Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Eines der gängigen Szenarien, die bei der Integration von Daten in Dataverse auftreten, ist die Synchronisierung mit der Quelle. Mithilfe des Standarddatenflusses können Sie Daten in Dataverse laden. In diesem Artikel wird erläutert, wie Sie die Daten mit dem Quellsystem synchronisieren können.
Die Wichtigkeit der Schlüsselspalte
Wenn Sie ein relationales Datenbasissystem als Quelle verwenden, verfügen Sie normalerweise über Schlüsselspalten in den Tabellen, und die Daten befinden sich in einem ordnungsgemäßen Format, das in Dataverse geladen werden soll. Die Daten aus den Excel-Dateien sind jedoch nicht immer so sauber. Sie haben häufig eine Excel-Datei mit Datenblättern, ohne dass eine Schlüsselspalte vorhanden ist. In Feldzuordnungsüberlegungen für Standarddatenflüsse können Sie sehen, dass es bei einer Schlüsselspalte in der Quelle problemlos als alternativer Schlüssel in der Feldzuordnung des Datenflusses verwendet werden kann.
Das Vorhandensein einer Schlüsselspalte ist für die Tabelle in Dataverse wichtig. Die Schlüsselspalte ist der Zeilenbezeichner; diese Spalte enthält eindeutige Werte in jeder Zeile. Wenn Sie eine Schlüsselspalte haben, können Sie doppelte Zeilen vermeiden, und sie hilft auch bei der Synchronisierung der Daten mit dem Quellsystem. Wenn eine Zeile aus dem Quellsystem entfernt wird, ist es hilfreich, eine Schlüsselspalte zu haben, um sie auch aus Dataverse zu entfernen.
Erstellen einer Schlüsselspalte
Wenn Sie keine Schlüsselspalte in Ihrer Datenquelle haben (Excel, Textdatei oder andere Quellen), können Sie eine spalte mit der folgenden Methode generieren:
