Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook, Architecting Cloud Native .NET Applications for Azure, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Wie wir in diesem Buch gesehen haben, ändert ein cloudeigener Ansatz die Art und Weise, wie Sie Anwendungen entwerfen, bereitstellen und verwalten. Sie ändert auch die Art und Weise, wie Sie Daten verwalten und speichern.
Abbildung 5-1 kontrastiert die Unterschiede.
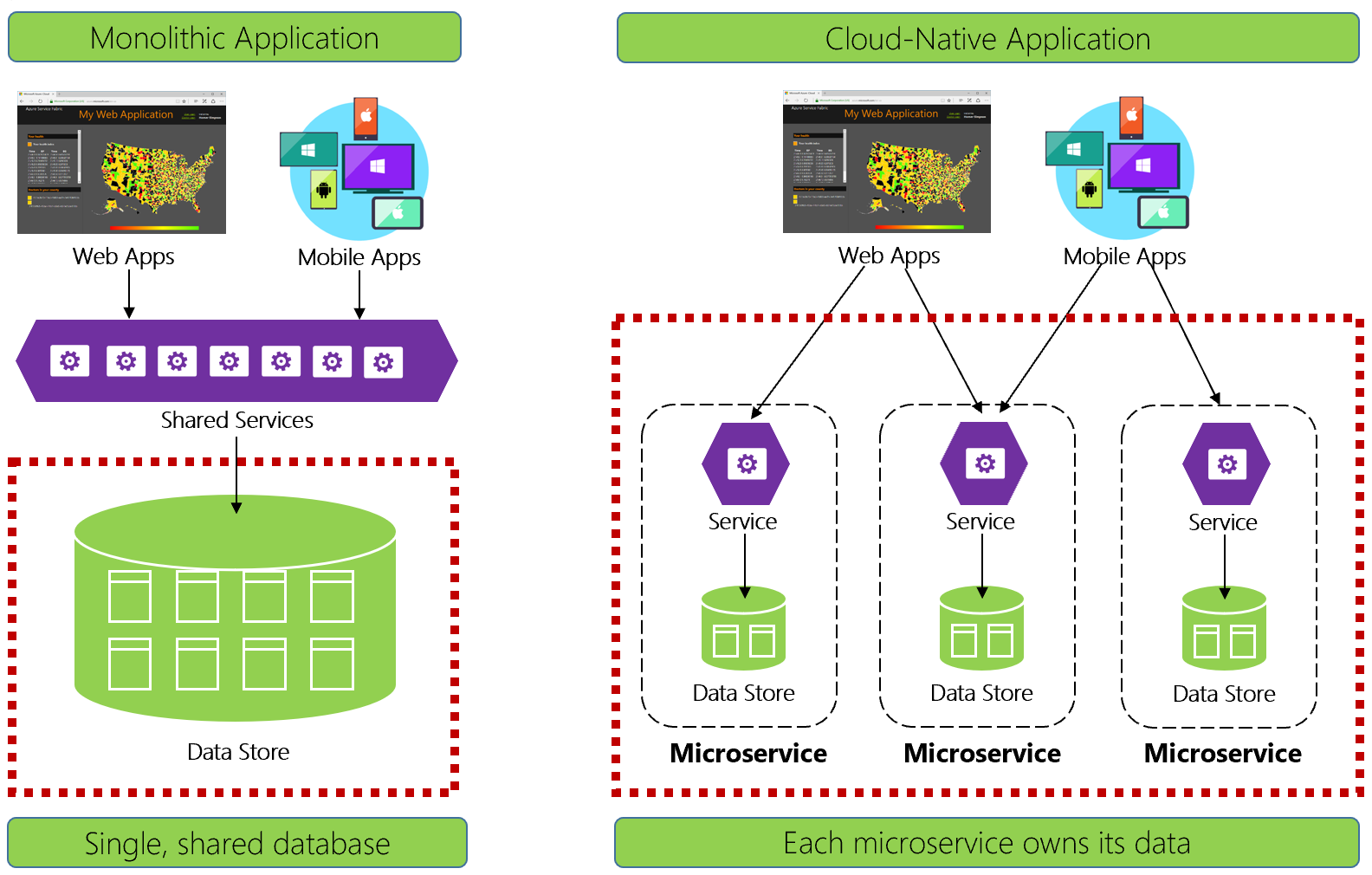
Abbildung 5-1. Datenverwaltung in cloudeigenen Anwendungen
Erfahrene Entwickler erkennen die Architektur auf der linken Seite von Abbildung 5-1 leicht. In dieser monolithischen Anwendung verbinden sich Geschäftsdienstkomponenten in einer Ebene für gemeinsame Dienste, die Daten aus einer einzigen relationalen Datenbank freigeben.
