Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se proporciona información general sobre la búsqueda de vectores de Mosaic A, incluyendo qué es y cómo funciona.
¿Qué es Vector de búsqueda de Mosaic AI?
Mosaic AI Vector Search es una solución de búsqueda vectorial integrada en databricks Data Intelligence Platform e integrada con sus herramientas de gobernanza y productividad. La búsqueda vectorial es un tipo de búsqueda optimizada para recuperar incrustaciones. Las incrustaciones son representaciones matemáticas del contenido semántico de los datos, normalmente datos de texto o imagen. Las incrustaciones se generan mediante un modelo de lenguaje grande y son un componente clave de muchas aplicaciones de IA generativas que dependen de buscar documentos o imágenes similares entre sí. Algunos ejemplos son los sistemas RAG, los sistemas recomendados y el reconocimiento de imágenes y vídeos.
Con el vector de búsqueda de Mosaic AI, se crea un índice de vector de búsqueda a partir de una tabla Delta. El índice incluye datos incrustados con metadatos. A continuación, puede consultar el índice mediante una API de REST para identificar los vectores más similares y devolver los documentos asociados. Puede estructurar el índice para que se sincronice automáticamente cuando se actualice la tabla Delta subyacente.
Mosaic AI Vector Search admite lo siguiente:
- Búsqueda de similitud de palabras clave híbrida.
- Filtrado.
- Reranking.
- Listas de control de acceso (ACL) para administrar puntos de conexión de vector de búsqueda.
- Sincronice solo las columnas seleccionadas.
- Guarde y sincronice las incrustaciones generadas.
¿Cómo funciona Mosaic AI Vector Search?
La búsqueda vectorial de IA de mosaico usa el algoritmo Jerárquico de pequeños mundos navegables (HNSW) para sus búsquedas de vecinos más cercanos (ANN) y la métrica de distancia L2 para medir la similitud de vectores de inserción. Si desea usar la similitud de coseno, debe normalizar las incrustaciones de puntos de datos antes de alimentarlas en el vector de búsqueda. Cuando se normalizan los puntos de datos, la clasificación producida por la distancia L2 es la misma que la clasificación produce la similitud de coseno.
La búsqueda vectorial de Mosaic AI también admite la búsqueda híbrida de similitud de palabras clave, que combina la búsqueda de incrustaciones basada en vectores con técnicas tradicionales de búsqueda basadas en palabras clave. Este enfoque coincide con las palabras exactas de la consulta, mientras que también usa una búsqueda de similitud basada en vectores para capturar las relaciones semánticas y el contexto de la consulta.
Al integrar estas dos técnicas, la búsqueda de similitud de palabras clave híbrida recuperará documentos que contengan no solo las palabras clave exactas, sino también las que sean conceptualmente similares, proporcionando resultados de búsqueda más completos y relevantes. Este método resulta especialmente útil en aplicaciones RAG en las que los datos de origen tengan palabras clave únicas, como SKU o identificadores que no sean adecuados para la búsqueda de similitud pura.
Para más información sobre la API, consulte la referencia del SDK de Python y Consulta de un índice de búsqueda vectorial.
Cálculo de búsqueda de similitud
El cálculo de la búsqueda de similitud usa la siguiente fórmula:

donde dist es la distancia euclidiana entre la consulta q y la entrada del índice x:

Algoritmo de búsqueda de palabras clave
Las puntuaciones de relevancia se calculan mediante Okapi BM25. Se buscan todas las columnas de texto o cadena, incluyendo la inserción de texto de origen y las columnas de metadatos en formato de texto o cadena. La función de tokenización divide en límites de palabras, quita la puntuación y convierte todo el texto en minúsculas.
Cómo se combinan la búsqueda de similitud y la búsqueda de palabras clave
Los resultados de búsqueda de similitud y búsqueda de palabras clave se combinan mediante la función Fusión de clasificación recíproca (RRF).
RRF primero reevalúa cada documento de cada método mediante las puntuaciones:


rrf_param controla la importancia relativa de los documentos de clasificación superior e inferior. Según la literatura, rrf_param se establece en 60.
Las puntuaciones se normalizan para que la puntuación más alta posible sea 1 mediante el siguiente factor de normalización:
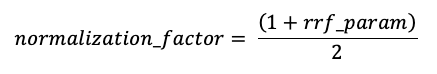
La puntuación final de cada documento se calcula de la siguiente manera:

