Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel bietet eine Übersicht über die Mosaic AI Vektorsuche, einschließlich was es ist und wie es funktioniert.
Was ist die Mosaic AI-Vektorsuche?
Mosaik AI Vector Search ist eine Vektorsuchlösung, die in die Databricks Data Intelligence Platform integriert ist und in seine Governance- und Produktivitätstools integriert ist. Die Vektorsuche ist eine Suchart, die für das Abrufen von Einbettungen optimiert ist. Einbettungen sind mathematische Darstellungen des semantischen Inhalts von Daten, in der Regel Text- oder Bilddaten. Einbettungen werden durch ein großes Sprachmodell generiert und sind eine wichtige Komponente vieler generativer KI-Anwendungen, die von der Suche nach Dokumenten oder Bildern abhängig sind, die einander ähneln. Beispiele sind RAG-Systeme, Empfehlungssysteme und Bild- und Videoerkennung.
Mit der Mosaic AI-Vektorsuche erstellen Sie einen Vektorsuchindex aus einer Delta-Tabelle. Der Index enthält eingebettete Daten mit Metadaten. Anschließend können Sie den Index mithilfe einer REST-API abfragen, um die ähnlichsten Vektoren zu identifizieren und die zugehörigen Dokumente zurückzugeben. Sie können den Index so strukturieren, dass er automatisch synchronisiert wird, wenn die zugrunde liegende Delta-Tabelle aktualisiert wird.
Die Mosaik-KI-Vektorsuche unterstützt Folgendes:
- Hybride Stichwort-Ähnlichkeitssuche.
- Filtern.
- Reranking.
- Zugriffssteuerungslisten (ACCESS Control Lists, ACLs), um Vektorsuchendpunkte zu verwalten.
- Nur ausgewählte Spalten synchronisieren.
- Speichern und synchronisieren Sie generierte Einbettungen.
Wie funktioniert die Mosaik-KI-Vektorsuche?
Die Mosaic AI Vektorsuche verwendet den Hierarchical Navigable Small World (HNSW)-Algorithmus für annähernd nächste Nachbarn (ANN)-Suchen und die L2-Entfernungsmetrik, um die Ähnlichkeit von Einbettungsvektoren zu messen. Wenn Sie Kosinusgleichheit verwenden möchten, müssen Sie Ihre Datenpunkteinbettungen normalisieren, bevor Sie sie in die Vektorsuche einbetten. Wenn die Datenpunkte normalisiert werden, ist die von L2-Entfernung erzeugte Rangfolge identisch mit der Rangfolge, die durch Kosinusgleichheit erzeugt wird.
Die Mosaic AI-Vektorsuche unterstützt auch eine hybride Suchfunktion zur Ähnlichkeit mit Schlüsselwörtern, die die vektorbasierte Einbettungssuche mit herkömmlichen schlüsselwortbasierten Suchtechniken kombiniert. Dieser Ansatz entspricht exakten Wörtern in der Abfrage und verwendet gleichzeitig eine vektorbasierte Ähnlichkeitssuche, um die semantischen Beziehungen und den Kontext der Abfrage zu erfassen.
Durch die Integration dieser beiden Techniken ruft die Hybrid-Stichwort-Ähnlichkeitssuche Dokumente ab, die nicht nur die genauen Schlüsselwörter enthalten, sondern auch solche, die konzeptionell ähnlich sind und umfassendere und relevante Suchergebnisse bereitstellen. Diese Methode ist besonders bei RAG-Anwendungen nützlich, bei denen Quelldaten eindeutige Schlüsselwörter wie SKUs oder Bezeichner aufweisen, die nicht gut für die reine Ähnlichkeitssuche geeignet sind.
Ausführliche Informationen zur API finden Sie in der Python SDK-Referenz und Abfrage eines Vektor-Suchindex.
Berechnung der Ähnlichkeitssuche
Die Berechnung der Ähnlichkeitssuche verwendet die folgende Formel:

wobei dist der euklidische Abstand zwischen der Abfrage q und dem Indexeintrag x ist:

Stichwortsuchalgorithmus
Relevanzbewertungen werden mit Okapi BM25 berechnet. Alle Text- oder Zeichenfolgenspalten werden durchsucht, einschließlich der Quelltexteinbettung und Metadatenspalten im Text- oder Zeichenfolgenformat. Die Tokenisierungsfunktion teilt sich an Wortgrenzen, entfernt Interpunktion und konvertiert den gesamten Text in Kleinbuchstaben.
