Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Tutorial dauert 15 Minuten und beschreibt, wie Daten mithilfe von Dataflow Gen2 inkrementell in einem Lakehouse erfasst werden.
Für das inkrementelle Erfassen von Daten in einem Datenziel ist eine Technik erforderlich, mit der nur neue oder aktualisierte Daten in das Datenziel geladen werden. Diese Technik kann mithilfe einer Abfrage umgesetzt werden, um die Daten basierend auf dem Datenziel zu filtern. In diesem Tutorial wird gezeigt, wie Sie einen Dataflow erstellen, um Daten aus einer OData-Quelle in ein Lakehouse zu laden, und wie Sie dem Dataflow eine Abfrage hinzufügen, um die Daten basierend auf dem Datenziel zu filtern.
Die allgemeinen Schritte in diesem Tutorial sind die folgenden:
- Erstellen eines Dataflows, um Daten aus einer OData-Quelle in ein Lakehouse zu laden.
- Hinzufügen einer Abfrage zum Dataflow, um die Daten basierend auf dem Datenziel zu filtern.
- (Optional) Erneutes Laden von Daten mithilfe von Notebooks und Pipelines.
Voraussetzungen
Sie müssen über einen für Microsoft Fabric aktivierten Arbeitsbereich verfügen. Wenn Sie noch nicht über einen solchen verfügen, finden Sie weitere Informationen unter Erstellen eines Arbeitsbereichs. Außerdem geht das Lernprogramm davon aus, dass Sie die Diagrammansicht in Dataflow Gen2 verwenden. Um zu überprüfen, ob Sie die Diagrammansicht verwenden, wechseln Sie im oberen Menüband zu Ansicht und stellen Sie sicher, dass Diagrammansicht ausgewählt ist.
Erstellen eines Dataflows, um Daten aus einer OData-Quelle in ein Lakehouse zu laden
In diesem Abschnitt erstellen Sie einen Dataflow, um Daten aus einer OData-Quelle in ein Lakehouse zu laden.
Erstellen Sie ein neues Lakehouse in Ihrem Arbeitsbereich.

Erstellen Sie einen neuen Dataflow Gen2 in Ihrem Arbeitsbereich.
Fügen Sie dem Dataflow eine neue Quelle hinzu. Wählen Sie die OData-Quelle aus, und geben Sie die folgende URL ein:
https://services.OData.org/V4/Northwind/Northwind.svc

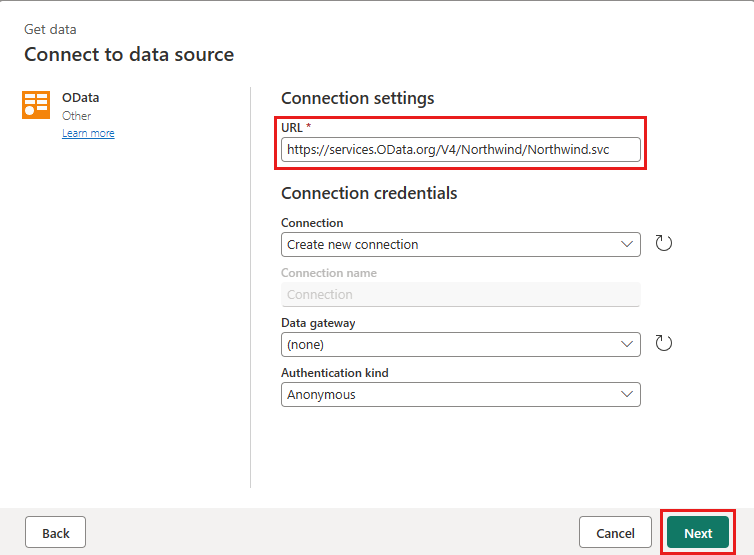
Wählen Sie die Tabelle „Orders“ (Aufträge) und dann Weiter aus.
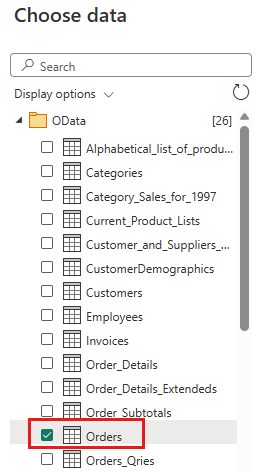
Wählen Sie die folgenden Spalten aus, die beibehalten werden sollen:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
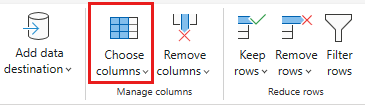

