Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure DevOps Services proporciona herramientas de colaboración para el desarrollo, como canalizaciones de alto rendimiento, repositorios de Git privados gratuitos, paneles Kanban configurables y amplias capacidades de pruebas automatizadas y continuas. Azure Pipelines es una capacidad de Azure DevOps que permite administrar CI/CD para implementar el código con las canalizaciones de alto rendimiento que funcionan con cualquier lenguaje, plataforma y nube. Azure Data Explorer: Herramientas de canalización es la tarea de Azure Pipelines que le permite crear canalizaciones de versión e implementar cambios en sus bases de datos de Azure Data Explorer. Está disponible de forma gratuita en Visual Studio Marketplace. La extensión incluye las siguientes tareas básicas:
Comando de Azure Data Explorer: ejecución de comandos de administrador en un clúster de Azure Data Explorer
Consulta de Azure Data Explorer: ejecución de consultas en un clúster de Azure Data Explorer y análisis de los resultados
Puerta del servidor de consultas de Azure Data Explorer: tarea sin agente para controlar las publicaciones según el resultado de la consulta
En este documento se describe un ejemplo sencillo del uso de la tarea Herramientas de canalización de Azure Data Explorer para implementar cambios de esquema en la base de datos. Para obtener información sobre las canalizaciones de CI/CD completas, consulte la documentación de Azure DevOps.
Requisitos previos
- Suscripción a Azure. Cree una cuenta de Azure gratuita.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
- Configuración del clúster de Azure Data Explorer:
- Cree una aplicación de Microsoft Entra aprovisionar una aplicación de Microsoft Entra.
- Conceda acceso a la aplicación De Microsoft Entra en la base de datos de Azure Data Explorer mediante administración de permisos de base de datos de Azure Data Explorer.
- Instalación de Azure DevOps:
- Instalación de la extensión:
Si es el propietario de la instancia de Azure DevOps, instale la extensión desde Marketplace, de lo contrario, póngase en contacto con la instancia de Azure DevOps propietario y pídale que lo instale.


Preparación del contenido para la publicación
Puede usar los métodos siguientes para ejecutar comandos de administrador en un clúster dentro de una tarea:

Use un patrón de búsqueda para obtener varios archivos de comandos de una carpeta del agente local (orígenes de compilación o artefactos de versión).

Escribir comandos en línea.
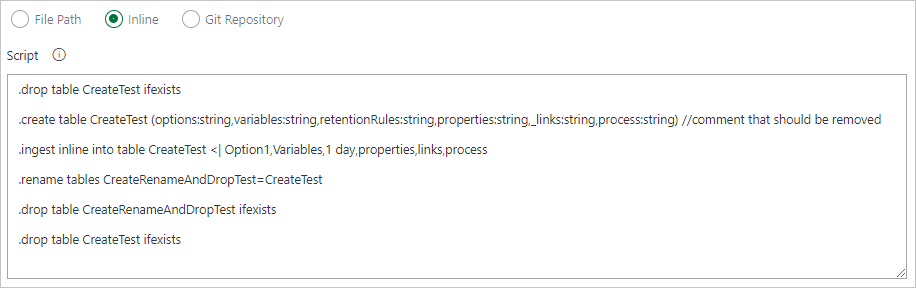
Especifique una ruta de acceso de archivo para obtener archivos de comandos directamente desde el control de código fuente de Git (recomendado).

Cree las siguientes carpetas de ejemplo (Funciones, Directivas y Tablas) en el repositorio de Git. Copie los archivos del repositorio de ejemplos en las carpetas respectivas y confirme los cambios. Los archivos de ejemplo se proporcionan para ejecutar el siguiente flujo de trabajo.
Sugerencia
Al crear su propio flujo de trabajo, le recomendamos que haga su código idempotente. Por ejemplo, use
.create-merge tableen lugar de.create tabley use la.create-or-alterfunción en lugar de la.createfunción .
Crear una canalización de versión
Inicie sesión en su organización de Azure DevOps.
Seleccione Lanzamientos de canalizaciones> en el menú izquierdo y, a continuación, seleccione Nueva canalización.

Se abrirá la ventana Nueva canalización de versión. En la pestaña Canalizaciones, en el panel Seleccionar una plantilla, elija Empty job (Trabajo vacío).

Seleccione el botón Etapa. En el panel Fase , agregue el nombre de la fase y, a continuación, seleccione Guardar para guardar la canalización.