Se devuelven los documentos con las puntuaciones finales más altas.
Opciones para proporcionar incrustaciones de vectores
Para crear un índice de búsqueda vectorial en Databricks, primero debe decidir cómo proporcionar incrustaciones de vectores. Databricks admite tres opciones.
Opción 1: Delta Sync Index con embeddings calculados por Databricks
Con esta opción, se proporciona una tabla Delta de origen que contiene datos en formato de texto. Databricks calcula las inserciones, con un modelo que usted especifique y, opcionalmente, guarda las inserciones en una tabla de Unity Catalog. A medida que se actualiza la tabla Delta, el índice permanece sincronizado con la tabla Delta.
En el siguiente diagrama se ilustra este proceso:
- Calcule las inserciones de consultas. La consulta puede incluir filtros de metadatos.
- Realice una búsqueda de similitud para identificar los documentos más relevantes.
- Devuelva los documentos más relevantes y anéxelos a la consulta.

Opción 2: Índice de sincronización diferencial con incrustaciones autoadministradas
Con esta opción, se proporciona una tabla Delta de origen que contiene incrustaciones calculadas previamente. A medida que se actualiza la tabla Delta, el índice permanece sincronizado con la tabla Delta.
Nota:
No es posible convertir un índice de inserción autoadministrado en un índice administrado por Databricks. Si más adelante decide usar incrustaciones administradas, debe crear un nuevo índice y volver a calcular las incrustaciones.
En el siguiente diagrama se ilustra este proceso:
- La consulta consta de inserciones y puede incluir filtros de metadatos.
- Realice una búsqueda de similitud para identificar los documentos más relevantes. Devuelva los documentos más relevantes y anéxelos a la consulta.

Opción 3: Índice de acceso vectorial directo
Con esta opción, debe actualizar manualmente el índice mediante la API REST cuando cambie la tabla de incrustaciones.
En el siguiente diagrama se ilustra este proceso:

