Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Monitor
Verteilte Anwendungen und Dienste, die in der Cloud ausgeführt werden, sind in ihrer Natur komplexe Softwareteile, die viele bewegliche Teile umfassen. In einer Produktionsumgebung ist es wichtig, die Art und Weise nachzuverfolgen, wie Benutzer Ihr System verwenden, die Ressourcenauslastung nachverfolgen und im Allgemeinen die Integrität und Leistung Ihres Systems überwachen können. Diese Informationen dienen als Diagnosehilfe, um Probleme zu erkennen und zu korrigieren sowie potenzielle Probleme frühzeitig zu erkennen und zu verhindern.
Überwachungs- und Diagnoseszenarien
Sie können die Überwachung verwenden, um einen Einblick in die Funktionsweise eines Systems zu erhalten. Die Überwachung ist ein wichtiger Bestandteil der Aufrechterhaltung von Qualitätszielen. Häufige Szenarien zum Sammeln von Überwachungsdaten sind:
- Sicherstellen, dass das System fehlerfrei bleibt.
- Nachverfolgen der Verfügbarkeit des Systems und der zugehörigen Komponentenelemente.
- Aufrechterhaltung der Leistung, um sicherzustellen, dass der Durchsatz des Systems nicht unerwartet beeinträchtigt wird, da das Arbeitsvolumen steigt.
- Gewährleistung, dass das System alle Vereinbarungen auf Service-Level-Vereinbarungen (SLAs) erfüllt, die mit Kunden eingerichtet wurden.
- Schutz der Privatsphäre und Sicherheit des Systems, der Benutzer und ihrer Daten.
- Nachverfolgen der Vorgänge, die für Überwachungszwecke oder behördliche Zwecke ausgeführt werden.
- Überwachung der täglichen Nutzung des Systems und Erkennen von Trends, die zu Problemen führen können, wenn sie nicht behoben werden.
- Nachverfolgen von Problemen, die auftreten, vom anfänglichen Bericht bis hin zur Analyse möglicher Ursachen, Berichtigung, konsequenter Softwareupdates und Bereitstellung.
- Ablaufverfolgungsvorgänge und Debuggen von Softwareversionen.
Hinweis
Diese Liste soll nicht umfassend sein. Dieses Dokument konzentriert sich auf diese Szenarien als die häufigsten Situationen für die Durchführung der Überwachung. Möglicherweise gibt es andere, die weniger häufig sind oder für Ihre Umgebung spezifisch sind.
In den folgenden Abschnitten werden diese Szenarien ausführlicher beschrieben. Die Informationen für jedes Szenario werden im folgenden Format erläutert:
- Eine kurze Übersicht über das Szenario.
- Die typischen Anforderungen dieses Szenarios.
- Die Rohinstrumentationsdaten, die erforderlich sind, um das Szenario zu unterstützen, und mögliche Quellen dieser Informationen.
- Wie diese Rohdaten analysiert und kombiniert werden können, um aussagekräftige Diagnoseinformationen zu generieren.
Systemüberwachung
Ein System ist gesund, wenn es läuft und in der Lage ist, Anfragen zu verarbeiten. Der Zweck der Integritätsüberwachung besteht darin, eine Momentaufnahme der aktuellen Integrität des Systems zu generieren, damit Sie überprüfen können, ob alle Komponenten des Systems erwartungsgemäß funktionieren.
Anforderungen für die Integritätsüberwachung
Ein Operator sollte schnell (innerhalb von Sekunden) benachrichtigt werden, wenn ein Teil des Systems als fehlerhaft eingestuft wird. Der Betreiber sollte feststellen können, welche Teile des Systems normal funktionieren und welche Teile Probleme haben. Die Systemintegrität kann über ein Ampelsystem hervorgehoben werden:
- Rot für ungesunde Probleme (das System wurde beendet)
- Gelb für teilweise fehlerfrei (das System wird mit eingeschränkter Funktionalität ausgeführt)
- Grün für völlig gesund
Ein umfassendes System zur Integritätsüberwachung ermöglicht es einem Operator, einen Drilldown durch das System zu durchführen, um den Integritätsstatus von Subsystemen und Komponenten anzuzeigen. Wenn z. B. das Gesamtsystem als teilweise fehlerfrei dargestellt wird, sollte der Operator in der Lage sein, zu zoomen und zu bestimmen, welche Funktionalität derzeit nicht verfügbar ist.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Die rohen Daten, die zur Unterstützung der Integritätsüberwachung erforderlich sind, können als Ergebnis generiert werden:
- Ablaufverfolgung der Ausführung von Benutzeranforderungen. Diese Informationen können verwendet werden, um zu bestimmen, welche Anforderungen erfolgreich waren, welche fehlgeschlagen sind und wie lange jede Anforderung dauert.
- Synthetische Benutzerüberwachung. Dieser Prozess simuliert die von einem Benutzer ausgeführten Schritte und folgt einer vordefinierten Reihe von Schritten. Die Ergebnisse der einzelnen Schritte sollten erfasst werden.
- Protokollierung von Ausnahmen, Fehlern und Warnungen. Diese Informationen können als Ergebnis von ablaufverfolgungsanweisungen erfasst werden, die in den Anwendungscode eingebettet sind, sowie das Abrufen von Informationen aus den Ereignisprotokollen aller Dienste, auf die das System verweist.
- Überwachen der Integrität von Drittanbieterdiensten, die das System verwendet. Diese Überwachung erfordert möglicherweise das Abrufen und Analysieren von Integritätsdaten, die diese Dienste bereitstellen. Diese Informationen können verschiedene Formate annehmen.
- Endpunktüberwachung. Dieser Mechanismus wird im Abschnitt "Verfügbarkeitsüberwachung" ausführlicher beschrieben.
- Sammeln von Umgebungsleistungsinformationen, z. B. cpu-Auslastung im Hintergrund oder E/A (einschließlich Netzwerkaktivität).
Analysieren von Integritätsdaten
Der Hauptfokus der Integritätsüberwachung besteht darin, schnell anzugeben, ob das System ausgeführt wird. Die hot analysis of the immediate data can trigger an alert if a critical component is detected as unhealthy. (Sie reagiert nicht auf eine aufeinander folgende Reihe von Pings, z. B...).) Der Betreiber kann dann die entsprechende Korrekturmaßnahme ergreifen.
Ein komplexeres System kann ein prädiktives Element enthalten, das eine kalte Analyse über aktuelle und aktuelle Workloads durchführt. Eine kalte Analyse kann Trends erkennen und bestimmen, ob das System wahrscheinlich fehlerfrei bleibt oder ob das System zusätzliche Ressourcen benötigt. Dieses prädiktive Element sollte auf kritischen Leistungsmetriken basieren, z. B.:
- Die Rate der Anforderungen, die an jeden Dienst oder Subsystem gerichtet sind.
- Die Antwortzeiten dieser Anforderungen.
- Das Datenvolumen, das in jeden Dienst fließt und aus ihnen heraus.
Wenn der Wert einer Metrik einen definierten Schwellenwert überschreitet, kann das System eine Warnung auslösen, um einen Operator oder eine automatische Skalierung (sofern verfügbar) zu aktivieren, um die präventiven Maßnahmen auszuführen, die erforderlich sind, um den Systemstatus aufrechtzuerhalten. Diese Aktionen können das Hinzufügen von Ressourcen, das Neustarten eines oder mehrerer Dienste, die fehlschlagen, oder das Anwenden einer Einschränkung auf Anforderungen mit niedrigerer Priorität umfassen.
Verfügbarkeitsüberwachung
Ein wirklich gesundes System erfordert, dass die Komponenten und Subsysteme, die das System erstellen, verfügbar sind. Die Verfügbarkeitsüberwachung ist eng mit der Integritätsüberwachung verbunden. Während die Integritätsüberwachung jedoch einen sofortigen Überblick über die aktuelle Integrität des Systems bietet, befasst sich die Verfügbarkeitsüberwachung mit der Verfolgung der Verfügbarkeit des Systems und seiner Komponenten, um Statistiken über die Betriebszeit des Systems zu generieren.
In vielen Systemen sind einige Komponenten (z. B. eine Datenbank) mit integrierter Redundanz konfiguriert, um ein schnelles Failover im Falle eines schwerwiegenden Fehlers oder Verlusts der Konnektivität zu ermöglichen. Im Idealfall sollten Benutzer nicht wissen, dass ein solcher Fehler aufgetreten ist. Aus Sicht der Verfügbarkeitsüberwachung ist es jedoch erforderlich, so viele Informationen wie möglich zu solchen Fehlern zu sammeln, um die Ursache zu ermitteln und Korrekturmaßnahmen zu ergreifen, um zu verhindern, dass sie sich wiederholen.
Die zum Nachverfolgen der Verfügbarkeit erforderlichen Daten hängen möglicherweise von mehreren Faktoren auf niedrigerer Ebene ab. Viele dieser Faktoren können für die Anwendung, das System und die Umgebung spezifisch sein. Ein effektives Überwachungssystem erfasst die Verfügbarkeitsdaten, die diesen Faktoren auf niedriger Ebene entsprechen, und aggregiert sie dann, um ein Gesamtbild des Systems zu liefern. In einem E-Commerce-System kann beispielsweise die Geschäftsfunktionalität, die es einem Kunden ermöglicht, Bestellungen zu tätigen, vom Repository abhängen, in dem Bestelldetails gespeichert sind, und vom Zahlungssystem, das die Geldtransaktionen für die Zahlung für diese Bestellungen verarbeitet. Die Verfügbarkeit des Auftragsplatzierungsteils des Systems ist daher eine Funktion der Verfügbarkeit des Repositorys und des Zahlungssubsystems.
Anforderungen für die Verfügbarkeitsüberwachung
Ein Betreiber sollte auch in der Lage sein, die historische Verfügbarkeit jedes Systems und Subsystems anzuzeigen, und diese Informationen verwenden, um trends zu erkennen, die dazu führen können, dass ein oder mehrere Subsysteme regelmäßig fehlschlagen. (Beginnen Dienste zu einer bestimmten Tageszeit, die spitzen Verarbeitungsstunden entspricht?)
Eine Überwachungslösung sollte einen sofortigen und historischen Überblick über die Verfügbarkeit oder Nichtverfügbarkeit jedes Subsystems bieten. Es sollte auch in der Lage sein, einen Operator schnell zu benachrichtigen, wenn ein oder mehrere Dienste fehlschlagen oder wenn Benutzer keine Verbindung mit Diensten herstellen können. Dies ist nicht nur die Überwachung jedes Diensts, sondern auch die Überprüfung der Aktionen, die jeder Benutzer ausführt, wenn diese Aktionen fehlschlagen, wenn er versucht, mit einem Dienst zu kommunizieren. In gewissem Maße ist ein Gewisses an Konnektivitätsfehlern normal und kann auf vorübergehende Fehler zurückzuführen sein. Es kann jedoch sinnvoll sein, dem System die Möglichkeit zu geben, eine Warnung für die Anzahl der Verbindungsfehler an ein bestimmtes Subsystem auszurufen, die während eines bestimmten Zeitraums auftreten.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Wie bei der Integritätsüberwachung können die rohen Daten, die zur Unterstützung der Verfügbarkeitsüberwachung erforderlich sind, durch synthetische Benutzerüberwachung generiert und ausnahmen, Fehler und Warnungen protokolliert werden, die auftreten können. Darüber hinaus können Verfügbarkeitsdaten aus der Endpunktüberwachung abgerufen werden. Die Anwendung kann einen oder mehrere Integritätsendpunkte verfügbar machen, wobei jeder Testzugriff auf einen Funktionsbereich innerhalb des Systems getestet wird. Das Überwachungssystem kann jeden Endpunkt pingen, indem er einem definierten Zeitplan folgt und die Ergebnisse sammelt (Erfolg oder Fehlschlagen).
Alle Timeouts, Netzwerkkonnektivitätsfehler und Wiederholungsversuche der Verbindung müssen aufgezeichnet werden. Alle Daten sollten zeitstempelt sein.
Analysieren von Verfügbarkeitsdaten
Die Instrumentierungsdaten müssen aggregiert und korreliert werden, um die folgenden Analysetypen zu unterstützen:
- Die sofortige Verfügbarkeit des Systems und der Subsysteme.
- Die Verfügbarkeitsfehlerraten des Systems und der Subsysteme. Im Idealfall sollte ein Operator Fehler mit bestimmten Aktivitäten korrelieren können: Was passiert, wenn das System fehlgeschlagen ist?
- Eine historische Ansicht der Fehlerraten des Systems oder aller Subsysteme über einen bestimmten Zeitraum hinweg und die Auslastung des Systems (z. B. Anzahl der Benutzeranforderungen), wenn ein Fehler aufgetreten ist.
- Die Gründe für die Nichtverfügbarkeit des Systems oder aller Subsysteme. Die Gründe können z. B. sein, dass der Dienst nicht ausgeführt wird, konnektivitätsverlusten, aber zeitüberschreitungen und verbunden, aber Fehler zurückgeben.
Sie können die prozentuale Verfügbarkeit eines Diensts über einen bestimmten Zeitraum berechnen, indem Sie die folgende Formel verwenden:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Dies ist für SLA-Zwecke nützlich. (DIE SLA-Überwachung wird weiter unten in dieser Anleitung ausführlicher beschrieben.) Die Definition der Ausfallzeiten hängt vom Dienst ab. Beispielsweise definiert visual Studio Team Services Build Service Ausfallzeiten als Zeitraum (gesamt akkumulierte Minuten), während der build service nicht verfügbar ist. Eine Minute wird als nicht verfügbar betrachtet, wenn alle fortlaufenden HTTP-Anforderungen an build Service, um vom Kunden initiierte Vorgänge während der gesamten Minute auszuführen, entweder zu einem Fehlercode führen oder keine Antwort zurückgeben.
Leistung überwachen
Da das System immer mehr Stress hat (indem die Anzahl der Benutzer erhöht wird), wächst die Größe der Datasets, auf die diese Benutzer zugreifen, und die Möglichkeit des Ausfalls einer oder mehrerer Komponenten wird wahrscheinlicher. Häufig liegt ein Komponentenfehler vor einer Leistungsminderung. Wenn Sie eine solche Abnahme erkennen können, können Sie proaktive Schritte ergreifen, um die Situation zu beheben.
Die Systemleistung hängt von mehreren Faktoren ab. Jeder Faktor wird in der Regel durch Key Performance Indicators (KPIs) gemessen, z. B. die Anzahl der Datenbanktransaktionen pro Sekunde oder das Volumen der Netzwerkanforderungen, die erfolgreich in einem bestimmten Zeitraum gewartet werden. Einige dieser KPIs sind möglicherweise als spezifische Leistungskennzahlen verfügbar, während andere aus einer Kombination von Metriken abgeleitet werden können.
Hinweis
Die Ermittlung schlechter oder guter Leistung erfordert, dass Sie die Leistungsebene verstehen, auf der das System ausgeführt werden kann. Dazu ist es erforderlich, das System zu beobachten, während es unter einer typischen Last funktioniert und die Daten für jeden KPI über einen bestimmten Zeitraum erfasst. Dies kann das Ausführen des Systems unter einer simulierten Last in einer Testumgebung und das Sammeln der entsprechenden Daten umfassen, bevor das System in einer Produktionsumgebung bereitgestellt wird.
