Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se explica cómo crear un recurso de cómputo asignado a un grupo utilizando el modo de acceso dedicado.
El modo de acceso de grupo dedicado permite a los usuarios obtener la eficacia operativa de un clúster de modo de acceso estándar, a la vez que admite de forma segura idiomas y cargas de trabajo que no son compatibles con el modo de acceso estándar, como Databricks Runtime para ML, API de RDD y R.
Requisitos
Para usar el modo de acceso de grupo dedicado:
- El área de trabajo debe estar habilitada para el catálogo de Unity.
- Debe usar Databricks Runtime 15.4 o superior.
- El grupo asignado debe tener permisos
CAN MANAGEen una carpeta del área de trabajo donde pueden mantener cuadernos, experimentos de ML y otros artefactos de área de trabajo usados por el clúster de grupo.
¿Qué es el modo de acceso dedicado?
El modo de acceso dedicado es la versión más reciente del modo de acceso de usuario único. Con el acceso dedicado, se puede asignar un recurso de proceso a un solo usuario o grupo, solo permitiendo el acceso de los usuarios asignados para usar el recurso de proceso.
Cuando un usuario está conectado a un recurso de proceso dedicado a un grupo (un clúster de grupos), los permisos del usuario se reducen automáticamente a los permisos del grupo, lo que permite al usuario compartir de forma segura el recurso con los demás miembros del grupo.
Crea un recurso de cálculo dedicado a un grupo
- En el área de trabajo de Azure Databricks, vaya a Proceso y haga clic en Crear proceso.
- Expanda la sección Avanzado.
- En el Modo de acceso, haz clic en Manual y, después, selecciona Dedicado (anteriormente: Usuario Único) en el menú desplegable.
- En el campo usuario único o grupo, seleccione el grupo que desea asignar a este recurso.
- Configure las demás opciones de proceso deseadas y, a continuación, haga clic en Crear.
Procedimientos recomendados para administrar clústeres de grupos
Dado que los permisos de usuario se limitan al grupo al usar clústeres de grupo, Databricks recomienda crear una carpeta de /Workspace/Groups/<groupName> para cada grupo que planea usar con un clúster de grupos. A continuación, asigne permisos CAN MANAGE en la carpeta al grupo. Esto permite a los grupos evitar errores de permisos. Todos los cuadernos y recursos del área de trabajo del grupo deben administrarse en la carpeta del grupo.
También debe modificar las siguientes cargas de trabajo para que se ejecuten en clústeres de grupo:
- MLflow: asegúrese de ejecutar el cuaderno desde la carpeta de grupo o ejecutar
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>"). - AutoML: establezca el parámetro opcional
experiment_diren“/Workspace/Groups/<groupName>”para las ejecuciones de AutoML. -
dbutils.notebook.run: asegúrese de que el grupo tiene el permisoREADen el cuaderno que se está ejecutando.
Comportamiento de permisos en clústeres de grupo
Todos los comandos, consultas y otras acciones realizadas en un clúster de grupo usan los permisos asignados al grupo, no al usuario individual.
No se pueden aplicar permisos de usuario individuales porque todos los miembros del grupo tienen acceso total a las API de Spark y al entorno de proceso compartido. Si se aplicaron permisos basados en el usuario, un miembro podría consultar datos restringidos y otro miembro sin acceso podría recuperar los resultados a través del entorno compartido. Por lo tanto, el propio grupo, no el usuario que es miembro del grupo, debe tener los permisos necesarios para realizar correctamente la acción.
Por ejemplo, el grupo necesita permiso explícito para consultar una tabla, acceder a un ámbito de secretos o a un secreto, usar una credencial de conexión de Unity Catalog, acceder a una carpeta de Git o crear un objeto de área de trabajo.
Permisos de grupo de ejemplo
Al crear un objeto de datos mediante el clúster de grupo, el grupo se asigna como propietario del objeto.
