Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, wie Sie benutzerdefinierte Apache Spark-Pools in Microsoft Fabric für Ihre Analyseworkloads erstellen. Apache Spark Pools ermöglichen Es Ihnen, maßgeschneiderte Computeumgebungen basierend auf Ihren Anforderungen zu erstellen, sodass Sie optimale Leistung und Ressourcennutzung erhalten.
Geben Sie die minimalen und maximalen Knoten für die automatische Skalierung an. Das System ruft Knoten ab und gibt sie zurück, wenn sich die Rechenanforderungen Ihres Auftrags ändern, wodurch die Skalierung effizient und die Leistung verbessert wird. Sparkpools passen die Anzahl der Executoren automatisch an, sodass Sie sie nicht manuell festlegen müssen. Das System ändert die Ausführungsanzahl basierend auf den Datenvolumen- und Auftragsberechnungsanforderungen, sodass Sie sich auf Ihre Workloads anstatt auf die Leistungsoptimierung und ressourcenverwaltung konzentrieren können.
Tipp
Wenn Sie Spark-Pools konfigurieren, wird die Knotengröße durch Kapazitätseinheiten (CU) bestimmt, die die berechnungskapazität darstellen, die jedem Knoten zugewiesen ist. Weitere Informationen zu Knotengrößen und CU finden Sie im Abschnitt "Knotengrößenoptionen " in diesem Handbuch.
Voraussetzungen
Um einen benutzerdefinierten Spark-Pool zu erstellen, stellen Sie sicher, dass Sie über Administratorzugriff auf den Arbeitsbereich verfügen. Der Kapazitätsadministrator aktiviert die Option " Angepasste Arbeitsbereichspools " im Abschnitt "Spark Compute " der Einstellungen für Kapazitätsadministratoren. Weitere Informationen finden Sie unter Spark-Berechnungseinstellungen für GewebeKapazitäten.
Erstellen von benutzerdefinierten Spark-Pools
So erstellen oder verwalten Sie den Spark-Pool, der Ihrem Arbeitsbereich zugeordnet ist:
Wechseln Sie zu Ihrem Arbeitsbereich, und wählen Sie " Arbeitsbereichseinstellungen" aus.
Wählen Sie die Option "Data Engineering/Science " aus, um das Menü zu erweitern, und wählen Sie dann "Spark"-Einstellungen aus.

Wählen Sie die Option "Neuer Pool" aus. Benennen Sie im Bildschirm " Pool erstellen " Ihren Spark-Pool. Wählen Sie außerdem die Node-Familie und eine Knotengröße aus den verfügbaren Größen (Small, Medium, Large, X-Large und XX-Large) basierend auf den Berechnungsanforderungen für Ihre Workloads aus.
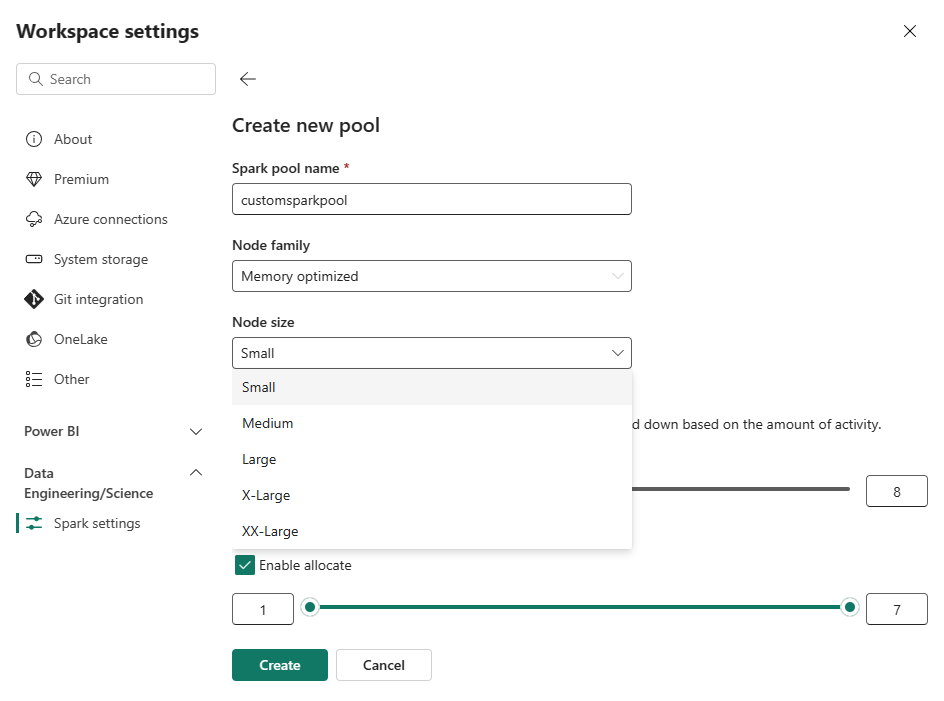
Sie können die Mindestknotenkonfiguration für Ihre benutzerdefinierten Pools auf 1 festlegen. Da Fabric Spark eine wiederherstellbare Verfügbarkeit für Cluster mit einem einzelnen Knoten bietet, müssen Sie sich keine Gedanken über Fehlschläge bei Aufträgen, den Verlust der Sitzung während eines Fehlers oder die Überbezahlung für Berechnungen bei kleineren Spark-Jobs machen.