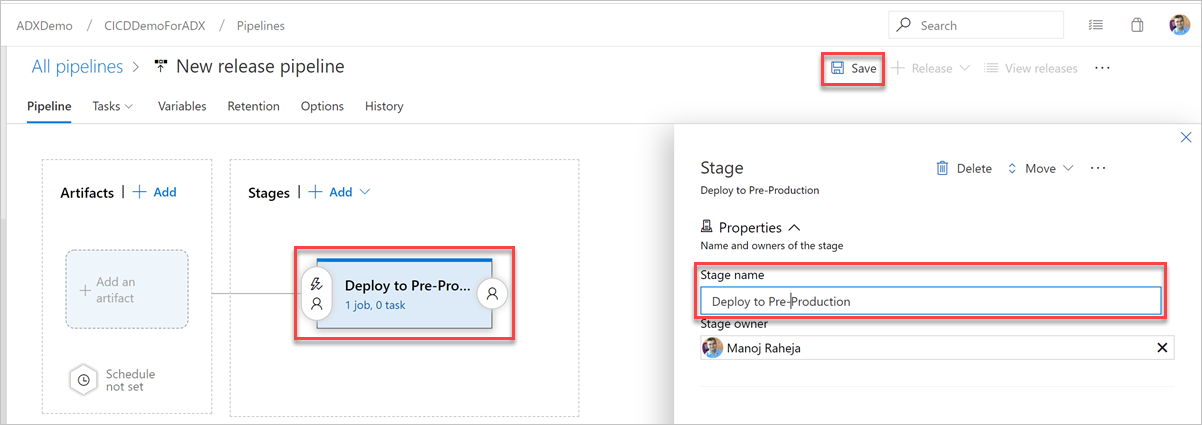
Seleccione el botón Agregar un artefacto. En el panel Agregar un artefacto, seleccione el repositorio donde existe el código, rellene la información pertinente y seleccione Agregar. Seleccione Guardar para guardar la canalización.

En la pestaña Variables , seleccione + Agregar para crear una variable para la dirección URL del punto de conexión que se usa en la tarea. Escriba el nombre y el valor del punto de conexión y, a continuación, seleccione Guardar para guardar la canalización.
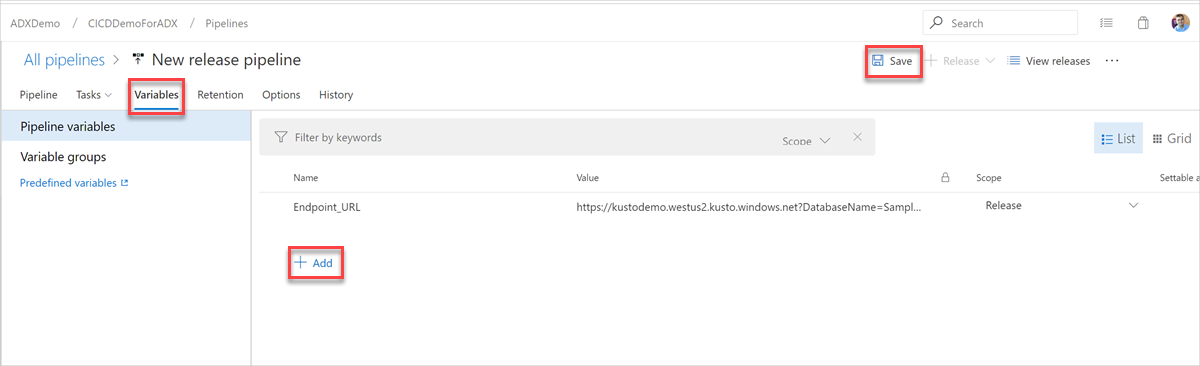
Para buscar la dirección URL del punto de conexión, vaya a la página de información general del clúster de Azure Data Explorer en Azure Portal y copie el URI del clúster. Construya el URI de variable en el formato siguiente
https://<ClusterURI>?DatabaseName=<DBName>. Por ejemplo: https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB
Creación de una tarea para implementar las carpetas
En la pestaña Canalización, seleccione 1 trabajo, 0 tareas para agregar tareas.