Sie sollten auch sicherstellen, dass die Überwachung für Leistungszwecke keine Belastung für das System wird. Möglicherweise können Sie die Detailebene für die Daten, die der Prozess zur Leistungsüberwachung erfasst, dynamisch anpassen.
Anforderungen für die Leistungsüberwachung
Um die Systemleistung zu untersuchen, muss ein Operator in der Regel Informationen anzeigen, die Folgendes umfassen:
- Die Antwortraten für Benutzeranforderungen.
- Die Anzahl der gleichzeitigen Benutzeranforderungen.
- Das Volumen des Netzwerkdatenverkehrs.
- Die Kurse, mit denen Geschäftstransaktionen abgeschlossen werden.
- Die durchschnittliche Verarbeitungszeit für Anforderungen.
Es kann auch hilfreich sein, Tools bereitzustellen, mit denen ein Operator Korrelationen erkennen kann, z. B.:
- Die Anzahl der gleichzeitigen Benutzer im Vergleich zur Anforderungslatenz (wie lange es dauert, die Verarbeitung einer Anforderung zu starten, nachdem der Benutzer sie gesendet hat).
- Die Anzahl der gleichzeitigen Benutzer im Vergleich zur durchschnittlichen Antwortzeit (wie lange dauert es, um eine Anforderung abzuschließen, nachdem sie mit der Verarbeitung begonnen hat).
- Das Volumen der Anforderungen im Vergleich zur Anzahl der Verarbeitungsfehler.
Zusammen mit diesen allgemeinen Funktionalen Informationen sollte ein Operator in der Lage sein, eine detaillierte Übersicht über die Leistung für jede Komponente im System zu erhalten. Diese Daten werden in der Regel über Leistungsindikatoren auf niedriger Ebene bereitgestellt, die Informationen nachverfolgen, z. B.:
- Arbeitsspeicherauslastung.
- Anzahl der Threads.
- CPU-Verarbeitungszeit.
- Länge der Anforderungswarteschlange.
- Datenträger- oder Netzwerk-E/A-Raten und -Fehler.
- Anzahl geschriebener oder gelesener Bytes.
- Middleware-Indikatoren, z. B. Warteschlangenlänge.
Alle Visualisierungen sollten es einem Operator ermöglichen, einen Zeitraum anzugeben. Die angezeigten Daten können eine Momentaufnahme der aktuellen Situation oder eine historische Ansicht der Leistung sein.
Ein Operator sollte eine Warnung basierend auf allen Leistungskennzahlen für jeden angegebenen Wert während eines bestimmten Zeitintervalls auslösen können.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Sie können allgemeine Leistungsdaten (z. B. Durchsatz, Anzahl gleichzeitiger Benutzer, Anzahl der Geschäftstransaktionen und Fehlerraten) sammeln, indem Sie den Fortschritt der Anforderungen der Benutzer überwachen, sobald sie ankommen und das System durchlaufen. Dazu gehören die Einbeziehung von Ablaufverfolgungsanweisungen an wichtigen Punkten im Anwendungscode sowie Zeitangaben. Alle Fehler, Ausnahmen und Warnungen sollten mit ausreichenden Daten erfasst werden, um sie mit den Anforderungen zu korrelieren, die sie verursacht haben. Das Iis-Protokoll (Internet Information Services) ist eine weitere nützliche Quelle.
Wenn möglich, sollten Sie auch Leistungsdaten für alle externen Systeme erfassen, die von der Anwendung verwendet werden. Diese externen Systeme stellen möglicherweise eigene Leistungsindikatoren oder andere Features zum Anfordern von Leistungsdaten bereit. Wenn dies nicht möglich ist, zeichnen Sie Informationen wie die Startzeit und die Endzeit jeder Anforderung an ein externes System zusammen mit dem Status (Erfolg, Fehler oder Warnung) des Vorgangs auf. Sie können z. B. einen Stopwatch-Ansatz für Zeitanforderungen verwenden: Einen Timer starten, wenn die Anforderung gestartet wird, und dann den Timer beenden, wenn die Anforderung abgeschlossen ist.
Leistungsdaten auf niedriger Ebene für einzelne Komponenten in einem System können über Features und Dienste wie Windows-Leistungsindikatoren und Azure-Diagnose verfügbar sein.
Analysieren von Leistungsdaten
Ein Großteil der Analysearbeit besteht aus dem Aggregieren von Leistungsdaten nach Benutzeranforderungstyp oder dem Subsystem oder Dienst, an das jede Anforderung gesendet wird. Ein Beispiel für eine Benutzeranfrage ist das Hinzufügen eines Artikels zu einem Einkaufswagen oder das Ausführen des Auscheckvorgangs in einem E-Commerce-System.
Eine weitere häufige Anforderung besteht darin, Leistungsdaten in ausgewählten Quantils zusammenzufassen. Beispielsweise kann ein Operator die Antwortzeiten für 99 Prozent der Anforderungen, 95 Prozent der Anforderungen und 70 Prozent der Anforderungen bestimmen. Es können SLA-Ziele oder andere Ziele für jedes Quantil festgelegt werden. Die laufenden Ergebnisse sollten in nahezu Echtzeit gemeldet werden, um sofortige Probleme zu erkennen. Die Ergebnisse sollten auch über die längere Zeit für statistische Zwecke aggregiert werden.
Im Falle von Latenzproblemen, die sich auf die Leistung auswirken, sollte ein Operator in der Lage sein, die Ursache des Engpasses schnell zu identifizieren, indem die Latenz jedes Schritts untersucht wird, den jede Anforderung ausführt. Die Leistungsdaten müssen daher ein Mittel zum Korrelieren von Leistungskennzahlen für jeden Schritt bereitstellen, um sie mit einer bestimmten Anforderung zu verknüpfen.
Je nach den Visualisierungsanforderungen kann es hilfreich sein, einen Datenwürfel zu generieren und zu speichern, der Ansichten der Rohdaten enthält. Dieser Datenwürfel kann eine komplexe Ad-hoc-Abfrage und Analyse der Leistungsinformationen ermöglichen.
Sicherheitsüberwachung
Alle kommerziellen Systeme, die vertrauliche Daten enthalten, müssen eine Sicherheitsstruktur implementieren. Die Komplexität des Sicherheitsmechanismus ist in der Regel eine Funktion der Vertraulichkeit der Daten. In einem System, bei dem Benutzer authentifiziert werden müssen, sollten Sie Folgendes aufzeichnen:
- Alle Anmeldeversuche, unabhängig davon, ob sie fehlschlagen oder erfolgreich sind.
- Alle Vorgänge, die von einem authentifizierten Benutzer ausgeführt werden – und die Details aller Ressourcen, auf die zugegriffen wird.
- Wenn ein Benutzer eine Sitzung beendet und sich abmeldet.
Die Überwachung kann dabei helfen, Angriffe auf das System zu erkennen. Eine große Anzahl fehlgeschlagener Anmeldeversuche kann beispielsweise auf einen Brute-Force-Angriff hinweisen. Ein unerwarteter Anstieg der Anforderungen kann das Ergebnis eines verteilten Denial-of-Service-Angriffs (DDoS) sein. Sie müssen bereit sein, alle Anforderungen an alle Ressourcen zu überwachen, unabhängig von der Quelle dieser Anforderungen. Ein System, das über eine Anmeldelücke verfügt, kann Ressourcen versehentlich außerhalb der Welt verfügbar machen, ohne dass sich ein Benutzer tatsächlich anmelden muss.
Anforderungen für die Sicherheitsüberwachung
Die wichtigsten Aspekte der Sicherheitsüberwachung sollten es einem Betreiber ermöglichen, schnell:
- Erkennen von versuchten Eindringversuchen durch eine nicht authentifizierte Entität.
- Identifizieren Sie Versuche von Entitäten, Vorgänge für Daten auszuführen, für die ihnen kein Zugriff gewährt wurde.
- Bestimmen Sie, ob das System oder ein Teil des Systems von außerhalb oder innerhalb angegriffen wird. (Beispielsweise kann ein böswilliger authentifizierter Benutzer versuchen, das System herunterzubringen.)
Um diese Anforderungen zu unterstützen, sollte ein Betreiber benachrichtigt werden, wenn:
- Ein Konto führt wiederholt fehlgeschlagene Anmeldeversuche innerhalb eines bestimmten Zeitraums durch.
- Ein authentifiziertes Konto versucht wiederholt, während eines bestimmten Zeitraums auf eine verbotene Ressource zuzugreifen.
- Eine große Anzahl nicht authentifizierter oder nicht autorisierter Anforderungen tritt während eines bestimmten Zeitraums auf.
Die Informationen, die einem Operator bereitgestellt werden, sollten die Hostadresse der Quelle für jede Anforderung enthalten. Wenn Sicherheitsverletzungen regelmäßig aus einem bestimmten Adressbereich auftreten, werden diese Hosts möglicherweise blockiert.
Ein wichtiger Bestandteil der Aufrechterhaltung der Sicherheit eines Systems ist es, Aktionen, die vom üblichen Muster abweichen, schnell erkennen zu können. Informationen wie die Anzahl der fehlgeschlagenen oder erfolgreichen Anmeldeanforderungen können visuell angezeigt werden, um zu erkennen, ob es zu einem ungewöhnlichen Zeitpunkt eine Spitzenaktivität gibt. (Ein Beispiel für diese Aktivität ist, dass sich Benutzer um 3:00 Uhr anmelden und eine große Anzahl von Vorgängen ausführen, wenn ihr Arbeitstag um 9:00 Uhr beginnt). Diese Informationen können auch verwendet werden, um die zeitbasierte automatische Skalierung zu konfigurieren. Wenn ein Betreiber beispielsweise feststellt, dass sich eine große Anzahl von Benutzern regelmäßig zu einer bestimmten Tageszeit anmeldet, kann der Betreiber die Möglichkeit haben, zusätzliche Authentifizierungsdienste für die Verarbeitung des Arbeitsvolumens zu starten und diese zusätzlichen Dienste dann herunterzufahren, wenn der Höchstwert überschritten wurde.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Sicherheit ist ein allumfassender Aspekt der meisten verteilten Systeme. Die relevanten Daten werden wahrscheinlich an mehreren Punkten innerhalb eines Systems generiert. Sie sollten einen SIEM-Ansatz (Security Information and Event Management) einführen, um die sicherheitsrelevanten Informationen zu sammeln, die sich aus Ereignissen ergeben, die von der Anwendung, Netzwerkausrüstung, Servern, Firewalls, Antivirensoftware und anderen Elementen zur Eindringprävention ausgelöst werden.
Die Sicherheitsüberwachung kann Daten aus Tools integrieren, die nicht Teil Ihrer Anwendung sind. Diese Tools können Dienstprogramme umfassen, die Port-Scan-Aktivitäten durch externe Agenturen identifizieren, oder Netzwerkfilter, die Versuche erkennen, nicht authentifizierten Zugriff auf Ihre Anwendung und Ihre Daten zu erhalten.
In allen Fällen müssen die gesammelten Daten einem Administrator ermöglichen, die Art eines Angriffs zu bestimmen und die entsprechenden Gegenmaßnahmen zu ergreifen.
Analysieren von Sicherheitsdaten
Ein wichtiges Feature der Sicherheitsüberwachung besteht darin, dass daten aus vielen Quellen gesammelt werden. Die verschiedenen Formate und Detailebenen erfordern häufig eine komplexe Analyse der erfassten Daten, um sie in einen kohärenten Informationsthread zu binden. Abgesehen von den einfachsten Fällen (z. B. das Erkennen einer großen Anzahl fehlgeschlagener Anmeldungen oder wiederholter Versuche, nicht autorisierten Zugriff auf kritische Ressourcen zu erhalten), ist es möglicherweise nicht möglich, eine komplexe automatisierte Verarbeitung von Sicherheitsdaten durchzuführen. Stattdessen kann es vorzuziehen sein, diese Daten zu schreiben, zeitstempelt, aber andernfalls in seiner ursprünglichen Form, einem sicheren Repository, um eine manuelle Analyse von Experten zu ermöglichen.
SLA-Überwachung
Viele kommerzielle Systeme, die die Bezahlung von Kunden unterstützen, machen Garantien über die Leistung des Systems in Form von SLAs. Im Wesentlichen geben SLAs an, dass das System innerhalb eines vereinbarten Zeitraums ein definiertes Arbeitsvolumen verarbeiten kann und ohne kritische Informationen zu verlieren. Die SLA-Überwachung befasst sich mit der Sicherstellung, dass das System messbare SLAs erfüllen kann.
Hinweis
SLA-Überwachung ist eng mit der Leistungsüberwachung verbunden. In der Erwägung, dass die Leistungsüberwachung jedoch darauf bedacht ist, sicherzustellen, dass das System optimal funktioniert, unterliegt die SLA-Überwachung einer vertraglichen Verpflichtung, die definiert, was tatsächlich optimal bedeutet.
SLAs werden häufig in Bezug auf:
- Gesamtsystemverfügbarkeit. Beispielsweise kann eine Organisation garantieren, dass das System für 99,9 Prozent der Zeit verfügbar ist. Dies entspricht nicht mehr als 9 Stunden Ausfallzeiten pro Jahr oder ungefähr 10 Minuten pro Woche.
- Betriebsdurchsatz. Dieser Aspekt wird häufig als eine oder mehrere Wasserzeichen ausgedrückt, z. B. die Gewährleistung, dass das System bis zu 100.000 gleichzeitige Benutzeranforderungen unterstützen kann oder 10.000 gleichzeitige Geschäftstransaktionen verarbeiten kann.
- Betriebsantwortzeit. Das System kann auch Garantien für die Rate der Verarbeitung von Anfragen machen. Ein Beispiel dafür ist, dass 99 Prozent aller Geschäftstransaktionen innerhalb von zwei Sekunden abgeschlossen werden und keine einzelne Transaktion länger als 10 Sekunden dauert.
Hinweis
Einige Verträge für kommerzielle Systeme können auch SLAs für den Kundensupport enthalten. Ein Beispiel dafür ist, dass alle Helpdesk-Anfragen innerhalb von fünf Minuten eine Antwort erregen und dass 99 Prozent aller Probleme innerhalb eines Arbeitstags vollständig behoben werden. Effektive Problemverfolgung (weiter unten in diesem Abschnitt beschrieben) ist der Schlüssel zu Besprechungs-SLAs wie diesen.
Anforderungen für die SLA-Überwachung
Auf höchster Ebene sollte ein Betreiber auf einen Blick ermitteln können, ob das System die vereinbarten SLAs erfüllt oder nicht. And if not, the operator should be able down and examine the underlying factors to determine the reasons for substandard performance.
Typische allgemeine Indikatoren, die visuell dargestellt werden können:
- Der Prozentsatz der Dienstverfügbarkeit.
- Der Anwendungsdurchsatz (gemessen in Bezug auf erfolgreiche Transaktionen oder Vorgänge pro Sekunde).
