Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird beschrieben, wie Daten gelesen werden, die mit dem offenen Freigabeprotokoll "Delta Sharing" mit Bearertoken geteilt wurden. Sie enthält Anweisungen zum Lesen freigegebener Daten mithilfe der folgenden Tools:
- Databricks, eine Plattform für Datenanalyse
- Apache Spark
- Pandas
- Power BI
- Tableau
- Iceberg-Kunden
In diesem offenen Freigabemodell verwenden Sie eine Anmeldeinformationsdatei, die vom Datenanbieter für ein Mitglied Ihres Teams freigegeben wurde, um sicheren Lesezugriff auf freigegebene Daten zu erhalten. Der Zugriff wird beibehalten, solange die Anmeldeinformationen gültig sind und der Anbieter die Daten weiterhin freigibt. Anbieter verwalten den Ablauf und die Rotation von Anmeldeinformationen. Aktualisierungen der Daten sind nahezu in Echtzeit verfügbar. Sie können Kopien der freigegebenen Daten lesen und erstellen, aber Sie können die Quelldaten nicht ändern.
Hinweis
Wenn Daten für Sie mit Databricks-to-Databricks Delta Sharing freigegeben wurden, benötigen Sie keine Anmeldedatei, um auf die Daten zuzugreifen, und diese Seite ist irrelevant für Sie. Lesen Sie stattdessen Daten, die mit Databricks-to-Databricks Delta Sharing (für Empfänger) freigegeben wurden.
In den folgenden Abschnitten wird beschrieben, wie Sie Azure Databricks- und Apache Spark-, pandasPower BI- und Iceberg-Clients verwenden, um mithilfe der Anmeldeinformationsdatei auf freigegebene Daten zuzugreifen und diese zu lesen. Eine vollständige Liste der Delta Sharing-Connectors sowie Informationen zu ihrer Verwendung finden Sie in der Open-Source-Dokumentation zu Delta Sharing. Wenn beim Zugriff auf die freigegebenen Daten Probleme auftreten, wenden Sie sich an den Datenanbieter.
Vor dem Start
Ein Mitglied Ihres Teams muss die vom Datenanbieter bereitgestellte Anmeldeinformationsdatei herunterladen. Weitere Informationen finden Sie unter Erhalten von Zugriff im Modell für offene Freigaben.
Sie sollten einen sicheren Kanal verwenden, um die Datei oder den Dateispeicherort mit Ihnen zu teilen.
Azure Databricks: Lesen freigegebener Daten mithilfe von Connectors für offene Freigaben
In diesem Abschnitt wird das Importieren eines Anbieters und das Abfragen der freigegebenen Daten im Katalog-Explorer oder in einem Python-Notizbuch beschrieben:
Wenn Ihr Azure Databricks-Arbeitsbereich für Unity-Katalog aktiviert ist, verwenden Sie die Benutzeroberfläche des Importanbieters im Katalog-Explorer. Sie können die folgenden Schritte ausführen, ohne eine Anmeldeinformationsdatei speichern oder angeben zu müssen:
- Erstellen Sie Kataloge aus freigegebenen Ordnern per Knopfdruck.
- Verwenden Sie Die Zugriffssteuerungen des Unity-Katalogs, um den Zugriff auf freigegebene Tabellen zu gewähren.
- Abfragen freigegebener Daten mithilfe der standardmäßigen Unity-Katalogsyntax.
Wenn Ihr Azure Databricks-Arbeitsbereich für Unity-Katalog nicht aktiviert ist, verwenden Sie die Python-Notizbuchanweisungen als Beispiel.
Katalog-Explorer
Erforderliche Berechtigungen: Ein Metastore-Administrator oder ein Benutzer, der sowohl über die Berechtigungen CREATE PROVIDER als auch USE PROVIDER für Ihren Unity-Katalog-Metastore verfügt.
Klicken Sie im Azure Databricks-Arbeitsbereich auf das
 Katalog zum Öffnen des Katalog-Explorers.
Katalog zum Öffnen des Katalog-Explorers.Klicken Sie oben im Katalogbereich auf
 Wählen Sie "Delta-Freigabe" aus.
Wählen Sie "Delta-Freigabe" aus.Klicken Sie alternativ auf der Seite Schnellzugriff auf die Schaltfläche Delta Sharing >.
Klicken Sie auf der Registerkarte " Für mich freigegeben " auf "Daten importieren".
Geben Sie den Anbieternamen ein.
Der Name darf keine Leerzeichen enthalten.
Laden Sie die Anmeldeinformationsdatei hoch, die der Anbieter für Sie freigegeben hat.