Repita los pasos siguientes para crear tareas de comando para implementar archivos desde las carpetas Tables, Functions y Policies:
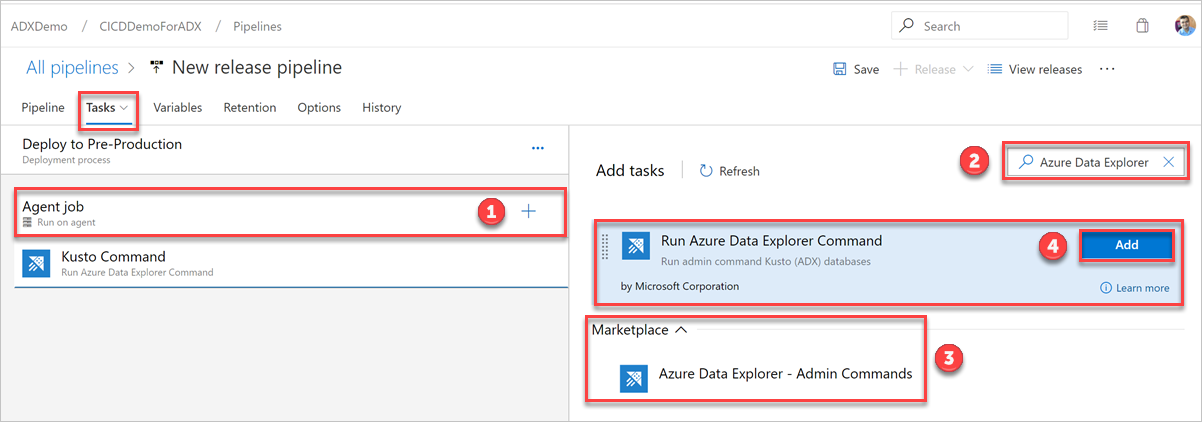
En la pestaña Tareas, seleccione + al lado de Trabajo de agente y busque Azure Data Explorer.
En Run Azure Data Explorer Command (Ejecutar comando de Azure Data Explorer), seleccione Agregar.
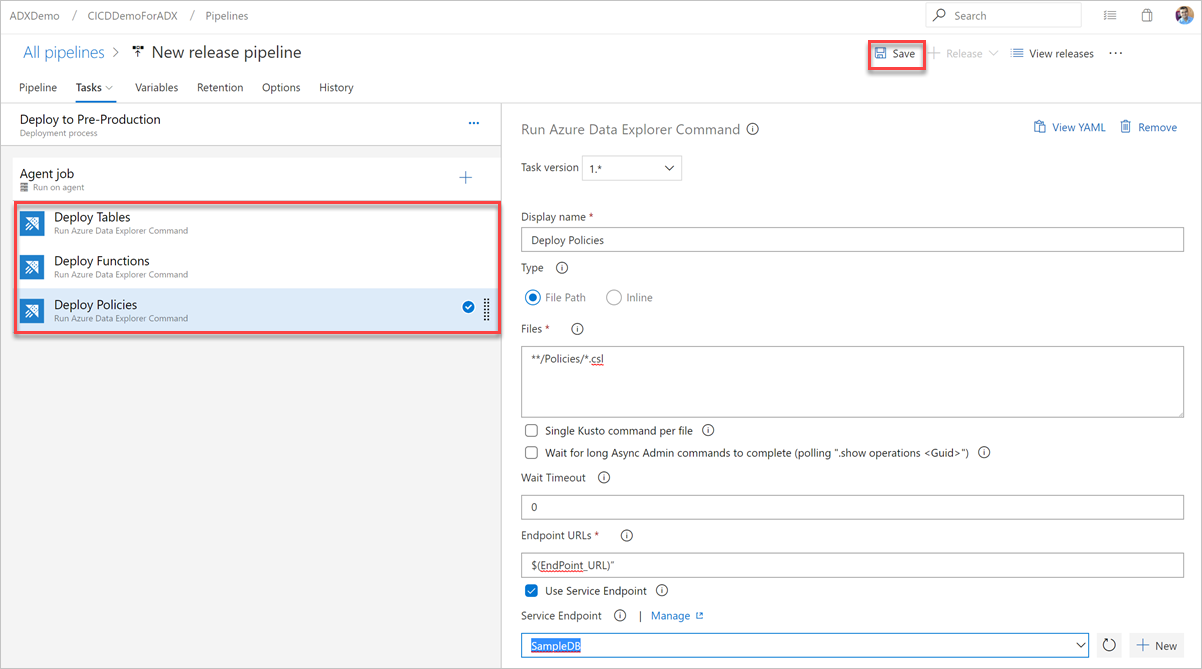
Seleccione Kusto Command (Comando Kusto) y actualice la tarea con la siguiente información:
Nombre para mostrar: nombre de la tarea. Por ejemplo,
Deploy <FOLDER>donde<FOLDER>es el nombre de la carpeta de la tarea de implementación que va a crear.Ruta de acceso del archivo: para cada carpeta, especifique la ruta de acceso como, por ejemplo,
*/<FOLDER>/*.csldonde<FOLDER>es la carpeta pertinente para la tarea.Dirección URL del punto de conexión: especifique la variable
EndPoint URLcreada en el paso anterior.Use Service Endpoint (Usar punto de conexión de servicio): seleccione esta opción.