Wie Ähnlichkeitssuche und Stichwortsuche kombiniert werden
Die Ähnlichkeitssuche und die Schlüsselwortsuchergebnisse werden mithilfe der Funktion Reciprocal Rank Fusion (RRF) kombiniert.
RRF bewertet jedes Dokument zuerst anhand der Bewertungen von jeder Methode neu:


rrf_param steuert die relative Wichtigkeit höher bewerteter und niedriger bewerteter Dokumente. Basierend auf der Literatur ist rrf_param auf 60 festgelegt.
Bewertungen werden normalisiert, sodass der höchste mögliche Wert 1 mit dem folgenden Normalisierungsfaktor ist:
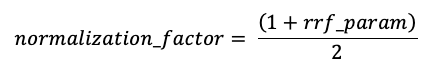
Die Endbewertung für jedes Dokument wird wie folgt berechnet:

Die Dokumente mit den höchsten Endergebnissen werden zurückgegeben.
Optionen zum Bereitstellen von Vektoreinbettungen
Um einen Vektorsuchindex in Databricks zu erstellen, müssen Sie zuerst entscheiden, wie Vektoreinbettungen bereitgestellt werden sollen. Databricks unterstützt drei Optionen.
Option 1: Delta-Synchronisierungsindex mit von Databricks berechneten Einbettungen
Mit dieser Option stellen Sie eine Delta-Quelltabelle bereit, die Daten im Textformat enthält. Databricks berechnet die Einbettungen mithilfe eines von Ihnen angegebenen Modells und speichert optional die Einbettungen in einer Tabelle im Unity-Katalog. Wenn die Delta-Tabelle aktualisiert wird, bleibt der Index mit der Delta-Tabelle synchronisiert.
Das folgende Diagramm veranschaulicht diesen Prozess:
- Berechnen Sie Abfrageeinbettungen. Abfrage kann Metadatenfilter enthalten.
- Durchführen der Ähnlichkeitssuche zur Identifizierung der relevantesten Dokumente.
- Geben Sie die relevantesten Dokumente zurück und fügen Sie sie zur Abfrage hinzu.

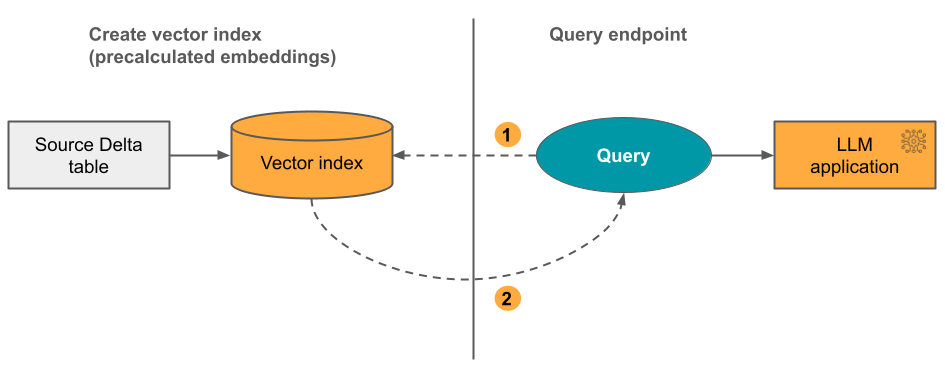
Option 2: Delta-Sync-Index mit selbstverwalteten Einbettungen
Mit dieser Option stellen Sie eine Delta-Quelltabelle bereit, die vorab berechnete Einbettungen enthält. Wenn die Delta-Tabelle aktualisiert wird, bleibt der Index mit der Delta-Tabelle synchronisiert.
Hinweis
Es ist nicht möglich, einen selbstverwalteten Einbettungsindex in einen von Databricks verwalteten Index zu konvertieren. Wenn Sie später verwaltete Einbettungen verwenden möchten, müssen Sie einen neuen Index erstellen und einbetten.