Bereinigen Sie Ihre Daten.
Der erste Schritt zum Erstellen der Schlüsselspalte besteht darin, alle unnötigen Zeilen zu entfernen, die Daten zu bereinigen, leere Zeilen zu entfernen und mögliche Duplikate zu entfernen.
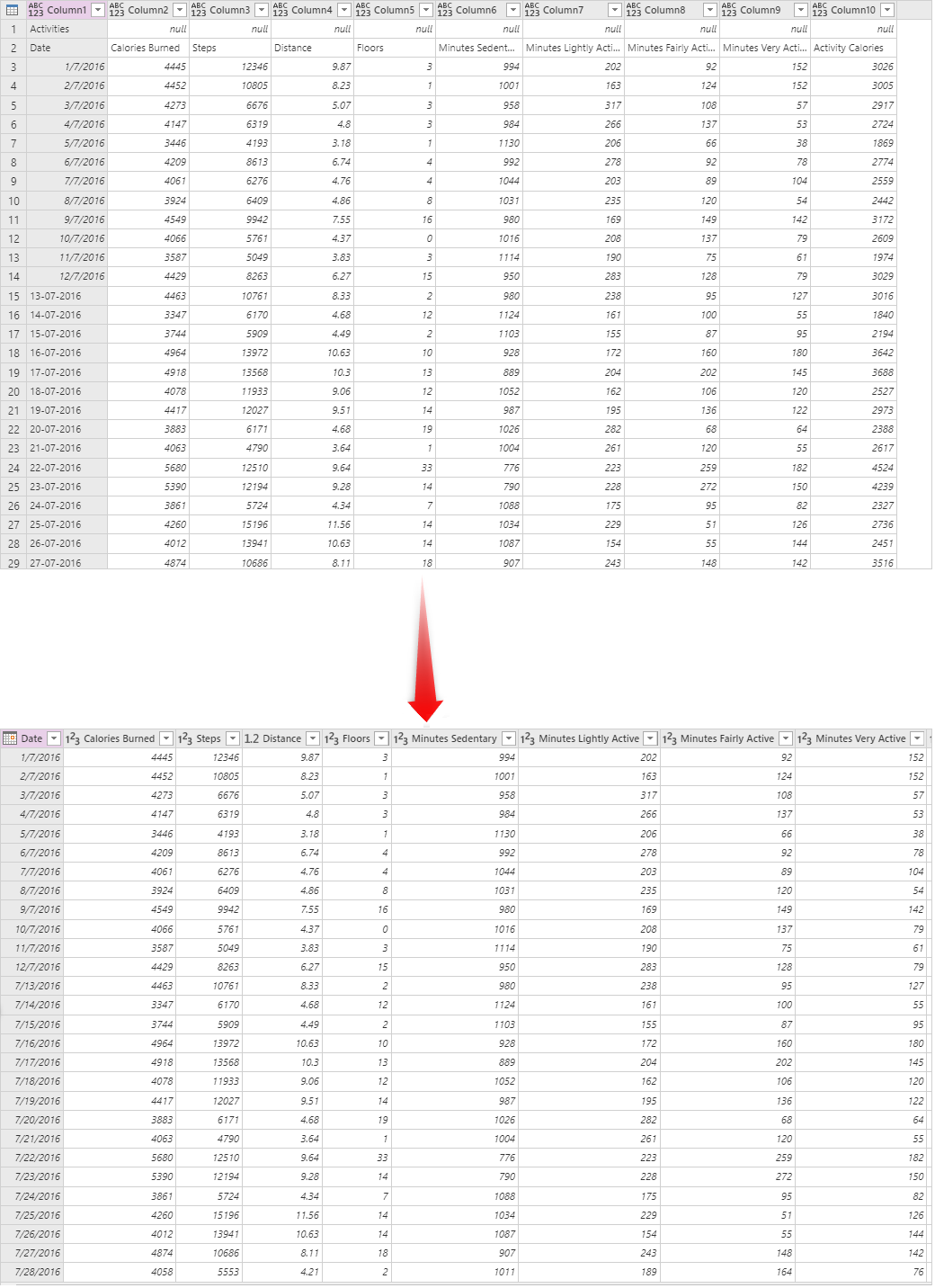
Fügen Sie eine Indexspalte hinzu.
Nachdem die Daten bereinigt wurden, besteht der nächste Schritt darin, ihm eine Schlüsselspalte zuzuweisen. Sie können " Indexspalte hinzufügen " aus der Registerkarte " Spalte hinzufügen " zu diesem Zweck verwenden.

Wenn Sie die Indexspalte hinzufügen, haben Sie einige Optionen, um sie anzupassen, z. B. Anpassungen für die Startnummer oder die Anzahl der Werte, die jedes Mal springen sollen. Der Startwert ist null und wird jedes Mal um eins erhöht.
Verwenden Sie die Schlüsselspalte als alternativen Schlüssel
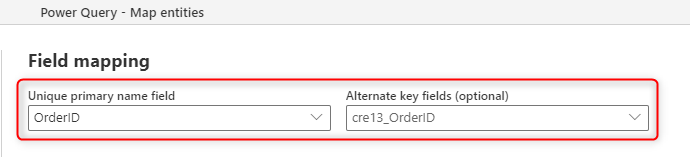
Nachdem Sie nun über die Schlüsselspalten verfügen, können Sie die Feldzuordnung des Datenflusses dem Alternativen Schlüssel zuweisen.
Die Einstellung ist einfach, Sie müssen lediglich den alternativen Schlüssel festlegen. Wenn Sie jedoch über mehrere Dateien oder Tabellen verfügen, müssen Sie einen anderen Schritt in Betracht ziehen.
Wenn Sie über mehrere Dateien verfügen
Wenn Sie nur eine Excel-Datei (oder tabelle) haben, sind die Schritte im vorherigen Verfahren ausreichend, um den alternativen Schlüssel festzulegen. Wenn Sie jedoch mehrere Dateien (oder Blätter oder Tabellen) mit derselben Struktur (aber mit unterschiedlichen Daten) haben, fügen Sie sie zusammen an.