Punto de conexión de servicio: seleccione un punto de conexión de servicio existente o cree uno nuevo (+ Nuevo) que proporcione la siguiente información en la ventana Add Azure Data Explorer service connection (Agregar conexión del servicio de Azure Data Explorer):
Configuración Valor sugerido Método de autenticación Configurar credenciales de identidad federada (FIC) (recomendado) o Seleccionar autenticación de entidad de servicio (SPA). Nombre de la conexión Escriba un nombre para identificar este punto de conexión de servicio. URL de clúster El valor se puede encontrar en la sección de información general del clúster de Azure Data Explorer en Azure Portal. Id. de entidad de servicio Escriba el identificador de aplicación de Microsoft Entra (creado como requisito previo) Service Principal App Key (Clave de la aplicación de entidad de servicio) Escriba la clave de aplicación de Microsoft Entra (creada como requisito previo) Identificador de inquilino de Microsoft Entra Escriba el inquilino de Microsoft Entra (por ejemplo, microsoft.com o contoso.com)
Seleccione la casilla Permita que todas las canalizaciones usen esta conexión y, después, Aceptar.

Seleccione Guardar y, a continuación, en la pestaña Tareas , compruebe que hay tres tareas: Implementar tablas, Implementar funciones e Implementar directivas.
Creación de una tarea de consulta
Si es necesario, cree una tarea para ejecutar una consulta en el clúster. La ejecución de consultas en una canalización de compilación o versión se puede usar para validar un conjunto de datos y tener un paso correcto o un error en función de los resultados de la consulta. Los criterios de éxito de las tareas se pueden basar en un umbral de recuento de filas o un valor único en función de lo que devuelva la consulta.
En la pestaña Tareas, seleccione + al lado de Trabajo de agente y busque Azure Data Explorer.
En Run Azure Data Explorer Query (Ejecutar consulta de Azure Data Explorer), seleccione Agregar.
Seleccione Kusto Query (Consulta de Kusto) y actualice la tarea con la siguiente información:
- Nombre para mostrar: nombre de la tarea. Por ejemplo, Consulta del clúster.
- Tipo: seleccione Insertada.
- Consulta: escriba la consulta que desea ejecutar.
-
Dirección URL del punto de conexión: especifique la variable
EndPoint URLcreada anteriormente. - Use Service Endpoint (Usar punto de conexión de servicio): seleccione esta opción.
- Punto de conexión de servicio: seleccione un punto de conexión de servicio.
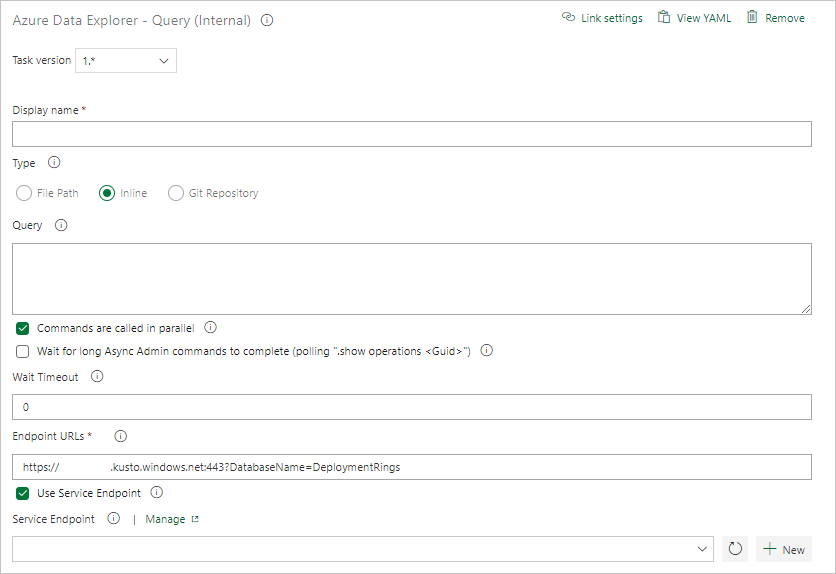
En Resultados de la tarea, seleccione los criterios de éxito de la tarea en función de los resultados de la consulta, como se muestra a continuación:
Si la consulta devuelve filas, seleccione Número de filas y proporcione los criterios que necesita.
