Definieren des Problems
Beginnend mit dem ersten Schritt möchten Sie das Problem definieren , das das Modell lösen sollte, indem Sie Folgendes verstehen:
- Wie die Ausgabe des Modells aussehen soll.
- Welchen Typ von Machine Learning-Aufgabe Sie verwenden
- Welche Kriterien ein erfolgreiches Modell auszeichnen
Abhängig von den verfügbaren Daten und der erwarteten Ausgabe des Modells können Sie die Machine Learning-Aufgabe identifizieren. Die Aufgabe bestimmt, welche Arten von Algorithmen Sie verwenden können, um das Modell zu trainieren.
Einige gängige Machine Learning-Aufgaben sind:

- Klassifizierung: Vorhersagen eines kategorisierten Werts.
- Regression: Vorhersagen eines numerischen Werts.
- Zeitreihenprognose: Vorhersagen zukünftiger numerischer Werte basierend auf Zeitreihendaten.
- Computervision: Klassifizieren von Bildern oder Erkennen von Objekten in Bildern.
- Verarbeitung natürlicher Sprachen (NLP): Extrahieren von Erkenntnissen aus Text.
Zum Trainieren eines Modells verfügen Sie über eine Reihe von Algorithmen, die Sie je nach auszuführender Aufgabe verwenden können. Zum Auswerten des Modells können Sie Leistungsmetriken wie die Genauigkeit berechnen. Die verfügbaren Metriken hängen auch von der Aufgabe ab, die Ihr Modell ausführen muss, und helfen Ihnen bei der Entscheidung, ob die Aufgabe eines Modells erfolgreich durchgeführt wurde.
Erkunden eines Beispiels
Stellen Sie sich ein Szenario vor, in dem Sie feststellen möchten, ob zu behandelnde Personen an Diabetes leiden. Das Problem, das Sie lösen möchten, und der Typ der verfügbaren Daten bestimmen die Machine Learning-Aufgabe, die Sie auswählen. In diesem Fall handelt es sich bei den verfügbaren Daten um andere Gesundheitsdaten der zu behandelnden Personen. Wir können das gewünschte Ergebnis als kategorische Informationen darstellen, die entweder besagen, dass Diabetes vorliegt oder nicht. Daher ist die Machine Learning-Aufgabe klassifizierung.
Wenn Sie den gesamten Prozess verstehen, bevor Sie beginnen, können Sie die Entscheidungen planen, die Sie treffen müssen, um eine erfolgreiche Machine Learning-Lösung zu entwickeln. Das folgende Diagramm zeigt eine Möglichkeit, das Problem der Identifizierung von Diabetes bei einer Person in Behandlung anzugehen. In dem Diagramm werden die Daten mithilfe spezifischer Algorithmen vorbereitet, aufgeteilt und trainiert. Anschließend wird die Qualität des Modells ausgewertet.
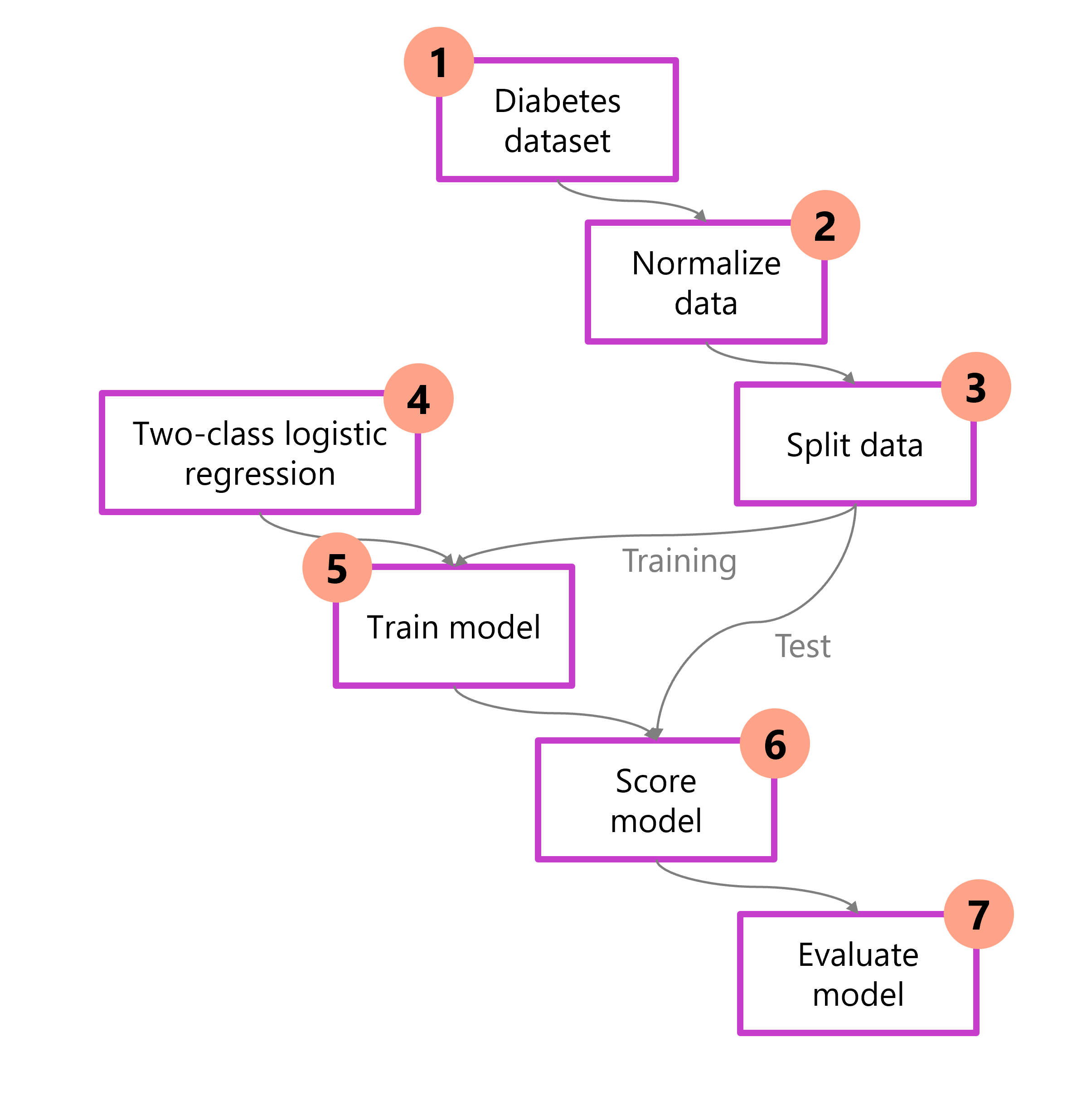
- Laden von Daten: Importieren und Überprüfen des Datasets.
- Daten vorverarbeiten: Normalisieren und bereinigen, um Konsistenz zu gewährleisten.
- Daten teilen: Nehmen Sie eine Aufteilung in Trainings- und Testsätze vor.
- Wählen Sie das Modell aus: Wählen Sie einen Algorithmus aus, und konfigurieren Sie diesen.
- Modell trainieren: Erlernen Sie Muster aus den Schulungsdaten.
- Bewertungsmodell: Generieren von Vorhersagen für Testdaten.
- Auswerten: Berechnen von Leistungsmetriken.
Das Training eines Machine Learning-Modells ist häufig ein iterativer Prozess, bei dem Sie jeden dieser Schritte mehrmals durchlaufen, um das leistungsstärkste Modell zu finden. Als Nächstes untersuchen wir den Datenvorbereitungsprozess für die Entwicklung einer Machine Learning-Lösung.