Viele Anbieter verfügen über eigene Delta Sharing-Netzwerke, von denen Sie Freigaben erhalten können. Weitere Informationen finden Sie unter anbieterspezifische Konfigurationen.
(Optional) Geben Sie einen Kommentar ein.

Klicken Sie auf Importieren.
Erstellen Sie Kataloge aus den freigegebenen Daten.
Wählen Sie auf der Registerkarte Freigaben in der Zeile „Freigeben“ die Option Katalog erstellen aus.
Weitere Informationen zum Verwenden von SQL oder der Databricks CLI zum Erstellen eines Katalogs aus einer Freigabe finden Sie unter Erstellen eines Katalogs aus einer Freigabe.
Gewähren des Zugriffs auf die Kataloge.
Erfahren Sie , wie kann ich freigegebene Daten für mein Team verfügbar machen? Und verwalten Sie Berechtigungen für die Schemas, Tabellen und Volumes in einem Delta-Freigabekatalog.
Lesen Sie die freigegebenen Datenobjekte genau wie jedes Datenobjekt, das im Unity-Katalog registriert ist.
Ausführliche Informationen und Beispiele finden Sie unter Datenzugriff in einer freigegebenen Tabelle oder einem freigegebenen Volume.
Python
In diesem Abschnitt wird beschrieben, wie Sie in Ihrem Azure Databricks-Arbeitsbereich mithilfe eines Notebooks einen Connector für offene Freigaben verwenden, um auf freigegebene Daten zuzugreifen. Sie oder ein anderes Mitglied Ihres Teams speichern die Anmeldeinformationsdatei in Azure Databricks, verwenden Sie sie dann, um sich beim Azure Databricks-Konto des Datenanbieters zu authentifizieren und die Daten zu lesen, die der Datenanbieter für Sie freigegeben hat.
Hinweis
In diesen Anweisungen wird davon ausgegangen, dass Ihr Azure Databricks-Arbeitsbereich für Unity-Katalog nicht aktiviert ist. Wenn Sie Unity Catalog verwenden, müssen Sie nicht auf die Anmeldeinformationsdatei verweisen, wenn Sie aus der Freigabe lesen. Sie können aus freigegebenen Tabellen genau wie aus einer beliebigen Tabelle lesen, die im Unity-Katalog registriert ist. Databricks empfiehlt, die Benutzeroberfläche des Importanbieters im Katalog-Explorer anstelle der hier angegebenen Anweisungen zu verwenden.
Speichern Sie zuerst die Anmeldeinformationsdatei als Azure Databricks-Arbeitsbereichsdatei, damit Benutzer in Ihrem Team auf freigegebene Daten zugreifen können.
Informationen zum Importieren der Anmeldeinformationsdatei in Ihrem Azure Databricks-Arbeitsbereich finden Sie unter Importieren einer Datei.
Erteilen Sie anderen Benutzern die Berechtigung, auf die Datei zuzugreifen, indem Sie auf das
 Neben der Datei und dann "Freigeben "(Berechtigungen)". Geben Sie die Azure Databricks-Identitäten ein, die Zugriff auf die Datei haben sollen.
Neben der Datei und dann "Freigeben "(Berechtigungen)". Geben Sie die Azure Databricks-Identitäten ein, die Zugriff auf die Datei haben sollen.Weitere Informationen zu Dateiberechtigungen finden Sie unter Datei-ACLs.
Nachdem die Zugangsdaten-Datei gespeichert wurde, verwenden Sie ein Notebook zum Auflisten und Lesen freigegebener Tabellen.
Klicken Sie in Ihrem Azure Databricks-Arbeitsbereich auf Neu > Notebook.
Weitere Informationen zu Azure Databricks-Notizbüchern finden Sie unter Databricks-Notizbücher.
Um Python oder
pandaszum Zugriff auf die freigegebenen Daten zu verwenden, installieren Sie den Delta Sharing Python-Connector. Fügen Sie im Notebook-Editor den folgenden Befehl ein:%sh pip install delta-sharingFühren Sie die Zelle aus.
Die
delta-sharingPython-Bibliothek wird im Cluster installiert, wenn sie noch nicht installiert ist.Listen Sie mit Python die Tabellen in der Freigabe auf.
Fügen Sie in einer neuen Zelle den folgenden Befehl ein. Ersetzen Sie den Arbeitsbereichspfad durch den Dateipfad zu Ihrer Anmeldeinformationsdatei.
Wenn der Code ausgeführt wird, liest Python die Anmeldeinformationsdatei vor.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Führen Sie die Zelle aus.
