Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel stellen Sie eine AWS EDW-Workload in Azure bereit.
Anmelden bei Azure
Melden Sie sich mit dem
az login-Befehl bei Azure an.az loginWenn Ihr Azure-Konto über mehrere Abonnements verfügt, achten Sie darauf, das richtige Abonnement auszuwählen. Listen Sie die Namen und IDs Ihrer Abonnements mit dem Befehl
az account listauf.az account list --query "[].{id: id, name:name }" --output tableWählen Sie ein bestimmtes Abonnement mit dem Befehl
az account setaus.az account set --subscription $subscriptionId
Bereitstellungsskript für die EDW-Workload
Überprüfen Sie die Umgebungsvariablen in der Datei deployment/environmentVariables.sh und verwenden Sie dann das Skript deploy.sh im Verzeichnis deployment/infra/ des GitHub-Repositorys, um die Anwendung in Azure bereitzustellen.
Das Skript überprüft zunächst, ob alle erforderlichen Tools installiert sind. Andernfalls wird das Skript beendet und eine Fehlermeldung angezeigt, in der Sie darüber informiert werden, welche Voraussetzungen fehlen. Überprüfen Sie in diesem Fall die erforderlichen Komponenten, installieren Sie fehlende Tools, und führen Sie das Skript dann erneut aus. Das Feature-Flag NAP (Node AutoProvisioning) für AKS muss in Ihrem Azure-Abonnement registriert sein. Wenn es noch nicht registriert ist, führt das Skript einen Azure CLI-Befehl aus, um das Featureflag zu registrieren.
Das Skript zeichnet den Status der Bereitstellung in einer Datei mit dem Namen deploy.state im Verzeichnis deployment auf. Sie können diese Datei verwenden, um Umgebungsvariablen für das Bereitstellen der App festzulegen.
Wenn das Skript die Befehle ausführt, um die Infrastruktur für den Workflow zu konfigurieren, wird überprüft, ob jeder Befehl erfolgreich ausgeführt wurde. Wenn Probleme auftreten, wird eine Fehlermeldung angezeigt, und die Ausführung wird beendet.
Das Skript zeigt während der Ausführung ein Protokoll an. Sie können das Protokoll speichern, indem Sie die Ausgabe der Protokollinformationen mit den folgenden Befehlen in die Datei install.log im Verzeichnis logs umleiten:
mkdir ./logs
./deployment/infra/deploy.sh | tee ./logs/install.log
Weitere Informationen finden Sie im Skript ./deployment/infra/deploy.sh in unserem GitHub-Repository.
Workloadressourcen
Das Bereitstellungsskript erstellt die folgenden Azure-Ressourcen:
Azure-Ressourcengruppe: die Azure-Ressourcengruppe, in der die vom Bereitstellungsskript erstellten Ressourcen gespeichert werden
Azure Storage-Konto: das Azure Storage-Konto mit der Warteschlange, an die Nachrichten von der Producer-App gesendet und aus der Nachrichten von der Consumer-App gelesen werden, sowie die Tabelle, in der die Consumer-App die verarbeiteten Nachrichten speichert
Azure Container Registry: Die Containerregistrierung stellt ein Repository für den Container bereit, der den umgestalteten Consumer-App-Code bereitstellt.
AKS-Cluster (Azure Kubernetes Service): Der AKS-Cluster bietet Kubernetes-Orchestrierung für den Consumer-App-Container sowie die folgenden Features:
- NAP (Node autoprovisioning): die Implementierung der automatischen Skalierung für Karpenter-Knoten in AKS.
- KEDA (Kubernetes Event-driven Autoscaling):KEDA ermöglicht die Podskalierung basierend auf Ereignissen, z. B. das Überschreiten eines angegebenen Schwellenwerts für die Warteschlangentiefe.
- Workloadidentität: ermöglicht das Anfügen rollenbasierter Zugriffsrichtlinien an Podidentitäten für mehr Sicherheit.
- Angefügte Azure Container Registry: Mit diesem Feature kann der AKS-Cluster Images aus Repositorys in der angegebenen ACR-Instanz abrufen.
Anwendungs- und Systemknotenpool: Das Skript erstellt auch einen Anwendungs- und Systemknotenpool im AKS-Cluster, der einen Taint hat, um zu verhindern, dass Anwendungspods im Systemknotenpool geplant werden.
Verwaltete AKS-Clusteridentität: Das Skript weist dieser verwalteten Identität die Rolle
acrPullzu, wodurch der Zugriff auf die angefügte Azure Container Registry-Instanz zum Abrufen von Images vereinfacht wird.Workloadidentität: Das Skript weist die Rollen Mitwirkender an Storage-Warteschlangendaten und Mitwirkender an Speichertabellendaten zu, um mithilfe der rollenbasierten Zugriffssteuerung (RBAC) der Identität Zugriff zuzuweisen, die dem Kubernetes-Dienstkonto zugeordnet ist, das als Identität für Pods verwendet wird, in denen die Consumer-App-Container bereitgestellt werden.
