Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Japan Data Platform Tech Sales Team
高木 英朗
2016年の秋に HDInsight の新しいクラスタータイプとして 「インタラクティブ Hive」 が登場しました。インタラクティブ Hive は Hive 2.0 で追加された LLAP (Long Live and Process) という Hive クエリをより高速にするための仕組みを搭載したものです。これによって、大量のデータをよりインタラクティブに柔軟に分析することが可能になります。本記事の投稿時点 (2017/03/21) ではパブリック プレビュー版が利用可能です。
背景
Hadoop が普及した理由の一つとして、分析担当者がログファイル等の raw data に直接アクセスして分析するようなセルフサービス型を実現することが挙げられますが、そのためには分析担当者が使い慣れた BI ツール等からアクセスし、インタラクティブに試行錯誤できる必要がありました。しかし、当初はバッチ向きで開発されたこともあり大量データを扱うこと自体は得意としていたものの、インタラクティブな分析を行うには不向きな点もありました。
そこで、インタラクティブな分析ニーズにも応えるために、今回ご紹介する Hive/Tez + LLAP のアプローチや、Impala、Presto、Drill などが登場しました。
現在の Hive は Tez や Cost-Based-Optimizer(CBO) や Vectorized Query Execution などによって非常に高速化されています。さらにインタラクティブ分析へのニーズにこたえていくために、これまでの仕組みと組み合わせてより高速化できる LLAP が登場しました。LLAP は Hive 実行時のオーバーヘッド排除やインメモリキャッシュ等でさらに高速化させることができ、Hadoop でのスタンダードな Hive クエリを使ったまま、インタラクティブな分析を実現することができるようになります。
LLAP の概要
LLAP は Hive 2.0 で追加された機能で、Hive/Tez をさらにインタラクティブに実行できるようにするための仕組みです。LLAP は Apache Slider (YARN 上にアプリケーションをデプロイする仕組み) 経由で YARN 環境のうえに Daemon を常時起動し、キャッシュ、複数クエリ実行、アクセス制御等の機能を実行します。Daemon として常時起動させておくことによって、Hive/Tez クエリ実行時のオーバーヘッドを取り払います。Daemon は実データとメタデータをキャッシュしますが、メタデータは Java オブジェクトのプロセス内に保存され、実データはカラム型フォーマットでヒープ外に保存されます。このようにして Daemon 自体は少ないメモリ利用で動作させることができます。キャッシュの使用効率を高めるため、LRFU(Least Recency / Frequency Used) アルゴリズムなどを採用しテーブルスキャンの頻度等によってキャッシュのエビクション ポリシーは調整されます。このポリシーはプラガブルなので変更することができます。
LLAP は既存の実行エンジンを置き換えるものではなく、改善するための位置づけです。Hive は LLAP がデプロイされていてもバイパスして実行することも可能です。
LLAP のアーキテクチャの概要やベンチマークテスト結果については Hortonworks 社のこちらの記事にまとめられています。現在の Hive が非常に高速であることが分かりますので是非一度ご参照ください。
インタラクティブ Hive (LLAP) on HDInsight
現在 HDInsight の新しいクラスタータイプとして インタラクティブ Hive が追加されており、上記でご紹介した LLAP 等のテクノロジーによって高速化した Hive クエリを利用することができます。
HDInsight のデプロイ方法については過去の記事「Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (1)」をご参照ください。インタラクティブ Hive のデプロイ方法の異なる部分は「クラスター構成」において、クラスターの種類を「インタラクティブ Hive (プレビュー)」を選択する部分です。
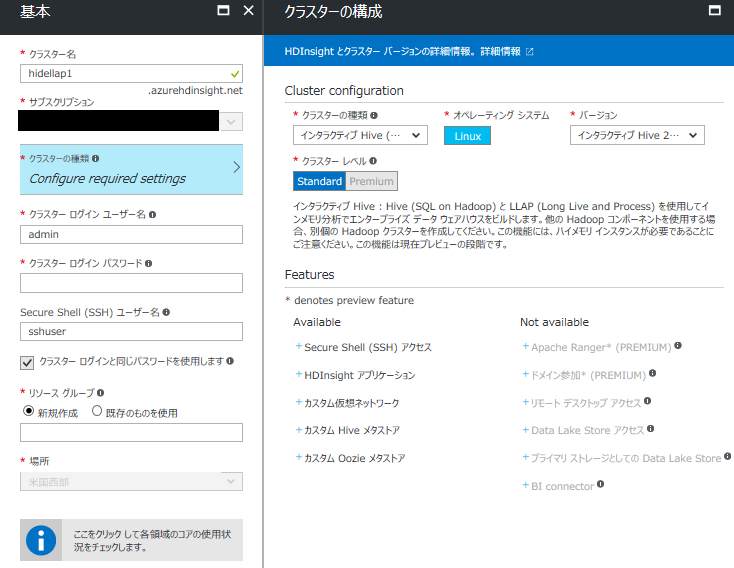
デプロイ完了後、インタラクティブ Hiveは以下の方法で実行することができます。
※Hiveコンソール等のその他ツールからは現在アクセスすることができません。
ODBC 経由で Power BI 等の様々な BI ツールからアクセスすることもできます。Hive ODBC Driver についてはこちらをご参照ください。 ので、是非お試しいただければと思います。
関連記事
- Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (1)
- Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (2)
- HDInsight にデータを取り込む方法
- [Microsoft Tech Summit (11/1-2) ] (DAT011) “HDInsight + Spark + R を活用した機械学習のためのスケーラブルなビッグデータ分析基盤” セッションフォローアップ
- Apache kafka on HDInsight (public preview) (1)
- Apache kafka on HDInsight (public preview) (2)
- Apache Spark on Azure をビジネス価値につなげる 8 つのシナリオ(1)