Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Dieser Artikel befasst sich mit Azure DevOps, von einem Drittanbieter entwickelt. Informationen zum Kontaktieren des Anbieters finden Sie unter Azure DevOps Services-Support.
In diesem Artikel erfahren Sie mehr über die Konfiguration der Azure DevOps-Automatisierung für Ihren Code und Ihre Artefakte für die Verwendung mit Azure Databricks. Insbesondere konfigurieren Sie einen CI/CD-Workflow (Continuous Integration und Continuous Delivery), um eine Verbindung mit einem Git-Repository herzustellen, Aufträge mit Azure Pipelines auszuführen, um ein Python-Wheel (WHL-Datei) zu erstellen, einen Komponententest damit durchzuführen und es für die Verwendung in Databricks-Notebooks bereitzustellen.
CI/CD-Entwicklungsworkflow
Databricks schlägt den folgenden Workflow für die CI/CD-Entwicklung mit Azure DevOps vor:
- Erstellen Sie ein Repository, oder verwenden Sie ein vorhandenes Repository mit Ihrem Git-Drittanbieter.
- Verbinden Sie Ihren lokalen Entwicklungscomputer mit demselben Drittanbieter-Repository. Anweisungen finden Sie in der Dokumentation Ihres Git-Anbieters.
- Pullen Sie alle vorhandenen aktualisierten Artefakte (z. B. Notebooks, Codedateien und Buildskripts) aus dem Drittanbieterrepository auf Ihren lokalen Entwicklungscomputer.
- Erstellen, aktualisieren und testen Sie Artefakte bei Bedarf auf Ihrem lokalen Entwicklungscomputer. Pushen Sie dann alle neuen und geänderten Artefakte von Ihrem lokalen Entwicklungscomputer in das Drittanbieterrepository. Anweisungen finden Sie in der Dokumentation Ihres Git-Anbieters.
- Wiederholen Sie die Schritte 3 und 4 nach Bedarf.
- Verwenden Sie Azure DevOps regelmäßig als integrierten Ansatz, um Artefakte aus Ihrem Drittanbieterrepository automatisch zu pullen und Code in Ihrem Azure Databricks-Arbeitsbereich zu erstellen, zu testen und auszuführen, und Berichte zu Test- und Ausführungsergebnissen zu erstellen. Sie können Azure DevOps zwar manuell ausführen, würden in realen Implementierungen allerdings Ihren Git-Drittanbieter anweisen, Azure DevOps jedes Mal auszuführen, wenn ein bestimmtes Ereignis auftritt, z. B. ein Pull Request im Repository.
Es gibt zahlreiche CI/CD-Tools, die Sie zum Verwalten und Ausführen Ihrer Pipeline verwenden können. Der vorliegende Artikel veranschaulicht, wie Sie Azure DevOps verwenden. CI/CD ist ein Entwurfsmuster, sodass die Schritte und Phasen, die im Beispiel dieses Artikels beschrieben sind, mit einigen Änderungen an der Pipelinedefinitionssprache in jedem Tool übertragen werden sollten. Darüber hinaus ist ein Großteil des Codes in dieser Beispielpipeline Python-Standardcode, der in anderen Tools aufgerufen werden kann.
Tipp
Informationen zur Verwendung von Jenkins mit Azure Databricks anstelle von Azure DevOps finden Sie unter CI/CD in Azure Databricks mithilfe von Jenkins.
In den verbleibenden Abschnitten dieses Artikels werden zwei Beispielpipelines in Azure DevOps beschrieben, die Sie an Ihre eigenen Anforderungen für Azure Databricks anpassen können.
Informationen zum Beispiel
Im Beispiel dieses Artikels werden zwei Pipelines zum Sammeln, Bereitstellen und Ausführen von Python-Beispielcode und Python-Notizbüchern verwendet, die in einem Remote-Git-Repository gespeichert sind.
Die erste Pipeline, bezeichnet als Buildpipeline, bereitet Buildartefakte für die zweite Pipeline vor, die sogenannte Releasepipeline. Wenn Sie die Buildpipeline von der Releasepipeline trennen, können Sie ein Buildartefakt erstellen, ohne es bereitzustellen, oder Artefakte aus mehreren Builds gleichzeitig bereitstellen. So erstellen Sie die Build- und Releasepipelines
- Erstellen Sie eine Azure-VM für die Buildpipeline.
- Kopieren der Dateien aus Ihrem Git-Repository auf die VM.
- Erstellen Sie eine gzip'ed tar-Datei, die den Python-Code, Python-Notizbücher und zugehörige Build-, Bereitstellungs- und Ausführungseinstellungendateien enthält.