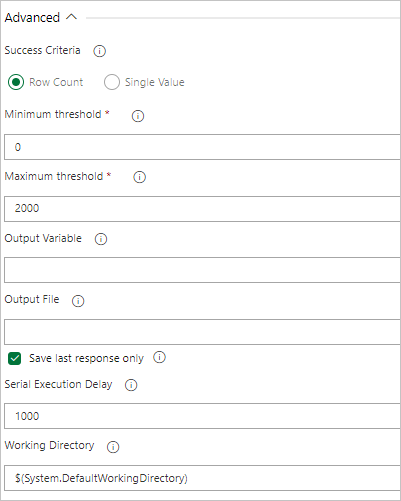
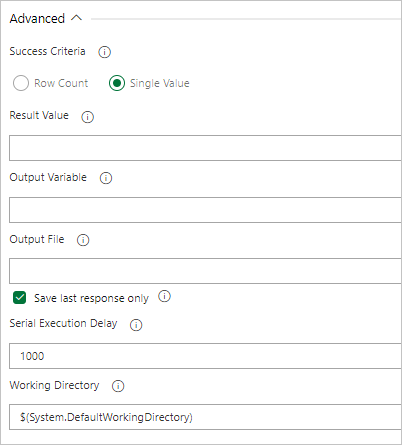
Si la consulta devuelve un valor, seleccione Valor único y proporcione el resultado esperado.
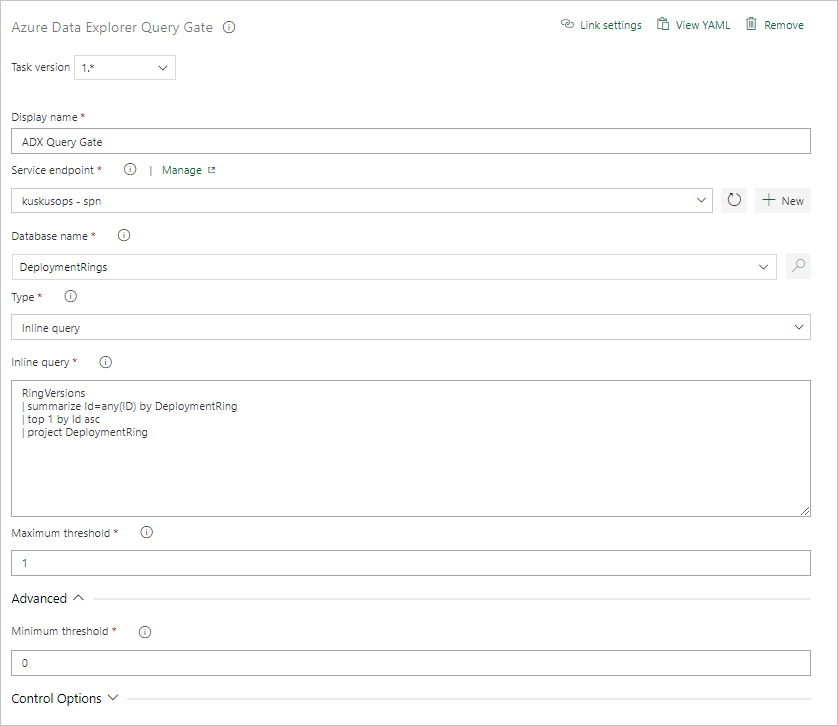
Creación de una tarea de puerta del servidor de consultas
Si es necesario, cree una tarea para ejecutar una consulta en un clúster y compuerta el progreso de la versión pendiente de recuento de filas de resultados de la consulta. La tarea de puerta del servidor de consultas es un trabajo sin agente, lo que significa que la consulta se ejecuta directamente en Azure DevOps Server.
