Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook, Architecting Cloud Native .NET Applications for Azure, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Das Bevorzugte Mantra von Softwareberatern ist, "Es hängt von jeder Frage ab". Es liegt nicht daran, dass Softwareberater gerne keine Position einnehmen. Es liegt daran, dass es keine wahre Antwort auf Fragen in software gibt. Es gibt kein absolutes Recht und falsch, sondern ein Gleichgewicht zwischen gegensätzlich.
Nehmen wir beispielsweise die beiden Hauptschulen für die Entwicklung von Webanwendungen: Single Page Applications (SPAs) im Vergleich zu serverseitigen Anwendungen. Einerseits ist die Benutzererfahrung tendenziell besser mit SPAs, und die Menge des Datenverkehrs an den Webserver kann minimiert werden, sodass sie auf etwas einfaches wie statisches Hosting gehostet werden können. Andererseits neigen SPAs dazu, langsamer zu entwickeln und schwieriger zu testen. Welches ist die richtige Wahl? Nun, es hängt von Ihrer Situation ab.
Cloud-native Anwendungen sind nicht immun gegen dieselbe Dichotomie. Sie haben klare Vorteile hinsichtlich der Geschwindigkeit der Entwicklung, Stabilität und Skalierbarkeit, aber die Verwaltung kann ziemlich schwierig sein.
Vor einigen Jahren war es nicht ungewöhnlich, dass der Prozess, eine Anwendung von der Entwicklung in die Produktionsumgebung zu verschieben, einen Monat oder noch mehr in Anspruch nehmen konnte. Unternehmen haben Software im 6-Monats-Rhythmus oder sogar jährlich veröffentlicht. Sie brauchen nur einen Blick auf Microsoft Windows zu werfen, um eine Vorstellung von dem Rhythmus der Veröffentlichungen zu bekommen, die vor den Tagen von Windows 10 als akzeptabel galten. Fünf Jahre zwischen Windows XP und Vista bestanden, eine weitere drei zwischen Vista und Windows 7.
Es ist jetzt weitgehend anerkannt, dass die Möglichkeit, Software schnell freizugeben, schnellen Unternehmen einen riesigen Marktvorteil gegenüber ihren trägen Wettbewerbern bietet. Aus diesem Grund sind wichtige Updates für Windows 10 jetzt ungefähr alle sechs Monate.
Die Muster und Praktiken, die schnellere, zuverlässigere Versionen ermöglichen, um Wert für das Unternehmen zu liefern, werden gemeinsam als DevOps bezeichnet. Sie bestehen aus einer breiten Palette von Ideen, die den gesamten Lebenszyklus der Softwareentwicklung umfassen, von der Angabe einer Anwendung bis hin zur Bereitstellung und Bedienung dieser Anwendung.
DevOps ist vor Microservices entstanden, und es ist wahrscheinlich, dass die Bewegung in Richtung kleinerer, besser geeigneter Dienste nicht möglich wäre, ohne DevOps die Veröffentlichung und Bedienung nicht nur einer, sondern viele Anwendungen in der Produktion zu vereinfachen.
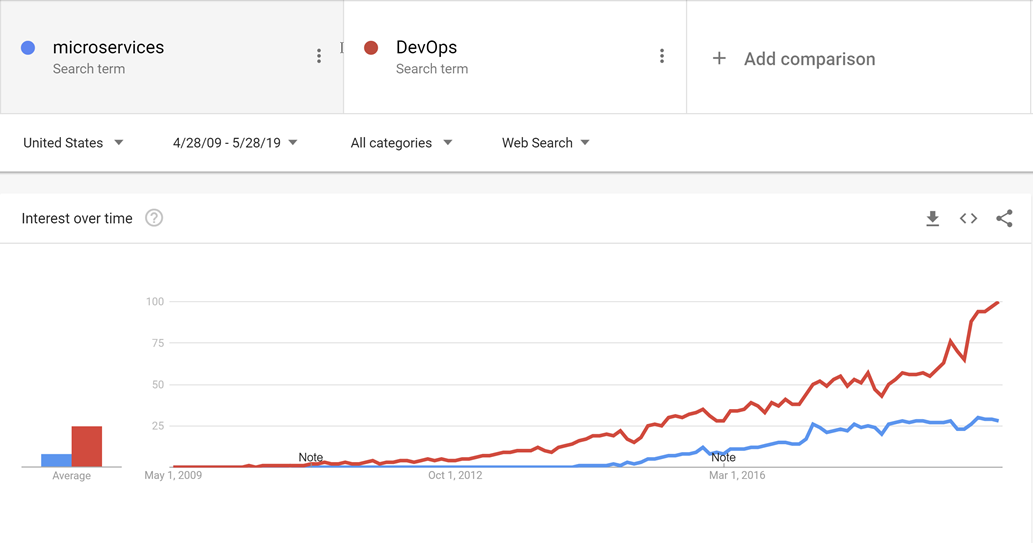
Abbildung 10-1 – DevOps und Microservices.
Durch gute DevOps-Praktiken ist es möglich, die Vorteile von Cloud-nativen Anwendungen zu nutzen, ohne unter einem Berg der Arbeit zu ersticken, die benötigt wird, um die Anwendungen tatsächlich zu betreiben.