- Kopieren Sie die gzip-komprimierte tar-Datei als ZIP-Datei an einen Speicherort, auf den die Release-Pipeline zugreifen kann.
- Erstellen Sie eine weitere Azure-VM für die Releasepipeline.
- Rufen Sie die ZIP-Datei vom Speicherort der Buildpipeline ab und entpacken Sie dann die ZIP-Datei, um den Python-Code, Python-Notizbücher und zugehörige Build-, Bereitstellungs- und Ausführungs-Einstellungsdateien abzurufen.
- Stellen Sie den Python-Code, die Python-Notebooks und die zugehörigen Einstellungsdateien für Erstellung, Bereitstellung und Ausführung in Ihrem Azure Databricks-Remotearbeitsbereich bereit.
- Erstellen Sie die Komponentencodedateien der Python-Wheel-Bibliothek in einer Python-Wheel-Datei.
- Führen Sie Komponententests für den Komponentencode aus, um die Logik in der Python-Wheel-Datei zu überprüfen.
- Führen Sie die Python-Notizbücher aus, von denen eines die Funktionalität der Python-Wheel-Datei aufruft.
Über die Databricks CLI
Das Beispiel dieses Artikels veranschaulicht die Verwendung der Databricks CLI in einem nicht interaktiven Modus in einer Pipeline. Die Beispielpipeline dieses Artikels stellt Code bereit, erstellt eine Bibliothek und führt Notizbücher in Ihrem Azure Databricks-Arbeitsbereich aus.
Wenn Sie die Databricks CLI in Ihrer Pipeline verwenden, ohne den Beispielcode, die Bibliothek und Notebooks aus diesem Artikel zu implementieren, führen Sie die folgenden Schritte aus:
Bereiten Sie Ihren Azure Databricks-Arbeitsbereich auf die Verwendung der OAuth-Machine-to-Machine-Authentifizierung (M2M) für die Authentifizierung eines Dienstprinzipals vor. Vergewissern Sie sich vor Beginn, dass Sie über einen Microsoft Entra ID-Dienstprinzipal mit einem Azure Databricks OAuth-Schlüssel verfügen. Siehe Autorisieren des Dienstprinzipalzugriffs auf Azure Databricks mit OAuth.
Installieren Sie die Databricks CLI in Ihrer Pipeline. Fügen Sie dazu ihrer Pipeline eine Bash-Skriptaufgabe hinzu, die das folgende Skript ausführt:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shInformationen zum Hinzufügen einer Bash-Skriptaufgabe zu Ihrer Pipeline finden Sie in Schritt 3.6. Installieren Sie die Databricks CLI- und Python-Wheel Build Tools.
Konfigurieren Sie Ihre Pipeline so, dass die installierte Databricks CLI Ihren Dienstprinzipal mit Ihrem Arbeitsbereich authentifiziert. Lesen Sie hierzu Schritt 3.1: Definieren von Umgebungsvariablen für die Releasepipeline.
Fügen Sie Ihrer Pipeline nach Bedarf weitere Bash-Skriptaufgaben hinzu, um Ihre Databricks CLI-Befehle auszuführen. Weitere Informationen unter Databricks CLI-Befehle.
Bevor Sie anfangen
Um das Beispiel dieses Artikels zu verwenden, müssen Sie folgendes haben:
- Ein vorhandenes Azure DevOps-Projekt. Wenn Sie noch kein Projekt haben, erstellen Sie ein Projekt in Azure DevOps.
- Ein vorhandenes Repository mit einem Git-Anbieter, der von Azure DevOps unterstützt wird. Sie fügen diesem Repository den Python-Beispielcode, das Python-Beispielnotebook und die zugehörigen Einstellungsdateien für das Release hinzu. Wenn Sie noch kein Repository haben, erstellen Sie ein Repository, indem Sie die Anweisungen Ihres Git-Anbieters befolgen. Verbinden Sie dann Ihr Azure DevOps-Projekt mit diesem Repository, wenn Sie dies noch nicht erledigt haben. Anweisungen finden Sie unter den Links unter Unterstützte Quellrepositorys.
- Im Beispiel dieses Artikels wird die Machine-to-Machine-OAuth-Authentifizierung (M2M) verwendet, um einen Microsoft Entra ID-Dienstprinzipal in einem Azure Databricks-Arbeitsbereich zu authentifizieren. Sie benötigen einen Microsoft Entra ID-Dienstprinzipal mit einem Azure Databricks-OAuth-Geheimnis für diesen Dienstprinzipal. Siehe Autorisieren des Dienstprinzipalzugriffs auf Azure Databricks mit OAuth.