Das Ergebnis ist ein Array aus Tabellen sowie Metadaten für jede Tabelle. Die folgende Ausgabe zeigt zwei Tabellen:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Wenn die Ausgabe leer ist oder die erwarteten Tabellen nicht enthält, wenden Sie sich an den Datenanbieter.
Fragen Sie eine freigegebene Tabelle ab.
Vorgehensweise mit Scala:
Fügen Sie in einer neuen Zelle den folgenden Befehl ein. Wenn der Code ausgeführt wird, wird die Zugangsdaten-Datei aus der Arbeitsbereich-Datei gelesen.
Ersetzen Sie die Variablen folgendermaßen:
-
<profile-path>: der Arbeitsbereichspfad der Anmeldeinformationsdatei. Beispiel:/Workspace/Users/user.name@email.com/config.share. -
<share-name>: Wert vonshare=für die Tabelle -
<schema-name>: Wert vonschema=für die Tabelle -
<table-name>: Wert vonname=für die Tabelle
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Führen Sie die Zelle aus. Jedes Mal, wenn Sie die freigegebene Tabelle laden, werden aktualisierte Daten aus der Quelle angezeigt.
-
Vorgehensweise mit SQL:
Um die Daten mithilfe von SQL abfragen zu können, müssen Sie im Arbeitsbereich zunächst eine lokale Tabelle auf der Grundlage der freigegebenen Tabelle erstellen und dann die lokale Tabelle abfragen. Die freigegebenen Daten werden nicht in der lokalen Tabelle gespeichert oder zwischengespeichert. Jedes Mal, wenn Sie die lokale Tabelle abfragen, wird der aktuelle Status der freigegebenen Daten angezeigt.
Fügen Sie in einer neuen Zelle den folgenden Befehl ein.
Ersetzen Sie die Variablen folgendermaßen:
-
<local-table-name>: Name der lokalen Tabelle -
<profile-path>: Speicherort der Anmeldeinformationsdatei -
<share-name>: Wert vonshare=für die Tabelle -
<schema-name>: Wert vonschema=für die Tabelle -
<table-name>: Wert vonname=für die Tabelle
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Wenn Sie den Befehl ausführen, werden die freigegebenen Daten direkt abgefragt. Die Tabelle wird testweise abgefragt, und die ersten zehn Ergebnisse werden zurückgegeben.
-
Wenn die Ausgabe leer ist oder die erwarteten Daten nicht enthält, wenden Sie sich an den Datenanbieter.
Apache Spark: Lesen freigegebener Daten
Gehen Sie wie folgt vor, um mithilfe von Apache Spark 3.x oder einer höheren Version auf freigegebene Daten zuzugreifen.
Bei dieser Anleitung wird davon ausgegangen, dass Sie Zugriff auf die Anmeldeinformationsdatei haben, die vom Datenanbieter bereitgestellt wurde. Weitere Informationen finden Sie unter Erhalten von Zugriff im Modell für offene Freigaben.
Wichtig
Stellen Sie sicher, dass Ihre Anmeldeinformationsdatei von Apache Spark über einen absoluten Pfad zugänglich ist. Der Pfad kann auf ein Cloudobjekt oder ein Unity Catalog-Volume verweisen.
Hinweis
Wenn Sie Spark für einen Azure Databricks-Arbeitsbereich verwenden, der für Unity Catalog aktiviert ist und Sie die Benutzeroberfläche des Importanbieters verwendet haben, um den Anbieter zu importieren und freizugeben, gelten die Anweisungen in diesem Abschnitt nicht für Sie. Sie können auf freigegebene Tabellen genauso zugreifen wie jede andere Tabelle, die im Unity-Katalog registriert ist. Sie müssen den delta-sharing Python-Connector nicht installieren oder den Pfad zur Anmeldeinformationsdatei angeben. Weitere Informationen finden Sie unter Azure Databricks: Lesen freigegebener Daten mithilfe von Connectors für offene Freigaben.
Installieren der Delta Sharing-Connectors für Python und Spark
Gehen Sie wie folgt vor, um auf Metadaten zu den freigegebenen Daten zuzugreifen (etwa auf die Liste der für Sie freigegebenen Tabellen). In diesem Beispiel wird Python verwendet.
Installieren Sie den Delta-Sharing-Python-Konnektor. Informationen zu Python-Connectorbeschränkungen finden Sie unter Einschränkungen des Delta Sharing Python-Connectors.
pip install delta-sharingInstallieren Sie den Apache Spark-Connector.