- Die Anzahl der erfolgreichen/fehlerhaften Anwendungsanforderungen.
- Die Anzahl der Anwendungs- und Systemfehler, Ausnahmen und Warnungen.
Alle diese Indikatoren sollten in der Lage sein, nach einem bestimmten Zeitraum gefiltert zu werden.
Eine Cloudanwendung umfasst wahrscheinlich mehrere Subsysteme und Komponenten. Ein Operator sollte in der Lage sein, einen High-Level-Indikator auszuwählen und zu sehen, wie er aus der Integrität der zugrunde liegenden Elemente besteht. Wenn beispielsweise die Betriebszeit des Gesamtsystems unter einen akzeptablen Wert fällt, sollte ein Operator in der Lage sein, zu zoomen und zu bestimmen, welche Elemente zu diesem Fehler beitragen.
Hinweis
Systembetriebszeit muss sorgfältig definiert werden. In einem System, das Redundanz verwendet, um eine maximale Verfügbarkeit sicherzustellen, können einzelne Instanzen von Elementen fehlschlagen, das System kann jedoch funktionsfähig bleiben. Systembetriebszeit, wie durch die Integritätsüberwachung dargestellt, sollte die aggregierte Betriebszeit jedes Elements angeben und nicht unbedingt, ob das System tatsächlich angehalten wurde. Darüber hinaus können Fehler isoliert werden. Selbst wenn ein bestimmtes System nicht verfügbar ist, bleibt der Rest des Systems möglicherweise verfügbar, obwohl die Funktionalität verringert ist. (In einem E-Commerce-System kann ein Fehler im System möglicherweise verhindern, dass ein Kunde Bestellungen abgibt, der Kunde kann aber trotzdem den Produktkatalog durchsuchen.)
Für Warnzwecke sollte das System in der Lage sein, ein Ereignis auszuheben, wenn eines der High-Level-Indikatoren einen angegebenen Schwellenwert überschreitet. Die Details der unteren Ebene der verschiedenen Faktoren, die den Indikator auf hoher Ebene erstellen, sollten als Kontextdaten für das Warnsystem verfügbar sein.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Die rohen Daten, die zur Unterstützung der SLA-Überwachung erforderlich sind, ähneln den rohen Daten, die für die Leistungsüberwachung erforderlich sind, zusammen mit einigen Aspekten der Integritäts- und Verfügbarkeitsüberwachung. Weitere Informationen finden Sie in diesen Abschnitten. Sie können diese Daten erfassen, indem Sie:
- Durchführen der Endpunktüberwachung.
- Protokollierung von Ausnahmen, Fehlern und Warnungen.
- Nachverfolgen der Ausführung von Benutzeranforderungen.
- Überwachen der Verfügbarkeit von Drittanbieterdiensten, die das System verwendet.
- Verwenden von Leistungsmetriken und Leistungsindikatoren.
Alle Daten müssen zeit- und zeitstempelt sein.
Analysieren von SLA-Daten
Die Instrumentierungsdaten müssen aggregiert werden, um ein Bild der Gesamtleistung des Systems zu generieren. Aggregierte Daten müssen auch Drilldowns unterstützen, um die Untersuchung der Leistung der zugrunde liegenden Subsysteme zu ermöglichen. Sie sollten z. B. folgende Möglichkeiten haben:
- Berechnen Sie die Gesamtzahl der Benutzeranforderungen während eines bestimmten Zeitraums, und bestimmen Sie die Erfolgs- und Fehlerrate dieser Anforderungen.
- Kombinieren Sie die Antwortzeiten von Benutzeranforderungen, um eine Gesamtansicht der Systemantwortzeiten zu generieren.
- Analysieren Sie den Fortschritt von Benutzeranforderungen, um die Gesamtantwortzeit einer Anforderung in die Antwortzeiten der einzelnen Arbeitsaufgaben in dieser Anforderung aufzuteilen.
- Ermitteln Sie die Gesamtverfügbarkeit des Systems als Prozentsatz der Betriebszeit für einen bestimmten Zeitraum.
- Analysieren Sie die prozentuale Verfügbarkeit der einzelnen Komponenten und Dienste im System. Dies kann das Analysieren von Protokollen umfassen, die von Drittanbieterdiensten generiert wurden.
Viele kommerzielle Systeme sind erforderlich, um reale Leistungszahlen für einen bestimmten Zeitraum, in der Regel einen Monat, gegen vereinbarte SLAs zu melden. Diese Informationen können zum Berechnen von Krediten oder anderen Rückzahlungsformen für Kunden verwendet werden, wenn die SLAs während dieses Zeitraums nicht erfüllt sind. Sie können die Verfügbarkeit für einen Dienst berechnen, indem Sie die im Abschnitt "Analysieren von Verfügbarkeitsdaten" beschriebene Technik verwenden.
Für interne Zwecke kann eine Organisation auch die Anzahl und Art von Vorfällen nachverfolgen, die dazu geführt haben, dass Dienste fehlschlugen. Wenn Sie erfahren, wie Sie diese Probleme schnell beheben oder vollständig beseitigen können, können Sie Ausfallzeiten reduzieren und SLAs erfüllen.
Überwachung
Je nach Art der Anwendung gibt es möglicherweise gesetzliche oder andere gesetzliche Vorschriften, die Anforderungen für die Überwachung der Benutzervorgänge und die Aufzeichnung aller Datenzugriffe angeben. Die Überwachung kann Nachweise liefern, die Kunden mit bestimmten Anforderungen verknüpft. Nonrepudiation ist ein wichtiger Faktor in vielen E-Business-Systemen, um das Vertrauen zwischen einem Kunden und der Organisation aufrechtzuerhalten, die für die Anwendung oder den Dienst verantwortlich ist.
Anforderungen für die Überwachung
Ein Analyst muss in der Lage sein, die Abfolge von Geschäftsvorgängen nachzuverfolgen, die Benutzer ausführen, damit Sie die Aktionen der Benutzer rekonstruieren können. Dies kann einfach als Datensatz oder als Teil einer forensischen Untersuchung notwendig sein.
Überwachungsinformationen sind streng vertraulich. Es enthält wahrscheinlich Daten, die die Benutzer des Systems identifizieren, zusammen mit den Aufgaben, die sie ausführen. Aus diesem Grund werden Überwachungsinformationen wahrscheinlich in Form von Berichten verwendet, die nur vertrauenswürdigen Analysten zur Verfügung stehen, anstatt als interaktives System, das Drilldowns grafischer Vorgänge unterstützt. Ein Analyst sollte in der Lage sein, eine Reihe von Berichten zu generieren. Beispielsweise können Berichte die Aktivitäten aller Benutzer auflisten, die während eines bestimmten Zeitrahmens auftreten, die Chronologie der Aktivität für einen einzelnen Benutzer detailliert darstellen, oder die Abfolge der Vorgänge auflisten, die für eine oder mehrere Ressourcen ausgeführt werden.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Die wichtigsten Informationsquellen für die Überwachung können folgendes umfassen:
- Das Sicherheitssystem, das die Benutzerauthentifizierung verwaltet.
- Ablaufverfolgungsprotokolle, die Benutzeraktivitäten aufzeichnen.
- Sicherheitsprotokolle, die alle identifizierbaren und nicht identifizierten Netzwerkanforderungen nachverfolgen.
Das Format der Auditdaten und die Art und Weise, in der sie gespeichert wird, kann durch regulatorische Anforderungen gesteuert werden. Beispielsweise ist es möglicherweise nicht möglich, die Daten auf irgendeine Weise zu bereinigen. (Es muss in seinem ursprünglichen Format aufgezeichnet werden.) Der Zugriff auf das Repository, in dem es gehalten wird, muss geschützt sein, um Manipulationen zu verhindern.
Analysieren von Überwachungsdaten
Ein Analyst muss vollständig auf die Rohdaten zugreifen können, in seiner ursprünglichen Form. Abgesehen von der Anforderung, gemeinsame Überwachungsberichte zu erstellen, sind die Tools für die Analyse dieser Daten wahrscheinlich spezialisiert und werden außerhalb des Systems gehalten.
Überwachung der Nutzung
Die Verwendungsüberwachung verfolgt, wie die Features und Komponenten einer Anwendung verwendet werden. Ein Operator kann die gesammelten Daten verwenden, um:
Ermitteln Sie, welche Features stark verwendet werden, und bestimmen Sie potenzielle Hotspots im System. Elemente mit hohem Datenverkehr können von funktionaler Partitionierung oder sogar Replikation profitieren, um die Auslastung gleichmäßiger zu verteilen. Ein Betreiber kann diese Informationen auch verwenden, um festzustellen, welche Features selten verwendet werden und welche Kandidaten für den Ruhestand oder ersatz in einer zukünftigen Version des Systems möglich sind.
Rufen Sie Informationen über die betriebstechnischen Ereignisse des Systems unter normaler Verwendung ab. Beispielsweise können Sie auf einer E-Commerce-Website die statistischen Informationen über die Anzahl der Transaktionen und das Volumen der Für sie verantwortlichen Kunden aufzeichnen. Diese Informationen können für die Kapazitätsplanung verwendet werden, wenn die Anzahl der Kunden wächst.
Erkennen (möglicherweise indirekt) der Benutzerzufriedenheit mit der Leistung oder Funktionalität des Systems. Wenn beispielsweise eine große Anzahl von Kunden in einem E-Commerce-System regelmäßig ihre Einkaufswagen aufgibt, kann dies auf ein Problem mit der Checkout-Funktionalität zurückzuführen sein.
Generieren Sie Abrechnungsinformationen. Eine kommerzielle Anwendung oder ein mehrinstanzenfähiger Dienst kann Kunden für die von ihnen verwendeten Ressourcen belasten.
Erzwingen Sie Kontingente. Wenn ein Benutzer in einem Mehrinstanzensystem sein bezahltes Verarbeitungskontingent oder die Ressourcennutzung während eines bestimmten Zeitraums überschreitet, kann der Zugriff eingeschränkt oder die Verarbeitung gedrosselt werden.
Anforderungen für die Nutzungsüberwachung
Um die Systemnutzung zu untersuchen, muss ein Operator in der Regel Informationen anzeigen, die Folgendes umfassen:
- Die Anzahl der Anforderungen, die von jedem Subsystem verarbeitet und an jede Ressource weitergeleitet werden.
- Die Arbeit, die jeder Benutzer ausführt.
- Das Volumen der Datenspeicherung, die jeder Benutzer belegt.
- Die Ressourcen, auf die jeder Benutzer zugreift.
Ein Operator sollte auch in der Lage sein, Diagramme zu generieren. Ein Diagramm kann beispielsweise die am meisten ressourcenhungrigen Benutzer oder die am häufigsten verwendeten Ressourcen oder Systemfeatures anzeigen.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Die Verwendungsnachverfolgung kann auf relativ hoher Ebene durchgeführt werden. Sie kann die Anfangs- und Endzeiten jeder Anforderung und die Art der Anforderung (Lese-, Schreib- und andere Anforderungen, abhängig von der betreffenden Ressource) notieren. Sie können diese Informationen erhalten, indem Sie:
- Nachverfolgen von Benutzeraktivitäten.
- Erfassen von Leistungsindikatoren, die die Auslastung für jede Ressource messen.
- Überwachen des Ressourcenverbrauchs durch jeden Benutzer.
Für Die Messung müssen Sie auch in der Lage sein, zu ermitteln, welche Benutzer für die Durchführung der Vorgänge und die Ressourcen verantwortlich sind, die diese Vorgänge verwenden. Die gesammelten Informationen sollten detailliert genug sein, um eine genaue Abrechnung zu ermöglichen.
Problemverfolgung
Kunden und andere Benutzer melden möglicherweise Probleme, wenn unerwartete Ereignisse oder Verhaltensweisen im System auftreten. Die Problemnachverfolgung befasst sich mit der Verwaltung dieser Probleme, deren Zuordnung zu den Bemühungen, die zugrunde liegenden Probleme im System zu lösen, und kunden über mögliche Lösungen zu informieren.
Anforderungen für die Problemverfolgung
Operatoren führen häufig die Problemnachverfolgung mithilfe eines separaten Systems durch, mit dem sie die Details von Problemen aufzeichnen und melden können, die benutzer melden. Diese Details können die Aufgaben umfassen, die der Benutzer auszuführen versucht hat, Symptome des Problems, die Abfolge von Ereignissen und alle ausgegebenen Fehlermeldungen oder Warnmeldungen.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Die ursprüngliche Datenquelle für Problemverfolgungsdaten ist der Benutzer, der das Problem zuerst gemeldet hat. Der Benutzer kann möglicherweise zusätzliche Daten bereitstellen, z. B.:
- Ein Absturzabbild (wenn die Anwendung eine Komponente enthält, die auf dem Desktop des Benutzers ausgeführt wird).
- Eine Bildschirmmomentaufnahme.
- Das Datum und die Uhrzeit, zu der der Fehler aufgetreten ist, zusammen mit anderen Umgebungsinformationen wie dem Standort des Benutzers.
Diese Informationen können verwendet werden, um den Debuggingaufwand zu unterstützen und dabei zu helfen, einen Backlog für zukünftige Versionen der Software zu erstellen.
Analysieren von Problemverfolgungsdaten
Verschiedene Benutzer melden möglicherweise dasselbe Problem. Das Problemverfolgungssystem sollte allgemeine Berichte zuordnen.
Der Fortschritt des Debugaufwands sollte für jeden Problembericht aufgezeichnet werden. Wenn das Problem behoben ist, kann der Kunde über die Lösung informiert werden.
Wenn ein Benutzer ein Problem meldet, das über eine bekannte Lösung im Problemverfolgungssystem verfügt, sollte der Operator den Benutzer sofort über die Lösung informieren können.
Ablaufverfolgungsvorgänge und Debuggen von Softwareversionen
Wenn ein Benutzer ein Problem meldet, ist der Benutzer häufig nur der unmittelbaren Wirkung bewusst, die er auf seine Vorgänge hat. Der Benutzer kann nur die Ergebnisse seiner eigenen Erfahrung an einen Betreiber zurückmelden, der für die Wartung des Systems verantwortlich ist. Diese Erfahrungen sind in der Regel nur ein sichtbares Symptom für ein oder mehrere grundlegende Probleme. In vielen Fällen muss ein Analyst die Chronologie der zugrunde liegenden Vorgänge durchsuchen, um die Ursache des Problems zu ermitteln. Dieser Prozess wird als Ursachenanalyse bezeichnet.
Hinweis
Die Ursachenanalyse kann Ineffizienzen im Entwurf einer Anwendung aufdecken. In diesen Situationen kann es möglich sein, die betroffenen Elemente zu überarbeiten und als Teil einer nachfolgenden Version bereitzustellen. Dieser Prozess erfordert eine sorgfältige Kontrolle, und die aktualisierten Komponenten sollten genau überwacht werden.