Es gibt keinen goldenen Hammer, wenn es um DevOps geht. Niemand kann eine komplette und umfassende Lösung für die Veröffentlichung und den Betrieb hochwertiger Anwendungen verkaufen. Dies liegt daran, dass sich jede Anwendung von allen anderen stark unterscheidet. Es gibt jedoch Tools, die DevOps zu einem viel weniger entmutigenden Vorschlag machen können. Eines dieser Tools wird als Azure DevOps bezeichnet.
Azure DevOps
Azure DevOps verfügt über eine lange Tradition. Es kann seine Wurzeln bis zu der Zeit zurückverfolgen, als Team Foundation Server zum ersten Mal online ging und durch die verschiedenen Namensänderungen: Visual Studio Online und Visual Studio Team Services. In den Jahren ist es jedoch weit mehr geworden als seine Vorgänger.
Azure DevOps ist in fünf Hauptkomponenten unterteilt:

Abbildung 10-2 – Azure DevOps.
Azure Repos – Quellcodeverwaltung, die die würdige Team Foundation Version Control (TFVC) und die branchenfavoriten Git unterstützt. Pull-Anforderungen bieten eine Möglichkeit, soziale Codierung zu ermöglichen, indem sie die Diskussion über Änderungen fördern, während sie vorgenommen werden.
Azure Boards – Stellt ein Tool zur Problem- und Aufgabenverfolgung bereit, mit dem Benutzer die Workflows auswählen können, die für sie am besten geeignet sind. Es enthält eine Reihe von vorkonfigurierten Vorlagen, einschließlich derer, die SCRUM- und Kanban-Stile der Entwicklung unterstützen.
Azure Pipelines – Ein Build- und Releaseverwaltungssystem, das eine enge Integration in Azure unterstützt. Builds können auf verschiedenen Plattformen von Windows bis Linux auf macOS ausgeführt werden. Build-Agents können in der Cloud oder lokal bereitgestellt werden.
Azure Testpläne – Keine QA-Person wird mit der Testverwaltungs- und explorativen Testunterstützung des Features "Testpläne" hinter sich gelassen.
Azure Artifacts – Ein Artefaktfeed, mit dem Unternehmen eigene, interne Versionen von NuGet, npm und anderen erstellen können. Es dient einem doppelten Zweck, als Cache von Upstreampaketen zu fungieren, wenn ein Fehler eines zentralisierten Repositorys auftritt.
Die Organisationseinheit auf oberster Ebene in Azure DevOps wird als Projekt bezeichnet. Innerhalb jedes Projekts können die verschiedenen Komponenten, z. B. Azure Artifacts, aktiviert und deaktiviert werden. Jede dieser Komponenten bietet unterschiedliche Vorteile für cloudeigene Anwendungen. Die drei nützlichsten sind Repositorys, Boards und Pipelines. Wenn Benutzer ihren Quellcode in einem anderen Repositorystapel wie GitHub verwalten möchten, aber dennoch Azure-Pipelines und andere Komponenten nutzen möchten, ist dies perfekt möglich.
Glücklicherweise haben Entwicklungsteams beim Auswählen eines Repositorys viele Optionen. Einer davon ist GitHub.
GitHub-Aktionen
GitHub wurde 2009 gegründet und ist ein beliebtes webbasiertes Repository zum Hosten von Projekten, Dokumentationen und Code. Viele große Tech-Unternehmen wie Apple, Amazon, Google und Mainstream-Unternehmen nutzen GitHub. GitHub verwendet das Open-Source-System für verteilte Versionsverwaltung namens Git als Grundlage. Darüber hinaus fügt sie einen eigenen Satz von Features hinzu, einschließlich Fehlerverfolgung, Feature- und Pullanforderungen, Aufgabenverwaltung und Wikis für jede Codebasis.
Da sich GitHub weiterentwickelt, fügt es auch DevOps-Features hinzu. Beispielsweise verfügt GitHub über eine eigene kontinuierliche Integrations-/Lieferpipeline (CI/CD), die GitHub Actions genannt wird. GitHub Actions ist ein communitygestütztes Workflowautomatisierungstool. Es ermöglicht DevOps-Teams die Integration mit ihren vorhandenen Tools, neue Produkte zu kombinieren und in den Software-Lebenszyklus zu integrieren, einschließlich vorhandener CI/CD-Partner.
GitHub hat über 40 Millionen Benutzer und ist damit der größte Host für Quellcode weltweit. Im Oktober 2018 kaufte Microsoft GitHub. Microsoft hat versprochen, dass GitHub eine offene Plattform bleibt, die jeder Entwickler anschließen und erweitern kann. Sie ist weiterhin als unabhängiges Unternehmen tätig. GitHub bietet Pläne für Unternehmens-, Team-, Professionelle- und kostenlose Konten.
Quellcodeverwaltung
Das Organisieren des Codes für eine cloudeigene Anwendung kann eine Herausforderung darstellen. Anstelle einer einzigen riesigen Anwendung bilden die cloudeigenen Anwendungen tendenziell ein Web mit kleineren Anwendungen, die miteinander sprechen. Wie bei der Berechnung bleibt die beste Codeanordnung eine offene Frage. Es gibt Beispiele für erfolgreiche Anwendungen mit verschiedenen Arten von Layouts, aber zwei Varianten scheinen die größte Beliebtheit zu haben.