Das folgende Diagramm veranschaulicht diesen Prozess:
- Abfrage besteht aus Einbettungen und kann Metadatenfilter enthalten.
- Durchführen der Ähnlichkeitssuche zur Identifizierung der relevantesten Dokumente. Geben Sie die relevantesten Dokumente zurück und fügen Sie sie zur Abfrage hinzu.
Option 3: Direkter Vektorzugriff-Index
Mit dieser Option müssen Sie den Index mithilfe der REST-API manuell aktualisieren, wenn sich die Einbettungstabelle ändert.
Das folgende Diagramm veranschaulicht diesen Prozess:

Endpunktoptionen
Die Mosaik AI-Vektorsuche bietet die folgenden Optionen, damit Sie die Endpunktkonfiguration auswählen können, die den Anforderungen Ihrer Anwendung entspricht.
Hinweis
Speicheroptimierte Endpunkte befinden sich in der öffentlichen Vorschau.
- Standardendpunkte verfügen über eine Kapazität von 320 Millionen Vektoren in Dimension 768.
- Speicheroptimierte Endpunkte verfügen über eine größere Kapazität (über eine Milliarde Vektoren in Dimension 768) und bieten 10-20x schnellere Indizierung. Abfragen auf speicheroptimierten Endpunkten haben eine etwas erhöhte Latenz von ca. 250 msec. Die Preise für diese Option sind für die größere Anzahl von Vektoren optimiert. Details zu den Preisen finden Sie auf der Preisseite für die Vektorsuche. Informationen zum Verwalten von Vektorsuchkosten finden Sie unter Mosaik AI Vector Search: Cost Management Guide.
Sie geben den Endpunkttyp an, wenn Sie den Endpunkt erstellen.
Siehe auch Einschränkungen für speicheroptimierte Endpunkte.
Einrichten der Mosaic AI-Vektorsuche
Um die Mosaic AI-Vektorsuche zu verwenden, müssen Sie Folgendes erstellen:
Ein Endpunkt für die Vektorsuche. Dieser Endpunkt dient dem Vektorsuchindex. Sie können den Endpunkt mithilfe der REST-API oder des SDK abfragen und aktualisieren. Anweisungen finden Sie unter Erstellen eines Vektorsuchendpunkts.
Endpunkte skalieren automatisch, um sowohl die Größe des Indexes als auch die Anzahl paralleler Anfragen zu bewältigen. Speicheroptimierte Endpunkte werden automatisch nach unten skaliert, wenn ein Index gelöscht wird. Standardendpunkte werden nicht automatisch herunterskaliert.
Ein Vektorsuchindex. Der Vektorsuchindex wird aus einer Delta-Tabelle erstellt und ist optimiert, um ungefähre nächste Nachbarn (ANN)-Suchvorgänge in Echtzeit auszuführen. Ziel der Suche ist es, Dokumente zu identifizieren, die der Abfrage ähneln. Vektorsuchindizes werden im Unity-Katalog angezeigt und unterliegen diesem. Anweisungen finden Sie unter Erstellen eines Vektorsuchindex.
Wenn Sie darüber hinaus von Databricks die Einbettungen berechnen lassen möchten, können Sie einen vordefinierten Foundation Model-APIs-Endpunkt verwenden oder einen Modell-Serving-Endpunkt erstellen, um das Einbettungsmodell Ihrer Wahl bereitzustellen. Anweisungen hierzu finden Sie unter Foundation Model-APIs mit tokenbasierter Bezahlung oder Erstellen von Foundation Model-Bereitstellungsendpunkten.
Um den Endpunkt des Modells abzufragen, verwenden Sie entweder die REST-API oder das Python SDK. Ihre Abfrage kann Filter basierend auf einer beliebigen Spalte in der Delta-Tabelle definieren. Ausführliche Informationen finden Sie unter Verwenden von Filtern für Abfragen, in der API-Referenz oder der Python SDK-Referenz.
Anforderungen
- Arbeitsbereich mit Unity Catalog-Unterstützung.
- Serverloses Rechnen aktiviert Anleitungen finden Sie unter Verbinden mit serverlosem Computing.