En la pestaña Tareas, seleccione + al lado de Trabajo sin agente y busque Azure Data Explorer.
En Run Azure Data Explorer Query Server Gate (Ejecutar puerta del servidor de consultas de Azure Data Explorer), seleccione Agregar.
Seleccione Kusto Query Server Gate (Puerta del servidor de consultas de Kusto) y, a continuación, seleccione Server Gate Test (Prueba de puerta de servidor).

Para configurar la tarea, proporcione la información siguiente:
- Nombre para mostrar: nombre de la puerta.
- Punto de conexión de servicio: seleccione un punto de conexión de servicio.
- Nombre de la base de datos: especifique el nombre de la base de datos.
- Tipo: seleccione Inline query (Consulta insertada).
- Consulta: escriba la consulta que desea ejecutar.
- Umbral máximo: especifique el número máximo de filas para los criterios de éxito de la consulta.
Nota:
Debería ver unos resultados como los siguientes al ejecutar la versión.
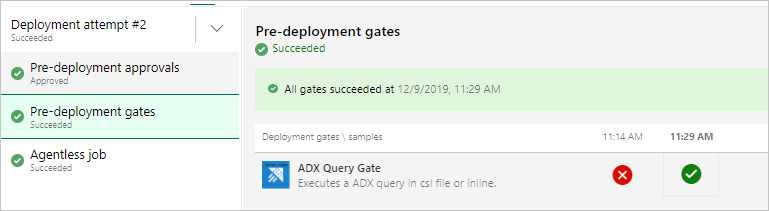
Ejecución de la versión
Seleccione + Publicar>Crear publicación para iniciar una publicación.
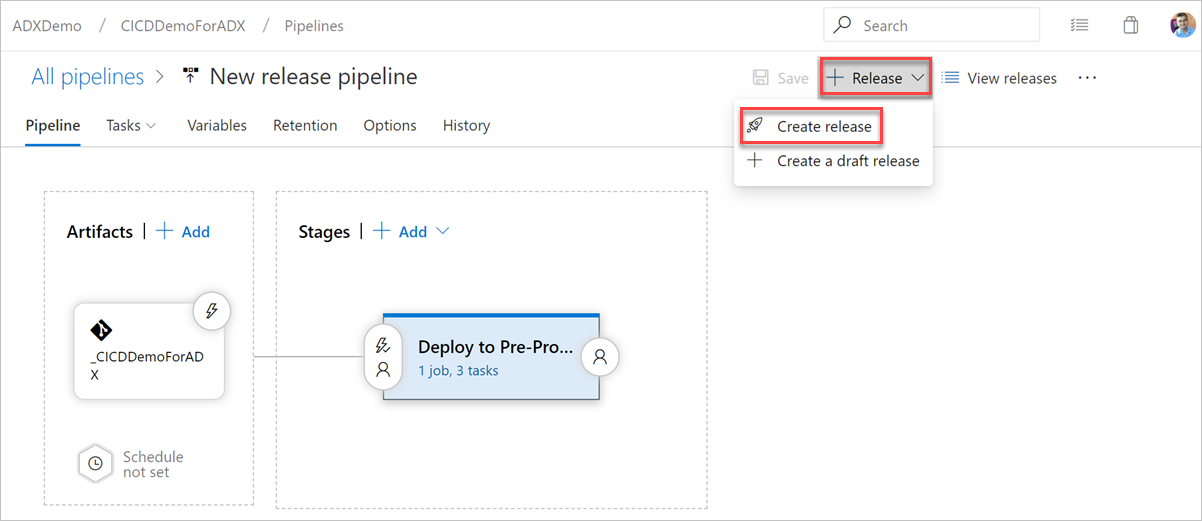
En la pestaña Registros, compruebe si el estado de implementación es correcto.