Anforderungen für Ablaufverfolgung und Debugging
Für die Nachverfolgung unerwarteter Ereignisse und anderer Probleme ist es wichtig, dass die Überwachungsdaten genügend Informationen zur Verfügung stellen, damit ein Analyst die Ursprünge dieser Probleme zurückverfolgen und die Abfolge der aufgetretenen Ereignisse rekonstruieren kann. Diese Informationen müssen ausreichen, um es einem Analysten zu ermöglichen, die Ursache von Problemen zu diagnostizieren. Ein Entwickler kann dann die erforderlichen Änderungen vornehmen, um zu verhindern, dass sie sich wiederholen.
Anforderungen an Datenquellen, Instrumentierung und Datensammlung
Die Problembehandlung kann die Ablaufverfolgung aller Methoden (und deren Parameter) umfassen, die als Teil eines Vorgangs aufgerufen werden, um eine Struktur zu erstellen, die den logischen Fluss über das System darstellt, wenn ein Kunde eine bestimmte Anforderung sendet. Ausnahmen und Warnungen, die das System als Ergebnis dieses Flusses generiert, müssen erfasst und protokolliert werden.
Um das Debuggen zu unterstützen, kann das System Hooks bereitstellen, mit denen ein Operator Zustandsinformationen an wichtigen Stellen im System erfassen kann. Oder das System kann detaillierte Schritt-für-Schritt-Informationen bereitstellen, wenn der Fortschritt der ausgewählten Vorgänge erfolgt. Das Erfassen von Daten auf dieser Detailebene kann eine zusätzliche Belastung für das System erzwingen und sollte ein temporärer Prozess sein. Ein Operator verwendet diesen Prozess hauptsächlich, wenn eine sehr ungewöhnliche Serie von Ereignissen auftritt und schwer repliziert werden kann, oder wenn eine neue Freigabe eines oder mehrerer Elemente in ein System eine sorgfältige Überwachung erfordert, um sicherzustellen, dass die Elemente erwartungsgemäß funktionieren.
Die Überwachungs- und Diagnosepipeline
Die Überwachung eines umfangreichen verteilten Systems stellt eine erhebliche Herausforderung dar. Jedes der im vorherigen Abschnitt beschriebenen Szenarien sollte nicht unbedingt isoliert betrachtet werden. Es gibt wahrscheinlich eine erhebliche Überschneidung in den Überwachungs- und Diagnosedaten, die für jede Situation erforderlich sind, obwohl diese Daten möglicherweise auf unterschiedliche Weise verarbeitet und präsentiert werden müssen. Aus diesen Gründen sollten Sie einen ganzheitlichen Blick auf die Überwachung und Diagnose werfen.
Sie können sich den gesamten Überwachungs- und Diagnoseprozess als Pipeline vorstellen, die die in Abbildung 1 dargestellten Stufen umfasst.

Abbildung 1 : Die Phasen in der Überwachungs- und Diagnosepipeline.
Abbildung 1 zeigt, wie die Daten für die Überwachung und Diagnose aus verschiedenen Datenquellen stammen können. Die Instrumentierungs- und Sammlungsphasen befassen sich mit der Identifizierung der Quellen, aus denen die Daten erfasst werden müssen, bestimmen, welche Daten erfasst werden sollen, wie sie erfasst werden sollen, und wie diese Daten so formatiert werden, dass sie leicht untersucht werden können. Die Analyse-/Diagnosephase verwendet die Rohdaten und verwendet sie, um aussagekräftige Informationen zu generieren, die ein Operator verwenden kann, um den Zustand des Systems zu bestimmen. Der Operator kann diese Informationen verwenden, um Entscheidungen über mögliche Aktionen zu treffen, und die Ergebnisse dann wieder in die Instrumentierungs- und Sammlungsphasen einspeist. In der Phase der Visualisierung/Warnungsphase wird eine Verbrauchsansicht des Systemzustands dargestellt. Mithilfe einer Reihe von Dashboards können Informationen nahezu in Echtzeit angezeigt werden. Außerdem können Berichte, Diagramme und Diagramme erstellt werden, um eine historische Ansicht der Daten bereitzustellen, die dazu beitragen können, langfristige Trends zu identifizieren. Wenn Informationen angeben, dass ein KPI wahrscheinlich akzeptable Grenzen überschreitet, kann diese Phase auch eine Warnung an einen Operator auslösen. In einigen Fällen kann eine Warnung auch verwendet werden, um einen automatisierten Prozess auszulösen, der versucht, Korrekturmaßnahmen zu ergreifen, z. B. die automatische Skalierung.
Diese Schritte stellen einen kontinuierlichen Ablaufprozess dar, bei dem die Phasen parallel ausgeführt werden. Im Idealfall sollten alle Phasen dynamisch konfigurierbar sein. Zu einigen Punkten, insbesondere wenn ein System neu bereitgestellt wurde oder Probleme auftreten, kann es notwendig sein, erweiterte Daten häufiger zu sammeln. Zu anderen Zeiten sollte es möglich sein, auf die Erfassung einer Basisebene wesentlicher Informationen zurückgesetzt werden, um zu überprüfen, ob das System ordnungsgemäß funktioniert.
Darüber hinaus sollte der gesamte Überwachungsprozess als Live-, fortlaufende Lösung betrachtet werden, die aufgrund von Feedback feinabstimmungen und Verbesserungen unterzogen wird. Beispielsweise können Sie mit der Messung vieler Faktoren beginnen, um die Systemintegrität zu bestimmen. Die Analyse im Laufe der Zeit kann zu einer Einschränkung führen, wenn Sie nicht relevante Measures verwerfen, sodass Sie sich genauer auf die daten konzentrieren können, die Sie benötigen, während Sie Hintergrundgeräusche minimieren.
Quellen der Überwachung und Diagnosedaten
Die Informationen, die der Überwachungsprozess verwendet, können aus mehreren Quellen stammen, wie in Abbildung 1 dargestellt. Auf Anwendungsebene stammen Informationen aus Ablaufverfolgungsprotokollen, die in den Code des Systems integriert sind. Entwickler sollten einen Standardansatz zum Nachverfolgen des Steuerungsflusses über ihren Code befolgen. Beispielsweise kann ein Eintrag in einer Methode eine Ablaufverfolgungsmeldung ausgeben, die den Namen der Methode, die aktuelle Uhrzeit, den Wert der einzelnen Parameter und alle anderen relevanten Informationen angibt. Die Aufzeichnung der Ein- und Ausgangszeiten kann sich auch als nützlich erweisen.
Sie sollten alle Ausnahmen und Warnungen protokollieren und sicherstellen, dass Sie eine vollständige Ablaufverfolgung aller geschachtelten Ausnahmen und Warnungen beibehalten. Im Idealfall sollten Sie auch Informationen erfassen, die den Benutzer identifizieren, der den Code ausführt, zusammen mit Aktivitätskorrelationsinformationen (um Anforderungen nachzuverfolgen, während sie das System durchlaufen). Und Sie sollten Versuche protokollieren, auf alle Ressourcen zuzugreifen, z. B. Nachrichtenwarteschlangen, Datenbanken, Dateien und andere abhängige Dienste. Diese Informationen können für Mess- und Überwachungszwecke verwendet werden.
Viele Anwendungen verwenden Bibliotheken und Frameworks, um allgemeine Aufgaben auszuführen, z. B. den Zugriff auf einen Datenspeicher oder die Kommunikation über ein Netzwerk. Diese Frameworks können konfigurierbar sein, um eigene Ablaufverfolgungsmeldungen und unformatierte Diagnoseinformationen bereitzustellen, z. B. Transaktionsraten und Datenübertragungserfolge und Fehler.
Hinweis
Viele moderne Frameworks veröffentlichen automatisch Leistungs- und Ablaufverfolgungsereignisse. Das Erfassen dieser Informationen ist einfach eine Frage der Bereitstellung einer Möglichkeit, sie abzurufen und zu speichern, wo sie verarbeitet und analysiert werden kann.
Das Betriebssystem, auf dem die Anwendung ausgeführt wird, kann eine Quelle für systemweite Informationen auf niedriger Ebene sein, z. B. Leistungsindikatoren, die die E/A-Raten, die Speicherauslastung und die CPU-Auslastung angeben. Betriebssystemfehler (z. B. fehler beim ordnungsgemäßen Öffnen einer Datei) können ebenfalls gemeldet werden.
Sie sollten auch die zugrunde liegende Infrastruktur und Komponenten berücksichtigen, auf der Ihr System ausgeführt wird. Virtuelle Computer, virtuelle Netzwerke und Speicherdienste können Alle Quellen wichtiger Leistungsindikatoren auf Infrastrukturebene und andere Diagnosedaten sein.
Wenn Ihre Anwendung andere externe Dienste verwendet, z. B. einen Webserver oder ein Datenbankverwaltungssystem, veröffentlichen diese Dienste möglicherweise ihre eigenen Ablaufverfolgungsinformationen, Protokolle und Leistungsindikatoren. Beispiele sind SQL Server Dynamic Management Views for tracking operations perform against a SQL Server database, and IIS trace logs for recording requests made to a web server.
Da die Komponenten eines Systems geändert und neue Versionen bereitgestellt werden, ist es wichtig, Probleme, Ereignisse und Metriken jeder Version zuzuordnen. Diese Informationen sollten an die Releasepipeline gebunden werden, damit Probleme mit einer bestimmten Version einer Komponente schnell nachverfolgt und korrigiert werden können.
Sicherheitsprobleme können jederzeit im System auftreten. Beispielsweise kann ein Benutzer versuchen, sich mit einer ungültigen Benutzer-ID oder einem ungültigen Kennwort anzumelden. Ein authentifizierter Benutzer versucht möglicherweise, nicht autorisierten Zugriff auf eine Ressource zu erhalten. Oder ein Benutzer stellt möglicherweise einen ungültigen oder veralteten Schlüssel für den Zugriff auf verschlüsselte Informationen bereit. Sicherheitsbezogene Informationen für erfolgreiche und fehlerhafte Anforderungen sollten immer protokolliert werden.
Der Abschnitt Instrumentierung einer Anwendung enthält weitere Anleitungen zu den Informationen, die Sie erfassen sollten. Sie können jedoch verschiedene Strategien verwenden, um diese Informationen zu sammeln:
Anwendungs-/Systemüberwachung. Diese Strategie verwendet interne Quellen innerhalb der Anwendung, Anwendungsframeworks, Betriebssystem und Infrastruktur. Der Anwendungscode kann seine eigenen Überwachungsdaten zu wichtigen Punkten während des Lebenszyklus einer Clientanforderung generieren. Die Anwendung kann Ablaufverfolgungsanweisungen enthalten, die unter Umständen selektiv aktiviert oder deaktiviert werden können. Es kann auch möglich sein, diagnosen dynamisch mithilfe eines Diagnoseframeworks einzujizieren. Diese Frameworks stellen in der Regel Plug-Ins bereit, die an verschiedenen Instrumentierungspunkten in Ihrem Code angefügt und Ablaufverfolgungsdaten an diesen Punkten erfasst werden können.
Darüber hinaus kann Ihr Code oder die zugrunde liegende Infrastruktur Ereignisse an kritischen Punkten auslösen. Überwachungs-Agents, die für die Überwachung dieser Ereignisse konfiguriert sind, können die Ereignisinformationen aufzeichnen.
Reale Benutzerüberwachung. Dieser Ansatz zeichnet die Interaktionen zwischen einem Benutzer und der Anwendung auf und beobachtet den Fluss jeder Anforderung und Antwort. Diese Informationen können einen zweifachen Zweck haben: Sie kann für die Messung der Nutzung durch jeden Benutzer verwendet werden, und es kann verwendet werden, um zu bestimmen, ob Benutzer eine geeignete Dienstqualität erhalten (z. B. schnelle Reaktionszeiten, niedrige Latenz und minimale Fehler). Sie können die erfassten Daten verwenden, um Problembereiche zu identifizieren, in denen Fehler am häufigsten auftreten. Sie können die Daten auch verwenden, um Elemente zu identifizieren, bei denen das System verlangsamt wird, möglicherweise aufgrund von Hotspots in der Anwendung oder einer anderen Form von Engpass. Wenn Sie diesen Ansatz sorgfältig implementieren, kann es möglich sein, die Abläufe der Benutzer über die Anwendung für Debugging- und Testzwecke zu rekonstruieren.
Wichtig
Sie sollten die Daten berücksichtigen, die erfasst werden, indem Sie echte Benutzer überwachen, um hochgradig vertraulich zu sein, da sie vertrauliche Materialien enthalten können. Wenn Sie erfasste Daten speichern, speichern Sie sie sicher. Wenn Sie die Daten zur Leistungsüberwachung oder zum Debuggen verwenden möchten, entfernen Sie zuerst alle personenbezogenen Daten.
Synthetische Benutzerüberwachung. Bei diesem Ansatz schreiben Sie Ihren eigenen Testclient, der einen Benutzer simuliert und eine konfigurierbare, aber typische Reihe von Vorgängen ausführt. Sie können die Leistung des Testclients nachverfolgen, um den Status des Systems zu ermitteln. Sie können auch mehrere Instanzen des Testclients als Teil eines Auslastungstestvorgangs verwenden, um festzulegen, wie das System unter Stress reagiert und welche Art von Überwachungsausgabe unter diesen Bedingungen generiert wird.
Hinweis
Sie können die reale und synthetische Benutzerüberwachung implementieren, indem Sie Code einschließen, der die Ausführung von Methodenaufrufen und anderen kritischen Teilen einer Anwendung überwacht und uhrzeitt.
Profilerstellung. Dieser Ansatz zielt in erster Linie auf die Überwachung und Verbesserung der Anwendungsleistung ab. Anstatt auf der funktionalen Ebene der realen und synthetischen Benutzerüberwachung zu arbeiten, erfasst sie Informationen auf niedrigerer Ebene, während die Anwendung ausgeführt wird. Sie können Profilerstellung mithilfe des regelmäßigen Samplings des Ausführungszustands einer Anwendung implementieren (bestimmen, welcher Codeabschnitt der Anwendung zu einem bestimmten Zeitpunkt ausgeführt wird). Sie können auch Instrumentierung verwenden, die Prüfpunkte an wichtigen Zeitpunkten (z. B. Start und Ende eines Methodenaufrufs) in den Code einfügt, und erfasst, welche Methoden aufgerufen wurden, zu welchem Zeitpunkt und wie lange jeder Aufruf dauerte. Anschließend können Sie diese Daten analysieren, um zu bestimmen, welche Teile der Anwendung Leistungsprobleme verursachen können.
Endpunktüberwachung. Diese Technik verwendet einen oder mehrere Diagnoseendpunkte, die die Anwendung speziell zur Aktivierung der Überwachung verfügbar macht. Ein Endpunkt stellt einen Weg in den Anwendungscode bereit und kann Informationen zur Integrität des Systems zurückgeben. Verschiedene Endpunkte können sich auf verschiedene Aspekte der Funktionalität konzentrieren. Sie können Ihren eigenen Diagnoseclient schreiben, der regelmäßige Anforderungen an diese Endpunkte sendet und die Antworten einschüchtert. Weitere Informationen finden Sie im Integritätsendpunktüberwachungsmuster.
Für eine maximale Abdeckung sollten Sie eine Kombination dieser Techniken verwenden.