Schritt 1: Hinzufügen der Beispieldateien zu Ihrem Repository
In diesem Schritt fügen Sie im Drittanbieter-Git-Repository alle Beispieldateien dieses Artikels hinzu, die Ihre Azure DevOps-Pipelines in Ihrem entfernten Azure-Databricks-Arbeitsbereich erstellen, bereitstellen und ausführen.
Schritt 1.1: Hinzufügen der Komponentendateien für das Python-Wheel
Im Beispiel dieses Artikels erstellen und testen Ihre Azure DevOps-Pipelines eine Python-Raddatei. Ein Azure Databricks-Notizbuch ruft dann die Funktionen der integrierten Python-Raddatei auf.
Um die Logik- und Komponententests für die Python-Wheel-Datei zu definieren, mit dem die Notebooks ausgeführt werden, erstellen Sie im Stammverzeichnis Ihres Repositorys zwei Dateien mit den Namen addcol.py und test_addcol.py und fügen sie einer Ordnerstruktur python/dabdemo/dabdemo im Ordner Libraries hinzu, wie im Folgenden dargestellt:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Die Datei addcol.py enthält eine Bibliotheksfunktion, die später in eine Python-Wheel-Datei integriert und dann in Azure Databricks-Clustern installiert wird. Es handelt sich um eine einfache Funktion, die eine neue Spalte, die durch ein Literal aufgefüllt wird, einem Apache Spark-DataFrame hinzufügt:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Die Datei test_addcol.py enthält Tests zum Übergeben eines Pseudo-DataFrame-Objekts an die Funktion with_status, die in addcol.py definiert ist. Das Ergebnis wird dann mit einem DataFrame-Objekt verglichen, das die erwarteten Werte enthält. Wenn die Werte übereinstimmen, ist der Test bestanden:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Damit die Databricks-CLI diesen Bibliothekscode ordnungsgemäß in eine Python-Wheel-Datei packen kann, erstellen Sie zwei Dateien mit dem Namen __init__.py und __main__.py im selben Ordner wie die vorherigen beiden Dateien. Erstellen Sie außerdem eine Datei namens setup.py im Ordner python/dabdemo, wie im Folgenden dargestellt:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Die __init__.py Datei enthält die Versionsnummer und den Autor der Bibliothek. Ersetzen Sie <my-author-name> durch Ihren Namen:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Die __main__.py Datei enthält den Einstiegspunkt der Bibliothek:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Die Datei setup.py enthält zusätzliche Einstellungen zum Erstellen der Bibliothek in einer Python-Wheel-Datei. Ersetzen Sie <my-url>, <my-author-name>@<my-organization> und <my-package-description> durch gültige Werte:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Schritt 1.2: Hinzufügen eines Notebooks für Komponententests für die Python-Wheel-Datei
Später führt die Databricks CLI einen Notebookauftrag aus. Dieser Auftrag führt ein Python-Notebook mit dem Dateinamen run_unit_tests.py aus. Dieses Notizbuch führt pytest gegen die Logik der Python Wheel-Bibliothek aus.
Um die Komponententests für das Beispiel dieses Artikels auszuführen, fügen Sie dem Stammverzeichnis Ihres Repositorys eine Notizbuchdatei run_unit_tests.py mit dem folgenden Inhalt hinzu:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Schritt 1.3: Hinzufügen eines Notebooks, das die Python-Wheel-Datei aufruft
Später führt die Databricks CLI einen weiteren Notebookauftrag aus. Dieses Notizbuch erstellt ein DataFrame-Objekt, übergibt es an die Funktion der Python-Radbibliothek with_status , druckt das Ergebnis und meldet die Ausführungsergebnisse des Auftrags. Erstellen Sie im Stammverzeichnis Ihres Repositorys eine Notebookdatei namens dabdemo_notebook.py mit folgendem Inhalt:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Schritt 1.4: Erstellen der Bundlekonfiguration
Das Beispiel dieses Artikels verwendet Databricks Asset Bundles, um die Einstellungen und Verhaltensweisen für das Erstellen, Bereitstellen und Ausführen der Python-Raddatei, der beiden Notizbücher und der Python-Codedatei zu definieren. Databricks-Ressourcenpakete, einfach als Pakete bezeichnet, ermöglichen, vollständige Daten, Analysen und ML-Projekte als Sammlung von Quelldateien auszudrücken. Siehe Was sind Databricks Asset Bundles?.