Auf viele Arten sorgt eine einzelne Datenbank für eine einfache Datenverwaltung. Das Abfragen von Daten über mehrere Tabellen hinweg ist einfach. Änderungen an Daten werden zusammen aktualisiert oder sie werden alle zurückgesetzt. ACID-Transaktionen garantieren eine starke und sofortige Konsistenz.
Bei der Entwicklung von cloudnativen Lösungen verfolgen wir einen anderen Ansatz. Beachten Sie auf der rechten Seite von Abbildung 5-1, wie die Geschäftsfunktionalität in kleine, unabhängige Microservices unterteilt wird. Jeder Microservice kapselt eine bestimmte Geschäftsfunktion und eigene Daten. Die monolithische Datenbank zerfällt in ein verteiltes Datenmodell mit vielen kleineren Datenbanken, die jeweils an einem Microservice ausgerichtet sind. Wenn sich der Rauch verzieht, kommen wir mit einem Design hervor, das eine Datenbank pro Mikroservice offenbart.
Warum Datenbank pro Microservice?
Diese Datenbank pro Microservice bietet viele Vorteile, insbesondere für Systeme, die sich schnell entwickeln und massiven Umfang unterstützen müssen. Mit diesem Modell...
- Domänendaten werden innerhalb des Diensts gekapselt.
- Datenschema kann sich weiterentwickeln, ohne dass sich dies direkt auf andere Dienste auswirkt
- Jeder Datenspeicher kann unabhängig skaliert werden.
- Ein Datenspeicherfehler in einem Dienst wirkt sich nicht direkt auf andere Dienste aus
Das Trennen von Daten ermöglicht jedem Microservice auch die Implementierung des Datenspeichertyps, der am besten für seine Workload, Speicheranforderungen und Lese-/Schreibmuster optimiert ist. Zu den Auswahlmöglichkeiten gehören relationale, Dokument-, Schlüsselwert- und sogar graphbasierte Datenspeicher.
Abbildung 5-2 zeigt das Prinzip der Polyglotperistenz in einem cloudeigenen System.