Bevor Sie sich mit der eigentlichen Quellcodeverwaltung selbst beschäftigen, lohnt es sich wahrscheinlich, zu entscheiden, wie viele Projekte angemessen sind. Innerhalb eines einzelnen Projekts gibt es Unterstützung für mehrere Repositorys und Buildpipelines. Boards sind etwas komplexer, aber auch dort können die Aufgaben einfach mehreren Teams innerhalb eines einzigen Projekts zugewiesen werden. Es ist möglich, Hunderte, sogar Tausende von Entwicklern, aus einem einzigen Azure DevOps-Projekt zu unterstützen. Dies ist wahrscheinlich der beste Ansatz, da er einen einzigen Ort für alle Entwickler schafft, von dem aus sie arbeiten können. Außerdem wird die Verwirrung reduziert, die entsteht, wenn Entwickler unsicher sind, in welchem Projekt sich eine Anwendung befindet.
Das Aufteilen von Code für Microservices innerhalb des Azure DevOps-Projekts kann etwas schwieriger sein.
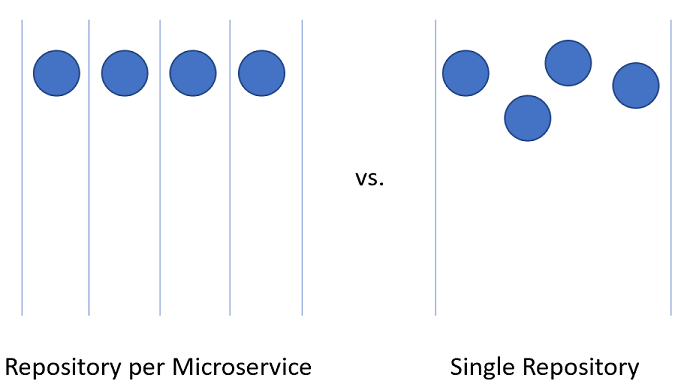
Abbildung 10-3 – Eins im Vergleich zu vielen Repositorys.
Repository pro Microservice
Auf den ersten Blick scheint dieser Ansatz der logischeste Ansatz, den Quellcode für Microservices aufzuteilen. Jedes Repository kann den Code enthalten, der zum Erstellen des einen Microservice benötigt wird. Die Vorteile dieses Ansatzes sind leicht sichtbar:
- Anweisungen zum Erstellen und Verwalten der Anwendung können einer README-Datei am Stamm jedes Repositorys hinzugefügt werden. Beim Durchblättern der Repositorys ist es einfach, diese Anweisungen zu finden, wodurch die Einarbeitungszeit für Entwickler verkürzt wird.
- Jeder Dienst befindet sich an einem logischen Ort, leicht zu finden, wenn man den Namen des Dienstes kennt.
- Builds können ganz einfach so eingerichtet werden, dass sie nur ausgelöst werden, wenn eine Änderung am eigenen Repository vorgenommen wird.
- Die Anzahl der Änderungen, die in ein Repository eingehen, ist auf die geringe Anzahl von Entwicklern beschränkt, die am Projekt arbeiten.
- Die Sicherheit ist einfach einzurichten, indem die Repositorys eingeschränkt werden, für die Entwickler Lese- und Schreibberechtigungen besitzen.
- Die Einstellungen auf Repositoryebene können von dem Team, das das Repository besitzt, mit einem Minimum an Diskussion mit anderen geändert werden.
Einer der wichtigsten Ideen hinter Microservices besteht darin, dass Dienste isoliert und voneinander getrennt werden sollten. Wenn Sie domänengesteuertes Design verwenden, um die Grenzen für Dienste zu bestimmen, fungieren die Dienste als Transaktionsgrenzen. Datenbankupdates sollten sich nicht über mehrere Dienste erstrecken. Diese Sammlung verwandter Daten wird als gebundener Kontext bezeichnet. Diese Idee spiegelt sich durch die Isolierung von Microservice-Daten in eine Datenbank wider, die von den restlichen Diensten getrennt und autonom ist. Es ist sehr sinnvoll, diese Idee bis in den Quellcode zu tragen.
Dieser Ansatz ist jedoch nicht ohne probleme. Eines der gnarren Entwicklungsprobleme unserer Zeit ist die Verwaltung von Abhängigkeiten. Berücksichtigen Sie die Anzahl der Dateien, aus denen das durchschnittliche node_modules Verzeichnis besteht. Eine frische Installation von etwas wie create-react-app wird wahrscheinlich Tausende von Paketen enthalten. Die Frage, wie diese Abhängigkeiten verwaltet werden, ist schwierig.
Wenn eine Abhängigkeit aktualisiert wird, müssen nachgeschaltete Pakete diese Abhängigkeit ebenfalls aktualisieren. Leider erfordert das Entwicklungsarbeit und so kommt es unvermeidlich dazu, dass das node_modules-Verzeichnis mit mehreren Versionen eines einzigen Pakets endet; jede Version ist eine Abhängigkeit eines anderen Pakets, das in einem etwas anderen Rhythmus versioniert wird. Welche Version einer Abhängigkeit sollte beim Bereitstellen einer Anwendung verwendet werden? Die Version, die sich derzeit in der Produktion befindet? Die Version, die sich derzeit in der Beta-Phase befindet, aber wahrscheinlich in der Produktion sein wird, wenn der Consumer es in die Produktion schafft? Schwierige Probleme, die nicht nur mithilfe von Microservices behoben werden.