Um das Bundle für das Beispiel dieses Artikels zu konfigurieren, erstellen Sie im Stammverzeichnis Ihres Repositorys eine Datei mit dem Namen databricks.yml. Ersetzen Sie in dieser databricks.yml-Beispieldatei die folgenden Platzhalter:
- Ersetzen Sie
<bundle-name>durch einen eindeutigen programmgesteuerten Namen für das Bundle. Beispiel:azure-devops-demo. - Ersetzen Sie
<job-prefix-name>durch eine Zeichenfolge, um die Aufträge eindeutig zu identifizieren, die in Ihrem Azure Databricks-Arbeitsbereich für dieses Beispiel erstellt werden. Beispiel:azure-devops-demo. - Ersetzen Sie
<spark-version-id>durch die Databricks Runtime-Versions-ID für Ihre Auftragscluster, z. B.13.3.x-scala2.12. - Ersetzen Sie
<cluster-node-type-id>durch die Clusterknotentyp-ID für Ihre Auftragscluster, z. B.Standard_DS3_v2. - Beachten Sie, dass
devin der Zuordnungtargetsden Host und das zugehörige Bereitstellungsverhalten angibt. In realen Implementierungen können Sie diesem Ziel einen anderen Namen in Ihren eigenen Bundles zuweisen.
Dies sind die Inhalte der Datei dieses Beispiels databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
targets:
dev:
mode: development
Weitere Informationen zur Syntax der databricks.yml Datei finden Sie unter Databricks Asset Bundle-Konfiguration.
Schritt 2: Definieren der Buildpipeline
Azure DevOps bietet eine in der Cloud gehostete Benutzeroberfläche zur Definition der Phasen Ihrer CI/CD-Pipeline mittels YAML. Weitere Informationen zu Azure DevOps und Pipelines finden Sie in der Azure DevOps-Dokumentation.
In diesem Schritt verwenden Sie YAML-Markup, um die Buildpipeline zu definieren, die ein Bereitstellungsartefakt erstellt. Um den Code in einem Azure Databricks-Arbeitsbereich bereitzustellen, geben Sie das Buildartefakt dieser Pipeline als Eingabe in eine Releasepipeline an. Sie definieren diese Releasepipeline später.
Zum Ausführen von Buildpipelines stellt Azure DevOps in der Cloud gehostete, bedarfsbasierte Ausführungs-Agents zur Verfügung, die Bereitstellungen in Kubernetes, VMs, Azure Functions, Azure-Web-Apps und vielen weiteren Zielen unterstützen. In diesem Beispiel verwenden Sie einen On-Demand-Agent, um das Erstellen des Bereitstellungsartefakts zu automatisieren.
Definieren Sie die Beispiel-Build-Pipeline in diesem Artikel wie folgt:
Melden Sie sich bei Azure DevOps an, und wählen Sie dann den Link Anmelden aus, um Ihr Azure DevOps-Projekt zu öffnen.
Hinweis
Wenn das Azure-Portal anstelle Ihres Azure DevOps-Projekts angezeigt wird, wählen Sie Weitere Dienste > Azure DevOps-Organisationen > Meine Azure DevOps-Organisationen aus, und öffnen Sie dann Ihr Azure DevOps-Projekt.
Klicken Sie in der Randleiste auf Pipelines und dann im Menü Pipelines auf Pipelines.

Wählen Sie die Schaltfläche Neue Pipeline aus, und befolgen Sie die Anweisungen auf dem Bildschirm. (Wenn Sie bereits über Pipelines verfügen, klicken Sie stattdessen auf Pipeline erstellen.) Am Ende dieser Anweisungen wird der Pipeline-Editor geöffnet. Hier definieren Sie Ihr Buildpipelineskript in der angezeigten Datei
azure-pipelines.yml. Wenn der Pipeline-Editor am Ende der Anweisungen nicht sichtbar ist, wählen Sie den Namen der Buildpipeline aus, und klicken Sie dann auf "Bearbeiten".Mit dem Git-Verzweigungsselektor
 können Sie den Build-Prozess für jeden Zweig in Ihrem Git-Repository anpassen. Es ist eine bewährte Methode für CI/CD, die Produktion nicht direkt in der Filiale Ihres Repositorys
können Sie den Build-Prozess für jeden Zweig in Ihrem Git-Repository anpassen. Es ist eine bewährte Methode für CI/CD, die Produktion nicht direkt in der Filiale Ihres Repositorys mainzu erledigen. In diesem Beispiel wird davon ausgegangen, dass im Repository ein Branch namensreleasevorhanden ist, der anstelle vonmainverwendet wird.
