die multidimensionale Objektdefinitionen bereitstellt, mit der Ausnahme, dass TMSL systemeigene Deskriptoren wie Modell, Tabelle und Beziehung verwendet, um tabellarische Metadaten zu beschreiben. Ausführliche Informationen zum Schema finden Sie in der Referenz zum Tabular Model Scripting Language (TMSL).
Ein generiertes JSON-basiertes Skript für ein tabellarisches Modell könnte wie folgt aussehen:
{
"create": {
"database": {
"name": "AdventureWorksTabular1200",
"id": "AdventureWorksTabular1200",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
}
}
Die Nutzlast ist ein JSON-Dokument, das genauso minimal sein kann wie das oben gezeigte Beispiel oder reichhaltig ergänzt mit dem vollständigen Satz von Objektdefinitionen. Tabular Model Scripting Language (TMSL)-Referenz beschreibt die Syntax.
Auf Datenbankebene geben CREATE-, ALTER- und DELETE-Befehle das TMSL-Skript im vertrauten XMLA-Fenster aus. Andere Befehle, z. B. "Prozess", können auch in dieser Version skriptiert werden. Die Skriptunterstützung für viele andere Aktionen kann in einer zukünftigen Version hinzugefügt werden.
| Skriptfähige Befehle | Beschreibung |
|---|---|
| erschaffen | Fügt eine Datenbank, Verbindung oder Partition hinzu. Das ASSL-Äquivalent ist CREATE. |
| erstellenOderErsetzen | Aktualisiert eine vorhandene Objektdefinition (Datenbank, Verbindung oder Partition), indem eine frühere Version überschrieben wird. Das ASSL-Äquivalent ist ALTER, wobei AllowOverwrite auf "true" und "ObjectDefinition" auf "ExpandFull" festgelegt ist. |
| löschen | Entfernt eine Objektdefinition. Die ASSL-Entsprechung ist "DELETE". |
| Aktualisieren | Verarbeitet das Objekt. ASSL-Entsprechung ist PROCESS. |
DAX
Verbesserte DAX-Formelbearbeitung
Aktualisierungen der Bearbeitungsleiste helfen Ihnen, Formeln einfacher zu schreiben, indem Sie Funktionen, Felder und Measures mithilfe von Syntaxfarben unterscheiden, sie stellt intelligente Funktions- und Feldvorschläge bereit und teilt Ihnen mit, ob Teile Des DAX-Ausdrucks mit Fehlersquiggles falsch sind. Außerdem können Sie mehrere Zeilen (Alt + Eingabetaste) und einen Tabulator (Tab) verwenden. In der Bearbeitungsleiste können Sie jetzt auch Kommentare als Teil Ihrer Maßeinheiten schreiben, Sie müssen nur "//" eingeben, und alles, was nach diesen Zeichen in derselben Zeile steht, wird als Kommentar angesehen.
DAX-Variablen
Diese Version enthält jetzt Unterstützung für Variablen in DAX. Variablen können nun das Ergebnis eines Ausdrucks als benannte Variable speichern, die dann als Argument an andere Measureausdrücke übergeben werden kann. Nachdem resultierende Werte für einen Variablenausdruck berechnet wurden, ändern sich diese Werte nicht, auch wenn auf die Variable in einem anderen Ausdruck verwiesen wird. Weitere Informationen finden Sie unter VAR-Funktion.
Neue DAX-Funktionen
Mit dieser Version führt DAX über fünfzig neue Funktionen ein, um schnellere Berechnungen und verbesserte Visualisierungen in Power BI zu unterstützen. Weitere Informationen finden Sie unter "Neue DAX-Funktionen".
Unvollständige Messungen speichern
Sie können jetzt unvollständige DAX-Maßnahmen direkt in einem Tabular-1200-Modellprojekt speichern und sie wieder aufnehmen, wenn Sie bereit sind, mit der Arbeit fortzufahren.
Zusätzliche DAX-Verbesserungen
- Berechnung ohne leere Werte – Reduziert die Anzahl der Scans, die für leere Werte erforderlich ist.