Es gibt Bibliotheken, die von einer Vielzahl von Projekten abhängig sind. Durch die Aufteilung der Microservices auf eins in jedem Repository können die internen Abhängigkeiten am besten mithilfe des internen Repositorys, Azure Artifacts, aufgelöst werden. Bei der Erstellung von Bibliotheken werden die neuesten Versionen in Azure Artifacts für den internen Gebrauch bereitgestellt. Das nachgelagerte Projekt muss weiterhin manuell aktualisiert werden, um eine Abhängigkeit von den neu aktualisierten Paketen zu erhalten.
Ein weiterer Nachteil stellt sich beim Verschieben von Code zwischen Diensten dar. Obwohl es schön wäre zu glauben, dass die erste Aufteilung einer Anwendung in Microservices zu 100 % korrekt ist, entspricht es eher der Realität, dass wir selten so vorausschauend sind, dass wir keine Fehler bei der Aufteilung von Diensten machen. Daher müssen die Funktionalität und der sie steuernde Code von Dienst zu Dienst und von Repository zu Repository wechseln. Beim Springen von einem Repository zu einem anderen verliert der Code seine Historie. Es gibt viele Fälle, insbesondere im Falle einer Prüfung, in denen ein vollständiger Verlauf eines Codes von unschätzbarem Wert ist.
Der letzte und wichtigste Nachteil ist die Koordinierung von Änderungen. In einer echten Microservices-Anwendung sollten keine Bereitstellungsabhängigkeiten zwischen Diensten vorhanden sein. Es sollte möglich sein, die Dienste A, B und C in jeder Reihenfolge bereitzustellen, da sie eine lose Kopplung haben. In der Realität gibt es jedoch Zeiten, in denen es wünschenswert ist, eine Änderung vorzunehmen, die mehrere Repositorys gleichzeitig durchquert. Einige Beispiele sind das Aktualisieren einer Bibliothek, um ein Sicherheitsloch zu schließen oder ein kommunikationsprotokoll zu ändern, das von allen Diensten verwendet wird.
Um eine repositoryübergreifende Änderung vorzunehmen, müssen Sie nacheinander einen Commit für jedes Repository vornehmen. Jede Änderung in jedem Repository muss als Pull-Request eingereicht und separat überprüft werden. Diese Aktivität kann schwierig zu koordinieren sein.
Eine Alternative zur Verwendung vieler Repositorys besteht darin, den gesamten Quellcode in einem riesigen, wissenden, einzigen Repository zusammenzustellen.
Einzelnes Repository
Bei diesem Ansatz, der manchmal als Monorepository bezeichnet wird, wird der gesamte Quellcode für jeden Dienst in dasselbe Repository eingefügt. Zunächst scheint dieser Ansatz eine schreckliche Idee zu sein, die den Umgang mit Quellcode unübersichtlich macht. Es gibt jedoch einige deutliche Vorteile, auf diese Weise zu arbeiten.
Der erste Vorteil besteht darin, dass es einfacher ist, Abhängigkeiten zwischen Projekten zu verwalten. Anstatt sich auf einen externen Artefaktfeed zu verlassen, können Projekte direkt einen anderen importieren. Dies bedeutet, dass Updates sofort durchgeführt werden und widersprüchliche Versionen wahrscheinlich zur Kompilierungszeit auf der Arbeitsstation des Entwicklers auftreten. Dadurch wird ein Teil der Integrationstests nach links verlagert.
Beim Verschieben von Code zwischen Projekten ist es jetzt einfacher, den Verlauf beizubehalten, da die Dateien erkannt werden, dass sie verschoben wurden, anstatt neu zu schreiben.
Ein weiterer Vorteil ist, dass breite Änderungen, die Dienstgrenzen überschreiten, in einem einzigen Commit vorgenommen werden können. Diese Aktivität reduziert den Aufwand, der entsteht, wenn Sie Dutzende von Änderungen einzeln überprüfen müssen.
Es gibt viele Tools, mit denen statische Codeanalysen durchgeführt werden können, um unsichere Programmierpraktiken oder problematische Verwendung von APIs zu erkennen. In einer Welt mit mehreren Repositorys muss jedes Repository durchlaufen werden, um die Probleme in ihnen zu finden. Das einzelne Repository ermöglicht das Ausführen der Analyse an einer zentralen Stelle.
Es gibt auch viele Nachteile für den Ansatz einzelner Repositorys. Einer der beunruhigendsten ist, dass ein einzelnes Repository Sicherheitsbedenken auslöst. Wenn der Inhalt eines Repositorys in einem Einzelrepository-Dienstmodell durchgesickert ist, ist die Menge des verloren gegangenen Codes minimal. Mit einem einzigen Repository könnte alles, was das Unternehmen besitzt, verlorengehen. Es gibt in der Vergangenheit viele Beispiele dafür, dass dies geschehen ist und ganze Spielentwicklungsprojekte zum Scheitern gebracht hat. Wenn mehrere Repositorys weniger Fläche verfügbar machen, ist dies eine wünschenswerte Eigenschaft in den meisten Sicherheitspraktiken.