Opciones de punto de conexión
Mosaic AI Vector Search proporciona las siguientes opciones para que pueda seleccionar la configuración del punto de conexión que satisfaga las necesidades de la aplicación.
Nota:
Los puntos de conexión optimizados para almacenamiento se encuentran en versión preliminar pública.
- Los puntos de conexión estándar tienen una capacidad de 320 millones de vectores en la dimensión 768.
- Los puntos de conexión optimizados para almacenamiento tienen una capacidad mayor (más de mil millones de vectores a la dimensión 768) y proporcionan una indexación de 10 a 20 veces más rápida. Las consultas en puntos de conexión optimizados para almacenamiento tienen una latencia ligeramente mayor de aproximadamente 250msec. Los precios de esta opción están optimizados para el mayor número de vectores. Para obtener más información sobre los precios, consulte la página de precios de búsqueda de vectores. Para obtener información sobre cómo administrar los costos de búsqueda de vectores, consulte Mosaic AI Vector Search: Cost management guide(Búsqueda de vectores de IA de mosaico: Guía de administración de costos).
Especifique el tipo de punto de conexión al crear el punto de conexión.
Consulte también Limitaciones de los puntos de conexión optimizados para almacenamiento.
Procedimiento para configurar Vector de búsqueda de Mosaic AI
Para usar Vector de búsqueda de Mosaic AI, es necesario crear lo siguiente:
Un punto de conexión de vector de búsqueda. Este punto de conexión sirve al índice de vector de búsqueda. Puede consultar y actualizar el punto de conexión mediante la API de REST o el SDK. Consulte Crear un punto de conexión de búsqueda de vectores para obtener instrucciones.
Los puntos de conexión aumentan automáticamente para soportar el tamaño del índice o el número de solicitudes concurrentes. Los puntos de conexión optimizados para almacenamiento se reducen verticalmente automáticamente cuando se elimina un índice. Los puntos de conexión estándar no escalan verticalmente automáticamente.
Índice de búsqueda vectorial El índice de búsqueda vectorial se crea a partir de una tabla Delta y está optimizado para proporcionar búsquedas aproximadas aproximadas de vecino (ANN) en tiempo real. El objetivo de la búsqueda es identificar documentos similares a la consulta. Los índices de búsqueda vectorial aparecen en Unity Catalog y están regulados por él. Vea Crear un índice de búsqueda vectorial para obtener instrucciones.
Además, si decide hacer que Databricks calcule las inserciones, puede usar un punto de conexión de Foundation Model API preconfigurado, o bien crear un punto de conexión de servicio del modelo para atender el modelo de inserción que prefiera. Consulte API de Modelo base de pago por token o Creación de puntos de conexión de modelo de servicio base para obtener instrucciones.
Para consultar el punto de conexión de servicio del modelo, use la API de REST o el SDK de Python. La consulta puede definir filtros en función de cualquier columna de la tabla Delta. Para obtener más información, vea Uso de filtros en consultas, la referencia de API o la referencia del SDK de Python.
Requisitos
- Área de trabajo habilitada para el catálogo de Unity.
- Computación sin servidor habilitada. Para obtener instrucciones, consulte Conectar a la computación sin servidor.
- En el caso de los puntos de conexión estándar, la tabla de origen debe tener habilitado el flujo de cambios de datos. Vea Uso de la fuente de distribución de datos de cambios de Delta Lake en Azure Databricks.
- Para crear un índice de búsqueda vectorial, debe tener CREATE TABLE privilegios en el esquema de catálogo donde se creará el índice.
El permiso para crear y administrar puntos de conexión de búsqueda vectorial se configura mediante listas de control de acceso. Consulte ACL de punto de conexión de vector de búsqueda.
Protección y autenticación de datos
Databricks implementa los siguientes controles de seguridad para proteger los datos:
- Todas las solicitudes de cliente a Vector de búsqueda de Mosaic AI están aisladas, autenticadas y autorizadas lógicamente.
- Vector de búsqueda de Mosaic AI cifra todos los datos en reposo (AES-256) y en tránsito (TLS 1.2+).
El vector de búsqueda de Mosaic AI admite dos modos de autenticación, entidades de servicio y tokens de acceso personal (PAT). En el caso de las aplicaciones de producción, Databricks recomienda usar entidades de servicio, que pueden tener un rendimiento de cada consulta hasta 100 msec más rápido comparado con los tokens de acceso personal.
Token de entidad de servicio. Un administrador puede generar un token de entidad de servicio y pasarlo al SDK o a la API. Consulte usar entidades de servicio. Para casos de uso de producción, Databricks recomienda usar un token de entidad de servicio.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Token de acceso personal. Puede usar un token de acceso personal para autenticarse con Mosaic AI Vector Search. Consulte token de autenticación de acceso personal. Si usa el SDK en un entorno de cuaderno, el SDK genera automáticamente un token pat para la autenticación.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Las claves administradas por el cliente (CMK) se admiten en los puntos de conexión creados el 8 de mayo de 2024 o después.