Zwei Verbundanmeldeinformationen: Eine Anmeldeinformation ermöglicht der verwalteten Identität die Implementierung der Podidentität, und die anderen Anmeldeinformation wird für das Dienstkonto für KEDA-Vorgänge verwendet, um Zugriff auf den KEDA-Skalierungsanbieter zu ermöglichen und Metriken zu erfassen, die zum Steuern der automatischen Podskalierung erforderlich sind.
Überprüfen der Bereitstellung und Ausführen der Workload
Nach Abschluss des Bereitstellungsskripts können Sie die Workload im AKS-Cluster bereitstellen.
Legen Sie die Quelle zum Sammeln und Aktualisieren der Umgebungsvariablen für
./deployment/environmentVariables.shmithilfe des folgenden Befehls fest:source ./deployment/environmentVariables.shSie benötigen die Informationen aus der Datei
./deployment/deploy.state, um Umgebungsvariablen für die Namen der in der Bereitstellung erstellten Ressourcen festzulegen. Zeigen Sie den Inhalt der Datei mit dem folgenden Befehlcatan:cat ./deployment/deploy.stateDie Ausgabe sollte die folgenden Variablen enthalten:
SUFFIX= RESOURCE_GROUP= AZURE_STORAGE_ACCOUNT_NAME= AZURE_QUEUE_NAME= AZURE_COSMOSDB_TABLE= AZURE_CONTAINER_REGISTRY_NAME= AKS_MANAGED_IDENTITY_NAME= AKS_CLUSTER_NAME= WORKLOAD_MANAGED_IDENTITY_NAME= SERVICE_ACCOUNT= FEDERATED_IDENTITY_CREDENTIAL_NAME= KEDA_SERVICE_ACCT_CRED_NAME=Lesen Sie die Datei, und erstellen Sie Umgebungsvariablen für die Namen der Azure-Ressourcen, die vom Bereitstellungsskript werden, mithilfe der folgenden Befehle:
while IFS= read -r; line do \ echo "export $line" \ export $line; \ done < ./deployment/deploy.stateRufen Sie die Anmeldeinformationen des AKS-Clusters mit dem Befehl
az aks get-credentialsab.az aks get-credentials --resource-group $RESOURCE_GROUP --name $AKS_CLUSTER_NAMEÜberprüfen Sie mit dem Befehl
kube-system, ob die KEDA-Vorgangspods imkubectl get-Namespace im AKS-Cluster ausgeführt werden.kubectl get pods --namespace kube-system | grep kedaIhre Ausgabe sollte in etwa dem folgendem Beispiel entsprechen:

Generieren simulierter Lasten
Nun generieren Sie mithilfe der Producer-App simulierte Lasten, um die Warteschlange mit Nachrichten aufzufüllen.
Navigieren Sie in einem separaten Terminalfenster zum Projektverzeichnis.
Legen Sie die Umgebungsvariablen mithilfe der Schritte im vorherigen Abschnitt fest. 1. Führen Sie die Producer-App mit dem folgenden Befehl aus:
python3 ./app/keda/aqs-producer.pyWenn die App mit dem Senden von Nachrichten beginnt, wechseln Sie zurück zum anderen Terminalfenster.
Stellen Sie den Consumer-App-Container mithilfe der folgenden Befehle im AKS-Cluster bereit:
chmod +x ./deployment/keda/deploy-keda-app-workload-id.sh ./deployment/keda/deploy-keda-app-workload-id.shDas Bereitstellungsskript (
deploy-keda-app-workload-id.sh) führt die Vorlagenerstellung mit der YAML-Spezifikation des Anwendungsmanifests aus, um Umgebungsvariablen an den Pod zu übergeben. Sehen Sie sich den folgenden Auszug aus diesem Skript an:cat <<EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: $AQS_TARGET_DEPLOYMENT namespace: $AQS_TARGET_NAMESPACE spec: replicas: 1 selector: matchLabels: app: aqs-reader template: metadata: labels: app: aqs-reader azure.workload.identity/use: "true" spec: serviceAccountName: $SERVICE_ACCOUNT containers: - name: keda-queue-reader image: ${AZURE_CONTAINER_REGISTRY_NAME}.azurecr.io/aws2azure/aqs-consumer imagePullPolicy: Always env: - name: AZURE_QUEUE_NAME value: $AZURE_QUEUE_NAME - name: AZURE_STORAGE_ACCOUNT_NAME value: $AZURE_STORAGE_ACCOUNT_NAME - name: AZURE_TABLE_NAME value: $AZURE_TABLE_NAME resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" EOFDie Bezeichnung
azure.workload.identity/useim Abschnittspec/templateist die Podvorlage für die Bereitstellung. Indem Sie die Bezeichnung auftruefestlegen, geben Sie an, dass Sie die Workloadidentität verwenden. DerserviceAccountNamein der Podspezifikation gibt das Kubernetes-Dienstkonto an, das der Workloadidentität zugeordnet werden soll. Die Podspezifikation enthält zwar einen Verweis auf ein Image in einem privaten Repository, es wurde jedoch keinimagePullSecretangegeben.Überprüfen Sie mit dem Befehl
kubectl get, ob das Skript erfolgreich ausgeführt wurde.kubectl get pods --namespace $AQS_TARGET_NAMESPACEIn der Ausgabe sollte ein einzelner Pod angezeigt werden.