- Measure Fusion - Mehrere Messwerte aus derselben Tabelle werden in einer einzigen Speicher-Engine-Abfrage kombiniert.
- Gruppierungsschemas – Wenn eine Abfrage nach Kennzahlen mit mehreren Granularitäten (Gesamtsumme/Jahr/Monat) fragt, wird eine einzelne Abfrage auf der niedrigsten Ebene gesendet, und die restlichen Granularitäten werden von dieser niedrigsten Ebene abgeleitet.
- Redundante Verknüpfungsabscheidung – Eine einzelne Abfrage des Speichermoduls gibt sowohl die Dimensionsspalten als auch die Messwerte zurück.
- Strenge Auswertung von IF/SWITCH – Eine Verzweigung, deren Bedingung falsch ist, wird nicht mehr zu Speicher-Engine-Abfragen führen. Zuvor wurden Zweige eifrig ausgewertet, aber die Ergebnisse wurden später verworfen.
Entwickler
Microsoft.AnalysisServices.Tabular-Namensraum für die Programmierbarkeit von Tabular 1200 in AMO
Analysis Services Management Objects (AMO) wird aktualisiert, um einen neuen tabellarischen Namespace für die Verwaltung einer Instanz des Tabellarischen Modus von SQL Server 2016 Analysis Services sowie die Datendefinitionssprache zum programmgesteuerten Erstellen oder Ändern von tabellarischen 1200-Modellen bereitzustellen. Besuchen Sie Microsoft.AnalysisServices.Tabular , um sich über die API zu informieren.
Updates für Analysis Services Management Objects (AMO)
Analysis Services Management Objects (AMO) wurde umgestaltet, um eine zweite Assembly, Microsoft.AnalysisServices.Core.dll, einzuschließen. Die neue Assembly trennt allgemeine Klassen wie Server, Datenbank und Rolle, die eine breite Anwendung in Analysis Services haben, unabhängig vom Servermodus. Zuvor waren diese Klassen Teil der ursprünglichen Microsoft.AnalysisServices-Assembly. Wenn Sie sie in eine neue Assembly verschieben, wird der Weg für zukünftige Erweiterungen auf AMO mit klarer Aufteilung zwischen generischen und kontextspezifischen APIs geebnet. Vorhandene Anwendungen sind von den neuen Assemblys nicht betroffen. Wenn Sie sich jedoch entscheiden, Anwendungen mithilfe der neuen AMO-Assembly aus irgendeinem Grund neu zu erstellen, müssen Sie unbedingt einen Verweis auf Microsoft.AnalysisServices.Core hinzufügen. Ebenso müssen PowerShell-Skripts, die AMO laden und aufrufen, jetzt Microsoft.AnalysisServices.Core.dllladen. Achten Sie darauf, alle Skripts zu aktualisieren.
JSON-Editor für BIM-Dateien
Die Codeansicht in Visual Studio 2015 rendert nun die BIM-Datei im JSON-Format für tabellarische 1200-Modelle. Die Version von Visual Studio bestimmt, ob die BIM-Datei über den integrierten JSON-Editor oder als einfacher Text in JSON gerendert wird.
Um den JSON-Editor zu verwenden, benötigen Sie mit der Möglichkeit, Abschnitte des Modells zu erweitern und zu reduzieren, die neueste Version von SQL Server Data Tools plus Visual Studio 2015 (jede Edition, einschließlich der kostenlosen Community-Edition). Für alle anderen Versionen von SSDT oder Visual Studio wird die BIM-Datei in JSON als einfacher Text gerendert. Mindestens ein leeres Modell enthält den folgenden JSON-Code:
{
"name": "SemanticModel",
"id": "SemanticModel",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
Warnung
Vermeiden Sie die direkte Bearbeitung des JSON-Codes. Dadurch kann das Modell beschädigt werden.
