Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Kusto Query Language (KQL) verfügt über integrierte Anomalieerkennungs- und Prognosefunktionen , um auf anomales Verhalten zu überprüfen. Sobald ein solches Muster erkannt wurde, kann eine Ursachenanalyse (Root Cause Analysis, RCA) ausgeführt werden, um die Anomalie zu mindern oder aufzulösen.
Der Diagnoseprozess ist komplex und langwierig und wird von Domänenexperten durchgeführt. Der Prozess umfasst:
- Abrufen und Verknüpfen weiterer Daten aus verschiedenen Quellen für den gleichen Zeitrahmen
- Suchen nach Änderungen der Verteilung von Werten in mehreren Dimensionen
- Diagrammerstellung weiterer Variablen
- Andere Techniken, die auf Domänenwissen und Intuition basieren
Da diese Diagnoseszenarien üblich sind, stehen Machine Learning Plugins zur Verfügung, um die Diagnosephase zu vereinfachen und die Dauer des RCA zu verkürzen.
Alle drei der folgenden Machine Learning-Plug-Ins implementieren Clusteringalgorithmen: autocluster, , basketund diffpatterns. Die autocluster Und basket Plugins clustern einen einzelnen Datensatzsatz, und das diffpatterns Plug-In gruppiert die Unterschiede zwischen zwei Datensatzsätzen.
Clusterbildung eines einzelnen Datensatzes
Ein gängiges Szenario enthält ein Dataset, das anhand eines bestimmten Kriteriums ausgewählt wurde, z. B.:
- Zeitfenster, in dem anomales Verhalten angezeigt wird
- Hochtemperaturgerätelesungen
- Langzeitbefehle
- Top-Ausgaben-Benutzer
Sie möchten eine schnelle und einfache Möglichkeit, allgemeine Muster (Segmente) in den Daten zu finden. Muster sind eine Teilmenge des Datasets, deren Datensätze dieselben Werte über mehrere Dimensionen (kategorisierte Spalten) aufweisen.
Die folgende Abfrage erstellt und zeigt eine Zeitreihe von Dienstanomalien über den Zeitraum einer Woche in Zehn-Minuten-Intervallen an.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")

Die Anzahl der Dienstfehler korreliert mit dem gesamten Dienstverkehr. Sie können das tägliche Muster für Werktage, Montag bis Freitag, deutlich sehen. Es gibt einen Anstieg der Anzahl der Service-Ausnahmen zur Mittagszeit und einen Rückgang in der Nacht. Niedrige Zahlen sind am Wochenende sichtbar. Ausnahmespitzen können mithilfe der Anomalieerkennung von Zeitreihen erkannt werden.
Die zweite Spitze der Daten tritt am Dienstagnachmittag auf. Die folgende Abfrage wird verwendet, um weiter zu diagnostizieren und zu überprüfen, ob es sich um einen plötzlichen Anstieg handelt. Die Abfrage zeichnet das Diagramm in einer höheren Auflösung von acht Stunden und einminütigen Intervallen um den Punkt herum neu. Daraufhin können Sie die Ränder genauer betrachten.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")

Sie sehen eine kurze zweiminütige Spitze von 15:00 bis 15:02. Zählen Sie in der folgenden Abfrage die Ausnahmen in diesem zweiminütigen Fenster:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Anzahl |
|---|
| 972 |
Beispiel für 20 Ausnahmen von 972 in der folgenden Abfrage:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Region | ScaleUnit | Bereitstellungs-ID | Überwachungspunkt | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8e7564 |
| 2016-08-23 15:00:58.2222707 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Obwohl es weniger als tausend Ausnahmen gibt, ist es immer noch schwierig, allgemeine Segmente zu finden, da in jeder Spalte mehrere Werte vorhanden sind. Sie können das autocluster() Plug-In verwenden, um sofort eine kurze Liste allgemeiner Segmente zu extrahieren und die interessanten Cluster innerhalb der zwei Minuten der Spitzen zu finden, wie in der folgenden Abfrage dargestellt:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| SegmentId | Anzahl | Prozent | Region | ScaleUnit | Bereitstellungs-ID | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5,65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
Aus den obigen Ergebnissen sehen Sie, dass das dominantste Segment 65,74% der gesamten Ausnahmedatensätze enthält und vier Dimensionen teilt. Das nächste Segment ist viel weniger verbreitet. Es enthält nur 9,67% der Datensätze und teilt drei Dimensionen. Die anderen Segmente sind noch weniger verbreitet.
Autocluster verwendet einen proprietären Algorithmus, um mehrere Dimensionen zu analysieren und interessante Segmente zu extrahieren. "Interessant" bedeutet, dass jedes Segment sowohl die Datensätze als auch den Merkmalsatz signifikant abdeckt. Die Segmente sind ebenfalls unterschiedlich, was bedeutet, dass sich jeder von den anderen unterscheidet. Mindestens eines dieser Segmente kann für den RCA-Prozess relevant sein. Um die Segmentüberprüfung und -bewertung zu minimieren, extrahiert autocluster nur eine kleine Segmentliste.
Sie können das Plugin auch in der folgenden Abfrage verwenden:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| SegmentId | Anzahl | Prozent | Region | ScaleUnit | Bereitstellungs-ID | Überwachungspunkt | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | Scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | Scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | Scus | ||||
| 9 | 55 | 5,65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Basket implementiert den Algorithmus "Apriori" für den Item Set Mining. Es extrahiert alle Segmente, deren Abdeckung des Datensatzes über einem Schwellenwert liegt (Standard 5%). Sie können sehen, dass weitere Segmente mit ähnlichen Segmenten extrahiert wurden, z. B. Segmente 0, 1 oder 2, 3.