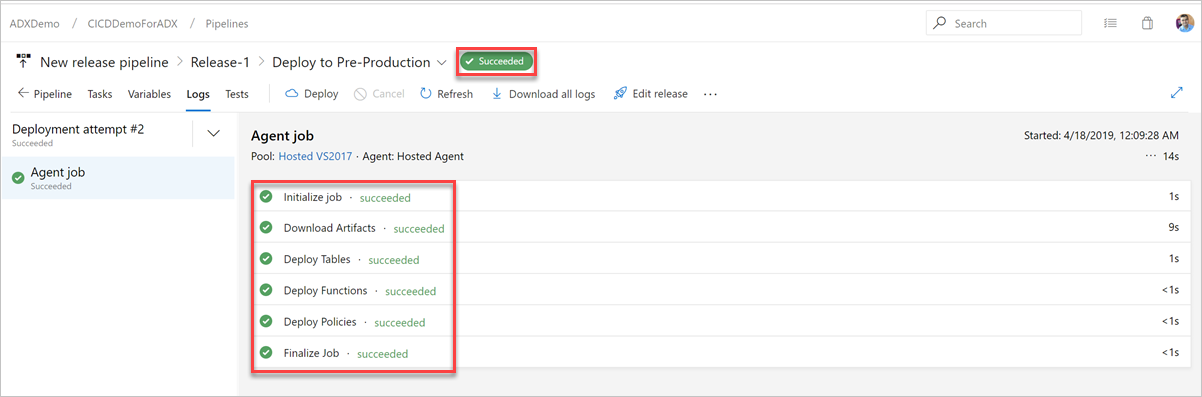
Ahora se ha completado la creación de una canalización de versión para la implementación en la preproducción.
Compatibilidad con la autenticación sin claves para las tareas de DevOps de Azure Data Explorer
La extensión admite la autenticación sin claves para clústeres de Azure Data Explorer. La autenticación sin claves le permite autenticarse en clústeres de Azure Data Explorer sin usar una clave. Es más seguro y fácil de administrar.
Uso de la autenticación de credenciales de identidad federada (FIC) en una conexión de servicio de Azure Data Explorer
En la instancia de DevOps, vaya a Configuración del proyecto>Conexiones de servicio>Nueva conexión de servicio>Azure Data Explorer.
Seleccione Credenciales de identidad federada, y escriba la dirección URL del clúster, el identificador de entidad de servicio, el identificador de inquilino, un nombre de conexión de servicio y a continuación, seleccione Guardar.
En Azure Portal, abra la aplicación Microsoft Entra para la entidad de servicio especificada.
En Certificados y secretos, seleccione Credenciales federadas.
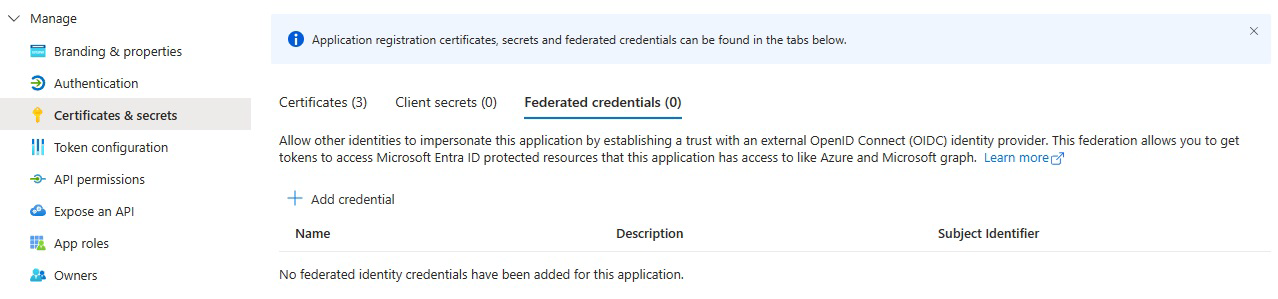
Seleccione Agregar credencial y después, para Escenario de credenciales federadas, seleccione Otro emisor, y rellene la configuración con la siguiente información:
Emisor:
<https://vstoken.dev.azure.com/{System.CollectionId}>donde{System.CollectionId}es el identificador de colección de la organización de Azure DevOps. Puede encontrar el identificador de colección de las maneras siguientes:- En la canalización de versión clásica de Azure DevOps, seleccione Inicializar trabajo. El identificador de colección se muestra en los registros.
Identificador del firmante:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>donde{DevOps_Org_name}es el nombre de la organización de Azure DevOps,{Project_Name}es el nombre del proyecto y{Service_Connection_Name}es el nombre de la conexión de servicio que creó anteriormente.Nota:
Si hay un espacio en el nombre de su conexión de servicio, puede usarlo con el espacio en el campo. Por ejemplo:
sc://MyOrg/MyProject/My Service Connection.Nombre: escriba un nombre para la credencial.