Neue Elemente im MS-CSDLBI 2.0-Schema
Die folgenden Elemente wurden dem komplexen TProperty-Typ hinzugefügt, der im [MS-CSDLBI] 2.0-Schema definiert ist:
| Element | Definition |
|---|---|
| Standardwert | Eine Eigenschaft, die den Wert angibt, der beim Auswerten der Abfrage verwendet wird. Die DefaultValue-Eigenschaft ist optional, wird aber automatisch ausgewählt, wenn die Werte aus dem Element nicht aggregiert werden können. |
| Statistik | Eine Reihe von Statistiken aus den zugrunde liegenden Daten, die der Spalte zugeordnet sind. Diese Statistiken werden vom komplexen Typ "TPropertyStatistics" definiert und werden nur bereitgestellt, wenn sie nicht rechenintensiv zu generieren sind, wie in Abschnitt 2.1.1.13.5 des Dokuments "Conceptual Schema Definition File Format with Business Intelligence Annotations" beschrieben. |
Direktabfrage
Neue DirectQuery-Implementierung
Diese Version sieht erhebliche Verbesserungen in DirectQuery für tabellarische 1200-Modelle. Dies ist eine Zusammenfassung:
- DirectQuery generiert jetzt einfachere Abfragen, die eine bessere Leistung bieten.
- Zusätzliche Kontrolle über das Definieren von Beispieldatensätzen, die für Modelldesign und Tests verwendet werden.
- Die Sicherheit auf Zeilenebene (Row Level Security, RLS) wird jetzt für tabellarische 1200er-Modelle im DirectQuery-Modus unterstützt. Zuvor verhinderte das Vorhandensein von RLS die Bereitstellung eines tabellarischen Modells im DirectQuery-Modus.
- Berechnete Spalten werden jetzt für tabellarische 1200-Modelle im DirectQuery-Modus unterstützt. Zuvor verhinderte das Vorhandensein berechneter Spalten die Bereitstellung eines tabellarischen Modells im DirectQuery-Modus.
- Leistungsoptimierungen umfassen redundante Join-Eliminierung für VertiPaq und DirectQuery.
Neue Datenquellen für den DirectQuery-Modus
Datenquellen, die für tabellarische 1200-Modelle im DirectQuery-Modus unterstützt werden, umfassen jetzt Oracle, Teradata und Microsoft Analytics Platform (früher als Parallel Data Warehouse bezeichnet). Weitere Informationen finden Sie im DirectQuery-Modus.
Veraltete Features in SSAS 2016
Die folgenden Features sind in dieser Version veraltet :
| Modus/Kategorie | Merkmal |
|---|---|
| Mehrdimensional | Remotepartitionen |
| Mehrdimensional | Verknüpfte Remote-Maßgruppen |
| Mehrdimensional | Dimensionaler Rückschreibvorgang |
| Mehrdimensional | Verknüpfte Dimensionen |
| Mehrdimensional | SQL Server-Tabellenbenachrichtigungen für proaktive Zwischenspeicherung. Der Ersatz besteht darin, abfragen für proaktives Zwischenspeichern zu verwenden. Siehe proaktives Zwischenspeichern (Dimensionen) und proaktives Zwischenspeichern (Partitionen). |
| Mehrdimensional | Sitzungswürfel. Es gibt keinen Ersatz. |
| Mehrdimensional | Lokale Würfel. Es gibt keinen Ersatz. |
| Tabellarisch | Tabellenmodell-Kompatibilitätsstufen 1100 und 1103 werden in einer zukünftigen Version nicht unterstützt. Der Ersatz besteht darin, Modelle auf Kompatibilitätsebene 1200 oder höher festzulegen und Modelldefinitionen in tabellarische Metadaten zu konvertieren. Siehe Kompatibilitätsebene für Tabellarische Modelle in Analysis Services. |
| Werkzeuge | SQL Server Profiler für die Ablaufverfolgungserfassung Der Ersatz besteht darin, den in SQL Server Management Studio eingebetteten Profiler für erweiterte Ereignisse zu verwenden. Siehe Überwachung von Analysis Services mit SQL Server Extended Events. |
