Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Lakeflow Connect bietet einfache und effiziente Connectors zum Aufnehmen von Daten aus lokalen Dateien, beliebten Unternehmensanwendungen, Datenbanken, Cloudspeicher, Nachrichtenbussen und mehr. Auf dieser Seite werden einige möglichkeiten beschrieben, wie Lakeflow Connect die ETL-Leistung verbessern kann. Außerdem werden gängige Anwendungsfälle und die Bandbreite der unterstützten Ingestion-Tools, von vollständig verwalteten Konnektoren bis zu anpassbaren Frameworks, behandelt.
Flexible Servicemodelle
Lakeflow Connect bietet eine breite Palette von Connectors für Unternehmensanwendungen, Cloudspeicher, Datenbanken, Nachrichtenbusse und vieles mehr. Es bietet Ihnen auch die Flexibilität, zwischen den folgenden Optionen zu wählen:
| Option | BESCHREIBUNG |
|---|---|
| Ein vollständig verwalteter Dienst | Sofort einsatzbereite Konnektoren, die den Datenzugriff mit einfachen Benutzeroberflächen und leistungsstarken APIs demokratisieren. Auf diese Weise können Sie schnell robuste Aufnahmepipelines erstellen und gleichzeitig die langfristigen Wartungskosten minimieren. |
| Eine benutzerdefinierte Pipeline | Wenn Sie weitere Anpassungen benötigen, können Sie Lakeflow Spark Declarative Pipelines oder Structured Streaming verwenden. Letztendlich ermöglicht diese Vielseitigkeit Lakeflow Connect, die spezifischen Anforderungen Ihrer Organisation zu erfüllen. |
Vereinheitlichung mit grundlegenden Databricks-Tools
Lakeflow Connect verwendet Kernfunktionen von Databricks, um ein umfassendes Datenmanagement bereitzustellen. Zum Beispiel bietet sie Governance mithilfe des Unity-Katalogs, Orchestrierung mit Lakeflow-Aufträgen und eine ganzheitliche Überwachung Ihrer Pipelines. Dies hilft Ihrer Organisation, Datensicherheit, Qualität und Kosten zu verwalten und gleichzeitig Ihre Erfassungsprozesse mit Ihren anderen Datentechniktools zu vereinheitlichen. Lakeflow Connect basiert auf einer offenen Data Intelligence Platform mit voller Flexibilität, um Ihre bevorzugten Drittanbietertools zu integrieren. Dadurch wird eine maßgeschneiderte Lösung sichergestellt, die sich an Ihre bestehende Infrastruktur und zukünftige Datenstrategien richtet.
Schnelle, skalierbare Aufnahme
Lakeflow Connect verwendet inkrementelle Lese- und Schreibvorgänge, um eine effiziente Aufnahme zu ermöglichen. In Kombination mit nachgelagerten inkrementellen Transformationen kann dies die ETL-Leistung erheblich verbessern.
Gängige Anwendungsfälle
Kunden nehmen Daten ein, um die herausforderndsten Probleme ihrer Organisation zu lösen. Beispiele für Anwendungsfälle sind:
| Anwendungsfall | BESCHREIBUNG |
|---|---|
| Kunde 360 | Messen der Kampagnenleistung und Kundenleadbewertung |
| Portfoliomanagement | Maximieren des ROI mit historischen und Prognosemodellen |
| Consumer Analytics | Personalisieren der EinkaufserfahrungEn Ihrer Kunden |
| Zentrale Personalabteilung | Unterstützung der Mitarbeiter Ihrer Organisation |
| Digitale Zwillinge | Steigerung der Fertigungseffizienz |
| RAG-Chatbots | Erstellen von Chatbots, die Benutzern helfen, Richtlinien, Produkte und mehr zu verstehen |
Ebenen des ETL-Stapels
Einige Verbinder arbeiten auf einer Ebene des ETL-Stapels. Beispielsweise bietet Databricks vollständig verwaltete Connectors für Unternehmensanwendungen wie Salesforce und Datenbanken wie SQL Server. Andere Verbinder funktionieren auf mehreren Ebenen des ETL-Stapels. Sie können z. B. Standardconnectors entweder in Structured Streaming für eine umfassende Anpassung oder Lakeflow Spark Declarative Pipelines für ein besser verwaltetes Erlebnis verwenden. Sie können auch Ihre Anpassungsebene für Streamingdaten aus Apache Kafka, Amazon Kinesis, Google Pub/Sub und Apache Pulsar auswählen.