Das Skript
azure-pipelines.ymlder Buildpipeline wird standardmäßig im Stammverzeichnis des Git-Remoterepositorys gespeichert, das Sie der Pipeline zugeordnet haben.Überschreiben Sie den
azure-pipelines.ymlStartinhalt der Pipelinedatei mit der folgenden Definition, und klicken Sie dann auf "Speichern".# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Schritt 3: Definieren der Releasepipeline
Die Releasepipeline stellt die Buildartefakte aus der Buildpipeline in einer Azure Databricks-Umgebung bereit. Wenn Sie die Releasepipeline in diesem Schritt von der Buildpipeline in den vorherigen Schritten trennen, können Sie einen Build erstellen, ohne ihn bereitzustellen, oder Artefakte aus mehreren Builds gleichzeitig bereitstellen.
Klicken Sie in Ihrem Azure DevOps-Projekt auf der Randleiste im Menü Pipelines auf Releases.

Wählen Sie Neu > Neue Releasepipeline aus. (Wenn Sie bereits über Pipelines verfügen, klicken Sie stattdessen auf Neue Pipeline.)
Auf der rechten Bildschirmseite finden Sie eine Liste mit Vorlagen für gängige Bereitstellungsmuster. Wählen Sie für die Releasepipeline in diesem Beispiel
 aus.
aus.
Klicken Sie im Feld Artefakte auf der rechten Bildschirmseite auf
 . Wählen Sie im Bereich Artefakt hinzufügen für Quelle (Buildpipeline) die zuvor erstellte Buildpipeline aus. Klicken Sie anschließend auf Hinzufügen.
. Wählen Sie im Bereich Artefakt hinzufügen für Quelle (Buildpipeline) die zuvor erstellte Buildpipeline aus. Klicken Sie anschließend auf Hinzufügen.
Sie können konfigurieren, wie die Pipeline ausgelöst wird, indem Sie
 auswählen, um auf der rechten Bildschirmseite Auslöseoptionen anzuzeigen. Wenn Sie möchten, dass ein Release automatisch basierend auf der Verfügbarkeit des Buildartefakts oder nach einem Pull Request-Workflow initiiert wird, aktivieren Sie den entsprechenden Auslöser. Für dieses Beispiel lösen Sie im letzten Schritt dieses Artikels manuell die Buildpipeline und dann die Releasepipeline aus.
auswählen, um auf der rechten Bildschirmseite Auslöseoptionen anzuzeigen. Wenn Sie möchten, dass ein Release automatisch basierend auf der Verfügbarkeit des Buildartefakts oder nach einem Pull Request-Workflow initiiert wird, aktivieren Sie den entsprechenden Auslöser. Für dieses Beispiel lösen Sie im letzten Schritt dieses Artikels manuell die Buildpipeline und dann die Releasepipeline aus.
Klicken Sie auf Speichern > OK.
Schritt 3.1: Definieren von Umgebungsvariablen für die Releasepipeline
Die Releasepipeline dieses Beispiels basiert auf den folgenden Umgebungsvariablen, die Sie hinzufügen können, indem Sie im Abschnitt "Pipelinevariablen" auf der Registerkarte "Variablen" mit einem Bereich der Stufe 1 auf "Hinzufügen" klicken:
-
BUNDLE_TARGETsollte mit dem Namentargetin Ihrer Dateidatabricks.ymlübereinstimmen. Im Beispiel dieses Artikels ist dies der Falldev. -
DATABRICKS_HOSTrepräsentiert die URL für den jeweiligen Azure Databricks-Arbeitsbereich, beginnend mithttps://(zum Beispielhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net). Schließen Sie den nachgestellten/nach.netnicht ein. -
DATABRICKS_CLIENT_ID: Steht für die Anwendungs-ID des Microsoft Entra ID-Dienstprinzipals. -
DATABRICKS_CLIENT_SECRET: Steht für das Azure Databricks-OAuth-Geheimnis für den Microsoft Entra ID-Dienstprinzipal.
Schritt 3.2: Konfigurieren des Release-Agents für die Releasepipeline
Klicken Sie auf den Link 1 Auftrag, 0 Aufgaben innerhalb des Objekts Phase 1.
Klicken Sie auf der Registerkarte Aufgaben auf Agent-Auftrag.
Wählen Sie im Abschnitt Agent-Auswahl für Agent-Pool die Option Azure Pipelines aus.
Wählen Sie unter Agent-Spezifikation denselben Agent aus, den Sie zuvor als Build-Agent angegeben haben, in diesem Beispiel ubuntu-22.04.