Instrumentieren einer Anwendung
Die Instrumentierung ist ein wichtiger Bestandteil des Überwachungsprozesses. Sie können sinnvolle Entscheidungen zur Leistung und Integrität eines Systems treffen, wenn Sie zuerst die Daten erfassen, mit denen Sie diese Entscheidungen treffen können. Die Informationen, die Sie mithilfe der Instrumentierung sammeln, sollten ausreichen, um die Leistung zu bewerten, Probleme zu diagnostizieren und Entscheidungen zu treffen, ohne dass Sie sich bei einem Remoteproduktionsserver anmelden müssen, um die Ablaufverfolgung (und das Debuggen) manuell durchzuführen. Instrumentierungsdaten umfassen in der Regel Metriken und Informationen, die in Ablaufverfolgungsprotokolle geschrieben werden.
Der Inhalt eines Ablaufverfolgungsprotokolls kann das Ergebnis von Textdaten sein, die von der Anwendung oder binärdaten geschrieben werden, die als Ergebnis eines Ablaufverfolgungsereignisses erstellt werden, wenn die Anwendung die Ereignisablaufverfolgung für Windows (ETW) verwendet. Sie können auch aus Systemprotokollen generiert werden, die Ereignisse aufzeichnen, die sich aus Teilen der Infrastruktur ergeben, z. B. einem Webserver. Textprotokollnachrichten sind oft so konzipiert, dass sie lesbar sind, aber sie sollten auch in einem Format geschrieben werden, das es einem automatisierten System ermöglicht, sie einfach zu analysieren.
Außerdem sollten Sie Protokolle kategorisieren. Schreiben Sie nicht alle Ablaufverfolgungsdaten in ein einzelnes Protokoll, sondern verwenden Sie separate Protokolle, um die Ablaufverfolgungsausgabe aus verschiedenen betrieblichen Aspekten des Systems aufzuzeichnen. Anschließend können Sie Protokollnachrichten schnell filtern, indem Sie aus dem entsprechenden Protokoll lesen, anstatt eine einzelne langwierige Datei verarbeiten zu müssen. Schreiben Sie niemals Informationen mit unterschiedlichen Sicherheitsanforderungen (z. B. Überwachungsinformationen und Debuggingdaten) in dasselbe Protokoll.
Hinweis
Ein Protokoll kann als Datei im Dateisystem implementiert werden, oder es wird in einem anderen Format gespeichert, z. B. ein Blob im Blobspeicher. Protokollinformationen können auch in strukturierteren Speicher gespeichert werden, z. B. Zeilen in einer Tabelle.
Metriken sind im Allgemeinen ein Maß oder eine Anzahl von Aspekten oder Ressourcen im System zu einem bestimmten Zeitpunkt mit mindestens einem zugeordneten Tag oder Dimension (manchmal auch als Stichprobe bezeichnet). Eine einzelne Instanz einer Metrik ist in der Regel nicht isoliert nützlich. Stattdessen müssen Metriken im Laufe der Zeit erfasst werden. Das wichtigste Problem, das Sie berücksichtigen sollten, ist die Metrik, die Sie aufzeichnen sollten, und wie häufig. Das Generieren von Daten für Metriken kann zu häufig eine erhebliche zusätzliche Belastung für das System verursachen, während das Erfassen von Metriken selten dazu führen kann, dass Sie die Umstände verpassen, die zu einem signifikanten Ereignis führen. Die Überlegungen variieren von Metrik zu Metrik. Die CPU-Auslastung auf einem Server kann z. B. von Sekunde zu Sekunde schwanken, aber eine hohe Auslastung ist nur dann ein Problem, wenn sie mehrere Minuten lang bestehen bleibt.
Informationen zum Korrelieren von Daten
Sie können einzelne Leistungsindikatoren auf Systemebene ganz einfach überwachen, Metriken für Ressourcen erfassen und Anwendungsablaufverfolgungsinformationen aus verschiedenen Protokolldateien abrufen. Einige Formen der Überwachung erfordern jedoch die Analyse- und Diagnosephase in der Überwachungspipeline, um die aus mehreren Quellen abgerufenen Daten zu korrelieren. Diese Daten können mehrere Formen in den Rohdaten haben, und der Analyseprozess muss mit ausreichenden Instrumentierungsdaten versehen werden, um diese verschiedenen Formulare zuordnen zu können. Beispielsweise kann eine Aufgabe auf Der Ebene des Anwendungsframeworks durch eine Thread-ID identifiziert werden. Innerhalb einer Anwendung kann dieselbe Arbeit der Benutzer-ID für den Benutzer zugeordnet werden, der diese Aufgabe ausführt.
Außerdem ist es unwahrscheinlich, dass eine 1:1-Zuordnung zwischen Threads und Benutzeranforderungen besteht, da asynchrone Vorgänge dieselben Threads möglicherweise wiederverwenden, um Vorgänge im Auftrag von mehr als einem Benutzer auszuführen. Um weitere Probleme zu erschweren, kann eine einzelne Anforderung von mehreren Threads verarbeitet werden, da die Ausführung über das System erfolgt. Ordnen Sie nach Möglichkeit jede Anforderung einer eindeutigen Aktivitäts-ID zu, die im Rahmen des Anforderungskontexts über das System weitergegeben wird. (Die Technik zum Generieren und Einschließen von Aktivitäts-IDs in Ablaufverfolgungsinformationen hängt von der Technologie ab, die zum Erfassen der Ablaufverfolgungsdaten verwendet wird.)
Alle Überwachungsdaten sollten auf die gleiche Weise zeitstempelt werden. Zeichnen Sie aus Gründen der Konsistenz alle Datums- und Uhrzeitangaben mithilfe der koordinierten Weltzeit auf. Auf diese Weise können Sie Ereignissequenzen einfacher nachverfolgen.
Hinweis
Computer, die in verschiedenen Zeitzonen und Netzwerken arbeiten, werden möglicherweise nicht synchronisiert. Verwenden Sie Zeitstempel nicht allein zum Korrelieren von Instrumentierungsdaten, die mehrere Computer umfassen.
Informationen, die in die Instrumentierungsdaten aufgenommen werden sollen
Berücksichtigen Sie die folgenden Punkte, wenn Sie entscheiden, welche Instrumentierungsdaten Sie sammeln müssen:
Stellen Sie sicher, dass informationen, die von Ablaufverfolgungsereignissen erfasst werden, maschinen- und lesbar sind. Übernehmen Sie gut definierte Schemas für diese Informationen, um die automatisierte Verarbeitung von Protokolldaten über Systeme hinweg zu vereinfachen und Konsistenz für Vorgänge und Technische Mitarbeiter zu gewährleisten, die die Protokolle lesen. Schließen Sie Umgebungsinformationen wie die Bereitstellungsumgebung, den Computer, auf dem der Prozess ausgeführt wird, die Details des Prozesses und den Aufrufstapel ein.
Aktivieren Sie die Profilerstellung nur bei Bedarf, da sie einen erheblichen Aufwand für das System verursachen kann. Die Profilerstellung mithilfe von Instrumentation zeichnet jedes Mal ein Ereignis (z. B. ein Methodenaufruf) auf, während beim Sampling nur ausgewählte Ereignisse aufgezeichnet werden. Die Auswahl kann zeitbasiert (einmal alle n Sekunden) oder häufigkeitsbasiert (einmal alle n Anforderungen) sein. Wenn Ereignisse sehr häufig auftreten, kann die Profilerstellung durch instrumentierung zu viel Belastung verursachen und sich selbst auf die Gesamtleistung auswirken. In diesem Fall kann der Sampling-Ansatz bevorzugt werden. Wenn die Häufigkeit von Ereignissen jedoch niedrig ist, kann das Sampling sie nicht verpassen. In diesem Fall könnte die Instrumentierung der bessere Ansatz sein.
Stellen Sie ausreichendEn Kontext bereit, damit ein Entwickler oder Administrator die Quelle jeder Anforderung ermitteln kann. Dies kann eine Form der Aktivitäts-ID sein, die eine bestimmte Instanz einer Anforderung identifiziert. Es kann auch Informationen enthalten, die verwendet werden können, um diese Aktivität mit der ausgeführten Rechenarbeit und den verwendeten Ressourcen zu korrelieren. Diese Arbeit kann Prozess- und Maschinengrenzen überschreiten. Für die Messung sollte der Kontext auch (entweder direkt oder indirekt über andere korrelierte Informationen) einen Verweis auf den Kunden enthalten, der die Anforderung verursacht hat. Dieser Kontext enthält wertvolle Informationen zum Zeitpunkt der Erfassung der Überwachungsdaten über den Anwendungszustand.
Notieren Sie alle Anforderungen und die Standorte oder Regionen, aus denen diese Anforderungen gestellt werden. Anhand dieser Informationen kann ermittelt werden, ob standortspezifische Hotspots vorhanden sind. Diese Informationen können auch hilfreich sein, um zu bestimmen, ob eine Anwendung oder die von ihr verwendeten Daten neu partitioniert werden sollen.
Erfassen und erfassen Sie die Details von Ausnahmen sorgfältig. Häufig geht wichtige Debuginformationen aufgrund einer schlechten Ausnahmebehandlung verloren. Erfassen Sie die vollständigen Details der Von der Anwendung ausgelösten Ausnahmen, einschließlich innerer Ausnahmen und anderer Kontextinformationen. Schließen Sie den Aufrufstapel nach Möglichkeit ein.
Seien Sie in den Daten konsistent, die die verschiedenen Elemente Ihrer Anwendungserfassung enthalten, da dies bei der Analyse von Ereignissen und derEn Korrelierung mit Benutzeranforderungen helfen kann. Erwägen Sie die Verwendung eines umfassenden und konfigurierbaren Protokollierungspakets zum Sammeln von Informationen, anstatt von Entwicklern, denselben Ansatz zu übernehmen, wie sie verschiedene Teile des Systems implementieren. Sammeln Sie Daten aus Schlüsselleistungsindikatoren, z. B. dem Ausgeführten E/A-Volumen, der Netzwerkauslastung, der Anzahl der Anforderungen, der Arbeitsspeichernutzung und der CPU-Auslastung. Einige Infrastrukturdienste stellen möglicherweise ihre eigenen spezifischen Leistungsindikatoren bereit, z. B. die Anzahl der Verbindungen zu einer Datenbank, die Rate, mit der Transaktionen ausgeführt werden, und die Anzahl der Transaktionen, die erfolgreich sind oder fehlschlagen. Anwendungen können auch eigene spezifische Leistungsindikatoren definieren.
Protokollieren Sie alle Aufrufe an externe Dienste, z. B. Datenbanksysteme, Webdienste oder andere Dienste auf Systemebene, die Teil der Infrastruktur sind. Notieren Sie Informationen über die Zeit, die für die Ausführung jedes Anrufs und den Erfolg oder Fehler des Anrufs dauert. Erfassen Sie nach Möglichkeit Informationen zu allen Wiederholungsversuchen und Fehlern für vorübergehende Fehler, die auftreten.
Sicherstellen der Kompatibilität mit Telemetriesystemen
In vielen Fällen werden die von der Instrumentierung erzeugten Informationen als Eine Reihe von Ereignissen generiert und zur Verarbeitung und Analyse an ein separates Telemetriesystem übergeben. Ein Telemetriesystem ist in der Regel unabhängig von einer bestimmten Anwendung oder Technologie, erwartet jedoch, dass Informationen einem bestimmten Format folgen, das normalerweise durch ein Schema definiert wird. Das Schema gibt effektiv einen Vertrag an, der die Datenfelder und Typen definiert, die das Telemetriesystem aufnehmen kann. Das Schema sollte generalisiert werden, damit Daten von einer Reihe von Plattformen und Geräten empfangen werden.
Ein allgemeines Schema sollte Felder enthalten, die allen Instrumentierungsereignissen gemeinsam sind, z. B. den Ereignisnamen, die Ereigniszeit, die IP-Adresse des Absenders und die Details, die zum Korrelieren mit anderen Ereignissen erforderlich sind (z. B. eine Benutzer-ID, eine Geräte-ID und eine Anwendungs-ID). Denken Sie daran, dass eine beliebige Anzahl von Geräten Ereignisse auslösen kann, sodass das Schema nicht vom Gerätetyp abhängig sein sollte. Darüber hinaus können verschiedene Geräte Ereignisse für dieselbe Anwendung auslösen; Die Anwendung unterstützt möglicherweise Roaming oder eine andere Form der geräteübergreifenden Verteilung.
Das Schema kann auch Domänenfelder enthalten, die für ein bestimmtes Szenario relevant sind, das in verschiedenen Anwendungen üblich ist. Dies kann Informationen zu Ausnahmen, Anwendungsstart- und Endereignissen sowie Erfolg oder Fehler von Webdienst-API-Aufrufen sein. Alle Anwendungen, die dieselbe Gruppe von Domänenfeldern verwenden, sollten denselben Satz von Ereignissen ausgeben, sodass eine Reihe allgemeiner Berichte und Analysen erstellt werden kann.
Schließlich kann ein Schema benutzerdefinierte Felder zum Erfassen der Details anwendungsspezifischer Ereignisse enthalten.
Bewährte Methoden für Instrumentierungsanwendungen
In der folgenden Liste werden bewährte Methoden für die Instrumentierung einer verteilten Anwendung zusammengefasst, die in der Cloud ausgeführt wird.
Vereinfachen Sie das Lesen und Analysieren von Protokollen. Verwenden Sie nach Möglichkeit die strukturierte Protokollierung. Seien Sie präzise und beschreibend in Protokollnachrichten.
Identifizieren Sie in allen Protokollen die Quelle, und geben Sie Kontext- und Anzeigedauerinformationen an, während jeder Protokolldatensatz geschrieben wird.
Verwenden Sie die gleiche Zeitzone und dasselbe Format für alle Zeitstempel. Dies hilft beim Korrelieren von Ereignissen für Vorgänge, die Hardware und Dienste umfassen, die in verschiedenen geografischen Regionen ausgeführt werden.
Kategorisieren Sie Protokolle, und schreiben Sie Nachrichten in die entsprechende Protokolldatei.
Geben Sie keine vertraulichen Informationen über das System oder persönliche Informationen zu Benutzern offen. Beruben Sie diese Informationen, bevor sie protokolliert werden, stellen Sie jedoch sicher, dass die relevanten Details beibehalten werden. Entfernen Sie z. B. die ID und das Kennwort aus allen Datenbankverbindungszeichenfolgen, schreiben Sie jedoch die restlichen Informationen in das Protokoll, damit ein Analyst bestimmen kann, dass das System auf die richtige Datenbank zugreift. Protokollieren Sie alle kritischen Ausnahmen, aktivieren und deaktivieren Sie jedoch die Protokollierung für niedrigere Ausnahmen und Warnungen. Erfassen und protokollieren Sie außerdem alle Wiederholungslogikinformationen. Diese Daten können nützlich sein, um die vorübergehende Integrität des Systems zu überwachen.
Ablaufverfolgung von Prozessaufrufen, z. B. Anforderungen an externe Webdienste oder Datenbanken.