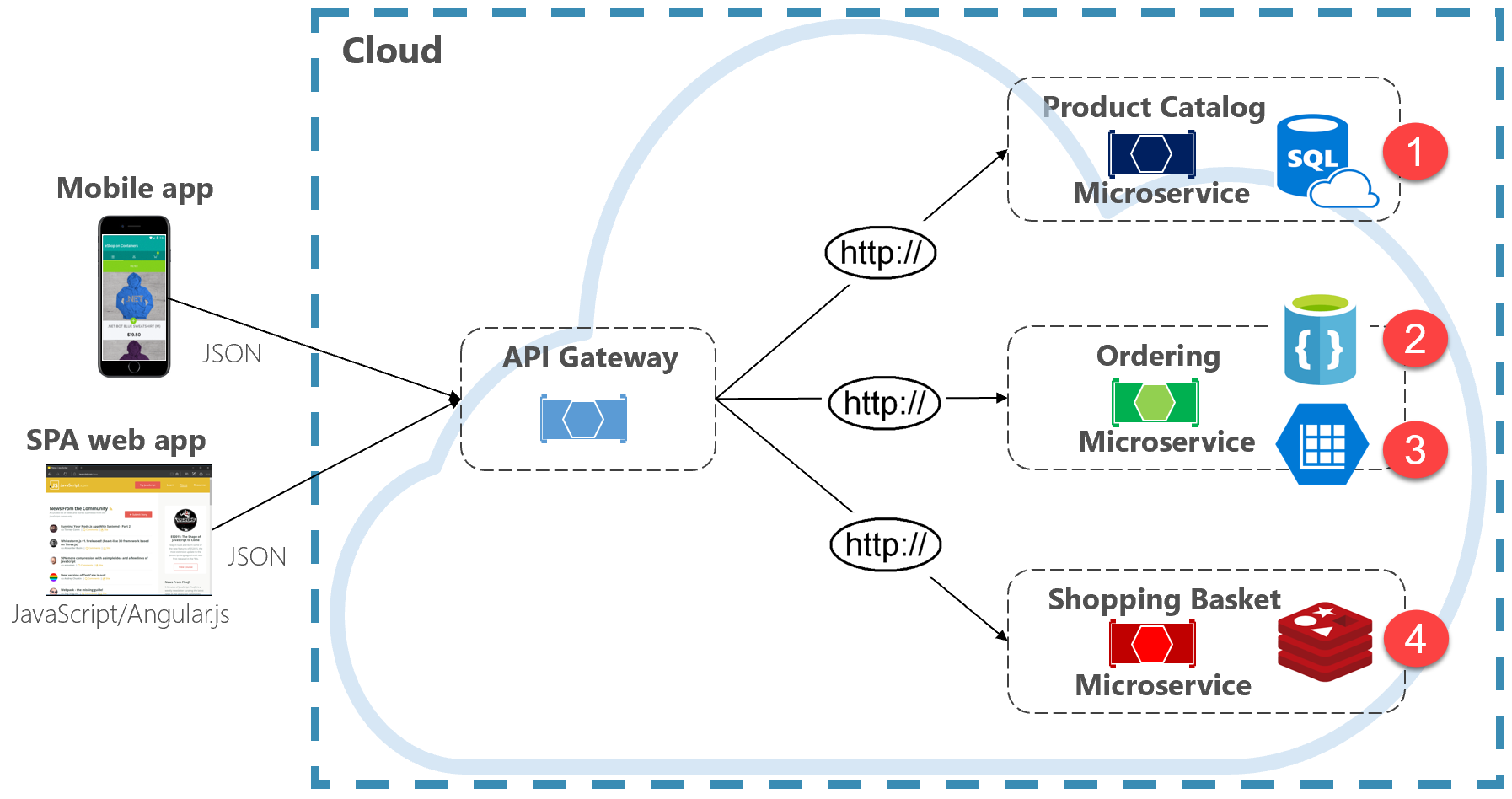
Abbildung 5-2. Polyglot-Datenpersistenz
Beachten Sie in der vorherigen Abbildung, wie jeder Microservice einen anderen Datenspeichertyp unterstützt.
- Der Produktkatalog microservice verwendet eine relationale Datenbank, um die umfangreiche relationale Struktur ihrer zugrunde liegenden Daten zu berücksichtigen.
- Der Einkaufswagen-Mikroservice nutzt einen verteilten Cache, der seinen einfachen Key-Value-Datenspeicher unterstützt.
- Der Sortier-Microservice nutzt sowohl eine NoSql-Dokumentdatenbank für Schreibvorgänge zusammen mit einem stark denormalisierten Schlüssel-/Wertspeicher, um hohe Lesevorgänge zu berücksichtigen.
Während relationale Datenbanken für Microservices mit komplexen Daten relevant bleiben, haben NoSQL-Datenbanken eine beträchtliche Beliebtheit gewonnen. Sie bieten massive Skalierung und hohe Verfügbarkeit. Ihre schemalose Natur ermöglicht Es Entwicklern, sich von einer Architektur von typierten Datenklassen und ORMs zu entfernen, die Änderungen teuer und zeitaufwendig machen. Weiter unten in diesem Kapitel behandeln wir NoSQL-Datenbanken.