Klicken Sie auf Speichern > OK.
Schritt 3.3: Festlegen der Python-Version für den Release-Agent
Klicken Sie zum Hinzufügen von Aufgaben im Abschnitt Agent-Auftrag auf das Pluszeichen, das in der folgenden Abbildung durch einen roten Pfeil gekennzeichnet wird. Eine durchsuchbare Liste der verfügbaren Aufgaben wird angezeigt. Es gibt außerdem einen Marketplace für Drittanbieter-Plug-Ins, die zur Ergänzung der Azure DevOps-Standardaufgaben verwendet werden können. In den nächsten Schritten fügen Sie dem Release-Agent verschiedene Aufgaben hinzu.
Die erste Aufgabe, die Sie hinzufügen, ist Python-Version verwenden, die sich auf der Registerkarte Tool befindet. Wenn Sie diese Aufgabe nicht finden können, suchen Sie mit dem Feld Suchen danach. Wenn Sie die Aufgabe gefunden haben, wählen Sie sie aus, und klicken dann auf die Schaltfläche Hinzufügen neben der Aufgabe Python-Version verwenden.
Wie bei der Buildpipeline möchten Sie sicherstellen, dass die Python-Version mit den Skripts kompatibel ist, die in nachfolgenden Aufgaben aufgerufen werden. Klicken Sie in diesem Fall auf die Aufgabe Python 3.x verwenden neben Agent-Auftrag, und legen Sie dann Versionsspezifikation auf
3.10fest. Legen Sie außerdem Anzeigename aufUse Python 3.10fest. Bei dieser Pipeline wird davon ausgegangen, dass Sie in den Clustern Databricks Runtime 13.3 LTS verwenden und Python 3.10.12 installiert ist.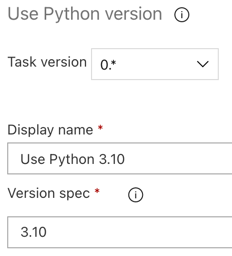
Klicken Sie auf Speichern > OK.
Schritt 3.4: Entpacken des Buildartefakts aus der Buildpipeline
Als Nächstes extrahieren Sie mithilfe der Aufgabe Dateien extrahieren die Python-Wheel-Datei, die zugehörigen Einstellungsdateien für das Release, die Notebooks und die Python-Codedatei aus der ZIP-Datei: Wählen Sie im Abschnitt Agent-Auftrag das Pluszeichen, anschließend auf der Registerkarte Hilfsprogramm die Aufgabe Dateien extrahieren und dann Hinzufügen aus.
Klicken Sie neben dem Agent-Auftrag auf die Aufgabe Dateien extrahieren, legen Sie Dateimuster archivieren auf
**/*.zipund den Zielordner auf die Systemvariable$(Release.PrimaryArtifactSourceAlias)/Databricksfest. Legen Sie außerdem Anzeigename aufExtract build pipeline artifactfest.Hinweis
$(Release.PrimaryArtifactSourceAlias)repräsentiert einen von Azure DevOps generierten Alias, um die primäre Artefaktquelle für den Release-Agent zu identifizieren, zum Beispiel_<your-github-alias>.<your-github-repo-name>. Die Releasepipeline legt diesen Wert als UmgebungsvariableRELEASE_PRIMARYARTIFACTSOURCEALIASin der Phase Auftrag initialisieren für den Release-Agent fest. Weitere Informationen finden Sie unter Klassische Release- und Artefaktvariablen.Legen Sie Anzeigename auf
Extract build pipeline artifactfest.
Klicken Sie auf Speichern > OK.
Schritt 3.5: Festlegen der Umgebungsvariable BUNDLE_ROOT
Damit das Beispiel dieses Artikels erwartungsgemäß funktioniert, müssen Sie eine Umgebungsvariable festlegen, die in der Releasepipeline benannt ist BUNDLE_ROOT . Databricks-Ressourcenpakete verwenden diese Umgebungsvariable, um zu bestimmen, wo sich die Datei databricks.yml befindet. So legen Sie diese Umgebungsvariable fest
Verwenden Sie die Aufgabe Umgebungsvariablen: Wählen Sie erneut das Pluszeichen im Abschnitt Agent-Auftrag, anschließend auf der Registerkarte Hilfsprogramm die Aufgabe Umgebungsvariablen und dann Hinzufügen aus.