| Werkzeuge | Server-Profil-Tool für Ablaufverfolgungswiedergabe Ersatz. Es gibt keinen Ersatz. |
| Ablaufverfolgungsverwaltungsobjekte und Ablaufverfolgungs-APIs | Microsoft.AnalysisServices.Trace-Objekte (enthält die APIs für Analysis Services Trace- und Replay-Objekte). Der Austausch ist mehrteilig: - Ablaufverfolgungskonfiguration: Microsoft.SqlServer.Management.XEvent - Ablaufverfolgungslesevorgang: Microsoft.SqlServer.XEvent.Linq - Ablaufverfolgungswiedergabe: Keine |
Nicht mehr unterstützte Features in SSAS 2016
Die folgenden Features werden in dieser Version nicht mehr unterstützt :
| Merkmal | Alternative oder Problemumgehung |
|---|---|
| CalculationPassValue (MDX) | Keiner. Dieses Feature wurde in SQL Server 2005 nicht mehr unterstützt. |
| CalculationCurrentPass (MDX) | Keiner. Dieses Feature wurde in SQL Server 2005 nicht mehr unterstützt. |
| NON_EMPTY_BEHAVIOR Abfrageoptimiererhinweis | Keiner. Dieses Feature wurde in SQL Server 2008 nicht mehr unterstützt. |
| COM Assemblies | Keiner. Dieses Feature wurde in SQL Server 2008 nicht mehr unterstützt. |
| CELL_EVALUATION_LIST intrinsische Zelleigenschaft | Keiner. Dieses Feature wurde in SQL Server 2005 nicht mehr unterstützt. |
Unterbrechen von Änderungen in SSAS 2016
.NET 4.0-Versionsupgrade
Analysis Services Management Objects (AMO), ADOMD.NET und Tabular Object Model (TOM)-Clientbibliotheken zielen jetzt auf die .NET 4.0-Laufzeit ab. Dies kann eine bahnbrechende Änderung für Anwendungen sein, die auf .NET 3.5 abzielen. Anwendungen, die neuere Versionen dieser Assemblys verwenden, müssen jetzt auf .NET 4.0 oder höher abzielen.
Aktualisierung der AMO-Version
Diese Version ist ein Versionsupgrade für Analysis Services Management Objects (AMO) und ist eine bahnbrechende Änderung unter bestimmten Umständen. Vorhandener Code und Skripts, der in AMO aufgerufen wird, werden weiterhin wie zuvor ausgeführt, wenn Sie ein Upgrade von einer früheren Version durchführen. Wenn Sie Ihre Anwendung jedoch neu kompilieren müssen und auf eine SQL Server 2016 Analysis Services-Instanz abzielen, müssen Sie den folgenden Namespace hinzufügen, um Ihren Code oder Ihr Skript betriebsbereit zu machen:
using Microsoft.AnalysisServices;
using Microsoft.AnalysisServices.Core;
Der Microsoft.AnalysisServices.Core-Namespace ist jetzt erforderlich, wenn Sie in Ihrem Code auf die Microsoft.AnalysisServices-Assembly verweisen. Objekte, die zuvor nur im Microsoft.AnalysisServices-Namespace waren, werden in dieser Version in den Core-Namespace verschoben, wenn das Objekt in tabellarischen und multidimensionalen Szenarien auf die gleiche Weise verwendet wird. Serverbezogene APIs werden beispielsweise in den Core-Namespace verschoben.
Obwohl es jetzt mehrere Namespaces gibt, sind beide in derselben Assembly vorhanden (Microsoft.AnalysisServices.dll).
XEvent DISCOVER-Änderungen
Um das XEvent DISCOVER-Streaming in SSMS für SQL Server 2016 Analysis Services besser zu unterstützen, DISCOVER_XEVENT_TRACE_DEFINITION wird durch die folgenden XEvent-Ablaufverfolgungen ersetzt:
DISCOVER_XEVENT_PACKAGES
DISCOVER_XEVENT_OBJECT
DISCOVER_XEVENT_OBJECT_COLUMNS
DISCOVER_XEVENT_SESSION_TARGETS
Verhaltensänderungen in SSAS 2016
Analysis Services im SharePoint-Modus
Das Ausführen des Power Pivot-Konfigurations-Assistenten ist nicht mehr als Aufgabe nach der Installation erforderlich. Dies gilt für alle unterstützten Versionen von SharePoint, die Modelle aus den aktuellen SQL Server 2016 Analysis Services laden.