Während die Kapselung von Daten in separate Microservices Flexibilität, Leistung und Skalierbarkeit steigern kann, stellt sie auch viele Herausforderungen dar. Im nächsten Abschnitt besprechen wir diese Herausforderungen zusammen mit Mustern und Praktiken, um sie zu überwinden.
Dienstübergreifende Abfragen
Während Microservices unabhängig sind und sich auf bestimmte funktionale Funktionen wie Bestand, Versand oder Bestellung konzentrieren, erfordern sie häufig eine Integration in andere Microservices. Häufig umfasst die Integration einen Microservice, der eine andere nach Daten abfragt . Abbildung 5-3 zeigt das Szenario.

Abbildung 5-3. Abfragen über Microservices
In der vorstehenden Abbildung sehen wir einen Microservice für den Warenkorb, der dem Einkaufskorb eines Benutzers einen Artikel hinzufügt. Während der Datenspeicher für diesen Microservice Korb- und Positionsdaten enthält, werden keine Produkt- oder Preisdaten beibehalten. Stattdessen gehören diese Datenelemente zu den Microservices für Katalog und Preisgestaltung. Dieser Aspekt stellt ein Problem dar. Wie kann der Einkaufskorb microservice dem Einkaufskorb des Benutzers ein Produkt hinzufügen, wenn es keine Produkt- oder Preisdaten in seiner Datenbank hat?
Eine in Kapitel 4 erläuterte Option ist ein direkter HTTP-Aufruf vom Einkaufskorb zum Katalog und zum Preis von Microservices. In Kapitel 4 haben wir jedoch gesagt, dass synchrone HTTP-Aufrufe paar Microservices zusammen aufrufen, ihre Autonomie reduzieren und ihre architekturlichen Vorteile verringern.
Wir könnten auch ein Anforderungsantwortmuster mit separaten eingehenden und ausgehenden Warteschlangen für jeden Dienst implementieren. Dieses Muster ist jedoch kompliziert und erfordert eine Sanitärinstallation, um Anforderungs- und Antwortnachrichten zu korrelieren. Während die Back-End-Microservice-Aufrufe entkoppelt werden, muss der aufrufende Dienst trotzdem synchron warten, bis der Aufruf abgeschlossen ist. Netzwerküberlastung, vorübergehende Fehler oder überlastete Microservices können zu langfristigen und sogar fehlgeschlagenen Vorgängen führen.
Stattdessen ist ein allgemein akzeptiertes Muster zum Entfernen von dienstübergreifenden Abhängigkeiten das Materialisierte Ansichtsmuster, das in Abbildung 5-4 dargestellt ist.
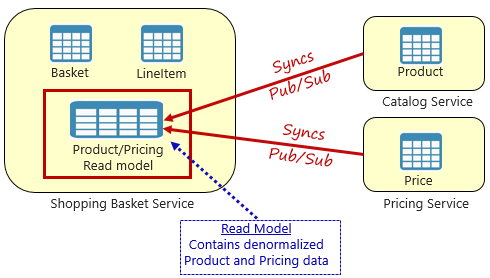
Abbildung 5-4. Materialisiertes Ansichtsmuster
Mit diesem Muster platzieren Sie eine lokale Datentabelle (als Lesemodell bezeichnet) im Einkaufskorbdienst. Diese Tabelle enthält eine denormalisierte Kopie der Daten, die für das Produkt und die Preise für Microservices erforderlich sind. Durch das direkte Kopieren der Daten in den Warenkorb-Microservice entfällt die Notwendigkeit von teuren dienstübergreifenden Anrufen. Mit den lokalen Daten für den Dienst verbessern Sie die Reaktionszeit und Zuverlässigkeit des Diensts. Darüber hinaus macht die eigene Kopie der Daten den Einkaufskorbdienst stabiler. Wenn der Katalogdienst nicht mehr verfügbar sein sollte, würde er sich nicht direkt auf den Warenkorbdienst auswirken. Der Warenkorb kann weiterhin mit den Daten aus einem eigenen Geschäft arbeiten.
