Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook, Architecting Cloud Native .NET Applications for Azure, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Die Vorteile der Zwischenspeicherung sind gut verstanden. Die Technik funktioniert, indem häufig verwendete Daten vorübergehend aus einem Back-End-Datenspeicher in schnellen Speicher kopiert werden, der sich näher an der Anwendung befindet. Zwischenspeichern wird häufig implementiert, wo...
- Daten bleiben relativ statisch.
- Der Datenzugriff ist langsam, insbesondere im Vergleich zur Geschwindigkeit des Caches.
- Die Daten unterliegen einem hohen Maß an Anstritt.
Warum?
Wie in der Microsoft-Zwischenspeicherungsanleitung erläutert, kann die Zwischenspeicherung die Leistung, Skalierbarkeit und Verfügbarkeit einzelner Microservices und des Systems insgesamt erhöhen. Dadurch werden die Latenz und die Konflikte bei der Bearbeitung großer Mengen gleichzeitiger Anfragen an einen Datenspeicher reduziert. Da sich das Datenvolumen und die Anzahl der Benutzer erhöhen, desto größer werden die Vorteile der Zwischenspeicherung.
Die Zwischenspeicherung ist am effektivsten, wenn ein Client Daten wiederholt liest, die unveränderlich sind oder sich selten ändern. Beispiele sind Referenzinformationen wie Produkt- und Preisinformationen oder gemeinsam genutzte statische Ressourcen, deren Erstellung kostspielig ist.
Während Microservices zustandslos sein sollten, kann ein verteilter Cache gleichzeitigen Zugriff auf Sitzungszustandsdaten unterstützen, wenn dies unbedingt erforderlich ist.
Erwägen Sie auch das Zwischenspeichern, um sich wiederholende Berechnungen zu vermeiden. Wenn ein Vorgang Daten transformiert oder eine komplizierte Berechnung durchführt, speichern Sie das Ergebnis für nachfolgende Anforderungen zwischen.
Architektur beim Zwischenspeichern
Cloud native Anwendungen implementieren in der Regel eine verteilte Cachearchitektur. Der Cache wird als cloudbasierter Sicherungsdienst gehostet, getrennt von den Microservices. Abbildung 5-15 zeigt die Architektur.
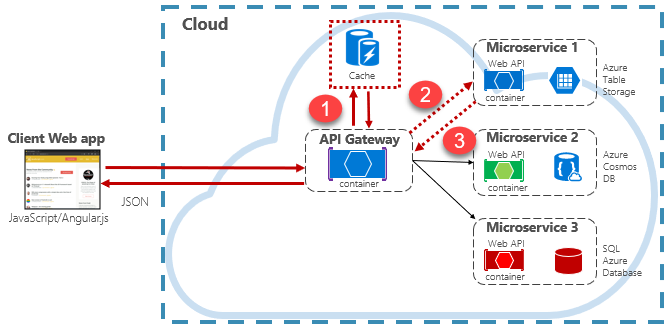
Abbildung 5-15: Zwischenspeichern in einer nativen Cloud-App
Beachten Sie in der vorherigen Abbildung, wie der Cache von den Microservices unabhängig und gemeinsam genutzt wird. In diesem Szenario wird der Cache vom API-Gateway aufgerufen. Wie in Kapitel 4 erläutert, dient das Gateway als Front-End für alle eingehenden Anforderungen. Der verteilte Cache erhöht die Reaktionsfähigkeit des Systems, indem nach Möglichkeit zwischengespeicherte Daten zurückgegeben werden. Durch die Trennung des Caches von den Diensten kann der Cache unabhängig voneinander skaliert oder verkleinert werden, um erhöhte Datenverkehrsanforderungen zu erfüllen.
Die vorherige Abbildung zeigt ein gängiges Zwischenspeicherungsmuster, das als Cache-Aside-Muster bezeichnet wird. Bei einer eingehenden Anforderung fragen Sie zuerst den Cache (Schritt 1) nach einer Antwort ab. Wenn gefunden, werden die Daten sofort zurückgegeben. Wenn die Daten nicht im Cache vorhanden sind (als Cachefehler bezeichnet), wird sie aus einer lokalen Datenbank in einem nachgeschalteten Dienst (Schritt #2) abgerufen. Anschließend wird er in den Cache für zukünftige Anforderungen (Schritt 3) geschrieben und an den Aufrufer zurückgegeben. Es muss darauf geachtet werden, in regelmäßigen Abständen zwischengespeicherte Daten zu löschen, damit das System rechtzeitig und konsistent bleibt.
Wenn ein freigegebener Cache wächst, kann es sich als vorteilhaft erweisen, seine Daten über mehrere Knoten zu partitionieren. Dies kann dazu beitragen, Konflikte zu minimieren und die Skalierbarkeit zu verbessern. Viele Cachedienste unterstützen die Möglichkeit, Knoten dynamisch hinzuzufügen und zu entfernen und Daten über Partitionen hinweg neu auszubalancieren. Bei diesem Ansatz handelt es sich in der Regel um Clustering. Durch clustering wird eine Sammlung von Verbundknoten als nahtloser einzelner Cache verfügbar gemacht. Intern werden die Daten jedoch über die Knoten verteilt, die auf eine vordefinierte Verteilungsstrategie folgen, die die Last gleichmäßig ausgleicht.
Azure Cache für Redis
Azure Cache for Redis ist ein sicherer Datenzwischenspeicherungs- und Messagingbrokerdienst, der vollständig von Microsoft verwaltet wird. Genutzt als Plattform als Dienst (PaaS)-Angebot bietet es einen hohen Durchsatz und Zugriff auf Daten mit geringer Latenz. Der Dienst ist für jede Anwendung innerhalb oder außerhalb von Azure zugänglich.
Der Azure-Cache für Redis-Dienst verwaltet den Zugriff auf Open-Source-Redis-Server, die in Azure-Rechenzentren gehostet werden. Der Dienst fungiert als Fassade, die Verwaltung, Zugriffssteuerung und Sicherheit bereitstellt. Der Dienst unterstützt nativ einen umfangreichen Satz von Datenstrukturen, einschließlich Zeichenfolgen, Hashes, Listen und Sets. Wenn Ihre Anwendung Redis bereits verwendet, funktioniert sie as-is mit Azure Cache für Redis.
Der Azure-Cache für Redis ist mehr als ein einfacher Cacheserver. Es kann eine Reihe von Szenarien unterstützen, um eine Microservices-Architektur zu verbessern:
- Ein In-Memory-Datenspeicher
- Eine verteilte nicht relationale Datenbank
- Ein Nachrichtenbroker
- Ein Konfigurations- oder Ermittlungsserver
Bei erweiterten Szenarien kann eine Kopie der zwischengespeicherten Daten auf dem Datenträger beibehalten werden. Wenn ein katastrophales Ereignis sowohl den primären als auch den Replikatcache deaktiviert, wird der Cache aus der letzten Momentaufnahme wiederhergestellt.
Azure Redis Cache ist in einer Reihe vordefinierter Konfigurationen und Preisstufen verfügbar. Die Premium-Stufe bietet viele Features auf Unternehmensebene, z. B. Clustering, Datenpersistenz, Georeplikation und Virtual-Network-Isolation.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.