Supervisión de uso y costos
La tabla del sistema de uso de facturación le permite supervisar el uso y los costos asociados a los índices y puntos de conexión del vector de búsqueda. Aquí se muestra una consulta de ejemplo:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
También puede consultar el uso según la política de presupuesto. Consulte Mosaic AI Vector Search: Budget policies (Búsqueda de vectores de IA de mosaico: directivas presupuestarias).
Para obtener más información sobre el contenido de la tabla de uso de facturación, consulte Referencia de la tabla del sistema de uso de facturación. Las consultas adicionales se encuentran en el siguiente cuaderno de ejemplo.
Cuaderno de consultas de tablas del sistema del vector de búsqueda
Límites de tamaño de recursos y datos
En la tabla siguiente se resumen los límites de tamaño de recursos y datos para los puntos de conexión y los índices del vector de búsqueda:
| Resource | Granularidad | Limit |
|---|---|---|
| Puntos de conexión de vector búsqueda | Por área de trabajo | 100 |
| Incrustaciones (índice de sincronización delta) | Por punto de conexión estándar | ~ 320 000 000 a 768 dimensiones de inserción ~ 160 000 000 a 1536 dimensiones de inserción ~ 80 000 000 a 3072 dimensiones de inserción (escala aproximadamente linealmente) |
| Embeddings (índice de acceso vectorial directo) | Por punto de conexión estándar | ~ 2 000 000 a 768 dimensiones de inserción |
| Incrustaciones (punto de conexión optimizado para almacenamiento) | Punto de conexión optimizado para almacenamiento | ~ 1 000 000 000 a 768 dimensiones de inserción |
| Dimensión de inserción | Por índice | 4096 |
| Indexes | Por punto de conexión | 50 |
| Columnas | Por índice | 50 |
| Columnas | Tipos admitidos: Bytes, short, integer, long, float, double, boolean, string, timestamp, date, array | |
| Campos de metadatos | Por índice | 50 |
| Nombre del índice | Por índice | 128 caracteres |
Los límites siguientes se aplican a la creación y actualización de índices del vector de búsqueda:
| Resource | Granularidad | Limit |
|---|---|---|
| Tamaño de fila para el Índice de Sincronización Delta | Por índice | 100 KB |
| Inserción del tamaño de columna de origen para el índice Delta Sync | Por índice | 32764 bytes |
| Límite de tamaño de solicitud upsert masivo para el índice de vector directo | Por índice | 10 MB |
| Límite de tamaño de solicitud de eliminación masiva para el índice de vectores directos | Por índice | 10 MB |
Los límites siguientes se aplican a la API de consulta.
| Resource | Granularidad | Limit |
|---|---|---|
| Longitud del texto de consulta | Por consulta | 32764 caracteres |
| Tokens al usar la búsqueda híbrida | Por consulta | 1024 palabras o caracteres de 2 bytes |
| Condiciones de filtro | Cláusula per filter | 1024 elementos |
| Número máximo de resultados devueltos (búsqueda de vecinos más cercana aproximada) | Por consulta | 10 000 |
| Número máximo de resultados devueltos (búsqueda de similitud de palabras clave híbrida) | Por consulta | 200 |
Limitaciones
- El nombre de la columna
_idestá reservado. Si la tabla de origen tiene una columna denominada_id, cámbiela antes de crear un índice de búsqueda vectorial. - No se admiten los permisos de nivel de fila y columna. Sin embargo, puede implementar sus propias ACL de nivel de aplicación mediante la API de filtro.
- No se puede clonar un índice en un área de trabajo diferente. Puede realizar solicitudes entre áreas de trabajo mediante el SDK de Databricks o la API REST.
Limitaciones de los puntos de conexión optimizados para almacenamiento
Las limitaciones de esta sección solo se aplican a los puntos de conexión optimizados para almacenamiento. Los puntos de conexión optimizados para almacenamiento se encuentran en versión preliminar pública.
- No se admite el modo de sincronización continua.
- No se admiten columnas para sincronizar.
- La dimensión de inserción debe ser divisible por 16.
- El soporte para la actualización incremental es parcial. Cada sincronización debe volver a generar partes del índice de búsqueda vectorial.
- En el caso de los índices administrados, las incrustaciones calculadas anteriormente se reutilizan si la fila de origen no ha cambiado.
- Debe prever una reducción significativa de extremo a extremo del tiempo necesario para el proceso de sincronización en comparación con los puntos de conexión estándar. Los conjuntos de datos con 100 millones de incrustaciones deben completar una sincronización en menos de 8 horas. Los conjuntos de datos más pequeños tardarán menos tiempo en sincronizarse.
- No se admiten áreas de trabajo compatibles con FedRAMP.
- No se admiten claves administradas por el cliente (CMK).
- Para usar un modelo de inserción personalizado para un índice administrado de Delta Sync, se debe habilitar la versión preliminar de la consulta de IA para modelos personalizados y modelos externos . Consulte Administración de versiones preliminares de Azure Databricks para obtener información sobre cómo habilitar las versiones preliminares.
- Los puntos de conexión optimizados para almacenamiento admiten hasta 1000 millones de inserciones de vectores de 768 dimensiones. Si tiene un caso de uso de escala mayor, póngase en contacto con el equipo de la cuenta.