Der Haken bei diesem Ansatz besteht darin, dass Sie jetzt doppelte Daten in Ihrem System haben. Das strategische Duplizieren von Daten in cloudeigenen Systemen ist jedoch eine bewährte Praxis und gilt nicht als Antimuster oder schlechte Praxis. Denken Sie daran, dass ein und nur ein Dienst über einen Datensatz verfügen kann und über diese verfügen kann. Sie müssen die Lesemodelle synchronisieren, wenn das Datensatzsystem aktualisiert wird. Die Synchronisierung wird in der Regel über asynchrones Messaging mit einem Veröffentlichungs-/Abonnementmuster implementiert, wie in Abbildung 5.4 dargestellt.
Verteilte Transaktionen
Während das Abfragen von Daten über Microservices hinweg schwierig ist, ist die Implementierung einer Transaktion über mehrere Microservices noch komplexer. Die inhärente Herausforderung, die Datenkonsistenz in unabhängigen Datenquellen in verschiedenen Microservices aufrechtzuerhalten, darf nicht unterschätzt werden. Der Mangel an verteilten Transaktionen in cloudeigenen Anwendungen bedeutet, dass Sie verteilte Transaktionen programmgesteuert verwalten müssen. Sie wechseln von einer Welt der sofortigen Konsistenz zu der der späteren Konsistenz.
Abbildung 5-5 zeigt das Problem.

Abbildung 5-5. Implementieren einer Transaktion über Microservices hinweg
In der vorherigen Abbildung nehmen fünf unabhängige Microservices an einer verteilten Transaktion teil, die eine Bestellung erstellt. Jeder Microservice verwaltet einen eigenen Datenspeicher und implementiert eine lokale Transaktion für seinen Speicher. Zum Erstellen der Bestellung muss die lokale Transaktion für jeden einzelnen Microservice erfolgreich sein, oder alle müssen den Vorgang abbrechen und zurücksetzen. Während integrierte Transaktionsunterstützung in jedem der Microservices verfügbar ist, gibt es keine Unterstützung für eine verteilte Transaktion, die sich über alle fünf Dienste erstreckt, um Daten konsistent zu halten.
Stattdessen müssen Sie diese verteilte Transaktion programmgesteuert erstellen.
Ein beliebtes Muster zum Hinzufügen von verteilter Transaktionsunterstützung ist das Saga-Muster. Sie wird implementiert, indem lokale Transaktionen programmgesteuert zusammengefasst und anschließend jede davon sequenziell aufgerufen wird. Wenn eine der lokalen Transaktionen fehlschlägt, bricht die Saga den Vorgang ab und ruft eine Reihe von Ausgleichstransaktionen auf. Durch die Ausgleichstransaktionen werden die änderungen rückgängig gemacht, die durch die vorherigen lokalen Transaktionen vorgenommen wurden, und die Datenkonsistenz wiederhergestellt. Abbildung 5-6 zeigt eine fehlgeschlagene Transaktion mit dem Saga-Muster.

Abbildung 5-6. Ausführen eines Rollbacks für eine Transaktion
In der vorherigen Abbildung ist der Aktualisierungsinventarvorgang im Inventory Microservice fehlgeschlagen. Die Saga ruft eine Reihe von Ausgleichstransaktionen (rot) auf, um die Lageranzahl anzupassen, die Zahlung und den Auftrag abzubrechen und die Daten für jeden Microservice wieder in einen konsistenten Zustand zurückzugeben.
