Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
For each Tasks übergeben Parameterarrays an geschachtelte Aufgaben iterativ, um jedem geschachtelten Vorgang Informationen für die Ausführung zu geben. Parameterarrays sind auf 10.000 Zeichen oder 48 KB beschränkt, wenn Sie Verweise auf Aufgabenwerte verwenden, um diese zu übergeben. Wenn Sie eine größere Menge an Daten an die geschachtelten Aufgaben übergeben müssen, können Sie diese nicht direkt über Eingaben, Aufgabenwerte oder Auftragsparameter weitergeben.
Eine Alternative zum Übergeben der vollständigen Daten besteht darin, die Aufgabendaten als JSON-Datei zu speichern und einen Nachschlageschlüssel (in die JSON-Daten) über die Aufgabeneingabe anstelle der vollständigen Daten zu übergeben. Geschachtelte Aufgaben können den Schlüssel verwenden, um die spezifischen Daten abzurufen, die für jede Iteration erforderlich sind.
Das folgende Beispiel zeigt eine JSON-Beispielkonfigurationsdatei und das Übergeben von Parametern an eine geschachtelte Aufgabe, die die Werte in der JSON-Konfiguration nachsieht.
JSON-Beispielkonfiguration
Diese Beispielkonfiguration ist eine Liste der Schritte mit Parametern (args) für jede Iteration (nur drei Schritte werden für dieses Beispiel gezeigt). Gehen Sie davon aus, dass diese JSON-Datei als /Workspace/Users/<user>/copy-filtered-table-config.jsongespeichert wird. Wir verweisen darauf innerhalb der geschachtelten Aufgabe.
{
"steps": [
{
"key": "table_1",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_1",
"destination_table": "filtered_table_1",
"filter_column": "col_a",
"filter_value": "value_1"
}
}
{
"key": "table_2",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_2",
"destination_table": "filtered_table_2",
"filter_column": "col_b",
"filter_value": "value_2"
}
},
{
"key": "table_3",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_3",
"destination_table": "filtered_table_3",
"filter_column": "col_c",
"filter_value": "value_3"
}
},
]
}
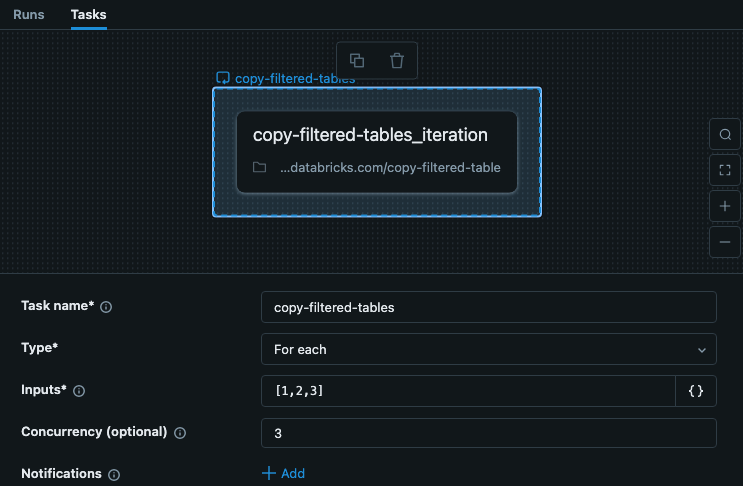
Beispielaufgabe For each
Die For each Aufgabe in Ihrem Job umfasst Eingaben mit Schlüsseln für jede Iteration. Dieses Beispiel zeigt eine Aufgabe namens copy-filtered-tables, mit den Eingaben festgelegt auf ["table_1","table_2","table_3"]. Diese Liste ist auf 10.000 Zeichen beschränkt, aber da Sie nur Schlüssel übergeben, ist sie wesentlich kleiner als die vollständigen Daten.
In diesem Beispiel hängen die Schritte nicht von anderen Schritten oder Aufgaben ab, sodass wir eine Parallelität festlegen können, die größer als 1 ist, damit die Aufgabe schneller ausgeführt wird.
