Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wenn Sie eine langsame Phase mit nicht viel E/A haben, kann dies durch Folgendes verursacht werden:
- Lesen vieler kleiner Dateien
- Schreiben in viele kleine Dateien
- Langsame UDF(s)
- Kartesische Verknüpfung
- Explodierende Verknüpfung
Fast alle diese Probleme können mit dem SQL-DAG identifiziert werden.
Öffnen der SQL-DAG
Um die SQL-DAG zu öffnen, scrollen Sie nach oben auf der Seite des Auftrags, und klicken Sie auf die zugeordnete SQL-Abfrage:

Nun sollte die DAG angezeigt werden. Wenn nicht, scrollen Sie ein bisschen herum, und Sie sollten es sehen:
Bevor Sie fortfahren, machen Sie sich mit der DAG vertraut und wo Zeit aufgewendet wird. Einige Knoten in der DAG verfügen über hilfreiche Zeitinformationen und andere nicht. Dieser Block dauerte beispielsweise 2,1 Minuten und stellt sogar die Phasen-ID bereit:

Dieser Knoten erfordert, dass Sie ihn öffnen müssen, um zu sehen, dass es 1,4 Minuten dauerte:
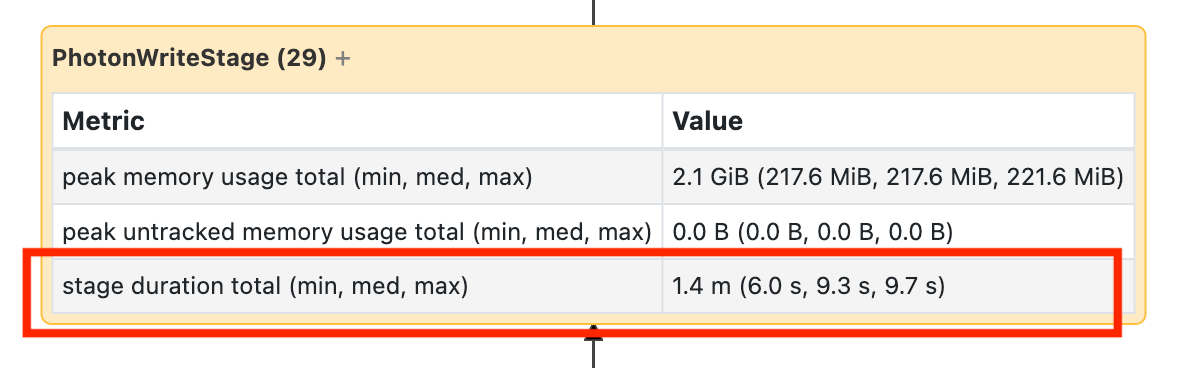
Diese Zeiten sind kumulativ, sodass es sich um die Gesamtzeit handelt, die für alle Vorgänge und nicht für die Uhr aufgewendet wurde. Aber es ist immer noch sehr nützlich, da sie mit der Uhrzeit und den Kosten korreliert sind.
Es ist hilfreich, sich mit dem Ort vertraut zu machen, an dem in der DAG die Zeit aufgewendet wird.
Lesen vieler kleiner Dateien
Wenn eine Ihrer Scanoperatoren viel Zeit in Anspruch nimmt, öffnen Sie sie, und suchen Sie nach der Anzahl der gelesenen Dateien:

Wenn Sie zehntausende Dateien oder mehr lesen, liegt möglicherweise ein kleines Dateiproblem vor. Ihre Dateien sollten nicht kleiner als 8 MB sein. Das Problem mit kleinen Dateien wird meist durch die Partitionierung auf zu viele Spalten oder eine Spalte mit hoher Kardinalität verursacht.
Wenn Sie Glück haben, müssen Sie vielleicht nur OPTIMIZE ausführen. Databricks empfiehlt, dass Sie auch die predictive Optimierung aktivieren und Ihr Dateilayout überdenken.
Schreiben in viele kleine Dateien
Wenn ihr Schreibvorgang lange dauert, öffnen Sie ihn, und suchen Sie nach der Anzahl der Dateien und wie viele Daten geschrieben wurden:

Wenn Sie zehntausende Dateien oder mehr schreiben, liegt möglicherweise ein kleines Dateiproblem vor. Ihre Dateien sollten nicht kleiner als 8 MB sein. Das Problem mit kleinen Dateien wird meist durch die Partitionierung auf zu viele Spalten oder eine Spalte mit hoher Kardinalität verursacht. Sie müssen die predictive Optimierung aktivieren, Ihr Dateilayout überdenken oder optimierte Schreibvorgänge aktivieren.
Langsame UDFs
Wenn Sie wissen, dass Sie UDFs haben oder etwas ähnliches in Ihrer DAG sehen, leiden Sie möglicherweise an langsamen UDFs:

Wenn Sie glauben, dass Sie an diesem Problem leiden, versuchen Sie, Ihre UDF zu kommentieren, um zu sehen, wie sich dies auf die Geschwindigkeit Ihrer Pipeline auswirkt. Wenn die UDF tatsächlich der Ort ist, an dem die Zeit aufgewendet wird, besteht die beste Wahl darin, die UDF mithilfe systemeigener Funktionen neu zu schreiben. Wenn dies nicht möglich ist, berücksichtigen Sie die Anzahl der Aufgaben während der Ausführung Ihrer UDF. Wenn diese Zahl kleiner als die Anzahl der Kerne in Ihrem Cluster ist, verwenden Sie Ihren DataFrame repartition(), bevor Sie die UDF verwenden.
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
UDFs können auch unter Speicherproblemen leiden. Berücksichtigen Sie, dass jede Aufgabe möglicherweise alle Daten in ihrer Partition in den Arbeitsspeicher laden muss. Wenn diese Daten zu groß sind, können die Dinge sehr langsam oder instabil werden. Die Neupartition kann dieses Problem auch beheben, indem jede Aufgabe kleiner wird.
Kartesische Verknüpfung
Wenn Sie eine kartesische Verknüpfung oder verschachtelte Schleifenverknüpfung in Ihrem DAG sehen, sollten Sie wissen, dass diese Verknüpfungen sehr teuer sind. Stellen Sie sicher, dass Sie dies beabsichtigt haben, und überprüfen Sie, ob es eine andere Möglichkeit gibt.
Explodierende Verknüpfung oder Explosion
Wenn einige Zeilen in einen Knoten hineingehen und wesentlich mehr herauskommen, kann eine explodierende Verknüpfung oder explode() vorliegen:

Weitere Informationen über explodierende Verknüpfungen finden Sie im Leitfaden zur Databricks-Optimierung.