Kombinieren Sie Protokollnachrichten nicht mit unterschiedlichen Sicherheitsanforderungen in derselben Protokolldatei. Schreiben Sie beispielsweise keine Debug- und Überwachungsinformationen in dasselbe Protokoll.
Stellen Sie mit Ausnahme von Überwachungsereignissen sicher, dass alle Protokollierungsaufrufe feuer- und vergessene Vorgänge sind, die den Fortschritt von Geschäftsvorgängen nicht blockieren. Überwachungsereignisse sind außergewöhnlich, da sie für das Unternehmen kritisch sind und als grundlegender Bestandteil von Geschäftsvorgängen klassifiziert werden können.
Stellen Sie sicher, dass die Protokollierung erweiterbar ist und keine direkten Abhängigkeiten von einem konkreten Ziel aufweist. Definieren Sie z. B. anstelle von Informationen mithilfe von System.Diagnostics.Trace eine abstrakte Schnittstelle (z. B. ILogger), die Protokollierungsmethoden verfügbar macht und über geeignete Mittel implementiert werden kann.
Stellen Sie sicher, dass die gesamte Protokollierung fehlsicher ist und niemals kaskadierende Fehler auslöst. Die Protokollierung darf keine Ausnahmen auslösen.
Behandeln Sie die Instrumentierung als fortlaufenden iterativen Prozess und überprüfen Sie Protokolle regelmäßig, nicht nur, wenn ein Problem vorliegt.
Sammeln und Speichern von Daten
Die Erfassungsphase des Überwachungsprozesses befasst sich mit dem Abrufen der von der Instrumentierung generierten Informationen, der Formatierung dieser Daten, um die Analyse-/Diagnosestufe zu vereinfachen und die transformierten Daten in einem zuverlässigen Speicher zu speichern. Die Instrumentierungsdaten, die Sie aus verschiedenen Teilen eines verteilten Systems sammeln, können an verschiedenen Standorten und mit unterschiedlichen Formaten gehalten werden. Ihr Anwendungscode kann beispielsweise Ablaufverfolgungsprotokolldateien generieren und Anwendungsereignisprotokolldaten generieren, während Leistungsindikatoren, die wichtige Aspekte der Infrastruktur überwachen, die Ihre Anwendung verwendet, über andere Technologien erfasst werden können. Alle Komponenten und Dienste von Drittanbietern, die Ihre Anwendung verwendet, können Instrumentierungsinformationen in verschiedenen Formaten bereitstellen, indem separate Ablaufverfolgungsdateien, Blobspeicher oder sogar ein benutzerdefinierter Datenspeicher verwendet werden.
Die Datensammlung erfolgt häufig über einen Sammlungsdienst, der von der Anwendung, die die Instrumentierungsdaten generiert, autonom ausgeführt werden kann. Abbildung 2 zeigt ein Beispiel für diese Architektur, wobei das Datensammlungssubsystem der Instrumentierung hervorgehoben wird.

Abbildung 2: Sammeln von Instrumentierungsdaten.
Dies ist eine vereinfachte Ansicht. Der Sammlungsdienst ist nicht unbedingt ein einzelner Prozess und kann viele Komponenten umfassen, die auf verschiedenen Computern ausgeführt werden, wie in den folgenden Abschnitten beschrieben. Darüber hinaus können lokale Komponenten, die außerhalb des Sammlungsdiensts ausgeführt werden, sofort die Analyseaufgaben ausführen, wenn die Analyse einiger Telemetriedaten schnell durchgeführt werden muss (wie im Abschnitt "Unterstützen der Heißen-, Warm- und Kaltanalyse " weiter unten in diesem Dokument beschrieben). Abbildung 2 zeigt diese Situation für ausgewählte Ereignisse. Nach der analytischen Verarbeitung können die Ergebnisse direkt an das Visualisierungs- und Warnsubsystem gesendet werden. Daten, die warm oder kalt analysiert werden, werden im Speicher aufbewahrt, während sie auf die Verarbeitung wartet.
Für Azure-Anwendungen und -Dienste bietet Azure Diagnostics eine mögliche Lösung zum Erfassen von Daten. Azure Diagnostics sammelt Daten aus den folgenden Quellen für jeden Computeknoten, aggregiert sie und lädt sie dann in Azure Storage hoch:
- IIS-Protokolle
- IIS-Protokolle für fehlgeschlagene Anforderungen
- Windows-Ereignisprotokolle
- Leistungsindikatoren
- Absturzabbilder
- Infrastrukturprotokolle der Azure-Diagnose
- Benutzerdefinierte Fehlerprotokolle
- .NET EventSource
- Manifestbasierte ETW
Weitere Informationen finden Sie im Artikel Azure: Telemetriegrundlagen und Problembehandlung.
Strategien zum Sammeln von Instrumentierungsdaten
Angesichts der elastischen Natur der Cloud und um zu vermeiden, dass Telemetriedaten von jedem Knoten im System manuell abgerufen werden müssen, sollten Sie die Daten an einen zentralen Ort übertragen und konsolidiert. In einem System, das mehrere Rechenzentren umfasst, kann es nützlich sein, zuerst Daten nach Region zu sammeln, zu konsolidieren und zu speichern und dann die Regionalen Daten in einem einzigen zentralen System zu aggregieren.
Um die Nutzung der Bandbreite zu optimieren, können Sie sich entscheiden, weniger dringende Daten in Datenblöcken als Batches zu übertragen. Die Daten dürfen jedoch nicht auf unbestimmte Zeit verzögert werden, insbesondere, wenn sie zeitabhängige Informationen enthält.
Daten zur Zieh- und Pushinstrumentation
Das Datensammlungs-Subsystem der Instrumentierung kann Instrumentierungsdaten aus den verschiedenen Protokollen und anderen Quellen für jede Instanz der Anwendung (das Pullmodell) aktiv abrufen. Sie kann auch als passiver Empfänger fungieren, der wartet, bis die Daten von den Komponenten gesendet werden, die jede Instanz der Anwendung bilden (das Pushmodell).
Ein Ansatz zur Implementierung des Pullmodells besteht darin, Überwachungs-Agents zu verwenden, die lokal mit jeder Instanz der Anwendung ausgeführt werden. Ein Überwachungs-Agent ist ein separater Prozess, der regelmäßig Telemetriedaten abruft (Pulls), die am lokalen Knoten gesammelt werden, und schreibt diese Informationen direkt in den zentralisierten Speicher, den alle Instanzen der Anwendung teilen. Dies ist der Mechanismus, den Azure Diagnostics implementiert. Jede Instanz einer Azure-Web- oder Workerrolle kann so konfiguriert werden, dass Diagnose- und andere Ablaufverfolgungsinformationen erfasst werden, die lokal gespeichert sind. Der Überwachungs-Agent, der zusammen mit jeder Instanz ausgeführt wird, kopiert die angegebenen Daten in Azure Storage. Der Artikel Enabling Diagnostics in Azure Cloud Services and Virtual Machines enthält weitere Details zu diesem Prozess. Einige Elemente, z. B. IIS-Protokolle, Absturzabbilder und benutzerdefinierte Fehlerprotokolle, werden in BLOB-Speicher geschrieben. Daten aus dem Windows-Ereignisprotokoll, ETW-Ereignissen und Leistungsindikatoren werden im Tabellenspeicher aufgezeichnet. Abbildung 3 veranschaulicht diesen Mechanismus.
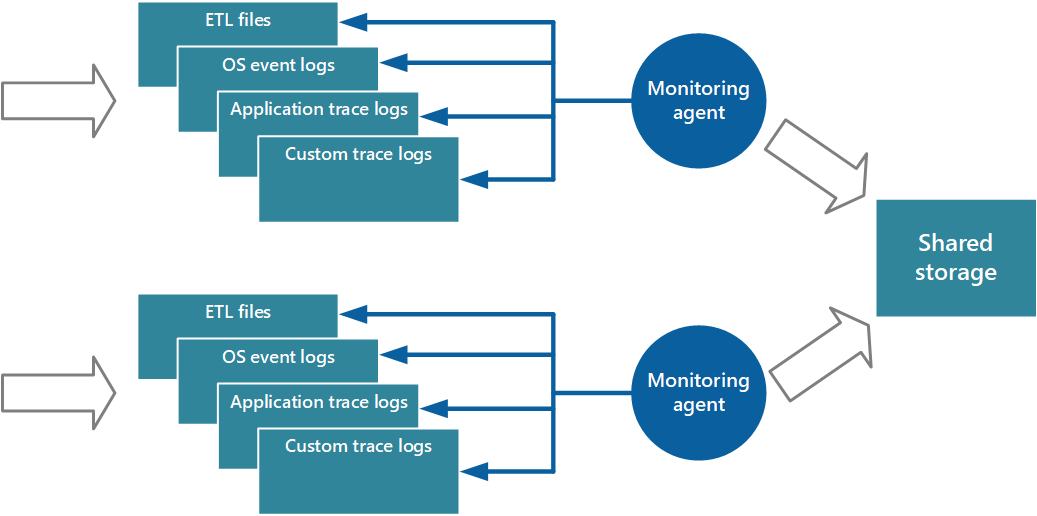
Abbildung 3: Verwenden eines Überwachungs-Agents zum Abrufen von Informationen und Schreiben in freigegebenen Speicher.
Hinweis
Die Verwendung eines Überwachungs-Agents eignet sich ideal zum Erfassen von Instrumentierungsdaten, die natürlich aus einer Datenquelle abgerufen werden. Ein Beispiel sind Informationen aus SQL Server Dynamic Management Views oder der Länge einer Azure Service Bus-Warteschlange.
Es ist machbar, den soeben beschriebenen Ansatz zum Speichern von Telemetriedaten für eine kleine Anwendung zu verwenden, die auf einer begrenzten Anzahl von Knoten an einem einzigen Ort ausgeführt wird. Eine komplexe, hoch skalierbare, globale Cloudanwendung kann jedoch große Datenmengen aus Hunderten von Web- und Workerrollen, Datenbankshards und anderen Diensten generieren. Diese Datenflut kann die verfügbare E/A-Bandbreite mit einem einzigen zentralen Standort leicht überfordern. Daher muss Ihre Telemetrielösung skalierbar sein, um zu verhindern, dass sie als Engpass fungiert, wenn das System erweitert wird. Im Idealfall sollte Ihre Lösung einen Grad an Redundanz enthalten, um die Risiken zu reduzieren, dass wichtige Überwachungsinformationen verloren gehen (z. B. Überwachungs- oder Abrechnungsdaten), wenn ein Teil des Systems fehlschlägt.
Um diese Probleme zu beheben, können Sie Warteschlange implementieren, wie in Abbildung 4 dargestellt. In dieser Architektur sendet der lokale Überwachungs-Agent (sofern er entsprechend konfiguriert werden kann) oder benutzerdefinierter Datensammlungsdienst (wenn nicht) Daten in eine Warteschlange. Ein separater Prozess, der asynchron ausgeführt wird (der Speicherschreibdienst in Abbildung 4) übernimmt die Daten in dieser Warteschlange und schreibt ihn in freigegebenen Speicher. Eine Nachrichtenwarteschlange eignet sich für dieses Szenario, da sie die "mindestens einmal"-Semantik bietet, mit der sichergestellt wird, dass in die Warteschlange gestellte Daten nach dem Posten nicht verloren gehen. Sie können den Speicherschreibdienst mithilfe einer separaten Workerrolle implementieren.
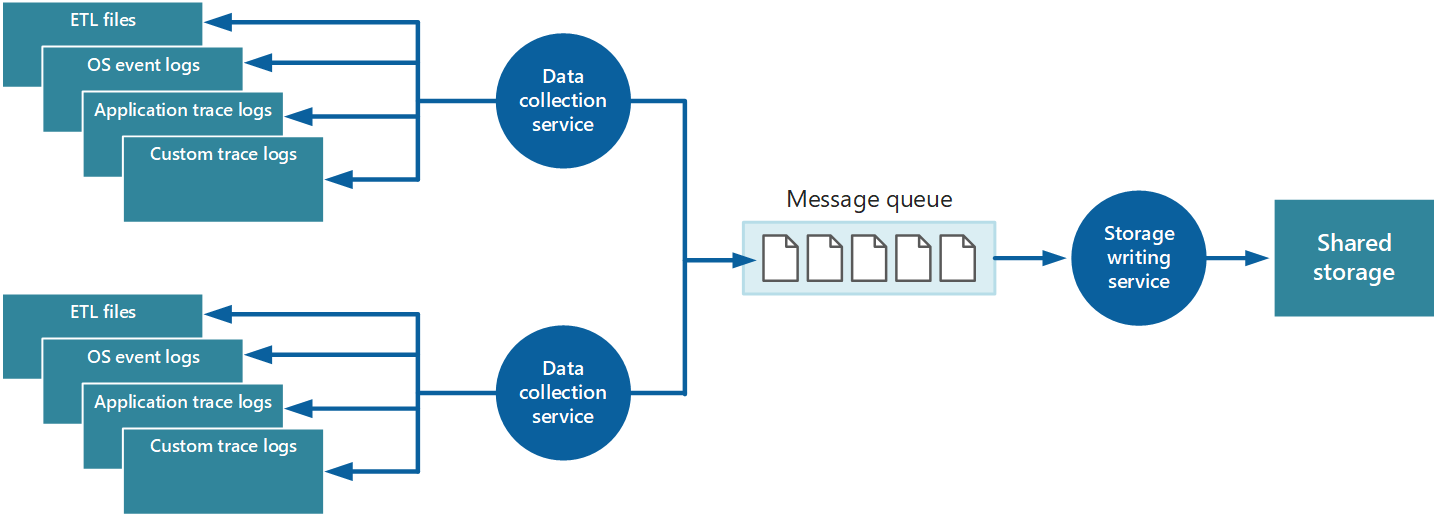
Abbildung 4: Verwenden einer Warteschlange zum Puffern von Instrumentierungsdaten.
Der lokale Datensammlungsdienst kann einer Warteschlange unmittelbar nach dem Empfang Daten hinzufügen. Die Warteschlange fungiert als Puffer, und der Speicherschreibdienst kann die Daten in ihrem eigenen Tempo abrufen und schreiben. Standardmäßig wird eine Warteschlange auf First-In-, First-Out-Basis ausgeführt. Sie können nachrichten jedoch priorisieren, um sie durch die Warteschlange zu beschleunigen, wenn sie Daten enthalten, die schneller behandelt werden müssen. Weitere Informationen finden Sie im Muster "Priority Queue". Alternativ können Sie unterschiedliche Kanäle (z. B. ServiceBus-Themen) verwenden, um Daten je nach erforderlicher Analyseverarbeitung an verschiedene Ziele zu leiten.
Zur Skalierbarkeit können Sie mehrere Instanzen des Speicherschreibdiensts ausführen. Wenn eine große Anzahl von Ereignissen vorhanden ist, können Sie einen Event Hub verwenden, um die Daten an verschiedene Computeressourcen für die Verarbeitung und Speicherung zu verteilen.
