Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Clusterwerte erstellen automatisch Gruppen mit ähnlichen Werten mithilfe eines Fuzzyabgleichsalgorithmus und ordnen dann den Wert jeder Spalte der am besten übereinstimmenden Gruppe zu. Diese Transformation ist nützlich, wenn Sie mit Daten arbeiten, die viele verschiedene Variationen desselben Werts aufweisen und Werte in konsistente Gruppen kombinieren müssen.
Betrachten Sie eine Beispieltabelle mit einer ID-Spalte , die eine Reihe von IDs und eine Spalte " Person " enthält, die eine Reihe unterschiedlich geschriebener und großgeschriebener Versionen der Namen Miguel, Mike, William und Bill enthält.
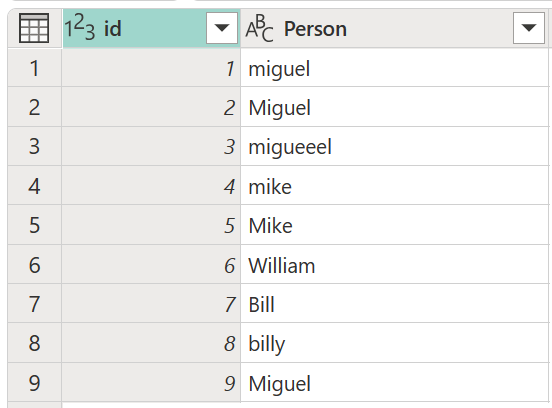
In diesem Beispiel ist das gesuchte Ergebnis eine Tabelle mit einer neuen Spalte, in der die richtigen Wertegruppen aus der Spalte " Person " und nicht alle unterschiedlichen Variationen derselben Wörter angezeigt werden.
Hinweis
Das Feature "Clusterwerte" ist nur für Power Query Online verfügbar.
Eine Clusterspalte erstellen
Um Clusterwerte zu gruppieren, wählen Sie zuerst die Spalte "Person " aus, wechseln Sie im Menüband zur Registerkarte "Spalte hinzufügen ", und wählen Sie dann die Option "Clusterwerte " aus.
![]()
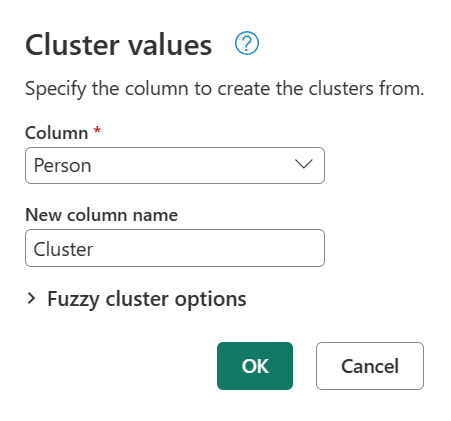
Bestätigen Sie im Dialogfeld "Clusterwerte " die Spalte, aus der Sie die Cluster erstellen möchten, und geben Sie den neuen Namen der Spalte ein. Nennen Sie in diesem Fall diese neue Spalte Cluster.
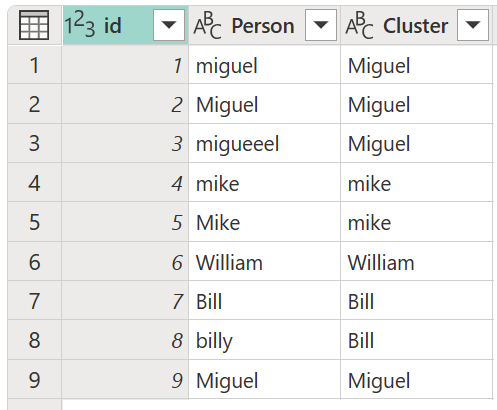
Das Ergebnis dieses Vorgangs wird in der folgenden Abbildung angezeigt.
Hinweis
Für jeden Wertecluster wählt Power Query die häufigste Instanz aus der ausgewählten Spalte als "kanonische" Instanz aus. Wenn mehrere Instanzen mit derselben Häufigkeit auftreten, wählt Power Query die erste Instanz aus.
Verwenden der Fuzzyclusteroptionen
Die folgenden Optionen stehen für Clusteringwerte in einer neuen Spalte zur Verfügung:
- Ähnlichkeitsschwellenwert (optional): Diese Option gibt an, wie ähnliche zwei Werte gruppiert werden müssen. Die Minimale Einstellung von Null (0) bewirkt, dass alle Werte gruppiert werden. Die maximale Einstellung von 1 erlaubt nur Werte, die genau übereinstimmen, zusammenzufassen. Der Standardwert ist 0.8.
- Groß-/Kleinschreibung ignorieren: Wenn Textzeichenfolgen verglichen werden, wird die Groß-/Kleinschreibung ignoriert. Diese Option ist standardmäßig aktiviert.
- Gruppieren nach der Kombination von Textteilen: Der Algorithmus versucht, Textteile zu kombinieren (z. B. das Zusammenfügen von Micro und soft zu Microsoft), um Werte zu gruppieren.
- Ähnlichkeitsbewertungen anzeigen: Zeigt Ähnlichkeitsbewertungen zwischen den Eingabewerten und berechneten repräsentativen Werten nach Fuzzyclustering an.
- Transformationstabelle (optional): Sie können eine Transformationstabelle auswählen, die Werte (z. B. das Zuordnen von MSFT zu Microsoft) ordnet, um sie zu gruppieren.
In diesem Beispiel wird eine neue Transformationstabelle mit dem Namen "Meine Transformationstabelle " verwendet, um zu veranschaulichen, wie Werte zugeordnet werden können. Diese Transformationstabelle hat zwei Spalten:
- Von: Die Zeichenkette, nach der Sie in Ihrer Tabelle suchen möchten.
- To: Der Textstring, der verwendet wird, um den Textstring in der From Spalte zu ersetzen.