Vergewissern Sie sich, dass ein Karpenter-Knotenpool erstellt wurde. Verwenden Sie dazu den Befehl
kubectl get nodepool. Die Antwort des Befehls sieht so aus:
Stellen Sie mit dem Befehl
kubectl describe nodepoolsicher, dass der Standardknotenpool ein Karpenter-Knotenpool ist. In der Befehlsantwort können Sie überprüfen, ob der Knotenpool ein Karpenter-Knotenpool ist. Die Ausgabe sollte in etwa wie folgt aussehen:


Überwachen der horizontalen Skalierung für Pods und Knoten mit k9s
Sie können verschiedene Tools verwenden, um die Funktion von Apps zu überprüfen, die in AKS bereitgestellt werden, einschließlich des Azure-Portals und k9s. Weitere Informationen zu k9s finden Sie in der Übersicht über k9s.
Installieren Sie k9s in Ihrem AKS-Cluster mithilfe des entsprechenden Leitfadens für Ihre Umgebung in der Übersicht über die k9s-Installation.
Erstellen Sie zwei Fenster, eines mit einer Ansicht der Pods und ein weiteres mit einer Ansicht der Knoten im Namespace, den Sie in der Umgebungsvariable
AQS_TARGET_NAMESPACEangegeben haben (Standardwert istaqs-demo), und starten Sie k9s in beiden Fenstern.Die Anzeige sollte dem Folgenden ähneln:

Nachdem Sie sich vergewissert haben, dass der Consumer-App-Container im AKS-Cluster installiert wurden und ausgeführt wird, installieren Sie
ScaledObjectund lösen die von KEDA für die automatische Podskalierung verwendete Authentifizierung aus, indem Sie das Installationsskript für Skalierungsobjekte (keda-scaleobject-workload-id.sh) ausführen. Verwenden Sie die folgenden Befehle:chmod +x ./deployment/keda/keda-scaleobject-workload-id.sh ./deployment/keda/keda-scaleobject-workload-id.shDas Skript führt bei Bedarf auch die Vorlagenerstellung zum Einfügen von Umgebungsvariablen durch. Sehen Sie sich den folgenden Auszug aus diesem Skript an:
cat <<EOF | kubectl apply -f - apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: aws2az-queue-scaleobj namespace: ${AQS_TARGET_NAMESPACE} spec: scaleTargetRef: name: ${AQS_TARGET_DEPLOYMENT} #K8s deployement to target minReplicaCount: 0 # We don't want pods if the queue is empty nginx-deployment maxReplicaCount: 15 # We don't want to have more than 15 replicas pollingInterval: 30 # How frequently we should go for metrics (in seconds) cooldownPeriod: 10 # How many seconds should we wait for downscale triggers: - type: azure-queue authenticationRef: name: keda-az-credentials metadata: queueName: ${AZURE_QUEUE_NAME} accountName: ${AZURE_STORAGE_ACCOUNT_NAME} queueLength: '5' activationQueueLength: '20' # threshold for when the scaler is active cloud: AzurePublicCloud --- apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-az-credentials namespace: $AQS_TARGET_NAMESPACE spec: podIdentity: provider: azure-workload identityId: '${workloadManagedIdentityClientId}' EOFDas Manifest beschreibt zwei Ressourcen: das