Konsolidieren von Instrumentierungsdaten
Die Instrumentierungsdaten, die der Datensammlungsdienst aus einer einzelnen Instanz einer Anwendung abruft, bietet eine lokalisierte Ansicht der Integrität und Leistung dieser Instanz. Um die Gesamtintegrität des Systems zu bewerten, ist es erforderlich, einige Aspekte der Daten in den lokalen Ansichten zu konsolidieren. Sie können dies ausführen, nachdem die Daten gespeichert wurden, aber in einigen Fällen können Sie sie auch erreichen, wenn die Daten gesammelt werden. Anstatt direkt in freigegebenen Speicher geschrieben zu werden, können die Instrumentierungsdaten einen separaten Datenkonsolidierungsdienst durchlaufen, der Daten kombiniert und als Filter- und Bereinigungsprozess fungiert. Beispielsweise können Instrumentierungsdaten, die dieselben Korrelationsinformationen wie eine Aktivitäts-ID enthalten, amalgamatiert werden. (Es ist möglich, dass ein Benutzer mit dem Ausführen eines Geschäftsvorgangs auf einem Knoten beginnt und dann im Falle eines Knotenausfalls auf einen anderen Knoten übertragen wird, oder je nachdem, wie der Lastenausgleich konfiguriert ist.) Dieser Vorgang kann auch duplizierte Daten erkennen und entfernen (immer eine Möglichkeit, wenn der Telemetriedienst Nachrichtenwarteschlangen verwendet, um Instrumentierungsdaten an den Speicher zu übertragen). Abbildung 5 veranschaulicht ein Beispiel für diese Struktur.

Abbildung 5: Verwenden eines separaten Diensts zum Konsolidieren und Bereinigen von Instrumentierungsdaten.
Speichern von Instrumentierungsdaten
Die vorherigen Diskussionen haben eine eher vereinfachte Ansicht der Art und Weise dargestellt, in der Instrumentierungsdaten gespeichert werden. In Wirklichkeit kann es sinnvoll sein, die verschiedenen Informationstypen mithilfe von Technologien zu speichern, die am besten geeignet sind, um die Art und Weise zu verwenden, in der jeder Typ verwendet wird.
Beispielsweise weisen Azure-BLOB- und Tabellenspeicher einige Ähnlichkeiten auf die Art und Weise auf, auf die sie zugegriffen werden. Sie haben jedoch Einschränkungen in den Vorgängen, die Sie ausführen können, indem Sie sie verwenden, und die Granularität der Daten, die sie enthalten, ist ganz anders. Wenn Sie mehr Analysevorgänge ausführen müssen oder Volltext-Suchfunktionen für die Daten benötigen, ist es möglicherweise besser geeignet, Datenspeicher zu verwenden, der Funktionen bereitstellt, die für bestimmte Arten von Abfragen und Datenzugriff optimiert sind. Beispiel:
- Leistungsindikatordaten können in einer SQL-Datenbank gespeichert werden, um Ad-hoc-Analysen zu ermöglichen.
- Ablaufverfolgungsprotokolle können besser in Azure Cosmos DB gespeichert werden.
- Sicherheitsinformationen können in HDFS geschrieben werden.
- Informationen, die die Volltextsuche erfordern, können über Elasticsearch gespeichert werden (wodurch suchvorgänge auch mithilfe von Rich Indexing beschleunigt werden können).
Sie können einen zusätzlichen Dienst implementieren, der die Daten regelmäßig aus freigegebenem Speicher abruft, partitioniert und filtert die Daten entsprechend ihrem Zweck und schreibt sie dann in eine entsprechende Gruppe von Datenspeichern, wie in Abbildung 6 dargestellt. Ein alternativer Ansatz besteht darin, diese Funktionalität in den Konsolidierungs- und Bereinigungsprozess einzuschließen und die Daten direkt in diese Speicher zu schreiben, da sie abgerufen wird, anstatt sie in einem zwischengespeicherten freigegebenen Speicherbereich zu speichern. Jeder Ansatz hat seine Vor- und Nachteile. Durch die Implementierung eines separaten Partitionierungsdiensts wird die Auslastung des Konsolidierungs- und Bereinigungsdiensts verringert, und es kann mindestens einige der partitionierten Daten bei Bedarf neu generiert werden (je nachdem, wie viele Daten im freigegebenen Speicher aufbewahrt werden). Es verbraucht jedoch zusätzliche Ressourcen. Außerdem kann es eine Verzögerung zwischen dem Empfang von Instrumentierungsdaten aus jeder Anwendungsinstanz und der Konvertierung dieser Daten in umsetzbare Informationen geben.

Abbildung 6: Partitionieren von Daten gemäß analytischen und Speicheranforderungen.
Die gleichen Instrumentierungsdaten können für mehrere Zwecke erforderlich sein. Beispielsweise können Leistungsindikatoren verwendet werden, um eine historische Ansicht der Systemleistung im Laufe der Zeit bereitzustellen. Diese Informationen können mit anderen Nutzungsdaten kombiniert werden, um Kundenabrechnungsinformationen zu generieren. In diesen Fällen können dieselben Daten an mehr als ein Ziel gesendet werden, z. B. an eine Dokumentdatenbank, die als langfristiger Speicher für die Aufbewahrung von Abrechnungsinformationen fungieren kann, und ein mehrdimensionaler Speicher für die Behandlung komplexer Leistungsanalysen.
Sie sollten auch überlegen, wie dringend die Daten erforderlich sind. Daten, die Informationen für die Warnung bereitstellen, müssen schnell aufgerufen werden, sodass sie in schneller Datenspeicherung gehalten und indiziert oder strukturiert werden sollten, um die vom Warnungssystem ausgeführten Abfragen zu optimieren. In einigen Fällen kann es erforderlich sein, dass der Telemetriedienst die Daten auf jedem Knoten sammelt, um Daten lokal zu formatieren und zu speichern, damit eine lokale Instanz des Warnsystems Sie schnell über Probleme benachrichtigen kann. Dieselben Daten können an den in den vorherigen Diagrammen dargestellten Speicherschreibdienst verteilt und zentral gespeichert werden, wenn sie auch für andere Zwecke erforderlich sind.
Informationen, die für eine umfassendere Analyse, für die Berichterstellung und für das Erkennen historischer Trends verwendet werden, sind weniger dringend und können auf eine Weise gespeichert werden, die Data Mining- und Ad-hoc-Abfragen unterstützt. Weitere Informationen finden Sie im Abschnitt "Unterstützen der heißen, warmen und kalten Analyse " weiter unten in diesem Dokument.
Protokolldrehung und Datenaufbewahrung
Die Instrumentierung kann erhebliche Datenmengen generieren. Diese Daten können an mehreren Stellen gespeichert werden, beginnend mit den rohen Protokolldateien, Ablaufverfolgungsdateien und anderen Informationen, die an jedem Knoten erfasst werden, in der konsolidierten, bereinigten und partitionierten Ansicht dieser Daten, die im freigegebenen Speicher gespeichert sind. In einigen Fällen können die ursprünglichen Rohquelldaten nach der Verarbeitung und Übertragung der Daten aus jedem Knoten entfernt werden. In anderen Fällen kann es notwendig oder einfach nützlich sein, die Rohinformationen zu speichern. Beispielsweise können Daten, die für Debuggingzwecke generiert werden, am besten in der rohen Form verfügbar sein, aber dann schnell verworfen werden, nachdem fehler behoben wurden.
Leistungsdaten haben oft eine längere Lebensdauer, sodass sie zum Erkennen von Leistungstrends und zur Kapazitätsplanung verwendet werden kann. Die konsolidierte Ansicht dieser Daten wird in der Regel für einen begrenzten Zeitraum online gehalten, um schnellen Zugriff zu ermöglichen. Danach kann sie archiviert oder verworfen werden. Daten, die für Die Metering- und Abrechnungskunden gesammelt werden, müssen möglicherweise unbegrenzt gespeichert werden. Darüber hinaus können regulatorische Anforderungen festlegen, dass informationen, die für Überwachungs- und Sicherheitszwecke gesammelt werden, ebenfalls archiviert und gespeichert werden müssen. Auch diese Daten sind vertraulich und müssen möglicherweise verschlüsselt oder anderweitig geschützt werden, um mögliche Manipulationen zu verhindern. Sie sollten niemals die Kennwörter von Benutzern oder andere Informationen aufzeichnen, die verwendet werden können, um Identitätsbetrug zu übernehmen. Diese Details sollten aus den Daten entfernt werden, bevor sie gespeichert werden.
Down-Sampling
Es ist nützlich, historische Daten zu speichern, damit Sie langfristige Trends erkennen können. Anstatt alte Daten vollständig zu speichern, kann es möglich sein, die Daten abzubilden, um die Auflösung zu reduzieren und Speicherkosten zu sparen. Als Beispiel können Sie daten konsolidieren, die länger als ein Monat alt sind, anstatt Minuten-nach-Minuten-Leistungsindikatoren zu speichern, um eine Stunden-nach-Stunden-Ansicht zu bilden.
Bewährte Methoden zum Sammeln und Speichern von Protokollierungsinformationen
In der folgenden Liste werden bewährte Methoden zum Erfassen und Speichern von Protokollierungsinformationen zusammengefasst:
Der Überwachungs-Agent oder der Datensammlungsdienst sollte als Out-of-Process-Dienst ausgeführt werden und sollte einfach bereitzustellen sein.
Alle Ausgaben des Überwachungs-Agents oder des Datensammlungsdiensts sollten ein agnostisches Format sein, das unabhängig vom Computer, Betriebssystem oder Netzwerkprotokoll ist. Geben Sie beispielsweise Informationen in einem selbst beschreibenden Format wie JSON, MessagePack oder Protobuf anstelle von ETL/ETW aus. Die Verwendung eines Standardformats ermöglicht dem System das Erstellen von Verarbeitungspipelines; Komponenten, die Daten im vereinbarten Format lesen, transformieren und senden, lassen sich problemlos integrieren.
Der Überwachungs- und Datensammlungsprozess muss ausfallsicher sein und darf keine kaskadierenden Fehlerbedingungen auslösen.
Im Falle eines vorübergehenden Fehlers beim Senden von Informationen an eine Datensenke sollte der Überwachungs-Agent oder der Datensammlungsdienst bereit sein, Telemetriedaten neu anzuordnen, sodass die neuesten Informationen zuerst gesendet werden. (Der Überwachungs-Agent/Datensammlungsdienst kann entscheiden, die älteren Daten abzulegen oder lokal zu speichern und später zu übermitteln, um nach eigenem Ermessen aufzuholen.)
Analysieren von Daten und Diagnostizieren von Problemen
Ein wichtiger Teil des Überwachungs- und Diagnoseprozesses ist die Analyse der gesammelten Daten, um ein Bild des Gesamtwohls des Systems zu erhalten. Sie sollten Ihre eigenen KPIs und Leistungsmetriken definiert haben, und es ist wichtig zu verstehen, wie Sie die gesammelten Daten strukturieren können, um Ihre Analyseanforderungen zu erfüllen. Es ist auch wichtig zu verstehen, wie die daten, die in verschiedenen Metriken und Protokolldateien erfasst werden, korreliert werden, da diese Informationen entscheidend für die Nachverfolgung einer Folge von Ereignissen sein können und dabei helfen, Probleme zu diagnostizieren, die auftreten.
Wie im Abschnitt "Konsolidieren von Instrumentierungsdaten" beschrieben, werden die Daten für jeden Teil des Systems normalerweise lokal erfasst, müssen jedoch in der Regel mit Daten kombiniert werden, die an anderen Standorten generiert werden, die am System teilnehmen. Diese Informationen erfordern eine sorgfältige Korrelation, um sicherzustellen, dass Daten korrekt kombiniert werden. Beispielsweise können die Nutzungsdaten für einen Vorgang einen Knoten umfassen, der eine Website hostt, mit der ein Benutzer eine Verbindung herstellt, einen Knoten, der einen separaten Dienst ausführt, auf den im Rahmen dieses Vorgangs zugegriffen wird, und die Datenspeicherung, die auf einem anderen Knoten gespeichert ist. Diese Informationen müssen miteinander verknüpft werden, um eine Gesamtansicht der Ressourcen- und Verarbeitungsverwendung für den Vorgang bereitzustellen. Einige Vorverarbeitungs- und Filtervorgänge von Daten können auf dem Knoten auftreten, auf dem die Daten erfasst werden, während Aggregation und Formatierung eher auf einem zentralen Knoten auftreten.
Unterstützung der heißen, warmen und kalten Analyse
Das Analysieren und Neuformatieren von Daten für Visualisierungs-, Berichterstellungs- und Warnzwecke kann ein komplexer Prozess sein, der seine eigenen Ressourcen verbraucht. Einige Formen der Überwachung sind zeitkritisch und erfordern eine sofortige Analyse von Daten, um effektiv zu sein. Dies wird als heiße Analyse bezeichnet. Beispiele sind die Analysen, die für Warnungen und einige Aspekte der Sicherheitsüberwachung erforderlich sind (z. B. das Erkennen eines Angriffs auf das System). Daten, die für diese Zwecke erforderlich sind, müssen für eine effiziente Verarbeitung schnell verfügbar und strukturiert sein. In einigen Fällen kann es erforderlich sein, die Analyseverarbeitung auf die einzelnen Knoten zu verschieben, in denen die Daten gespeichert werden.
Andere Analyseformen sind weniger zeitkritisch und erfordern möglicherweise eine Berechnung und Aggregation, nachdem die Rohdaten empfangen wurden. Dies wird als warme Analyse bezeichnet. Die Leistungsanalyse fällt häufig in diese Kategorie. In diesem Fall ist ein isoliertes, einzelnes Leistungsereignis unwahrscheinlich statistisch signifikant. (Es kann durch eine plötzliche Spitze oder Glitch verursacht werden.) Die Daten aus einer Reihe von Ereignissen sollten ein zuverlässigeres Bild der Systemleistung liefern.
Warmanalyse kann auch zur Diagnose von Gesundheitsproblemen verwendet werden. Ein Integritätsereignis wird in der Regel über die heiße Analyse verarbeitet und kann sofort eine Warnung auslösen. Ein Operator sollte in der Lage sein, die Gründe für das Integritätsereignis zu untersuchen, indem die Daten aus dem warmen Pfad untersucht werden. Diese Daten sollten Informationen zu den Ereignissen enthalten, die zu dem Problem führen, das das Integritätsereignis verursacht hat.
Einige Arten von Überwachung generieren langfristigere Daten. Diese Analyse kann zu einem späteren Zeitpunkt durchgeführt werden, möglicherweise nach einem vordefinierten Zeitplan. In einigen Fällen muss die Analyse möglicherweise eine komplexe Filterung großer Datenmengen durchführen, die über einen bestimmten Zeitraum erfasst werden. Dies wird als kalte Analyse bezeichnet. Die wichtigste Anforderung besteht darin, dass die Daten sicher gespeichert werden, nachdem sie erfasst wurden. Die Verwendungsüberwachung und -überwachung erfordern beispielsweise zu regelmäßigen Zeitpunkten ein genaues Bild des Zustands des Systems, aber diese Zustandsinformationen müssen nicht sofort nach der Erfassung zur Verarbeitung zur Verfügung stehen.