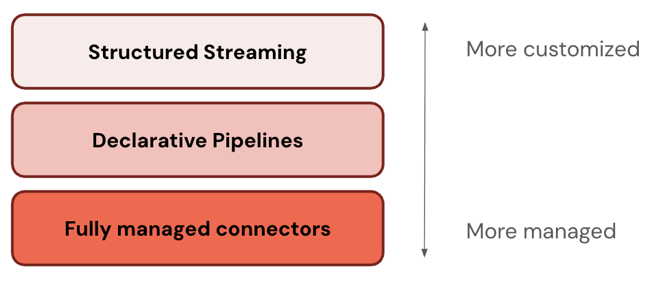
Databricks empfiehlt, mit der am häufigsten verwalteten Ebene zu beginnen. Wenn dies Ihre Anforderungen nicht erfüllt (z. B. wenn Ihre Datenquelle nicht unterstützt wird), gehen Sie zur nächsten Ebene. Databricks plant die Erweiterung der Unterstützung für weitere Connectors auf allen drei Ebenen.
In der folgenden Tabelle werden die drei Ebenen der Aufnahmeprodukte beschrieben, sortiert von den meisten anpassbaren bis zu den meisten verwalteten Produkten:
| Ebene | BESCHREIBUNG |
|---|---|
| Strukturiertes Streaming | Strukturiertes Streaming ist eine API für die inkrementelle Datenstromverarbeitung in nahezu Echtzeit. Sie bietet eine starke Leistung, Skalierbarkeit und Fehlertoleranz. |
| Lakeflow Spark Declarative Pipelines | Lakeflow Spark Declarative Pipelines baut auf Structured Streaming auf und bietet ein deklaratives Framework zum Erstellen von Datenpipelines. Sie können die Transformationen definieren, die für Ihre Daten ausgeführt werden sollen, und Lakeflow Spark Declarative Pipelines verwaltet Orchestrierung, Überwachung, Datenqualität, Fehler und vieles mehr. Daher bietet es mehr Automatisierung und weniger Mehraufwand als strukturiertes Streaming. |
| Vollständig verwaltete Connectors | Vollständig verwaltete Connectors basieren auf Lakeflow Spark Declarative Pipelines und bieten noch mehr Automatisierung für die beliebtesten Datenquellen. Sie erweitern die Funktionen von Lakeflow Spark Declarative Pipelines, um auch quellspezifische Authentifizierung, CDC, Edge case Handling, langfristige API-Wartung, automatisierte Wiederholungen, automatisierte Schemaentwicklung usw. einzuschließen. Daher bieten sie noch mehr Automatisierung für alle unterstützten Datenquellen. |
Verwaltete Anschlüsse
Sie können vollständig verwaltete Konnektoren verwenden, um Daten aus Unternehmensanwendungen und Datenbanken zu erfassen.
Zu den unterstützten Connectors gehören:
Zu den unterstützten Schnittstellen gehören:
- Databricks UI
- Databricks-Ressourcenpakete
- Databricks-APIs
- Databricks-SDKs
- Databricks-Befehlszeilenschnittstelle
Standardkonnektoren
Zusätzlich zu den verwalteten Connectors bietet Databricks anpassbare Connectors für Cloudobjektspeicher und Nachrichtenbusse. Siehe Standardanschlüsse in Lakeflow Connect.
Hochladen und Herunterladen von Dateien
Sie können Dateien verarbeiten, die sich in Ihrem lokalen Netzwerk befinden, Dateien, die auf ein Volume hochgeladen wurden, oder Dateien, die von einer Internetquelle heruntergeladen wurden. Siehe Dateien.
Erfassungspartner
Viele Drittanbietertools unterstützen die Batch- oder Streaming-Datenaufnahme in Databricks. Databricks überprüft verschiedene Drittanbieterintegrationen, obwohl die Schritte zum Konfigurieren des Zugriffs auf Quellsysteme und Aufnahmedaten je nach Tool variieren. Eine Liste der überprüften Tools finden Sie unter Ingestion-Partner . Einige Technologiepartner werden auch in Databricks Partner Connect vorgestellt, das über eine Benutzeroberfläche verfügt, die das Verbinden von Drittanbietertools mit Lakehouse-Daten vereinfacht.
Eigenständige Erfassung
Databricks bietet eine allgemeine Computeplattform. Daher können Sie eigene Ingestionskonnektoren mit jeder Programmiersprache erstellen, die von Databricks unterstützt wird, z. B. Python oder Java. Sie können auch beliebte Open Source-Connectorbibliotheken wie das Datenladetool, Airbyte und Debezium importieren und verwenden.
Alternativen zur Erfassung
Databricks empfiehlt die Aufnahme für die meisten Anwendungsfälle, da sie skaliert wird, um hohe Datenvolumes, Abfragen mit geringer Latenz und API-Grenzwerte von Drittanbietern zu berücksichtigen. Die Datenerfassung kopiert Daten aus Ihren Quellsystemen in Azure Databricks. Dies führt zu redundanten Daten, die mit der Zeit veralten könnten. Wenn Sie keine Daten kopieren möchten, können Sie die folgenden Tools verwenden:
| Werkzeug | BESCHREIBUNG |
|---|---|
| Lakehouse-Verbund | Ermöglicht es Ihnen, externe Datenquellen abzufragen, ohne Ihre Daten zu verschieben. |
| Delta-Sharing | Ermöglicht es Ihnen, Daten auf allen Plattformen, Clouds und Regionen sicher zu teilen. |