Hinweis
Wenn die Aufgabe Umgebungsvariablen nicht auf der Registerkarte Hilfsprogramm angezeigt wird, geben Sie
Environment Variablesin das Suchfeld ein, und befolgen Sie die Anweisungen auf dem Bildschirm, um die Aufgabe auf der Registerkarte Hilfsprogramm hinzuzufügen. Dafür müssen Sie möglicherweise Azure DevOps verlassen und dann an die Stelle zurückkehren, an der Sie aufgehört haben.Geben Sie für Umgebungsvariablen (kommagetrennt)die folgende Definition ein:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Hinweis
$(Agent.ReleaseDirectory)stellt einen von Azure DevOps generierten Alias dar, der den Speicherort des Releaseverzeichnisses für den Release-Agent angibt, z. B./home/vsts/work/r1/a. Die Releasepipeline legt diesen Wert als UmgebungsvariableAGENT_RELEASEDIRECTORYin der Phase Auftrag initialisieren für den Release-Agent fest. Weitere Informationen finden Sie unter Klassische Release- und Artefaktvariablen. Weitere Informationen zu$(Release.PrimaryArtifactSourceAlias)finden Sie im Hinweis im vorherigen Schritt.Legen Sie Anzeigename auf
Set BUNDLE_ROOT environment variablefest.
Klicken Sie auf Speichern > OK.
Schritt 3.6. Installieren Sie die Databricks CLI- und Python-Wheel Build Tools
Installieren Sie als Nächstes die Databricks CLI- und Python-Wheel Build Tools auf dem Release-Agent. Der Release-Agent ruft die Databricks CLI und die Python-Wheel-Build Tools in den nächsten Aufgaben auf. Verwenden Sie dazu die Aufgabe Bash: Klicken Sie erneut auf das Pluszeichen im Abschnitt Agent-Auftrag, wählen Sie auf der Registerkarte Hilfsprogramm die Aufgabe Bash aus, und klicken Sie dann auf Hinzufügen.
Klicken Sie neben Agent-Auftrag auf die Aufgabe Bash-Skript.
Wählen Sie als Typ die Option Inline aus.
Ersetzen Sie den Inhalt für das Skript durch den folgenden Befehl, mit dem die Databricks CLI und Python Wheel Build Tools installiert werden:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelLegen Sie Anzeigename auf
Install Databricks CLI and Python wheel build toolsfest.
Klicken Sie auf Speichern > OK.
Schritt 3.7: Überprüfen des Databricks-Ressourcenpakets
In diesem Schritt stellen Sie sicher, dass die Datei databricks.yml syntaktisch korrekt ist.
Verwenden Sie die Aufgabe Bash: Wählen Sie erneut das Pluszeichen im Abschnitt Agent-Auftrag, anschließend auf der Registerkarte Hilfsprogramm die Aufgabe Bash und dann Hinzufügen aus.
Klicken Sie neben Agent-Auftrag auf die Aufgabe Bash-Skript.
Wählen Sie als Typ die Option Inline aus.
Ersetzen Sie den Inhalt von Script durch den folgenden Befehl, der die Databricks CLI verwendet, um zu überprüfen, ob die Datei
databricks.ymlsyntaktisch korrekt ist:databricks bundle validate -t $(BUNDLE_TARGET)Legen Sie Anzeigename auf
Validate bundlefest.Klicken Sie auf Speichern > OK.
Schritt 3.8: Bereitstellen des Bundles
In diesem Schritt erstellen Sie die Python-Wheel-Datei und stellen die erstellte Python-Wheel-Datei, die beiden Python-Notebooks und die Python-Datei aus der Releasepipeline in Ihrem Azure Databricks-Arbeitsbereich bereit.
Verwenden Sie die Aufgabe Bash: Wählen Sie erneut das Pluszeichen im Abschnitt Agent-Auftrag, anschließend auf der Registerkarte Hilfsprogramm die Aufgabe Bash und dann Hinzufügen aus.
Klicken Sie neben Agent-Auftrag auf die Aufgabe Bash-Skript.
Wählen Sie als Typ die Option Inline aus.
Ersetzen Sie den Inhalt von Script durch den folgenden Befehl, der die Databricks CLI verwendet, um die Python-Raddatei zu erstellen und die Beispieldateien dieses Artikels aus der Releasepipeline in Ihrem Azure Databricks-Arbeitsbereich bereitzustellen:
databricks bundle deploy -t $(BUNDLE_TARGET)Legen Sie Anzeigename auf
Deploy bundlefest.Klicken Sie auf Speichern > OK.
Schritt 3.9: Ausführen des Notebooks für den Komponententest für das Python-Wheel
In diesem Schritt führen Sie einen Auftrag aus, der das Notebook für den Komponententest in Ihrem Azure Databricks-Arbeitsbereich ausführt. Dieses Notizbuch führt Komponententests mit der Logik der Python-Radbibliothek aus.