Mit Spark geteilte Tabellen auflisten
Listen Sie die Tabellen in der Freigabe auf. Ersetzen Sie <profile-path> im folgenden Beispiel durch den Speicherort der Anmeldeinformationsdatei.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Das Ergebnis ist ein Array aus Tabellen sowie Metadaten für jede Tabelle. Die folgende Ausgabe zeigt zwei Tabellen:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Wenn die Ausgabe leer ist oder die erwarteten Tabellen nicht enthält, wenden Sie sich an den Datenanbieter.
Zugreifen auf freigegebene Daten mithilfe von Spark
Führen Sie Folgendes aus, und ersetzen Sie dabei die folgenden Variablen:
-
<profile-path>: Speicherort der Anmeldeinformationsdatei -
<share-name>: Wert vonshare=für die Tabelle -
<schema-name>: Wert vonschema=für die Tabelle -
<table-name>: Wert vonname=für die Tabelle -
<version-as-of>: Optional. Die Version der Tabelle zum Laden der Daten. Funktioniert nur, wenn der Datenanbieter den Verlauf der Tabelle freigibt. Erfordertdelta-sharing-spark0.5.0 oder höher. -
<timestamp-as-of>: Optional. Laden Sie die Daten in der Version vor dem oder zum angegebenen Zeitstempel. Funktioniert nur, wenn der Datenanbieter den Verlauf der Tabelle freigibt. Erfordertdelta-sharing-spark0.6.0 oder höher.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Zugreifen auf freigegebene Änderungsdatenfeeds mithilfe von Spark
Wenn der Tabellenverlauf für Sie freigegeben wurde und der Datenfeed (CDF) in der Quelltabelle aktiviert ist, greifen Sie auf den Änderungsdatenfeed zu, indem Sie folgendes ausführen, indem Sie diese Variablen ersetzen. Erfordert delta-sharing-spark 0.5.0 oder höher.
Ein Startparameter muss angegeben werden.
-
<profile-path>: Speicherort der Anmeldeinformationsdatei -
<share-name>: Wert vonshare=für die Tabelle -
<schema-name>: Wert vonschema=für die Tabelle -
<table-name>: Wert vonname=für die Tabelle -
<starting-version>: Optional. Die Startversion der Abfrage (einschließlich). Geben Sie einen Long-Wert an. -
<ending-version>: Optional. Die Endversion der Abfrage (einschließlich). Ohne Angabe der Endversion verwendet die API die neueste Tabellenversion. -
<starting-timestamp>: Optional. Der Startzeitstempel der Abfrage. Wird in eine Version konvertiert, die frühestens zu diesem Zeitstempel erstellt wurde. Geben Sie diesen Wert als Zeichenfolge im Formatyyyy-mm-dd hh:mm:ss[.fffffffff]an. -
<ending-timestamp>: Optional. Der Endzeitstempel der Abfrage. Wird in eine Version konvertiert, die spätestens zu diesem Zeitstempel erstellt wurde. Geben Sie diesen Wert als Zeichenfolge im Formatyyyy-mm-dd hh:mm:ss[.fffffffff]an.
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Wenn die Ausgabe leer ist oder die erwarteten Daten nicht enthält, wenden Sie sich an den Datenanbieter.
Zugreifen auf eine freigegebene Tabelle mit Spark Structured Streaming
Wenn der Tabellenverlauf für Sie freigegeben wird, können Sie die freigegebenen Daten streamen. Erfordert delta-sharing-spark 0.6.0 oder höher.
Unterstützte Optionen:
-
ignoreDeletes: Ignorieren von Transaktionen, die Daten löschen. -
ignoreChanges: Erneutes Verarbeiten von Updates, wenn Dateien in der Quelltabelle aufgrund eines Datenwechselvorgangs wieUPDATE,MERGE INTO,DELETE(innerhalb von Partitionen) oderOVERWRITEneu geschrieben werden mussten. Unveränderte Zeilen können weiterhin ausgegeben werden. Daher sollten Ihre nachgeschalteten Verbraucher Duplikate verarbeiten können. Löschungen werden nicht nachgeschaltet propagiert.ignoreChangessubsumiertignoreDeletes. Wenn SieignoreChangesverwenden, wird Ihr Datenstrom daher nicht durch Löschungen oder Aktualisierungen der Quelltabelle unterbrochen. -
startingVersion: Die freigegebene Tabellenversion, mit der gestartet werden soll. Alle Tabellenänderungen ab dieser Version (einschließlich) werden von der Streamingquelle gelesen. -
startingTimestamp: Der Zeitstempel, ab dem gestartet werden soll. Alle Tabellenänderungen, die bei oder nach dem Zeitstempel (einschließlich) übernommen wurden, werden von der Streamingquelle gelesen. Beispiel:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: Die Anzahl der neuen Dateien, die in jedem Mikrobatch berücksichtigt werden sollen. -
maxBytesPerTrigger: Die Datenmenge, die in jedem Mikrobatch verarbeitet wird. Diese Option legt einen „soft max“ fest, was bedeutet, dass ein Batch ungefähr diese Datenmenge verarbeitet und möglicherweise mehr als den Grenzwert verarbeitet, um die Streamingabfrage voranzubringen, wenn die kleinste Eingabeeinheit größer als dieser Grenzwert ist. -
readChangeFeed: Lesen des Änderungsdatenfeeds der freigegebenen Tabelle im Stream.