Saga-Muster werden in der Regel als eine Serie verwandter Ereignisse choreografiert oder als ein Satz verwandter Befehle orchestriert. In Kapitel 4 haben wir das Dienstaggregatormuster erörtert, das die Grundlage für eine koordinierte Saga-Implementierung wäre. Darüber hinaus haben wir auch die Ereignisverwaltung und die Themen Azure Service Bus und Azure Event Grid besprochen, die die Grundlage für eine koordinierte Saga-Implementierung bilden würden.
Daten mit hohem Volumen
Große cloudeigene Anwendungen unterstützen häufig Anforderungen an datenintensive Datenmengen. In diesen Szenarien können herkömmliche Datenspeichertechniken zu Engpässen führen. Bei komplexen Systemen, die in großem Umfang bereitgestellt werden, kann sowohl die Befehls- als auch die Abfrageverantwortungstrennung (Command Responsibility Segregation, CQRS) und Event Sourcing die Anwendungsleistung verbessern.For complex systems that deploy on a large scale, both Command and Query Responsibility Segregation (CQRS) and Event Sourcing may improve application performance.
CQRS-Architektur
CQRS ist ein architekturbezogenes Muster, das die Leistung, Skalierbarkeit und Sicherheit maximieren kann. Das Muster trennt Vorgänge, die Daten von diesen Vorgängen lesen, die Daten schreiben.
In normalen Szenarien werden dasselbe Entitätsmodell und dasselbe Datenrepositoryobjekt sowohl für Lese- als auch für Schreibvorgänge verwendet.
Ein Szenario mit hohem Datenvolumen kann jedoch von separaten Modellen und Datentabellen für Lese- und Schreibvorgänge profitieren. Um die Leistung zu verbessern, könnte der Lesevorgang eine Abfrage nach einer stark denormalisierten Darstellung der Daten durchführen, um teure sich wiederholende Tabellenverknüppungen und Tabellensperren zu vermeiden. Der Schreibvorgang , der als Befehl bezeichnet wird, würde mit einer vollständig normalisierten Darstellung der Daten aktualisiert, die die Konsistenz garantieren. Anschließend müssen Sie einen Mechanismus implementieren, um beide Darstellungen synchron zu halten. Wenn die Schreibtabelle geändert wird, veröffentlicht sie in der Regel ein Ereignis , das die Änderung in der Lesetabelle repliziert.
Abbildung 5-7 zeigt eine Implementierung des CQRS-Musters.
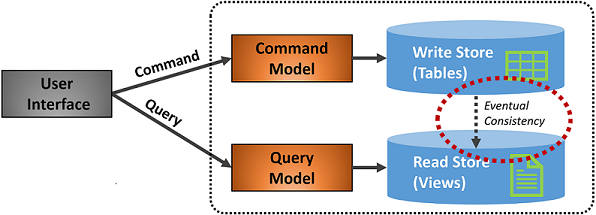
Abbildung 5-7. CQRS-Implementierung
In der vorherigen Abbildung werden separate Befehls- und Abfragemodelle implementiert. Jeder Datenschreibvorgang wird im Schreibspeicher gespeichert und dann an den Lesespeicher weitergegeben. Beachten Sie, wie der Datenverteilungsprozess nach dem Prinzip der letztendlichen Konsistenz funktioniert. Das Lesemodell wird schließlich mit dem Schreibmodell synchronisiert, es kann jedoch zu einem gewissen Zeitabstand im Prozess kommen. Im nächsten Abschnitt wird die mögliche Konsistenz erörtert.
Mit dieser Trennung können Lese- und Schreibvorgänge unabhängig voneinander skaliert werden. Lesevorgänge verwenden ein schema, das für Abfragen optimiert ist, während die Schreibvorgänge ein für Updates optimiertes Schema verwenden. Leseabfragen gehen gegen denormalisierte Daten vor, während komplexe Geschäftslogik auf das Schreibmodell angewendet werden kann. Außerdem können Sie Schreibvorgänge stärker absichern als Lesevorgänge.