DirectQuery-Modus für Tabellarische Modelle
DirectQuery ist ein Datenzugriffsmodus für tabellarische Modelle, in dem die Abfrageausführung in einer relationalen Back-End-Datenbank ausgeführt wird und ein Resultset in Echtzeit abgerufen wird. Es wird häufig für sehr große Datasets verwendet, die nicht in den Arbeitsspeicher passen können oder wenn Daten veränderlich sind und die neuesten Daten in Abfragen für ein tabellarisches Modell zurückgegeben werden sollen.
DirectQuery ist als Datenzugriffsmodus für die letzten Versionen vorhanden. In SQL Server 2016 Analysis Services wurde die Implementierung leicht überarbeitet, vorausgesetzt, das tabellarische Modell liegt auf Kompatibilitätsebene 1200 oder höher. DirectQuery hat weniger Einschränkungen als zuvor. Außerdem gibt es unterschiedliche Datenbankeigenschaften.
Wenn Sie DirectQuery in einem vorhandenen tabellarischen Modell verwenden, können Sie das Modell auf der aktuellen Kompatibilitätsebene von 1100 oder 1103 beibehalten und DirectQuery weiterhin als implementiert für diese Ebenen verwenden. Alternativ können Sie ein Upgrade auf 1200 oder höher durchführen, um von Verbesserungen zu profitieren, die an DirectQuery vorgenommen wurden.
Es gibt kein direktes Upgrade eines DirectQuery-Modells, da die Einstellungen von älteren Kompatibilitätsstufen keine genauen Entsprechungen in den neueren 1200 und höheren Kompatibilitätsstufen aufweisen. Wenn Sie über ein tabellarisches Modell verfügen, das im DirectQuery-Modus ausgeführt wird, sollten Sie das Modell in SQL Server-Datentools öffnen, DirectQuery deaktivieren, die Kompatibilitätsebeneneigenschaft auf 1200 oder höher festlegen und dann die DirectQuery-Eigenschaften neu konfigurieren. Details finden Sie im DirectQuery-Modus .
Definitionen
Ein veraltetes Feature wird in einer zukünftigen Version vom Produkt nicht mehr unterstützt, wird aber weiterhin unterstützt und in der aktuellen Version enthalten, um die Abwärtskompatibilität aufrechtzuerhalten. Es wird empfohlen, die Verwendung veralteter Features in neuen und vorhandenen Projekten einzustellen, um die Kompatibilität mit zukünftigen Versionen aufrechtzuerhalten. Die Dokumentation wird für veraltete Features nicht aktualisiert.
Ein nicht mehr vorhandenes Feature wurde in einer früheren Version nicht mehr unterstützt. Es kann weiterhin in der aktuellen Version enthalten sein, wird aber nicht mehr unterstützt. Nicht mehr vorhandene Features können vollständig in der angegebenen oder zukünftigen Version entfernt werden.
Eine bahnbrechende Änderung bewirkt, dass ein Feature, ein Datenmodell, ein Anwendungscode oder ein Skript nach dem Upgrade auf die aktuelle Version nicht mehr funktioniert.
Eine Verhaltensänderung wirkt sich auf die Funktionsweise desselben Features in der aktuellen Version im Vergleich zur vorherigen Version aus. Es werden nur erhebliche Verhaltensänderungen beschrieben. Änderungen an der Benutzeroberfläche sind nicht enthalten. Änderungen an Standardwerten, manuelle Konfiguration, die erforderlich ist, um eine Upgrade- oder Wiederherstellungsfunktion abzuschließen, oder eine neue Implementierung eines vorhandenen Features sind alle Beispiele für eine Verhaltensänderung.