Nicht unterstützte Optionen:
Trigger.availableNow
Beispiele strukturierter Streaming-Abfragen
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Siehe auch Strukturierte Streaming-Konzepte.
Tabellen mit aktivierten Löschvektoren oder Spaltenzuordnung lesen
Wichtig
Dieses Feature befindet sich in der Public Preview.
Löschvektoren sind ein Speicheroptimierungsfeature, das Ihr Anbieter für freigegebene Delta-Tabellen aktivieren kann. Weitere Informationen finden Sie unter Was sind Löschvektoren?.
Azure Databricks unterstützt auch die Spaltenzuordnung für Delta-Tabellen. Weitere Informationen finden Sie unter Rename and drop columns with Delta Lake column mapping (Umbenennen und Löschen von Spalten mit Delta Lake-Spaltenzuordnung).
Wenn Ihr Anbieter eine Tabelle mit eingeschalteten Löschvektoren oder Spaltenzuordnungen geteilt hat, können Sie die Tabelle mithilfe der Rechenleistung lesen, die delta-sharing-spark 3.1 oder höher ausführt. Wenn Sie Databricks-Cluster verwenden, können Sie Batchlesevorgänge mit einem Cluster ausführen, in dem Databricks Runtime 14.1 oder höher ausgeführt wird. CDF- und Streamingabfragen erfordern Databricks Runtime 14.2 oder höher.
Sie können Batchabfragen wie folgt ausführen, da sie basierend auf den Tabellenfeatures der freigegebenen Tabelle automatisch responseFormat auflösen können.
Wenn Sie einen Änderungsdatenfeed (CDF) lesen oder Streamingabfragen für freigegebene Tabellen mit aktivierten Löschvektoren oder Spaltenzuordnungen ausführen möchten, müssen Sie die zusätzliche Option responseFormat=delta festlegen.
Die folgenden Beispiele zeigen Batch-, CDF- und Streamingabfragen:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Pandas: Lesen freigegebener Daten
Führen Sie die folgenden Schritte aus, um auf freigegebene Daten in pandas 0.25.3 oder höher zuzugreifen.
Bei dieser Anleitung wird davon ausgegangen, dass Sie Zugriff auf die Anmeldeinformationsdatei haben, die vom Datenanbieter bereitgestellt wurde. Weitere Informationen finden Sie unter Erhalten von Zugriff im Modell für offene Freigaben.
Hinweis
Wenn Sie einen Azure Databricks-Arbeitsbereich verwenden pandas , der für Unity Catalog aktiviert ist und Sie die Benutzeroberfläche des Importanbieters zum Importieren des Anbieters und zum Freigeben verwendet haben, gelten die Anweisungen in diesem Abschnitt nicht für Sie. Sie können auf freigegebene Tabellen genauso zugreifen wie jede andere Tabelle, die im Unity-Katalog registriert ist. Sie müssen den delta-sharing Python-Connector nicht installieren oder den Pfad zur Anmeldeinformationsdatei angeben. Weitere Informationen finden Sie unter Azure Databricks: Lesen freigegebener Daten mithilfe von Connectors für offene Freigaben.
Installieren des Delta Sharing-Connectors für Python
Wenn Sie auf Metadaten zu den freigegebenen Daten zugreifen möchten (etwa auf die Liste der für Sie freigegebenen Tabellen), müssen Sie den Delta Sharing-Connector für Python installieren. Informationen zu Python-Connectorbeschränkungen finden Sie unter Einschränkungen des Delta Sharing Python-Connectors.
pip install delta-sharing
Auflisten freigegebener Tabellen mithilfe von pandas
Führen Sie zum Auflisten der Tabellen in der Freigabe Folgendes aus, und ersetzen Sie dabei <profile-path>/config.share durch den Speicherort der Anmeldeinformationsdatei.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Wenn die Ausgabe leer ist oder die erwarteten Tabellen nicht enthält, wenden Sie sich an den Datenanbieter.