Ändern Sie den Datentyp von
OrderDate,RequiredDateundShippedDateindatetime.
Richten Sie das Datenziel in Ihrem Lakehouse mit den folgenden Einstellungen ein:
- Datenziel:
Lakehouse - Lakehouse: Wählen Sie das Lakehouse aus, das Sie in Schritt 1 erstellt haben.
- Name der neuen Tabelle:
Orders - Aktualisierungsmethode:
Replace



- Datenziel:
Wählen Sie Weiter aus, und veröffentlichen Sie den Dataflow.



Sie haben jetzt einen Dataflow erstellt, um Daten aus einer OData-Quelle in ein Lakehouse zu laden. Dieser Dataflow wird im nächsten Abschnitt verwendet, um dem Dataflow eine Abfrage hinzuzufügen, um die Daten basierend auf dem Datenziel zu filtern. Danach können Sie den Dataflow verwenden, um Daten mithilfe von Notebooks und Pipelines erneut zu laden.
Hinzufügen einer Abfrage zum Dataflow, um die Daten basierend auf dem Datenziel zu filtern
In diesem Abschnitt wird dem Dataflow eine Abfrage hinzugefügt, um die Daten basierend auf den Daten im Ziel-Lakehouse zu filtern. Die Abfrage ruft die maximale OrderID im Lakehouse zu Beginn der Dataflowaktualisierung ab und verwendet die maximale OrderId, um nur die Aufträge mit einer höheren OrderId aus der Quelle abzurufen, um sie an Ihr Datenziel anzufügen. Dabei wird davon ausgegangen, dass der Quelle Aufträge in aufsteigender Reihenfolge von OrderID hinzugefügt werden. Wenn dies nicht der Fall ist, können Sie eine andere Spalte verwenden, um die Daten zu filtern. Beispielsweise können Sie die OrderDate-Spalte verwenden, um die Daten zu filtern.
Hinweis
OData-Filter werden in Fabric nach dem Empfang der Daten von der Datenquelle angewendet. Bei Datenbankquellen wie SQL Server wird der Filter jedoch in der Abfrage angewendet, die an die Back-End-Datenquelle übermittelt wird, und es werden nur gefilterte Zeilen an den Dienst zurückgegeben.
Nachdem der Dataflow aktualisiert wurde, öffnen Sie den Dataflow erneut, den Sie im vorherigen Abschnitt erstellt haben.
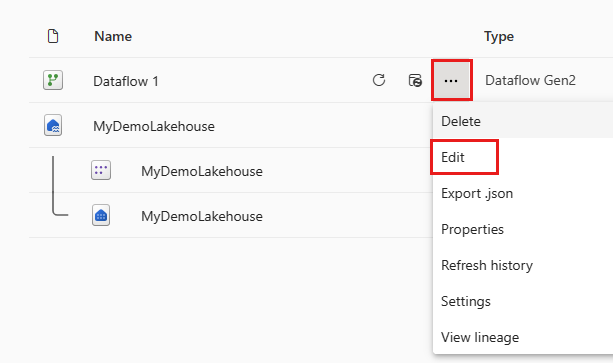
Erstellen Sie eine neue Abfrage namens
IncrementalOrderID, und rufen Sie Daten aus der Tabelle „Orders“ in das Lakehouse ab, das Sie im vorherigen Abschnitt erstellt haben.


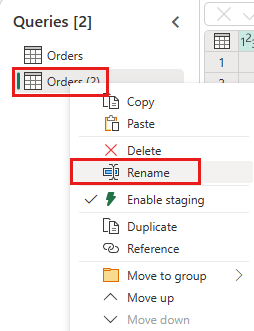

Deaktivieren Sie das Staging dieser Abfrage.