Die Größe des einzelnen Repositorys wird wahrscheinlich schnell nicht mehr verwaltbar. Dies stellt einige interessante Leistungsauswirkungen dar. Es kann notwendig werden, spezielle Tools wie das virtuelle Dateisystem für Git zu verwenden, das ursprünglich entwickelt wurde, um die Erfahrung für Entwickler im Windows-Team zu verbessern.
Häufig beschränkt sich das Argument für die Verwendung eines einzelnen Repositorys darauf, dass Facebook oder Google dieses Verfahren zur Organisation des Quellcodes verwenden. Wenn der Ansatz für diese Unternehmen gut genug ist, dann ist es sicher der richtige Ansatz für alle Unternehmen. Die Wahrheit der Sache ist, dass nur wenige Unternehmen auf etwas wie der Maßstab von Facebook oder Google arbeiten. Die Probleme, die in diesen Skalierungen auftreten, unterscheiden sich von denen, denen die meisten Entwickler begegnen. Was für die Ziegen gut ist, kann für den Gander nicht gut sein.
Am Ende kann eine der beiden Lösungen verwendet werden, um den Quellcode für Microservices zu hosten. Doch in den meisten Fällen überwiegen die geringen Vorteile nicht den Verwaltungs- und Engineering-Aufwand beim Betreiben in einem einzigen Repository. Das Aufteilen von Code über mehrere Repositorys fördert eine bessere Trennung von Bedenken und fördert die Autonomie zwischen Entwicklungsteams.
Standardverzeichnisstruktur
Trotz der Diskussion über einzelnes gegen mehrere Repositorys wird jeder Dienst über ein eigenes Verzeichnis verfügen. Eine der besten Optimierungen, mit denen Entwickler schnell zwischen Projekten wechseln können, besteht darin, eine Standardverzeichnisstruktur beizubehalten.
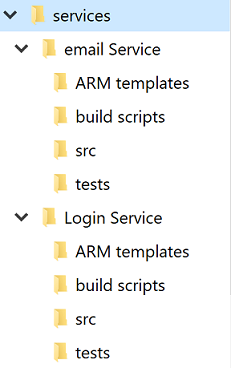
Abbildung 10-4 – Standardverzeichnisstruktur.
Immer wenn ein neues Projekt erstellt wird, sollte eine Vorlage verwendet werden, die die richtige Struktur einfügt. Diese Vorlage kann auch nützliche Elemente wie eine README-Datei mit Grundstruktur und ein azure-pipelines.yml enthalten. In jeder Mikroservice-Architektur erschwert ein hoher Grad an Varianz zwischen Projekten Massenvorgänge in Bezug auf die Dienste.
Es gibt viele Tools, die Vorlagen für ein gesamtes Verzeichnis bereitstellen können, das mehrere Quellcodeverzeichnisse enthält. Yeoman ist in der JavaScript-Welt beliebt und GitHub hat kürzlich Repositoryvorlagen veröffentlicht, die einen Großteil der gleichen Funktionalität bieten.
Aufgabenverwaltung
Das Verwalten von Vorgängen in jedem Projekt kann schwierig sein. Im Vorfeld gibt es unzählige Fragen zu den Workflows, die eingerichtet werden sollen, um die optimale Produktivität der Entwickler zu gewährleisten.
Cloudnative Anwendungen sind tendenziell kleiner als herkömmliche Softwareprodukte oder zumindest in kleinere Dienste unterteilt. Das Nachverfolgen von Problemen oder Aufgaben im Zusammenhang mit diesen Diensten bleibt ebenso wichtig wie bei jedem anderen Softwareprojekt. Niemand möchte den Überblick über eine Bestimmte Arbeitsaufgabe verlieren oder einem Kunden erklären, dass sein Problem nicht ordnungsgemäß protokolliert wurde. Boards werden auf Projektebene konfiguriert, aber innerhalb jedes Projekts können Bereiche definiert werden. Diese ermöglichen das Aufteilen von Problemen in mehreren Komponenten. Der Vorteil, alle Arbeiten für die gesamte Anwendung an einem Ort zu halten, besteht darin, dass arbeitsaufgaben einfach von einem Team in ein anderes verschoben werden können, da sie besser verstanden werden.
Azure DevOps verfügt über eine Reihe beliebter Vorlagen, die bereits konfiguriert sind. In der einfachsten Konfiguration müssen Sie lediglich wissen, was sich im Backlog befindet, woran die Personen arbeiten und was abgeschlossen ist. Es ist wichtig, diesen Einblick in den Prozess der Erstellung von Software zu erhalten, damit Die Arbeit priorisiert und erledigte Aufgaben an den Kunden gemeldet werden kann. Natürlich halten sich nur wenige Softwareprojekte an einen so einfachen Prozess wie to do, doing und done. Es dauert nicht lange, bis Personen mit dem Hinzufügen von Schritten wie QA oder Detailed Specification dem Prozess beginnen.