Zugreifen auf freigegebene Daten mithilfe von pandas
Um auf freigegebene Daten in pandas mit Python zuzugreifen, führen Sie Folgendes aus und ersetzen Sie die Variablen wie folgt:
-
<profile-path>: Speicherort der Anmeldeinformationsdatei -
<share-name>: Wert vonshare=für die Tabelle -
<schema-name>: Wert vonschema=für die Tabelle -
<table-name>: Wert vonname=für die Tabelle
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Zugreifen auf einen freigegebenen Änderungsdatenfeed mithilfe von pandas
Um auf den Änderungsdatenfeed für eine freigegebene Tabelle mithilfe pandas von Python zuzugreifen, führen Sie folgendes aus, indem Sie die Variablen wie folgt ersetzen. Ein Änderungsdatenfeed ist möglicherweise nicht verfügbar, je nachdem, ob der Datenanbieter den Änderungsdatenfeed für die Tabelle freigegeben hat oder nicht.
-
<starting-version>: Optional. Die Startversion der Abfrage (einschließlich). -
<ending-version>: Optional. Die Endversion der Abfrage (einschließlich). -
<starting-timestamp>: Optional. Der Startzeitstempel der Abfrage. Wird in eine Version konvertiert, die frühestens zu diesem Zeitstempel erstellt wurde. -
<ending-timestamp>: Optional. Der Endzeitstempel der Abfrage. Wird in eine Version konvertiert, die spätestens zu diesem Zeitstempel erstellt wurde.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Wenn die Ausgabe leer ist oder die erwarteten Daten nicht enthält, wenden Sie sich an den Datenanbieter.
Power BI: Lesen freigegebener Daten
Mit dem Delta Sharing-Connector für Power BI können Sie über das offene Delta Sharing-Protokoll für Sie freigegebene Datasets entdecken, analysieren und visualisieren.
Anforderungen
- Power BI Desktop 2.99.621.0 oder höher.
- Zugriff auf die Anmeldeinformationsdatei, die vom Datenanbieter bereitgestellt wurde. Weitere Informationen finden Sie unter Erhalten von Zugriff im Modell für offene Freigaben.
Mit Databricks verbinden
Führen Sie die folgenden Schritte aus, um über den Delta Sharing-Connector eine Verbindung mit Azure Databricks herzustellen:
- Öffnen Sie die bereitgestellte Anmeldeinformationsdatei in einem Text-Editor, um die Endpunkt-URL und das Token zu erhalten.
- Öffnen Sie Power BI Desktop.
- Suchen Sie im Menü Daten abrufen nach Delta Sharing.
- Wählen Sie den Connector aus, und klicken Sie auf Verbinden.
- Fügen Sie die Endpunkt-URL, die Sie aus der Datei mit den Anmeldeinformationen kopiert haben, in das Feld URL des Delta Sharing-Servers ein.
- Optional können Sie auf der Registerkarte Erweiterte Optionen ein Zeilenlimit für die maximale Anzahl der Zeilen festlegen, die heruntergeladen werden kann. Der Standardwert liegt bei 1 Million Zeilen.
- Klicken Sie auf OK.
- Fügen Sie für die Authentifizierung das Token, das Sie aus der Datei mit den Anmeldeinformationen abgerufen haben, in das Feld Bearertoken ein.
- Klicken Sie auf Verbinden.
Einschränkungen beim Delta Sharing-Connector für Power BI
Für den Delta Sharing-Connector für Power BI gelten folgende Einschränkungen:
- Die vom Connector geladenen Daten müssen in den Arbeitsspeicher Ihres Computers passen. Um diese Anforderung zu erfüllen, beschränkt der Konnektor die Anzahl importierter Zeilen auf das Zeilenlimit, das Sie in Power BI Desktop auf der Registerkarte „Erweiterte Optionen“ festgelegt haben.
Tableau: Lesen freigegebener Daten
Mit dem Tableau Delta Sharing-Konnektor können Sie Datasets entdecken, analysieren und visualisieren, die über das offene Delta Sharing-Protokoll mit Ihnen geteilt werden.
Anforderungen
- Tableau Desktop und Tableau Server 2024.1 oder höher
- Zugriff auf die Anmeldeinformationsdatei, die vom Datenanbieter bereitgestellt wurde. Weitere Informationen finden Sie unter Erhalten von Zugriff im Modell für offene Freigaben.