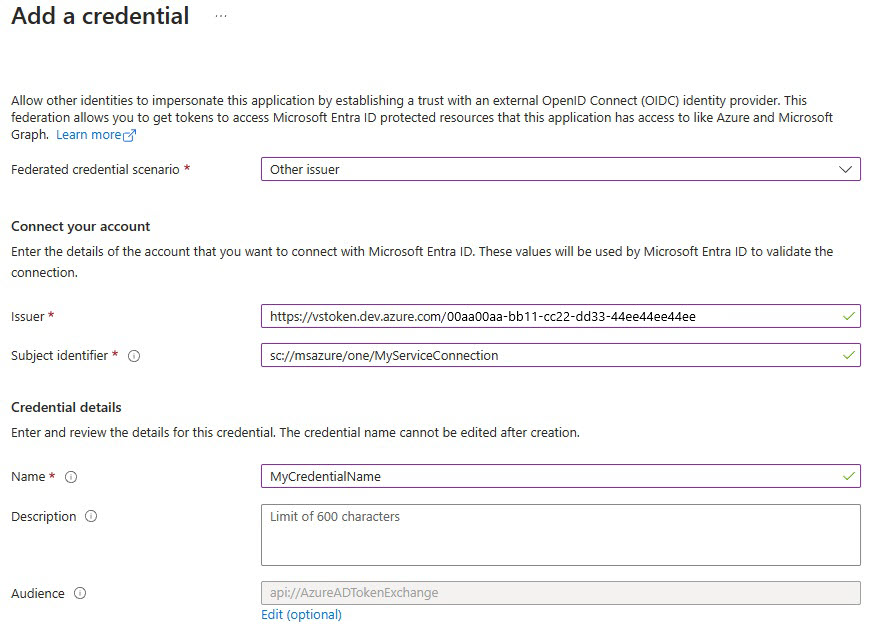
Seleccione Agregar.
Uso de credenciales de identidad federada o identidad administrada en una conexión de servicio de Azure Resource Manager (ARM)
En la instancia de DevOps, vaya a Configuración del proyecto>Conexiones de servicio>Nueva conexión de servicio>Azure Resource Manager.
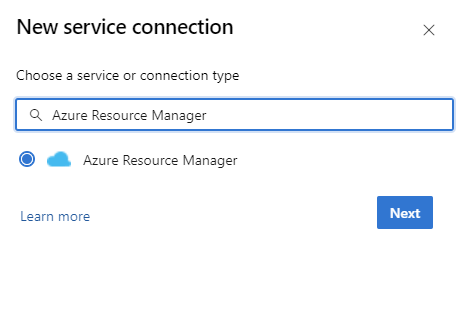
En Método de autenticación, seleccione Federación de identidad de carga de trabajo (automática) para continuar. También puede usar la opción manual de federación de identidad de la carga de trabajo (manual) para especificar los detalles de la federación de identidad de la carga de trabajo o la opción Identidad administrada. Obtenga más información sobre cómo configurar una identidad administrada mediante Azure Resource Management en conexiones de servicio de Azure Resource Manager (ARM).
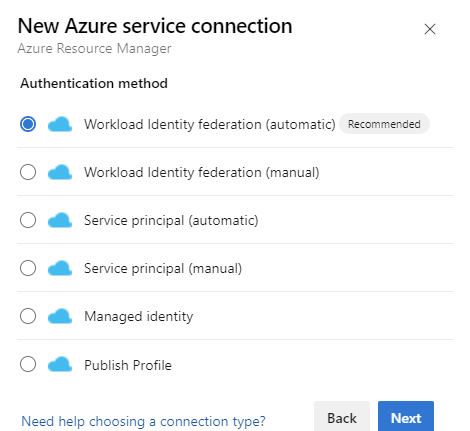
Rellene los detalles necesarios, seleccione Comprobar, y a continuación, seleccione Guardar.
Configuración de canalización de YAML
Puede configurar tareas mediante la interfaz de usuario web de Azure DevOps o el código YAML dentro del esquema de canalización.
Ejemplo de comando de administrador
steps:
- task: Azure-Kusto.PublishToADX.PublishToADX.PublishToADX@4
displayName: '<Task Name>'
inputs:
targetType: 'inline'
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
authType: 'armserviceconn'
connectedServiceARM: '<ARM Service Endpoint Name>'
serialDelay: 1000
`continueOnError: true`
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Ejemplo de consulta
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@4
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DatabaseName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true