Einer der wichtigsten Teile der Agile-Methoden ist die Selbstintrospektion in regelmäßigen Abständen. Diese Bewertungen sollen Einblicke in die Probleme liefern, mit denen das Team konfrontiert ist und wie sie verbessert werden können. Dies bedeutet häufig, den Ablauf von Problemen und Features durch den Entwicklungsprozess zu ändern. Es ist also völlig in Ordnung, die Layouts der Boards mit zusätzlichen Stages zu erweitern.
Die Phasen in den Boards sind nicht das einzige Organisationstool. Je nach Konfiguration des Boards gibt es eine Hierarchie von Arbeitsaufgaben. Das präziseste Element, das auf einer Tafel angezeigt werden kann, ist eine Aufgabe. Standardmäßig enthält eine Aufgabe Felder für einen Titel, eine Beschreibung, eine Priorität, eine Schätzung des verbleibenden Arbeitsaufwands und die Möglichkeit, eine Verknüpfung mit anderen Arbeitsaufgaben oder Entwicklungselementen (Branches, Commits, Pull-Anforderungen, Builds usw.) zu erstellen. Arbeitsaufgaben können in verschiedene Bereiche der Anwendung und unterschiedliche Iterationen (Sprints) unterteilt werden, um die Suche zu vereinfachen.
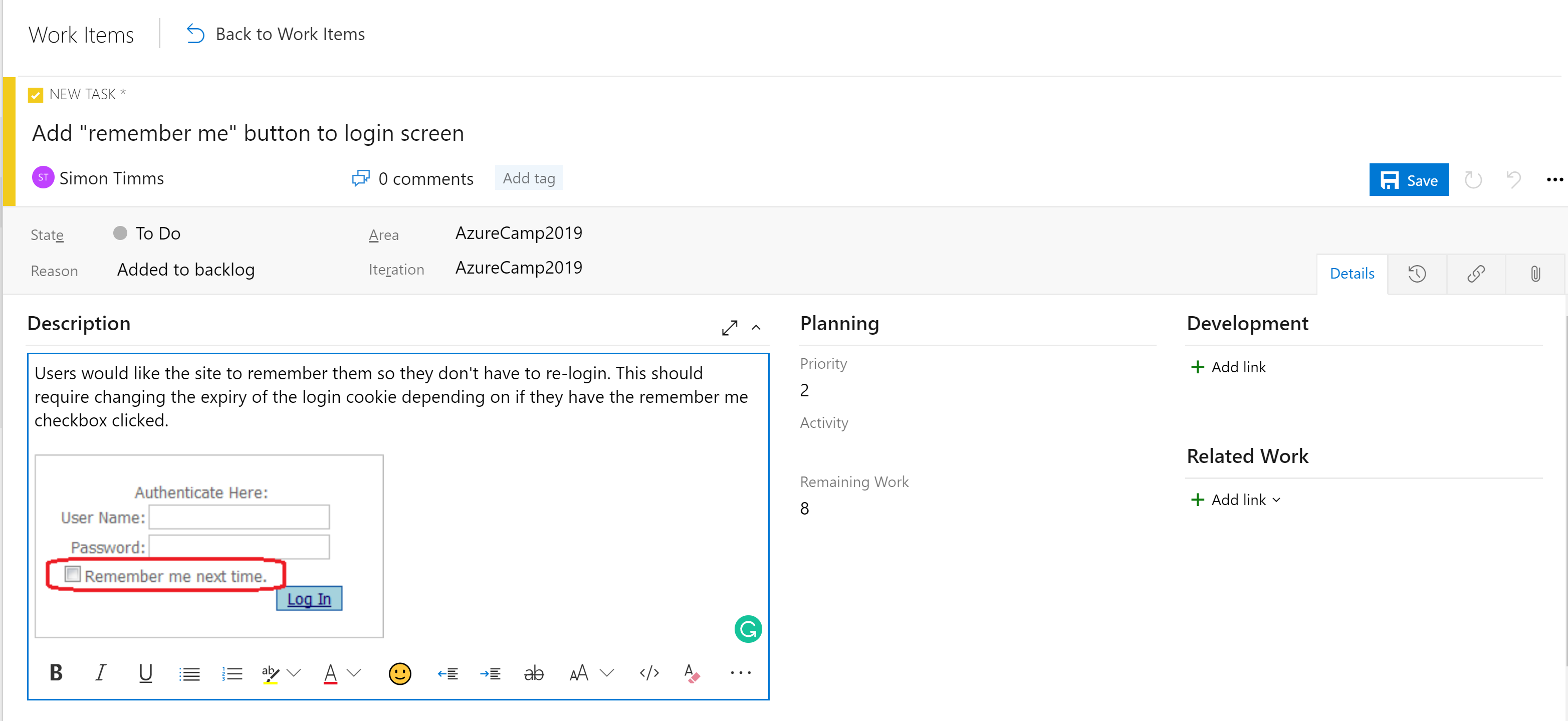
Abbildung 10-5 – Aufgabe in Azure DevOps.
Das Beschreibungsfeld unterstützt die normalen Formatvorlagen, die Sie erwarten (fett, kursiv, unterstrichen und durchgestrichen) und die Möglichkeit zum Einfügen von Bildern. Dadurch wird es zu einem leistungsfähigen Tool für die Verwendung bei der Angabe von Arbeit oder Fehlern.