- Für Standardendpunkte muss die Quelltabelle "Datenfeed ändern" aktiviert sein. Siehe Verwenden des Delta Lake-Änderungs-Datenfeeds in Azure Databricks.
- Zum Erstellen eines Vektorsuchindex müssen Sie über CREATE TABLE Berechtigungen für das Katalogschema verfügen, in dem der Index erstellt wird.
Die Berechtigung zum Erstellen und Verwalten von Vektorsuchendpunkten wird mithilfe von Zugriffssteuerungslisten konfiguriert. Siehe Vektor-Suche-Endpunkt-ACLs.
Datenschutz und Authentifizierung
Databricks implementiert die folgenden Sicherheitskontrollen zum Schutz Ihrer Daten:
- Jede Kundenanforderung an die Mosaic AI-Vektorsuche ist logisch isoliert, authentifiziert und autorisiert.
- Die Mosaic AI-Vektorsuche verschlüsselt alle ruhenden Daten (AES-256) und während der Übertragung (TLS 1.2+).
Die Mosaik-KI-Vektorsuche unterstützt zwei Authentifizierungsmodi, Dienstprinzipale und persönliche Zugriffstoken (PATs). Für Produktionsanwendungen empfiehlt Databricks, Dienstprinzipale zu verwenden, die eine Leistung pro Abfrage bis zu 100 msec schneller im Verhältnis zu persönlichen Zugriffstoken aufweisen können.
Dienstprinzipaltoken. Ein Administrator kann ein Dienstprinzipaltoken generieren und an das SDK oder die API übergeben. Siehe Verwenden von Dienstprinzipalen. Für Produktionsanwendungsfälle empfiehlt Databricks die Verwendung eines Dienstprinzipal-Tokens.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Persönliches Zugriffstoken. Sie können ein persönliches Zugriffstoken verwenden, um sich bei der Mosaik AI-Vektorsuche zu authentifizieren. Siehe Persönliches Zugriffstoken für die Authentifizierung. Wenn Sie das SDK in einer Notizbuchumgebung verwenden, generiert das SDK automatisch ein PAT-Token für die Authentifizierung.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
vom Kunden verwaltete Schlüssel (Customer Managed Keys, CMK) werden auf Endpunkten unterstützt, die am oder nach dem 8. Mai 2024 erstellt wurden.
Nachverfolgen von Nutzung und Kosten
In der Tabelle mit dem abrechnungsfähigen Nutzungssystem können Sie die Nutzung und Kosten im Zusammenhang mit Vektorsuchindizes und Endpunkten überwachen. Dies ist eine Beispielabfrage:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Sie können die Verwendung auch nach Budgetrichtlinie abfragen. Siehe Mosaik KI-Vektorsuche: Budgetrichtlinien.
Ausführliche Informationen zum Inhalt der Abrechnungsnutzungstabelle finden Sie in der Tabellenreferenz für das abrechnungsfähige Nutzungssystem. Weitere Abfragen befinden sich im folgenden Beispiel-Notebook.
Notebook für Vektorsuche-Systemtabellenabfragen
Grenzwerte für die Ressourcen- und Datengröße
In der folgenden Tabelle sind Ressourcen- und Datengrößenbeschränkungen für Vektorsuchendpunkte und Indizes zusammengefasst:
| Resource | Granularität | Limit |
|---|---|---|
| Endpunkte der Vektorsuche | Pro Arbeitsbereich | 100 |
| Einbettungen (Delta-Synchronisierungsindex) | Pro Standardendpunkt | ~ 320.000.000 bei 768 einbettenden Dimensionen ~ 160.000.000 bei 1536 einbettenden Dimensionen ~ 80.000.000 bei einer Dimension von 3072 (skaliert ungefähr linear) |
| Einbettungen (Direkter Vektorzugriff-Index) | Pro Standardendpunkt | ~ 2.000.000 bei 768 einbettender Dimension |
| Einbettungen (speicheroptimierter Endpunkt) | Pro speicher-optimierten Endpunkt | ~ 1.000.000.000 bei der Dimension 768 Einbettung |
| Einbettungsdimension | Pro Index | 4096 |
| Indizes | Pro Endpunkt | 50 |
| Columns | Pro Index | 50 |
| Columns | Unterstützte Typen: Bytes, short, integer, long, float, double, boolean, string, timestamp, date, array | |
| Metadatenfelder | Pro Index | 50 |
| Indexname | Pro Index | 128 Zeichen |
Die folgenden Grenzwerte gelten für die Erstellung und Aktualisierung von Vektorsuchindizes:
| Resource | Granularität | Limit |
|---|---|---|
| Zeilengröße für Delta-Synchronisierungsindex | Pro Index | 100 KB |
| Spaltegröße der Einbettungsquelle für den Delta Sync-Index | Pro Index | 32764 Bytes |
| Größenbeschränkung für Massenupertanforderungen für den Direct Vector-Index | Pro Index | 10 MB |
| Größenbeschränkung für Massenlöschanforderungen für den Direct Vector-Index | Pro Index | 10 MB |
Die folgenden Grenzwerte gelten für die Abfrage-API.