Por ejemplo, si tiene un cuaderno asociado a un clúster de grupo y ejecuta el siguiente comando:
use catalog main;
create schema group_cluster_group_schema;
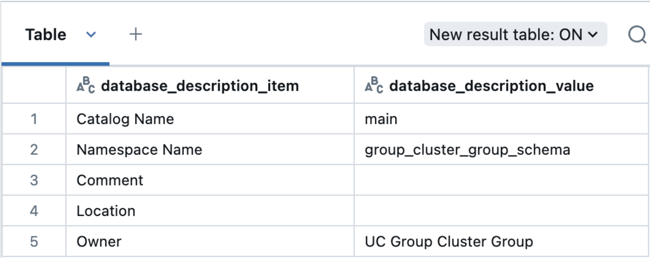
A continuación, ejecute esta consulta para comprobar el propietario del esquema:
describe schema group_cluster_group_schema;
Auditoría de la actividad de proceso dedicada del grupo
Hay dos identidades clave implicadas cuando un clúster de grupo ejecuta una carga de trabajo:
- Usuario que ejecuta la carga de trabajo en el clúster de grupo
- El grupo cuyos permisos se usan para realizar las acciones de carga de trabajo reales.
La tabla del sistema de registro de auditoría registra estas identidades en los parámetros siguientes:
-
identity_metadata.run_by: el usuario autenticador que realiza la acción -
identity_metadata.run_as: el grupo autorizador cuyos permisos se emplean para la acción.
La consulta de ejemplo siguiente extrae los metadatos de identidad de una acción realizada con el clúster de grupo:
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
Vea la referencia de la tabla del sistema de registro de auditoría para obtener más consultas de ejemplo. Consulte la referencia de la tabla del sistema de registro de auditoría .
Limitaciones conocidas
El acceso de grupo dedicado tiene las siguientes limitaciones:
- No se puede asignar acceso a grupos a los trabajos creados mediante la API y el SDK. Esto se debe a que el parámetro del
run_astrabajo solo admite un único usuario o principal de servicio. - Se producirá un error en los trabajos que usan Git porque el directorio temporal que usa el trabajo para desagrupar el repositorio de Git no se puede escribir. Use carpetas de Git en su lugar.
- Las tablas del sistema de linaje no registran el
identity_metadata.run_as(el grupo de autorización) oidentity_metadata.run_by(el usuario de autenticación) para las cargas de trabajo que se ejecutan en un clúster de grupo. - Los registros de auditoría entregados al almacenamiento del cliente no registran el
identity_metadata.run_as(el grupo de autorización) niidentity_metadata.run_by(el usuario autenticado) para las cargas de trabajo que se ejecutan en un clúster de grupo. Debe usar la tablasystem.access.auditpara ver los metadatos de identidad. - Cuando se adjunta a un clúster de grupo, el Explorador de catálogos no filtra solo por recursos accesibles para el grupo.
- Los administradores de grupos que no son miembros del grupo no pueden crear, editar ni eliminar clústeres de grupos. Solo los administradores del área de trabajo y los miembros del grupo pueden hacerlo.
- Si se cambia el nombre de un grupo, debe actualizar manualmente las directivas de proceso que hagan referencia al nombre del grupo.
- Los clústeres de grupo no se admiten para áreas de trabajo con ACL deshabilitadas (isWorkspaceAclsEnabled == false) debido a la falta inherente de controles de seguridad y acceso a datos cuando se deshabilitan las ACL del área de trabajo.
- El
%runcomando y otras acciones ejecutadas en el contexto del cuaderno siempre usan los permisos del usuario en lugar de los permisos del grupo. Esto se debe a que el entorno del cuaderno controla estas acciones, no el entorno del clúster. Los comandos alternativos comodbutils.notebook.run()se ejecutan en el clúster y, por tanto, usan los permisos del grupo. - La función
is_member(<group>)devuelvefalsecuando se invoca sobre un clúster de grupo porque el grupo no es miembro de sí mismo. Para comprobar correctamente la pertenencia tanto en los clústeres de grupo como en otros modos de acceso, useis_member(<group>) OR current_user() == <group>. - No se admite la creación ni el acceso a los puntos de conexión de servicio del modelo.
- No se admite la creación y el acceso a los puntos de conexión o índices de búsqueda vectorial.
- No se admite la eliminación de archivos y carpetas en clústeres de grupos.
- La interfaz de usuario de carga de archivos no admite clústeres de grupos.