Aufgaben können in Features eingerollt werden, die eine größere Arbeitseinheit definieren. Features können wiederum in Epen zusammengefasst werden. Durch die Klassifizierung von Aufgaben in dieser Hierarchie wird es viel einfacher zu verstehen, wie nah eine große Funktion an ihrer Einführung ist.

Abbildung 10-6 – Arbeitselement in Azure DevOps.
Es gibt verschiedene Arten von Ansichten zu den Problemen in Azure Boards. Elemente, die noch nicht geplant sind, werden im Backlog angezeigt. Von dort aus können sie einem Sprint zugewiesen werden. Ein Sprint ist ein Zeitraum, in dem erwartet wird, dass eine bestimmte Menge an Arbeit abgeschlossen wird. Diese Arbeit kann Aufgaben, aber auch die Lösung von Tickets umfassen. Dort können Sie den gesamten Sprint über den Abschnitt „Sprint-Board“ verwalten. In dieser Ansicht wird gezeigt, wie die Arbeit voranschreitet, und ein Burn-down-Diagramm ist enthalten, um eine fortlaufend aktualisierte Schätzung abzugeben, ob der Sprint erfolgreich sein wird.

Abbildung 10-7 – Board in Azure DevOps.
Mittlerweile sollte deutlich sein, dass es in den Boards in Azure DevOps eine große Macht gibt. Für Entwickler gibt es benutzerfreundliche Ansichten darüber, woran gearbeitet wird. Für Projektmanager gibt es Ansichten zu anstehenden Arbeiten sowie eine Übersicht über die bestehenden Arbeiten. Für Manager gibt es viele Berichte über Resourcing und Kapazität. Leider gibt es nichts Magisches über cloudeigene Anwendungen, die die Notwendigkeit beseitigen, Arbeit nachzuverfolgen. Wenn Sie die Arbeit jedoch nachverfolgen müssen, gibt es ein paar Orte, an denen die Erfahrung besser ist als in Azure DevOps.
CI/CD-Pipelines
Fast keine Veränderung des Lebenszyklus der Softwareentwicklung war so revolutionär wie das Aufkommen der kontinuierlichen Integration (CI) und der kontinuierlichen Lieferung (CD). Das Erstellen und Ausführen automatisierter Tests mit dem Quellcode eines Projekts, sobald eine Änderung frühzeitig eingecheckt wird, fängt Fehler auf. Vor dem Aufkommen kontinuierlicher Integrationsbuilds wäre es nicht ungewöhnlich, Code aus dem Repository abzurufen und zu finden, dass es keine Tests bestanden hat oder nicht einmal erstellt werden konnte. Dies führte dazu, die Quelle des Bruchs nachzuverfolgen.
Herkömmliches Versenden von Software an die Produktionsumgebung erforderte umfangreiche Dokumentation und eine Liste der Schritte. Jeder dieser Schritte muss in einem sehr fehleranfälligen Prozess manuell ausgeführt werden.

Abbildung 10-8 – Checkliste.
Das Pendant zu Continuous Integration ist Continuous Delivery, bei dem die kürzlich erstellten Pakete in einer Umgebung bereitgestellt werden. Der manuelle Prozess kann nicht an die Geschwindigkeit der Entwicklung angepasst werden, sodass die Automatisierung wichtiger wird. Checklisten werden durch Skripts ersetzt, die dieselben Aufgaben schneller und genauer ausführen können als jeder Mensch.
Die Umgebung, in der die kontinuierliche Lieferung geliefert wird, kann eine Testumgebung sein oder, wie es von vielen großen Technologieunternehmen getan wird, die Produktionsumgebung sein. Letzteres erfordert eine Investition in qualitativ hochwertige Tests, die das Vertrauen geben können, dass eine Änderung den Produktivbetrieb für die Benutzer nicht beeinträchtigt. Genauso wie Continuous Integration Probleme im Code frühzeitig abfängt, fängt Continuous Delivery Probleme bei der Bereitstellung frühzeitig ab.
Die Bedeutung der Automatisierung des Build- und Übermittlungsprozesses wird durch cloudeigene Anwendungen hervorgehoben. Bereitstellungen erfolgen häufiger und werden auf mehr Umgebungen ausgedehnt, sodass eine manuelle Bereitstellung nahezu unmöglich ist.
Azure-Builds
Azure DevOps bietet eine Reihe von Tools, um eine kontinuierliche Integration und Bereitstellung einfacher als je zuvor zu machen. Diese Tools befinden sich unter Azure Pipelines. Die erste von ihnen ist Azure Builds, ein Tool zum Ausführen von YAML-basierten Builddefinitionen in großem Umfang. Benutzer können entweder eigene Buildcomputer mitbringen (ideal für den Bedarf einer sorgfältig eingerichteten Umgebung) oder einen Computer aus einem ständig aktualisierten Pool von von Azure gehosteten virtuellen Computern verwenden. Diese gehosteten Build-Agents sind vorinstalliert mit einer breiten Palette von Entwicklungstools für nicht nur .NET-Entwicklung, sondern für alles von Java bis Python bis zur iPhone-Entwicklung.