Die Implementierung von CQRS kann die Anwendungsleistung für cloudeigene Dienste verbessern. Dies führt jedoch zu einem komplexeren Design. Wenden Sie dieses Prinzip sorgfältig und strategisch auf die Abschnitte Ihrer cloudeigenen Anwendung an, die davon profitieren werden. Weitere Informationen zu CQRS finden Sie im Microsoft-Buch .NET Microservices: Architecture for Containerized .NET Applications.
Ereignissourcing
Ein weiterer Ansatz zur Optimierung von Datenszenarien mit hohem Volumen umfasst Event Sourcing.
Ein System speichert in der Regel den aktuellen Status einer Datenentität. Wenn ein Benutzer beispielsweise seine Telefonnummer ändert, wird der Kundendatensatz mit der neuen Nummer aktualisiert. Wir kennen immer den aktuellen Status einer Datenentität, aber jedes Update überschreibt den vorherigen Zustand.
In den meisten Fällen funktioniert dieses Modell einwandfrei. Bei systemen mit hohem Volumen kann sich der Aufwand beim Sperren von Transaktionen und häufigen Aktualisierungsvorgängen jedoch auf die Leistung, Reaktionsfähigkeit und Skalierbarkeit der Datenbank auswirken.
Event Sourcing verwendet einen anderen Ansatz zum Erfassen von Daten. Jeder Vorgang, der sich auf Daten auswirkt, wird in einem Ereignisspeicher beibehalten. Anstatt den Status eines Datensatzes zu aktualisieren, fügen wir jede Änderung an eine sequenzielle Liste früherer Ereignisse an – ähnlich wie das Hauptbuch eines Buchhalters. Der Event Store wird zum System der Aufzeichnung für die Daten. Es wird verwendet, um verschiedene materialisierte Ansichten innerhalb des begrenzten Kontexts eines Microservice zu verbreiten. Abbildung 5.8 zeigt das Muster.

Abbildung 5-8. Ereignissourcing
Beachten Sie in der vorherigen Abbildung, wie jeder Eintrag (blau) für den Einkaufswagen eines Benutzers an einen zugrunde liegenden Ereignisspeicher angefügt wird. In der angrenzenden materialisierten Ansicht projiziert das System den aktuellen Zustand, indem alle Ereignisse wiedergegeben werden, die den einzelnen Einkaufswagen zugeordnet sind. Diese Ansicht oder dieses Lesemodell wird dann wieder auf der Benutzeroberfläche verfügbar gemacht. Ereignisse können auch in externe Systeme und Anwendungen integriert oder abgefragt werden, um den aktuellen Status einer Entität zu ermitteln. Mit diesem Ansatz bewahren Sie die Historie. Sie wissen nicht nur den aktuellen Status einer Entität, sondern auch, wie Sie diesen Zustand erreicht haben.
Im technischen Sinne vereinfacht das Event Sourcing das Schreibmodell. Es gibt keine Aktualisierungen oder Löschungen. Durch das Anfügen der einzelnen Dateneingaben als unveränderliches Ereignis werden Konflikte, Sperren und Parallelitätskonflikte minimiert, die relationalen Datenbanken zugeordnet sind. Durch das Erstellen von Lesemodellen mit dem materialisierten Ansichtsmuster können Sie die Ansicht vom Schreibmodell entkoppeln und den besten Datenspeicher auswählen, um die Anforderungen Ihrer Anwendungsbenutzeroberfläche zu optimieren.
Für dieses Muster sollten Sie einen Datenspeicher in Betracht ziehen, der Event Sourcing direkt unterstützt. Azure Cosmos DB, MongoDB, Cassandra, CouchDB und RavenDB sind gute Kandidaten.
Wie bei allen Mustern und Technologien implementieren Sie strategisch und bei Bedarf. Während die Event Sourcing eine höhere Leistung und Skalierbarkeit bieten kann, kommt es auf Kosten der Komplexität und einer Lernkurve.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.