Geschachtelte Beispielaufgabe
Die geschachtelte Aufgabe erhält die Eingabe von der übergeordneten For each Aufgabe. In diesem Fall richten wir die Eingabe ein, die als Key für die Konfigurationsdatei verwendet werden soll. Die folgende Abbildung zeigt die geschachtelte Aufgabe, einschließlich der Einrichtung eines Parameters, der mit dem Wert keyaufgerufen wird{{input}}.
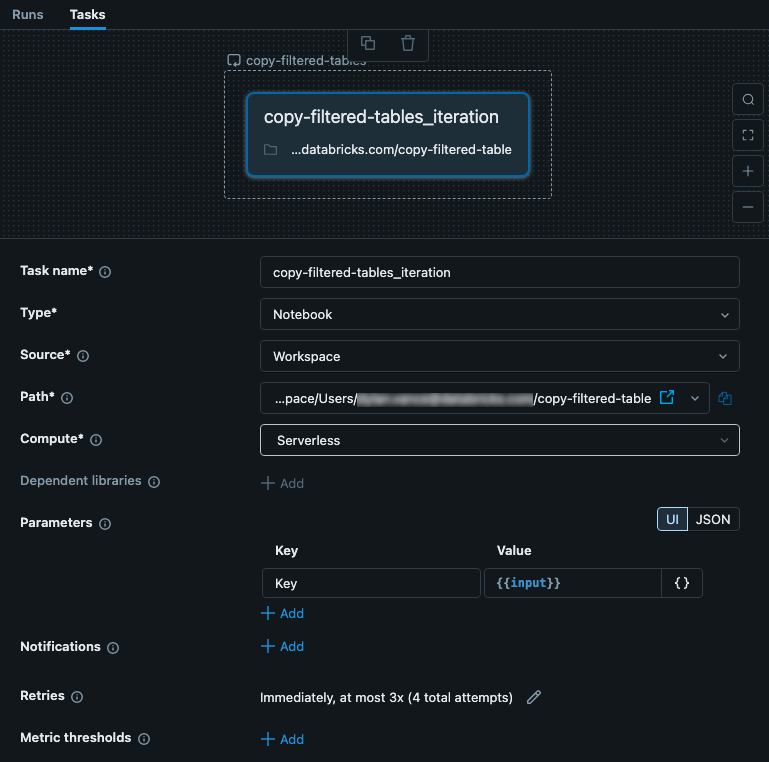
Diese Aufgabe ist ein Notizbuch, das Code enthält. In Ihrem Notizbuch können Sie den folgenden Python-Code verwenden, um die Eingabe zu lesen und diese als Schlüssel in der JSON-Konfigurationsdatei zu verwenden. Die Daten aus der JSON-Datei werden verwendet, um Daten aus einer Tabelle zu lesen, zu filtern und zu schreiben.
# copy-filtered-table (iteratable task code to read a table, filter by a value, and write as a new table)
from pyspark.sql.functions import expr
from types import SimpleNamespace
import json
# If the notebook is run outside of a job with a key parameter, this provides
# a default. This allows testing outside of a For each task
dbutils.widgets.text("key", "table_1", "key")
# load configuration (note that the path must be set to valid configuration file)
config_path = "/Workspace/Users/<user>/copy-filtered-table-config.json"
with open(config_path, "r") as file:
config = json.loads(file.read())
# look up step and arguments
key = dbutils.widgets.get("key")
current_step = next((step for step in config['steps'] if step['key'] == key), None)
if current_step is None:
raise ValueError(f"Could not find step '{key}' in the configuration")
args = SimpleNamespace(**current_step["args"])
# read the source table defined for the step, and filter it
df = spark.read.table(f"{args.catalog}.{args.schema}.{args.source_table}") \
.filter(expr(f"{args.filter_column} like '%{args.filter_value}%'"))
# write the filtered table to the destination
df.write.mode("overwrite").saveAsTable(f"{args.catalog}.{args.schema}.{args.destination_table}")