DevOps enthält eine vielzahl von sofort einsatzbereiten Builddefinitionen, die für jeden Build angepasst werden können. Die Builddefinitionen sind in einer Datei mit dem Namen `azure-pipelines.yml` definiert und werden in das Repository eingecheckt, damit sie zusammen mit dem Quellcode versioniert werden können. Dadurch wird es viel einfacher, Änderungen an der Buildpipeline in einem Branch vorzunehmen, da die Änderungen nur in diesen Branch eingecheckt werden können. Ein Beispiel azure-pipelines.yml zum Erstellen einer ASP.NET-Webanwendung im vollständigen Framework ist in Abbildung 10-9 dargestellt.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Abbildung 10-9 – Beispiel azure-pipelines.yml
Diese Builddefinition verwendet eine Reihe von integrierten Aufgaben, die das Erstellen von Builds so einfach wie das Erstellen eines Lego-Satzes (einfacher als der riesige Millennium Falcon) machen. Beispielsweise stellt die NuGet-Aufgabe NuGet-Pakete wieder her, während die VSBuild-Aufgabe die Visual Studio-Buildtools aufruft, um die eigentliche Kompilierung auszuführen. In Azure DevOps stehen Hunderte von verschiedenen Aufgaben zur Verfügung, mit Tausenden mehr, die von der Community verwaltet werden. Es ist wahrscheinlich, dass unabhängig davon, welche Build-Aufgaben Sie ausführen möchten, jemand bereits eine erstellt hat.
Builds können manuell, durch ein Check-in, durch einen Zeitplan oder durch den Abschluss eines anderen Builds ausgelöst werden. In den meisten Fällen ist die Erstellung bei jedem Einchecken wünschenswert. Builds können so gefiltert werden, dass verschiedene Builds für verschiedene Teile der Repositories oder für unterschiedliche Branches ausgeführt werden. Dies ermöglicht Szenarien wie das Ausführen von schnellen Builds mit reduzierten Tests bei Pull Requests und das nächtliche Ausführen einer vollständigen Regressionssammlung für den Trunk.
Das Endergebnis eines Builds ist eine Sammlung von Dateien, die als Buildartefakte bezeichnet werden. Diese Artefakte können an den nächsten Schritt im Buildprozess übergeben oder einem Azure Artifacts-Feed hinzugefügt werden, damit sie von anderen Builds genutzt werden können.
Azure DevOps-Veröffentlichungen
Builds kümmern sich um das Kompilieren der Software in ein versandfähiges Paket, aber die Artefakte müssen weiterhin an eine Testumgebung übertragen werden, um die kontinuierliche Lieferung abzuschließen. Dazu verwendet Azure DevOps ein separates Tool namens "Releases". Das Tool "Releases" verwendet dieselbe Aufgabenbibliothek, die für den Build verfügbar war, führt aber ein Konzept der "Phasen" ein. Eine Phase ist eine isolierte Umgebung, in der das Paket installiert ist. Beispielsweise kann ein Produkt eine Entwicklung, eine QA und eine Produktionsumgebung verwenden. Code wird kontinuierlich in die Entwicklungsumgebung übermittelt, in der automatisierte Tests ausgeführt werden können. Sobald diese Tests bestanden sind, wird das Release für manuelle Tests in die QA-Umgebung weitergeleitet. Schließlich wird der Code an die Produktion verschoben, wo er für alle sichtbar ist.

Abbildung 10-10 – Release-Pipeline
Jede Phase im Build kann automatisch durch den Abschluss der vorherigen Phase ausgelöst werden. In vielen Fällen ist dies jedoch nicht wünschenswert. Das Verschieben von Code in die Produktion erfordert möglicherweise eine Genehmigung von jemandem. Das Release-Tool unterstützt dies, indem es Genehmiger in jedem Schritt der Release-Pipeline zulässt. Regeln können so eingerichtet werden, dass eine bestimmte Person oder Gruppe von Personen einer Freigabe zustimmen muss, bevor sie in die Produktion geht. Diese Tore ermöglichen manuelle Qualitätsprüfungen und auch die Einhaltung gesetzlicher Vorschriften im Zusammenhang mit der Kontrolle, was in die Produktion geht.
Jeder erhält eine Buildpipeline
Es gibt keine Kosten für die Konfiguration vieler Buildpipelines, daher ist es vorteilhaft, mindestens eine Buildpipeline pro Microservice zu haben. Im Idealfall können Microservices unabhängig für jede Umgebung bereitgestellt werden, sodass jeder über seine eigene Pipeline freigegeben werden kann, ohne eine Masse von nicht verknüpftem Code freizugeben, perfekt ist. Jede Pipeline kann über eigene Genehmigungen verfügen, die Variationen im Buildprozess für jeden Dienst ermöglichen.
Versionsverwaltung für Releases
Ein Nachteil bei der Verwendung der Releases-Funktionalität besteht darin, dass sie nicht in einer eingecheckten azure-pipelines.yml Datei definiert werden kann. Es gibt viele Gründe, warum Sie dies möglicherweise tun möchten, von Freigabedefinitionen pro Zweig bis hin zum Einbinden eines Veröffentlichungsskeletts in Ihre Projektvorlage. Glücklicherweise wird weiterhin daran gearbeitet, die Unterstützung einiger Phasen in die Build-Komponente zu verschieben. Dies wird als mehrstufiger Build bezeichnet und die erste Version ist jetzt verfügbar!
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.