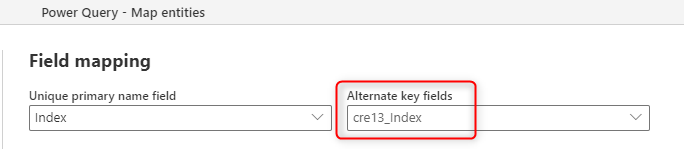
Wenn Sie Daten aus mehreren Excel-Dateien abrufen, fügt die Option "Dateien kombinieren " von Power Query automatisch alle Daten zusammen, und Ihre Ausgabe sieht wie in der folgenden Abbildung aus.
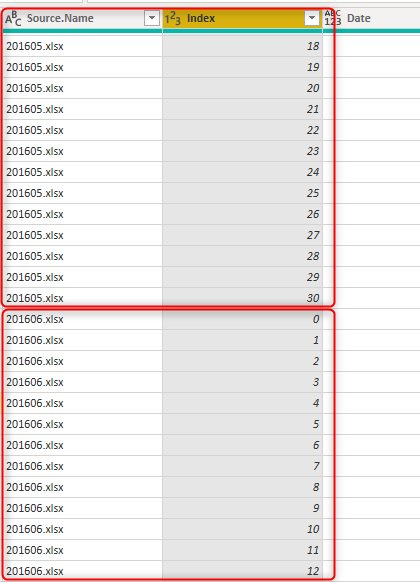
Wie in der vorherigen Abbildung gezeigt, fügt Power Query neben dem Ergebnis der Anhängung auch die Spalte "Source.Name" hinzu, die den Dateinamen enthält. Der Indexwert in jeder Datei kann eindeutig sein, aber er ist nicht für mehrere Dateien eindeutig. Die Kombination aus der Indexspalte und der Source.Name Spalte ist jedoch eine eindeutige Kombination. Wählen Sie einen zusammengesetzten Alternativschlüssel für dieses Szenario aus.

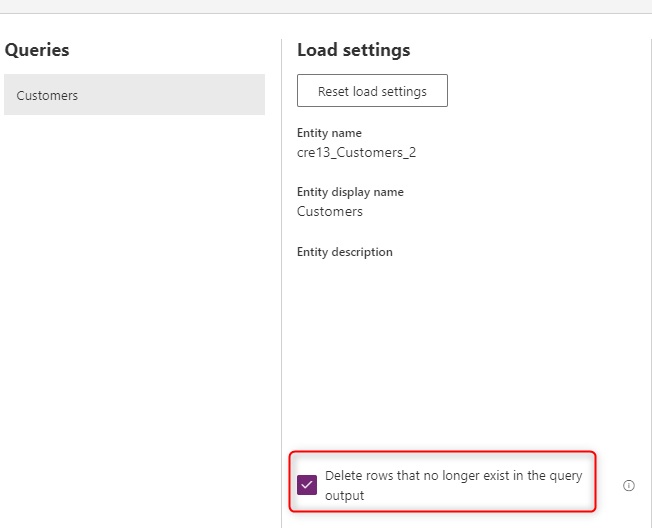
Löschen von Zeilen, die in der Abfrageausgabe nicht mehr vorhanden sind
Der letzte Schritt besteht darin, Zeilen zu löschen, die in der Abfrageausgabe nicht mehr vorhanden sind. Diese Option vergleicht die Daten in der Dataverse-Tabelle mit den Daten, die aus der Quelle stammen, basierend auf dem alternativen Schlüssel (der möglicherweise ein zusammengesetzter Schlüssel ist), und entfernen Sie die Zeilen, die nicht mehr vorhanden sind. Daher werden Ihre Daten in Dataverse immer mit Ihrer Datenquelle synchronisiert.