Herstellen einer Verbindung mit Azure Databricks
Führen Sie die folgenden Schritte aus, um über den Delta Sharing-Connector eine Verbindung mit Azure Databricks herzustellen:
- Wechseln Sie zu Tableau Exchange, und folgen Sie den Anweisungen, um den Delta Sharing-Konnektor herunterzuladen und in einem geeigneten Desktopordner abzulegen.
- Öffnen Sie Tableau Desktop.
- Suchen Sie auf der Seite Konnektoren nach „Delta Sharing von Databricks“.
- Wählen Sie Freigabedatei hochladen und anschließend die Anmeldeinformationsdatei aus, die Sie vom Anbieter erhalten haben.
- Klicken Sie auf Get Data (Daten abrufen).
- Wählen Sie im Daten-Explorer die Tabelle aus.
- Fügen Sie optional SQL-Filter oder Zeilenbeschränkungen hinzu.
- Klicken Sie auf Tabellendaten abrufen.
Einschränkungen
Für den Tableau Delta Sharing-Konnektor gelten folgende Einschränkungen:
- Die vom Connector geladenen Daten müssen in den Arbeitsspeicher Ihres Computers passen. Um diese Anforderung zu erfüllen, beschränkt der Konnektor die Anzahl importierter Zeilen auf das Zeilenlimit, das Sie in Tableau festgelegt haben.
- Alle Spalten werden mit dem Typ
Stringzurückgegeben. - Ein SQL-Filter funktioniert nur, wenn Ihr Delta-Sharing-Server predicateHint unterstützt.
- Löschvektoren werden nicht unterstützt.
- Spaltenzuordnung wird nicht unterstützt.
Iceberg-Clients: Lesen freigegebener Delta-Tabellen
Wichtig
Dieses Feature befindet sich in der Public Preview.
Verwenden Sie externe Iceberg-Clients wie Snowflake, Trino, Flink und Spark, um freigegebene Datenressourcen mit Zero-Copy-Zugriff mithilfe der Apache Iceberg REST Catalog-API zu lesen.
Wenn Sie Snowflake verwenden, können Sie die Anmeldeinformationsdatei verwenden, um einen SQL-Befehl zu generieren, mit dem Sie freigegebene Delta-Tabellen lesen können.
Abrufen von Zugangsdaten
Bevor Sie auf freigegebene Datenressourcen mit externen Iceberg-Clients zugreifen, sammeln Sie die folgenden Anmeldeinformationen:
- Der Iceberg REST Catalog-Endpunkt
- Ein gültiges Bearer-Token
- Der Freigabename
- (Optional) Der Namespace- oder Schemaname
- (Optional) Der Tabellenname
Der REST-Endpunkt und das Bearer-Token befinden sich in der Anmeldeinformationsdatei, die von Ihrem Datenanbieter bereitgestellt wird. Der Freigabename, der Namespace und der Tabellenname können programmgesteuert mithilfe von Delta Sharing APIs ermittelt werden.
Die folgenden Beispiele zeigen, wie Sie die zusätzlichen Anmeldeinformationen abrufen. Geben Sie den Endpunkt, den Iceberg-Endpunkt und das Bearer-Token aus der Anmeldeinformationsdatei ein, sofern erforderlich:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Hinweis
Diese Methode ruft immer die aktuellste Liste der Ressourcen ab. Es erfordert jedoch Internetzugriff und kann schwieriger in No-Code-Umgebungen integriert werden.
Konfigurieren des Iceberg-Katalogs
Nachdem Sie die erforderlichen Verbindungsanmeldeinformationen erhalten haben, konfigurieren Sie Ihren Client so, dass er die Iceberg REST Catalog-Endpunkte zum Erstellen und Abfragen von Tabellen verwendet.
Erstellen Sie für jede Freigabe eine Katalogintegration.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Fügen Sie
REFRESH_INTERVAL_SECONDSoptional hinzu, um Metadaten auf dem neuesten Stand zu halten. Legen Sie den Wert basierend auf der Aktualisierungshäufigkeit des Katalogs fest.REFRESH_INTERVAL_SECONDS = 30Nachdem der Katalog konfiguriert wurde, erstellen Sie eine Datenbank aus dem Katalog. Dadurch werden automatisch alle Schemas und Tabellen in diesem Katalog erstellt.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Um zu bestätigen, dass die Freigabe erfolgreich ist, fragen Sie eine Abfrage aus einer Tabelle in der Datenbank ab. Du solltest die freigegebenen Daten aus Azure Databricks sehen.
Wenn das Ergebnis leer ist oder ein Fehler auftritt, führen Sie die folgenden allgemeinen Schritte zur Problembehandlung aus:
- Überprüfen Sie die Berechtigungen, den Status der Momentaufnahmegenerierung und die REST-Anmeldeinformationen.