Verwenden Sie die Aufgabe Bash: Wählen Sie erneut das Pluszeichen im Abschnitt Agent-Auftrag, anschließend auf der Registerkarte Hilfsprogramm die Aufgabe Bash und dann Hinzufügen aus.
Klicken Sie neben Agent-Auftrag auf die Aufgabe Bash-Skript.
Wählen Sie als Typ die Option Inline aus.
Ersetzen Sie den Inhalt von Script durch den folgenden Befehl, der die Databricks CLI verwendet, um den Auftrag in Ihrem Azure Databricks-Arbeitsbereich auszuführen:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsLegen Sie Anzeigename auf
Run unit testsfest.Klicken Sie auf Speichern > OK.
Schritt 3.10: Ausführen des Notebooks, das das Python-Wheel aufruft
In diesem Schritt führen Sie einen Auftrag aus, der ein anderes Notebook in Ihrem Azure Databricks-Arbeitsbereich ausführt. Dieses Notebook ruft die Python-Wheel-Bibliothek auf.
Verwenden Sie die Aufgabe Bash: Wählen Sie erneut das Pluszeichen im Abschnitt Agent-Auftrag, anschließend auf der Registerkarte Hilfsprogramm die Aufgabe Bash und dann Hinzufügen aus.
Klicken Sie neben Agent-Auftrag auf die Aufgabe Bash-Skript.
Wählen Sie als Typ die Option Inline aus.
Ersetzen Sie den Inhalt von Script durch den folgenden Befehl, der die Databricks CLI verwendet, um den Auftrag in Ihrem Azure Databricks-Arbeitsbereich auszuführen:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookLegen Sie Anzeigename auf
Run notebookfest.Klicken Sie auf Speichern > OK.
Sie haben damit die Konfiguration der Releasepipeline abgeschlossen. Sie sollte wie folgt aussehen:
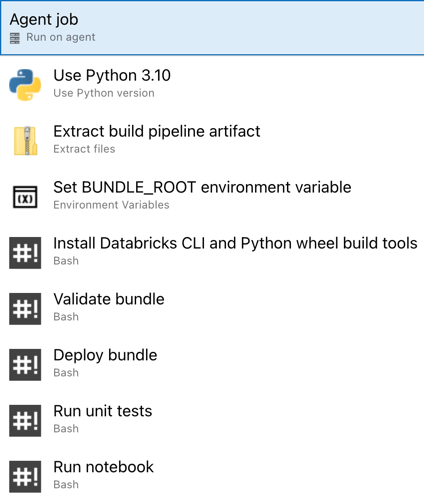
Schritt 4: Ausführen der Build- und Releasepipelines
In diesem Schritt führen Sie die Pipelines manuell aus. Informationen zum automatischen Ausführen von Pipelines finden Sie unter Angeben von Ereignissen, die Pipelines auslösen und Releasetrigger.
So führen Sie die Buildpipeline manuell aus
- Klicken Sie auf der Randleiste im Menü Pipelines auf Pipelines.
- Klicken Sie auf den Namen der Buildpipeline, und klicken Sie dann auf "Pipeline ausführen".
- Wählen Sie unter Branch/Tag den Namen des Branches in Ihrem Git-Repository aus, der den gesamten von Ihnen hinzugefügten Quellcode enthält. In diesem Beispiel wird davon ausgegangen, dass es sich um den Branch
releasehandelt. - Klicken Sie auf Ausführen. Die Ausführungsseite der Buildpipeline wird angezeigt.
- Um den Fortschritt der Buildpipeline anzuzeigen und die zugehörigen Protokolle anzuzeigen, klicken Sie auf das sich drehende Symbol neben "Auftrag".
- Nachdem das Symbol Auftrag in ein grünes Häkchen geändert wurde, fahren Sie mit der Ausführung der Releasepipeline fort.
So führen Sie die Releasepipeline manuell aus
- Nachdem die Buildpipeline erfolgreich ausgeführt wurde, wählen Sie im Menü Pipelines auf der Randleiste Releases aus.
- Klicken Sie auf den Namen der Releasepipeline, und klicken Sie dann auf "Release erstellen".
- Klicken Sie auf "Erstellen".
- Um den Fortschritt der Veröffentlichungspipeline anzuzeigen, klicken Sie in der Liste der Versionen auf den Namen der neuesten Version.
- Wählen Sie im Feld Phasen die Option Phase 1 und dann Protokolle aus.