TriggerAuthentication-Objekt, das KEDA informiert, dass das skalierte Objekt die Podidentität für die Authentifizierung verwendet, und dieidentityID-Eigenschaft, die auf die verwaltete Identität verweist, die als Workloadidentität verwendet wird.Wenn das skalierte Objekt ordnungsgemäß installiert wurde und KEDA erkennt, dass der Skalierungsschwellenwert überschritten wird, beginnt es mit der Planung von Pods. Wenn Sie k9s verwenden, sollte in etwa Folgendes angezeigt werden:

Wenn Sie zulassen, dass der Producer die Warteschlange mit ausreichend vielen Nachrichten füllt, muss KEDA möglicherweise mehr Pods planen, als Knoten für die Bereitstellung vorhanden sind. Dazu beginnt Karpenter mit der Planung von Knoten. Wenn Sie k9s verwenden, sollte in etwa Folgendes angezeigt werden:

Beachten Sie in diesen beiden Abbildung, wie die Anzahl der Knoten, deren Namen
aks-defaultenthalten, von einem auf drei Knoten steigt. Wenn Sie das Senden von Nachrichten von der Producer-App an die Warteschlange beenden, verringern die Consumer nach und nach die Warteschlangentiefe unter den Schwellenwert, und sowohl KEDA als auch Karpenter skalieren ab. Wenn Sie k9s verwenden, sollte in etwa Folgendes angezeigt werden:
Schließlich können Sie die Karpenter-Aktivität für automatische Skalierung mithilfe des Befehls
kubectl get eventsanzeigen, wie hier gezeigt: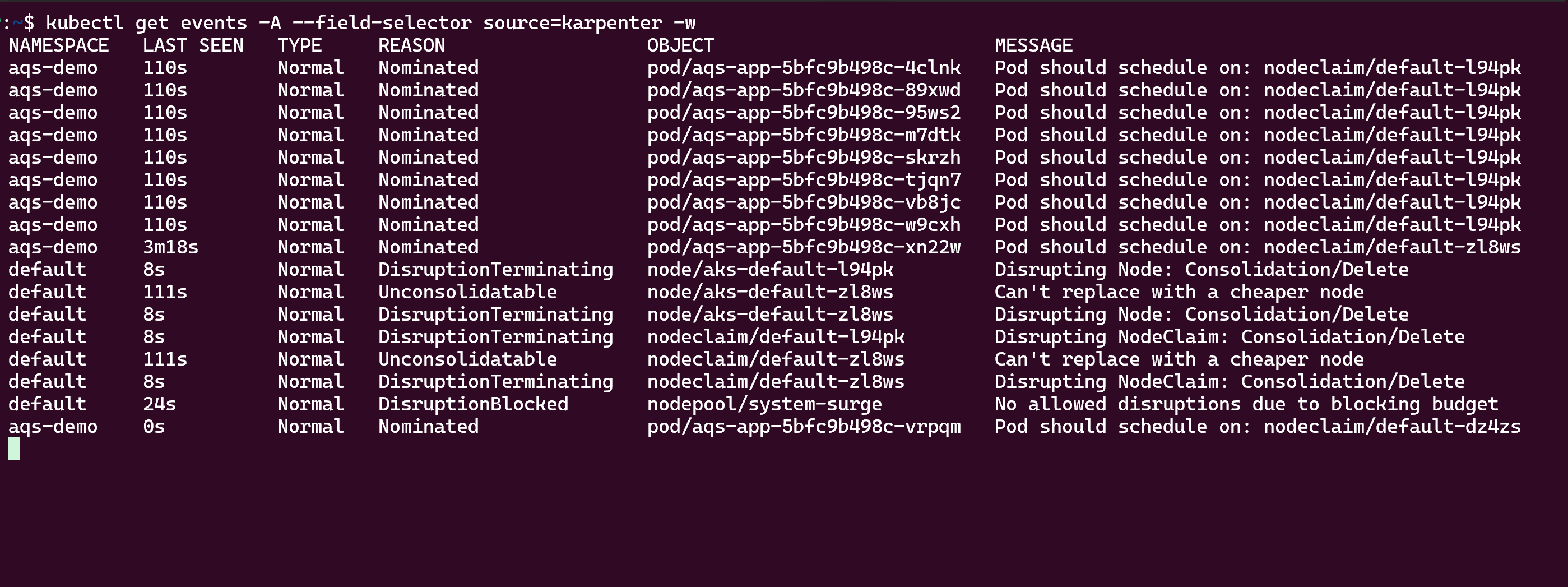





Bereinigen von Ressourcen
Sie können das Bereinigungsskript (/deployment/infra/cleanup.sh) in unserem GitHub-Repository verwenden, um alle von Ihnen erstellten Ressourcen zu entfernen.
Nächste Schritte
Weitere Informationen zum Entwickeln und Ausführen von Anwendungen in AKS finden Sie in den folgenden Ressourcen:
- Installieren vorhandener Anwendungen mit Helm in AKS
- Bereitstellen und Verwalten einer Kubernetes-Anwendung aus dem Azure Marketplace in AKS
- Bereitstellen einer Anwendung, die OpenAI verwendet, in AKS
Beitragende
Microsoft pflegt diesen Artikel. Die folgenden Mitwirkenden haben es ursprünglich geschrieben:
- Ken Kilty | Leitender TPM
- Russell de Pina | Leiter TPM
- Jennifer Hayes | Senior Content Developer
- Carol Smith | Senior Content Developer
- Erin Schaffer | Inhaltsentwickler 2