Klicken Sie in der Datenvorschau mit der rechten Maustaste auf die
OrderID-Spalte, und wählen Sie Drilldown ausführen aus.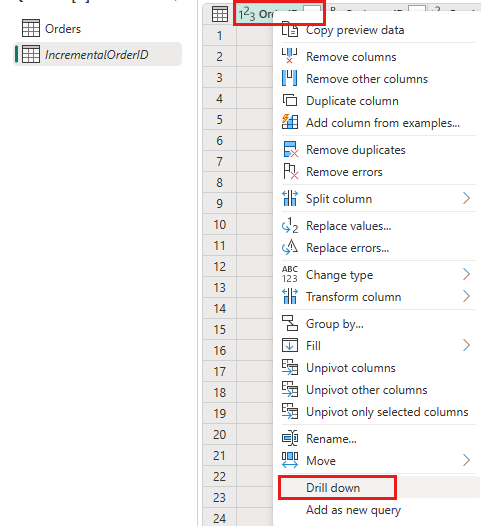
Wählen Sie im Menüband Listentools ->Statistiken ->Maximum aus.
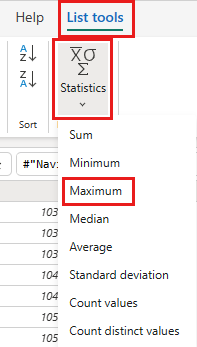
Sie verfügen jetzt über eine Abfrage, die die maximale OrderID im Lakehouse zurückgibt. Diese Abfrage wird verwendet, um die Daten aus der OData-Quelle zu filtern. Im nächsten Abschnitt wird dem Dataflow eine Abfrage hinzugefügt, um die Daten aus der OData-Quelle basierend auf der maximalen OrderID im Lakehouse zu filtern.
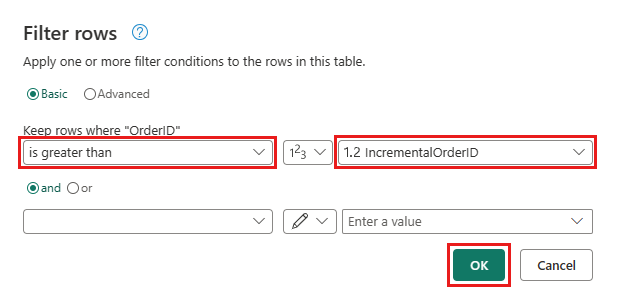
Navigieren Sie zurück zur Orders-Abfrage, und fügen Sie einen neuen Schritt hinzu, um die Daten zu filtern. Verwenden Sie folgende Einstellungen:
- Spalte:
OrderID - Vorgang:
Greater than - Wert: Parameter
IncrementalOrderID

- Spalte:
Ermöglichen Sie, dass die Daten aus der OData-Quelle und dem Lakehouse kombiniert werden, indem Sie das folgende Dialogfeld bestätigen:

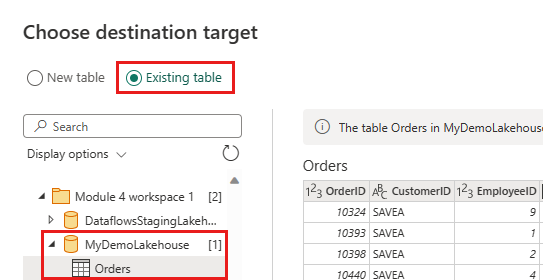
Aktualisieren Sie das Datenziel, um die folgenden Einstellungen zu verwenden:
- Aktualisierungsmethode:
Append