Beide Plug-Ins sind leistungsfähig und einfach zu bedienen. Ihre Einschränkung besteht darin, dass sie einen einzigen Datensatz in unbeaufsichtigter Weise ohne Etiketten gruppieren. Es ist unklar, ob die extrahierten Muster den ausgewählten Datensatzsatz, anomaliele Datensätze oder den globalen Datensatzsatz kennzeichnen.
Klassifizieren der Unterschiede zwischen zwei Datensätzen
Das diffpatterns() Plugin überwindet die Einschränkungen von autocluster und basket.
Diffpatterns nimmt zwei Datensätze und extrahiert die Hauptsegmente, die unterschiedlich sind. Ein Satz enthält in der Regel den anomalen Datensatz, der untersucht wird. Eins wird von autocluster und basket analysiert. Der andere Satz enthält den Referenzdatensatz, die Basislinie.
In der folgenden Abfrage findet diffpatterns interessante Cluster innerhalb der zweiminütigen Spitze, die sich von den Clustern innerhalb der Baseline unterscheiden. Das Basiszeitfenster wird als die acht Minuten vor 15:00 Uhr definiert, als die Spitze begann. Sie erweitern um eine binäre Spalte (AB) und geben an, ob ein bestimmter Datensatz zur Basislinie oder zur Anomalienmenge gehört.
Diffpatterns implementiert einen überwachten Lernalgorithmus, bei dem zwei Klassenbezeichnungen durch die anomale gegenüber der Basislinien-Flagge (AB) generiert wurden.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| SegmentId | CountA | CountB | ProzentA | PercentB | ProzentunterschiedAB | Region | ScaleUnit | Bereitstellungs-ID | Überwachungspunkt |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | Scus | |||
| 2 | 92 | 356 | 9.47 | 28,9 | 19,43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25,81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5,66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
Das dominante Segment ist dasselbe Segment, das von autocluster extrahiert wurde. Sein Abdeckungsgrad des zweiminütigen anomalen Fensters beträgt ebenfalls 65,74%. Die Abdeckung des achtminütigen Ausgangszeitfensters beträgt jedoch nur 1,7%. Der Unterschied beträgt 64,04%. Dieser Unterschied scheint mit der anomalen Spitze zusammenzuhängen. Um diese Annahme zu überprüfen, teilt die folgende Abfrage das ursprüngliche Diagramm in die Datensätze auf, die zu diesem problematischen Segment gehören, und Datensätze aus den anderen Segmenten.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
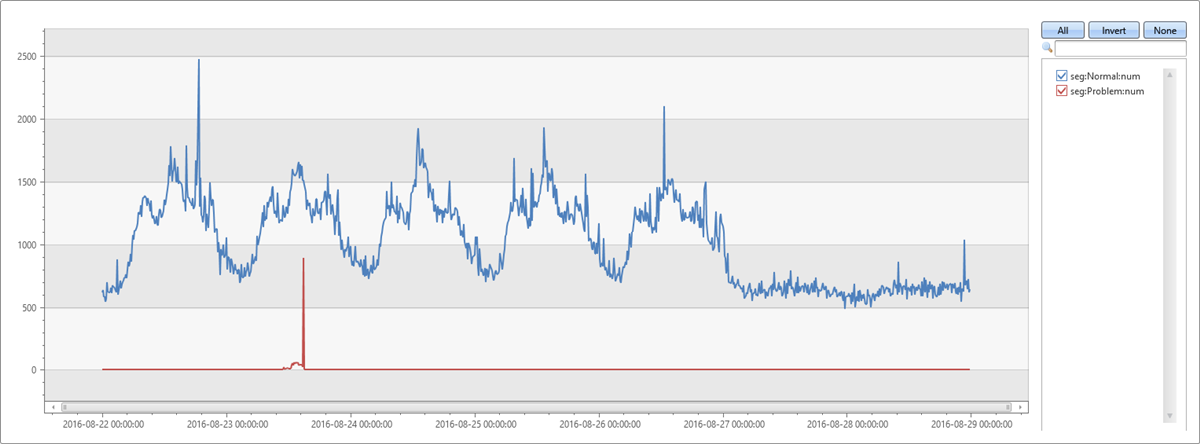
Dieses Diagramm ermöglicht es uns zu sehen, dass die Spitze am Dienstagnachmittag aufgrund von Ausnahmen von diesem bestimmten Segment war, die mithilfe des diffpatterns Plug-Ins ermittelt wurde.
Zusammenfassung
Die Machine Learning-Plug-Ins sind für viele Szenarien hilfreich.
autocluster und basket implementieren einen unbeaufsichtigten Lernalgorithmus und sind einfach zu bedienen.
Diffpatterns implementiert einen überwachten Lernalgorithmus und ist zwar komplexer, aber leistungsfähiger für die Extraktion von Differenzierungssegmenten für RCA.
Diese Plug-Ins werden interaktiv in Ad-hoc-Szenarien und in automatischen Echtzeitüberwachungsdiensten verwendet. Auf die Anomalieerkennung der Zeitreihen folgt ein Diagnoseprozess. Der Prozess ist hochoptimiert, um die erforderlichen Leistungsstandards zu erfüllen.