- Wenden Sie sich an Ihren Datenanbieter.
- Sehen Sie sich die Dokumentation an, die für Ihren Iceberg-Client spezifisch ist.
Beispiel: Lesen freigegebener Delta-Tabellen in Snowflake mithilfe eines SQL-Befehls
Um freigegebene Datenressourcen in Snowflake zu lesen, laden Sie die heruntergeladene Anmeldeinformationsdatei hoch, und generieren Sie den erforderlichen SQL-Befehl:
Klicken Sie im Link "Delta-Freigabeaktivierung" auf das Snowflake-Symbol.
Laden Sie auf der Snowflake-Integrationsseite die Anmeldeinformationsdatei hoch, die Sie vom Datenanbieter erhalten haben.

Nachdem Sie die Anmeldeinformationen geladen haben, wählen Sie die Ressource in Snowflake aus, auf die Sie zugreifen möchten.
Klicken Sie auf "SQL generieren ", nachdem Sie die gewünschten Ressourcen ausgewählt haben.
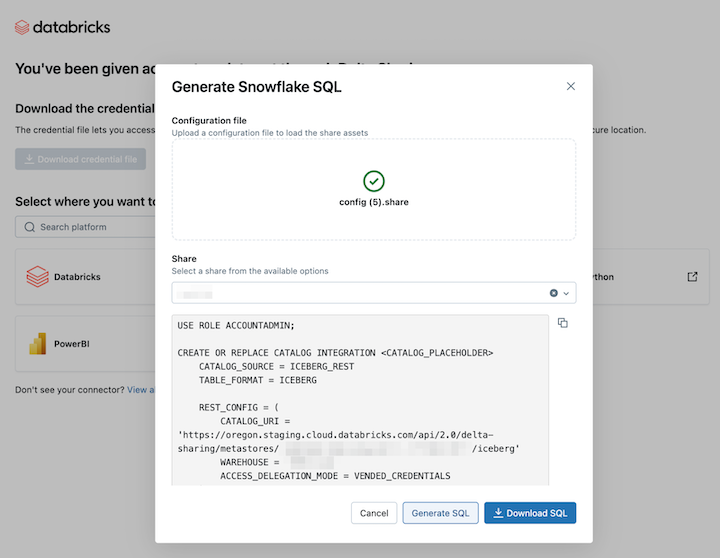
Kopieren Sie die generierte SQL-Datei, und fügen Sie sie in Ihr Snowflake-Arbeitsblatt ein. Ersetzen Sie den
CATALOG_PLACEHOLDERNamen des Katalogs, den Sie verwenden möchten, undDATABASE_PLACEHOLDERdurch den Namen der Datenbank, die Sie verwenden möchten.
Schneeflockenbeschränkungen
Die Verbindung mit dem Iceberg REST-Katalog in Snowflake hat die folgenden Einschränkungen:
- Die Metadatendatei wird nicht automatisch mit der neuesten Momentaufnahme aktualisiert. Sie müssen sich auf automatische Aktualisierungen oder manuelle Aktualisierungen verlassen.
- R2 wird nicht unterstützt.
- Alle Iceberg-Clientbeschränkungen gelten.
Einschränkungen des Iceberg-Clients
Die folgenden Einschränkungen gelten beim Abfragen von Delta Sharing-Daten von Iceberg-Clients:
- Beim Auflisten von Tabellen in einem Namespace ist die Antwort auf die ersten 100 freigegebenen Ansichten beschränkt, falls der Namespace mehr als 100 dieser Ansichten enthält.
Einschränkungen des Delta Sharing Python-Connectors
Diese Einschränkungen gelten speziell für den Delta Sharing Python-Connector:
- Der Delta Sharing Python Connector 1.1.0 unterstützt Momentaufnahmenabfragen für Tabellen mit Spaltenzuordnung, CDF-Abfragen für Tabellen mit Spaltenzuordnung werden jedoch nicht unterstützt.
- Der Delta Sharing Python-Connector schlägt CDF-Abfragen fehl, wenn
use_delta_format=Truedas Schema während des abgefragten Versionsbereichs geändert wurde.
Neue Zugangsdaten anfordern
Wenn die URL zur Aktivierung Ihrer Anmeldeinformationen oder Ihre heruntergeladenen Anmeldeinformationen verloren gehen, beschädigt oder kompromittiert werden oder Ihre Anmeldeinformationen ablaufen, ohne dass Ihr Anbieter Ihnen neue Anmeldeinformationen übermittelt, wenden Sie sich an Ihren Anbieter, um neue Anmeldeinformationen anzufordern.