- Aktualisierungsmethode:
Veröffentlichen Sie den Dataflow.
Ihr Dataflow enthält jetzt eine Abfrage, die die Daten aus der OData-Quelle basierend auf der maximalen OrderID im Lakehouse filtert. Dies bedeutet, dass nur neue oder aktualisierte Daten in das Lakehouse geladen werden. Im nächsten Abschnitt wird der Dataflow verwendet, um Daten mithilfe von Notebooks und Pipelines erneut zu laden.
(Optional) Erneutes Laden von Daten mithilfe von Notebooks und Pipelines
Optional können Sie bestimmte Daten mithilfe von Notebooks und Pipelines erneut laden. Mit benutzerdefiniertem Python-Code im Notebook entfernen Sie die alten Daten aus dem Lakehouse. Indem Sie dann eine Pipeline erstellen, in der Sie zuerst das Notebook ausführen und den Dataflow sequenziell ausführen, laden Sie die Daten aus der OData-Quelle erneut in das Lakehouse. Notebooks unterstützen mehrere Sprachen, aber dieses Tutorial verwendet PySpark. Pyspark ist eine Python-API für Spark und wird in diesem Tutorial zum Ausführen von Spark SQL-Abfragen verwendet.
Erstellen Sie ein neues Notebook in Ihrem Arbeitsbereich.
Fügen Sie Ihrem Notebook den folgenden PySpark-Code hinzu:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Führen Sie das Notebook aus, um zu überprüfen, ob die Daten aus dem Lakehouse entfernt werden.
Erstellen Sie eine neue Pipeline in Ihrem Arbeitsbereich.

Fügen Sie der Pipeline eine neue Notebookaktivität hinzu, und wählen Sie das Notebook aus, das Sie im vorherigen Schritt erstellt haben.
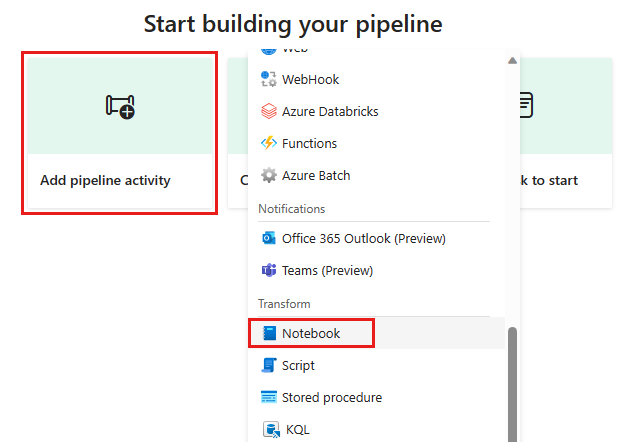
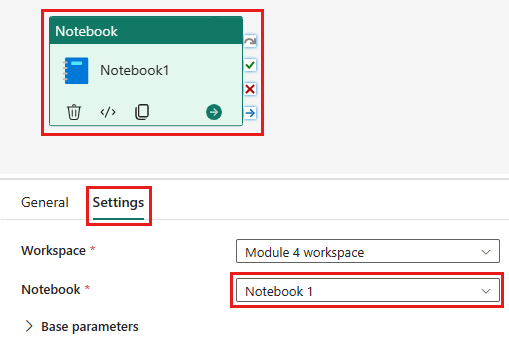
Fügen Sie der Pipeline eine neue Dataflowaktivität hinzu, und wählen Sie den Dataflow aus, den Sie im vorherigen Abschnitt erstellt haben.
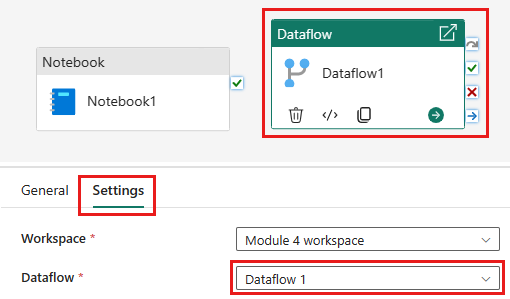
Verknüpfen Sie die Notebookaktivität mit einem Erfolgstrigger mit der Dataflowaktivität.

Speichern Sie die Pipeline, und führen Sie sie aus.


Sie verfügen jetzt über eine Pipeline, die alte Daten aus dem Lakehouse entfernt und die Daten aus der OData-Quelle in das Lakehouse erneut lädt. Mit diesem Setup können Sie die Daten aus der OData-Quelle regelmäßig in das Seehaus laden.