Von Bedeutung
Es ist wichtig, dass die Transformationstabelle die gleichen Spalten und Spaltennamen wie in der vorherigen Abbildung hat und dass diese 'Von' und 'An' genannt werden. Andernfalls erkennt Power Query diese Tabelle nicht als Transformationstabelle, und es findet keine Transformation statt.
Doppelklicken Sie mit der zuvor erstellten Abfrage auf den Schritt " Gruppierte Werte ", und erweitern Sie dann im Dialogfeld " Clusterwerte " die Optionen für den Fuzzycluster. Aktivieren Sie unter "Fuzzy-Clusteroptionen" die Option " Ähnlichkeitsbewertungen anzeigen ". Wählen Sie für die Transformationstabelle (optional) die Abfrage mit der Transformationstabelle aus.

Nachdem Sie die Transformationstabelle ausgewählt und die Option " Ähnlichkeitsergebnisse anzeigen " aktiviert haben, wählen Sie "OK" aus. Das Ergebnis dieses Vorgangs gibt Ihnen eine Tabelle, die die gleichen ID - und Personenspalten wie die ursprüngliche Tabelle enthält, enthält aber auch zwei neue Spalten namens Cluster und Person_Cluster_Similarity. Die Spalte "Cluster " enthält die richtig geschriebenen und großgeschriebenen Versionen der Namen Miguel für Versionen von Miguel und Mike sowie William für Versionen von Bill, Billy und William. Die Spalte Person_Cluster_Similarity enthält die Ähnlichkeitsbewertungen für jeden Namen.

Grundsätze der Transformationstabellen
Möglicherweise stellen Sie fest, dass die Transformationstabelle im vorherigen Abschnitt darauf hindeutet, dass Instanzen von Mike in Miguel geändert werden und Instanzen von William in Bill geändert werden. In der resultierenden Tabelle wurden jedoch die Instanzen von Bill und "billy" stattdessen in William geändert. In der Transformationstabelle ist anstelle eines direkten Von zu Zu Pfades die Tabelle während des Clusterings symmetrisch, was bedeutet, dass "Mike" "Miguel" entspricht und umgekehrt. Das Ergebnis der in der Transformationstabelle angegebenen Entsprechungen hängt von den folgenden Regeln ab:
- Wenn eine Mehrheit identischer Werte vorhanden ist, haben diese Werte Vorrang vor nichtidentischen Werten.
- Wenn keine Mehrheit von Werten vorhanden ist, hat der angezeigte Wert Vorrang.
In der ursprünglichen Tabelle, die in diesem Artikel verwendet wird, bilden die Versionen von Miguel (sowohl "Miguel" als auch Miguel) in der Spalte " Person " die Mehrheit der Instanzen des Namens Miguel und Mike. Darüber hinaus macht der Name Miguel mit großem Anfangsbuchstaben den Großteil des Namens Miguel aus. Das Zuordnen von Miguel und seinen Derivaten sowie Mike und seinen Ableitungen in der Transformationstabelle führt dazu, dass Miguel in der Spalte Cluster verwendet wird.
Für die Namen William, Bill und "billy" gibt es jedoch keine Mehrheit der Werte, da alle drei eindeutig sind. Da William zuerst erscheint, wird William in der Spalte "Cluster " verwendet. Wenn "billy" zuerst in der Tabelle erschienen wäre, würde "billy" in der Spalte Cluster verwendet werden. Da keine Mehrheit von Werten vorhanden ist, wird auch der von den einzelnen Namen verwendete Fall verwendet. Wenn William zuerst steht, wird William mit einem großen "W" als Ergebniswert verwendet; wenn "billy" an erster Stelle steht, wird "billy" mit einem kleinen "b" verwendet.