Sie können die automatische Skalierung für Ihre benutzerdefinierten Spark-Pools aktivieren oder deaktivieren. Wenn die automatische Skalierung aktiviert ist, erwirbt der Pool dynamisch neue Knoten bis zur vom Benutzer angegebenen maximalen Knotengrenze und setzt sie nach der Auftragsausführung zurück. Dieses Feature stellt eine bessere Leistung sicher, indem Ressourcen basierend auf den Auftragsanforderungen angepasst werden. Sie dürfen die Knoten skalieren, die in die im Rahmen der Fabric-Kapazitäts-SKU erworbenen Kapazitätseinheiten passen.
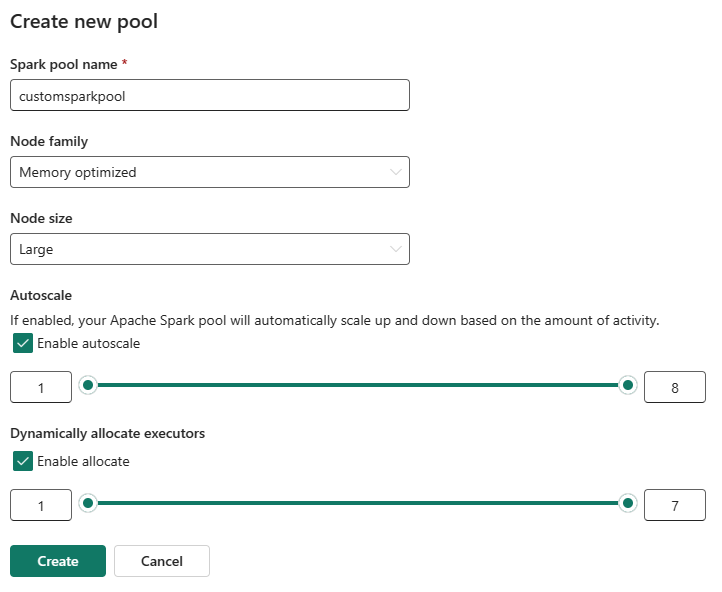
Sie können die Anzahl der Executoren mithilfe eines Schiebereglers anpassen. Jeder Executor ist ein Spark-Prozess, der Aufgaben ausführt und Daten im Arbeitsspeicher enthält. Das Erhöhen von Executoren kann die Parallelität verbessern, aber auch die Größe und Startzeit des Clusters erhöhen. Sie können auch die dynamische Executorzuordnung für Ihren Spark-Pool aktivieren, wodurch automatisch die optimale Anzahl von Executoren innerhalb der vom Benutzer angegebenen maximalen Grenze bestimmt wird. Dieses Feature passt die Anzahl der Executoren basierend auf dem Datenvolume an, was zu einer verbesserten Leistung und Ressourcenauslastung führt.



Diese benutzerdefinierten Pools haben eine standardmäßige Automatische Pausendauer von 2 Minuten, nachdem der Zeitraum der Inaktivität abgelaufen war. Sobald die Dauer der Autopause erreicht ist, läuft die Sitzung ab, und die Cluster werden nicht mehr zugewiesen. Ihnen entstehen Kosten basierend auf der Anzahl der Knoten und der Dauer, für die die benutzerdefinierten Spark-Pools verwendet werden.
Hinweis
Benutzerdefinierte Spark-Pools in Microsoft Fabric unterstützen derzeit eine maximale Knotengrenze von 200. Stellen Sie beim Konfigurieren der automatischen Skalierung oder beim Festlegen manueller Knotenanzahl sicher, dass Ihre Mindest- und Höchstwerte innerhalb dieses Grenzwerts verbleiben. Eine Überschreitung dieses Grenzwerts führt zu Überprüfungsfehlern während der Erstellung oder Aktualisierung des Pools.
Knotengrößenoptionen
Wenn Sie einen benutzerdefinierten Spark-Pool einrichten, wählen Sie aus den folgenden Knotengrößen aus:
| Knotengröße | V-Kerne | Arbeitsspeicher (GB) | BESCHREIBUNG |
|---|---|---|---|
| Klein | 4 | 32 | Für einfache Entwicklungs- und Testaufträge. |
| Mittelstufe | 8 | 64 | Für allgemeine Workloads und typische Vorgänge. |
| Groß | 16 | 128 | Für speicherintensive Aufgaben oder große Datenverarbeitungsaufträge. |
| XL | 32 | 256 | Für die anspruchsvollsten Spark-Workloads, die erhebliche Ressourcen benötigen. |
Verwandte Inhalte
- Weitere Informationen finden Sie in der öffentlichen Dokumentation zu Apache Spark.
- Erste Schritte mit den Verwaltungseinstellungen für den Spark-Arbeitsbereich in Microsoft Fabric.