Ein Operator kann auch die Kaltanalyse verwenden, um die Daten für die Predictive Health-Analyse bereitzustellen. Der Operator kann verlaufsgeschichtliche Informationen über einen bestimmten Zeitraum sammeln und in Verbindung mit den aktuellen Integritätsdaten (abgerufen aus dem heißen Pfad) verwenden, um Trends zu erkennen, die in Kürze zu Gesundheitlichen Problemen führen können. In diesen Fällen kann es notwendig sein, eine Warnung auszulösen, damit Korrekturmaßnahmen ergriffen werden können.
Korrelieren von Daten
Die erfassten Daten können eine Momentaufnahme des Systemzustands bereitstellen, aber der Zweck der Analyse besteht darin, diese Daten umsetzbar zu machen. Beispiel:
- Was hat eine intensive E/A-Belastung auf Systemebene zu einem bestimmten Zeitpunkt verursacht?
- Ist dies das Ergebnis einer großen Anzahl von Datenbankvorgängen?
- Spiegelt sich dies in den Antwortzeiten der Datenbank, der Anzahl der Transaktionen pro Sekunde und der Anwendungsantwortzeiten in derselben Zeit wider?
Wenn ja, kann eine Wartungsaktion, die die Last verringern könnte, sein, die Daten über mehr Server zu shardieren. Darüber hinaus können Ausnahmen aufgrund eines Fehlers auf jeder Ebene des Systems auftreten. Eine Ausnahme in einer Ebene löst häufig einen anderen Fehler in der obigen Ebene aus.
Aus diesen Gründen müssen Sie in der Lage sein, die verschiedenen Arten von Überwachungsdaten auf jeder Ebene zu korrelieren, um eine Gesamtansicht des Zustands des Systems und der Anwendungen zu erzeugen, die darauf ausgeführt werden. Sie können diese Informationen dann verwenden, um Entscheidungen darüber zu treffen, ob das System akzeptiert oder nicht funktioniert, und bestimmen, was getan werden kann, um die Qualität des Systems zu verbessern.
Wie im Abschnitt "Informationen zum Korrelieren von Daten" beschrieben, müssen Sie sicherstellen, dass die Rohinstrumentationsdaten ausreichende Kontext- und Aktivitäts-ID-Informationen enthalten, um die erforderlichen Aggregationen zum Korrelieren von Ereignissen zu unterstützen. Darüber hinaus können diese Daten in verschiedenen Formaten gespeichert werden, und es kann erforderlich sein, diese Informationen zu analysieren, um sie in ein standardisiertes Format für die Analyse zu konvertieren.
Problembehandlung und Diagnose von Problemen
Die Diagnose erfordert die Möglichkeit, die Ursache von Fehlern oder unerwartetem Verhalten zu bestimmen, einschließlich der Durchführung einer Ursachenanalyse. Die erforderlichen Informationen umfassen in der Regel Folgendes:
- Detaillierte Informationen aus Ereignisprotokollen und Ablaufverfolgungen, entweder für das gesamte System oder für ein angegebenes Subsystem während eines bestimmten Zeitfensters.
- Vollständige Stapelablaufverfolgungen, die sich aus Ausnahmen und Fehlern aller angegebenen Ebene ergeben, die innerhalb des Systems oder eines angegebenen Subsystems während eines bestimmten Zeitraums auftreten.
- Absturzabbilder für fehlgeschlagene Prozesse entweder an einer beliebigen Stelle im System oder für ein angegebenes Subsystem während eines bestimmten Zeitfensters.
- Aktivitätsprotokolle, in denen die Vorgänge aufgezeichnet werden, die entweder von allen Benutzern oder für ausgewählte Benutzer während eines bestimmten Zeitraums ausgeführt werden.
Die Analyse von Daten für Problembehandlungszwecke erfordert häufig ein tiefes technisches Verständnis der Systemarchitektur und der verschiedenen Komponenten, die die Lösung erstellen. Daher ist häufig ein großer Teil des manuellen Eingriffs erforderlich, um die Daten zu interpretieren, die Ursache von Problemen festzulegen und eine geeignete Strategie zu empfehlen, um sie zu beheben. Es kann sinnvoll sein, einfach eine Kopie dieser Informationen in ihrem ursprünglichen Format zu speichern und sie für die Kaltanalyse durch einen Experten zur Verfügung zu stellen.
Visualisieren von Daten und Auslösen von Warnungen
Ein wichtiger Aspekt jedes Überwachungssystems ist die Möglichkeit, die Daten so darzustellen, dass ein Betreiber schnell Trends oder Probleme erkennen kann. Wichtig ist auch die Möglichkeit, einen Operator schnell zu informieren, wenn ein bedeutendes Ereignis aufgetreten ist, das möglicherweise Aufmerksamkeit erfordert.
Die Datenpräsentation kann verschiedene Formen annehmen, einschließlich Visualisierung mithilfe von Dashboards, Warnungen und Berichten.
Visualisierung mithilfe von Dashboards
Die am häufigsten verwendete Möglichkeit zum Visualisieren von Daten besteht darin, Dashboards zu verwenden, die Informationen als Eine Reihe von Diagrammen, Diagrammen oder einer anderen Abbildung anzeigen können. Diese Elemente können parametrisiert werden, und ein Analyst sollte in der Lage sein, die wichtigen Parameter (z. B. den Zeitraum) für jede bestimmte Situation auszuwählen.
Dashboards können hierarchisch organisiert werden. Dashboards auf oberster Ebene können einen Überblick über die einzelnen Aspekte des Systems bieten, aber ermöglichen es einem Operator, einen Drilldown zu den Details zu ermöglichen. Beispielsweise sollte ein Dashboard, das die gesamte Datenträger-E/A für das System darstellt, zulassen, dass ein Analyst die E/A-Raten für jeden einzelnen Datenträger anzeigen kann, um festzustellen, ob ein oder mehrere bestimmte Geräte ein unverhältnismäßiges Datenverkehrsvolumen aufweisen. Im Idealfall sollte das Dashboard auch verwandte Informationen anzeigen, z. B. die Quelle jeder Anforderung (der Benutzer oder die Aktivität), die diese E/A generiert. Diese Informationen können dann verwendet werden, um zu bestimmen, ob (und wie) die Last gleichmäßiger auf geräteübergreifend verteilt wird und ob das System besser funktioniert, wenn weitere Geräte hinzugefügt wurden.
Ein Dashboard kann auch farbcodieren oder andere visuelle Hinweise verwenden, um Werte anzugeben, die anomale oder außerhalb eines erwarteten Bereichs angezeigt werden. Verwenden des vorherigen Beispiels:
- Ein Datenträger mit einer E/A-Rate, die sich der maximalen Kapazität über einen längeren Zeitraum nähert (ein Hot Disk), kann rot hervorgehoben werden.
- Ein Datenträger mit einer E/A-Rate, die in regelmäßigen Abständen über kurze Zeiträume (ein warmer Datenträger) ausgeführt wird, kann gelb hervorgehoben werden.
- Ein Datenträger, der eine normale Verwendung anzeigt, kann grün angezeigt werden.
Damit ein Dashboardsystem effektiv funktioniert, muss es über die Rohdaten verfügen, mit denen sie arbeiten können. Wenn Sie Ein eigenes Dashboardsystem erstellen oder ein Dashboard verwenden, das von einer anderen Organisation entwickelt wurde, müssen Sie wissen, welche Instrumentierungsdaten Sie sammeln müssen, auf welchen Granularitätsebenen und wie das Dashboard formatiert werden soll.
Neben der Anzeige von Informationen ermöglicht ein gutes Dashboard einem Analysten auch, Fragen zu diesen Informationen zu stellen. Einige Systeme bieten Verwaltungstools, mit denen ein Operator diese Aufgaben ausführen und die zugrunde liegenden Daten untersuchen kann. Je nach Repository, das zum Speichern dieser Informationen verwendet wird, kann es auch möglich sein, diese Daten direkt abzufragen oder in Tools wie Microsoft Excel für weitere Analysen und Berichte zu importieren.
Hinweis
Sie sollten den Zugriff auf Dashboards auf autorisierte Mitarbeiter beschränken, da diese Informationen möglicherweise kommerziell vertraulich sind. Sie sollten auch die zugrunde liegenden Daten für Dashboards schützen, um benutzer daran zu hindern, sie zu ändern.
Auslösen von Warnungen
Warnungen sind der Prozess der Analyse der Überwachungs- und Instrumentierungsdaten und das Generieren einer Benachrichtigung, wenn ein signifikantes Ereignis erkannt wird.
Durch Warnungen wird sichergestellt, dass das System fehlerfrei, reaktionsfähig und sicher bleibt. Es ist ein wichtiger Bestandteil jedes Systems, das den Benutzern, auf denen die Daten möglicherweise sofort reagieren müssen, Leistungs-, Verfügbarkeits- und Datenschutzgarantien vornimmt. Möglicherweise muss ein Operator über das Ereignis benachrichtigt werden, das die Warnung ausgelöst hat. Warnungen können auch verwendet werden, um Systemfunktionen wie die automatische Skalierung aufzurufen.
Die Warnung hängt in der Regel von den folgenden Instrumentierungsdaten ab:
- Sicherheitsereignisse. Wenn die Ereignisprotokolle angeben, dass wiederholte Authentifizierungs- oder Autorisierungsfehler auftreten, kann das System angegriffen werden und ein Operator sollte informiert werden.
- Leistungsmetriken: Das System muss schnell reagieren, wenn eine bestimmte Leistungsmetrik einen angegebenen Schwellenwert überschreitet.
- Verfügbarkeitsinformationen. Wenn ein Fehler erkannt wird, kann es erforderlich sein, ein oder mehrere Subsysteme schnell neu zu starten oder eine Sicherungsressource zu überschlagen. Wiederholte Fehler in einem Subsystem können schwerwiegendere Bedenken zeigen.
Betreiber erhalten möglicherweise Benachrichtigungsinformationen, indem sie viele Übermittlungskanäle wie E-Mail, ein Pagergerät oder eine SMS-Sms verwenden. Eine Warnung kann auch einen Hinweis darauf enthalten, wie kritisch eine Situation ist. Viele Warnungssysteme unterstützen Abonnentengruppen, und alle Operatoren, die Mitglieder derselben Gruppe sind, können dieselbe Gruppe von Warnungen empfangen.
Ein Warnsystem sollte anpassbar sein, und die entsprechenden Werte aus den zugrunde liegenden Instrumentierungsdaten können als Parameter bereitgestellt werden. Dieser Ansatz ermöglicht es einem Operator, Daten zu filtern und sich auf diese Schwellenwerte oder Kombinationen von Werten zu konzentrieren, die von Interesse sind. In einigen Fällen können die Rohinstrumentationsdaten dem Warnsystem bereitgestellt werden. In anderen Situationen ist es möglicherweise besser geeignet, aggregierte Daten anzugeben. (Eine Warnung kann beispielsweise ausgelöst werden, wenn die CPU-Auslastung für einen Knoten in den letzten 10 Minuten 90 Prozent überschritten hat). Die Details, die dem Warnsystem zur Verfügung gestellt werden, sollten auch alle geeigneten Zusammenfassungs- und Kontextinformationen enthalten. Diese Daten können dazu beitragen, die Möglichkeit zu verringern, dass falsch positive Ereignisse eine Warnung auslösen.
Berichterstattung
Durch die Berichterstellung entsteht ein Gesamtüberblick über das System. Es kann neben aktuellen Informationen auch historische Daten enthalten. Die Berichterstattungsanforderungen selbst sind in zwei allgemeine Kategorien unterteilt: operative Berichterstattung und Sicherheitsberichterstattung.
Die operative Berichterstellung umfasst in der Regel die folgenden Aspekte:
- Aggregierte Statistiken, die Ihnen helfen, die Ressourcennutzung im Gesamtsystem oder in bestimmten Teilsystemen während eines angegebenen Zeitfensters zu verstehen.
- Erkennen von Trends in der Ressourcennutzung im Gesamtsystem oder bestimmten Teilsystemen während eines angegebenen Zeitraums.
- Überwachen der Ausnahmen, die während eines bestimmten Zeitraums im gesamten System oder in bestimmten Subsystemen aufgetreten sind.
- Ermitteln der Effizienz der Anwendung hinsichtlich der bereitgestellten Ressourcen und Verstehen, ob das Ressourcenvolumen (und die damit verbundenen Kosten) reduziert werden kann, ohne die Leistung unnötig zu beeinträchtigen.
Die Sicherheitsberichterstattung befasst sich mit der Verfolgung der Nutzung des Systems durch Kunden. Dazu kann Folgendes gehören:
- Überwachen von Benutzervorgängen. Dazu müssen die einzelnen Anforderungen aufgezeichnet werden, die jeder Benutzer ausführt, zusammen mit Datums- und Uhrzeitangaben. Die Daten sollten so strukturiert sein, dass ein Administrator die Reihenfolge der Vorgänge, die ein Benutzer über einen bestimmten Zeitraum ausführt, schnell rekonstruieren kann.
- Nachverfolgen der Ressourcenverwendung durch den Benutzer. Dies erfordert eine Aufzeichnung, wie jede Anforderung für einen Benutzer auf die verschiedenen Ressourcen zugreift, die das System verfassen, und wie lange. Ein Administrator muss diese Daten verwenden können, um einen Nutzungsbericht von Benutzern über einen bestimmten Zeitraum zu generieren, möglicherweise zu Abrechnungszwecken.
In vielen Fällen können Batchprozesse Berichte nach einem definierten Zeitplan generieren. (Latenz ist normalerweise kein Problem.) Sie sollten aber auch bei Bedarf für die Generation auf Ad-hoc-Basis zur Verfügung stehen. Wenn Sie beispielsweise Daten in einer relationalen Datenbank wie Azure SQL-Datenbank speichern, können Sie ein Tool wie SQL Server Reporting Services verwenden, um Daten zu extrahieren und zu formatieren und als Gruppe von Berichten darzustellen.
Nächste Schritte
- Azure Monitor – Übersicht
- Microsoft Azure-Speicher: Überwachung, Diagnose und Problembehandlung
- Überblick über Warnungen in Microsoft Azure
- Anzeigen von Dienstintegritätsbenachrichtigungen im Azure-Portal
- Was ist Application Insights?
- Leistungsdiagnose für virtuelle Azure-Computer
- Herunterladen und Installieren von SQL Server Data Tools (SSDT) für Visual Studio
Verwandte Ressourcen
- Die Richtlinien zur automatischen Skalierung beschreiben, wie Sie den Verwaltungsaufwand verringern, indem sie die Notwendigkeit eines Operators verringern, die Leistung eines Systems kontinuierlich zu überwachen und Entscheidungen zum Hinzufügen oder Entfernen von Ressourcen zu treffen.
- Das Integritätsendpunktüberwachungsmuster beschreibt, wie Funktionsprüfungen in einer Anwendung implementiert werden, auf die externe Tools in regelmäßigen Abständen über verfügbar gemachte Endpunkte zugreifen können.
- Das Muster "Priority Queue" zeigt, wie Nachrichten in der Warteschlange priorisiert werden, sodass dringende Anforderungen empfangen und vor weniger dringenden Nachrichten verarbeitet werden können.