| Resource | Granularität | Limit |
|---|---|---|
| Länge des Abfragetexts | Pro Abfrage | 32764 Zeichen |
| Token bei Verwendung der Hybridsuche | Pro Abfrage | 1024 Wörter oder 2-Byte-Zeichen |
| Filterbedingungen | Pro Filterklausel | 1024 Elemente |
| Maximale Anzahl der zurückgegebenen Ergebnisse (ungefähre Nächste Nachbarsuche) | Pro Abfrage | 10.000 |
| Maximale Anzahl der zurückgegebenen Ergebnisse (Hybrid-Stichwort-Ähnlichkeitssuche) | Pro Abfrage | 200 |
Einschränkungen
- Der Spaltenname
_idist reserviert. Wenn die Quelltabelle eine Spalte mit dem Namen_idhat, benennen Sie sie um, bevor Sie einen Vektorsuchindex erstellen. - Berechtigungen auf Zeilen- und Spaltenebene werden nicht unterstützt. Sie können jedoch ihre eigenen ACLs auf Anwendungsebene mithilfe der Filter-API implementieren.
- Sie können einen Index nicht in einen anderen Arbeitsbereich klonen. Sie können Arbeitsbereichsübergreifende Anforderungen mithilfe des Databricks SDK oder der REST-API vornehmen.
Einschränkungen für speicheroptimierte Endpunkte
Die Einschränkungen in diesem Abschnitt gelten nur für speicheroptimierte Endpunkte. Speicheroptimierte Endpunkte befinden sich in der öffentlichen Vorschau.
- Der fortlaufende Synchronisierungsmodus wird nicht unterstützt.
- Columns to sync wird nicht unterstützt.
- Die Dimension der Einbettung muss durch 16 teilbar sein.
- Das inkrementelle Update wird nur teilweise unterstützt. Jede Synchronisierung muss Teile des Vektorsuchindex neu erstellen.
- Bei verwalteten Indizes werden alle zuvor berechneten Einbettungen wiederverwendet, wenn sich die Quellzeile nicht geändert hat.
- Sie sollten eine erhebliche End-to-End-Reduzierung der für eine Synchronisierung erforderlichen Zeit im Vergleich zu den Standardendpunkten erwarten. Datasets mit 1 Milliarden Einbettungen sollten eine Synchronisierung in weniger als 8 Stunden abschließen. Kleinere Datensätze nehmen weniger Zeit in Anspruch, um sich zu synchronisieren.
- FedRAMP-kompatible Arbeitsbereiche werden nicht unterstützt.
- Vom Kunden verwaltete Schlüssel (CMK) werden nicht unterstützt.
- Um ein benutzerdefiniertes Einbettungsmodell für einen verwalteten Delta-Synchronisierungsindex zu verwenden, muss die AI-Abfrage für benutzerdefinierte Modelle und die Vorschau für externe Modelle aktiviert sein. Informationen zum Aktivieren von Vorschauen finden Sie unter Verwalten von Azure Databricks-Vorschauen .
- Speicheroptimierte Endpunkte unterstützen bis zu 1 Milliarden Einbettungen von Vektoren mit 768 Dimensionen. Wenn Sie einen größeren Anwendungsfall haben, wenden Sie sich an Ihr Kontoteam.