Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El Reglamento General de Protección de Datos (RGPD) y la Ley de Privacidad del Consumidor de California (CCPA) son normativas de privacidad y seguridad de datos que requieren que las empresas eliminen permanente y completamente toda la información de identificación personal (PII) recopilada sobre un cliente tras su solicitud explícita. También conocido como "derecho a olvidar" (RTBF) o "derecho a borrar datos", las solicitudes de eliminación deben ejecutarse durante un período especificado (por ejemplo, en un mes natural).
En este artículo se explica cómo implementar RTBF en los datos almacenados en Databricks. El ejemplo incluido en este artículo modela conjuntos de datos para una empresa de comercio electrónico y muestra cómo eliminar datos en tablas de origen y propagar estos cambios a las tablas de bajada.
Plano técnico para implementar el "derecho a olvidar"
En el diagrama siguiente se muestra cómo implementar el "derecho a olvidar".

punto elimina con Delta Lake
Delta Lake acelera las eliminaciones puntuales en grandes lagos de datos con transacciones ACID, lo que le permite localizar y eliminar información de identificación personal (DCP) en respuesta a las solicitudes del RGPD o la CCPA de los consumidores.
Delta Lake conserva el historial de tablas y hace que esté disponible para reversiones y consultas a un momento dado. La función VACUUM quita los archivos de datos a los que ya no hace referencia una tabla Delta y son anteriores a un umbral de retención especificado, eliminando permanentemente los datos. Para más información sobre los valores predeterminados y las recomendaciones, consulte Trabajar con historial de tablas.
Asegúrese de que los datos se eliminan al usar vectores de eliminación
En el caso de las tablas con vectores de eliminación habilitados, después de eliminar registros, también debe ejecutarse REORG TABLE ... APPLY (PURGE) para eliminar permanentemente los registros subyacentes. Esto incluye tablas de Delta Lake, vistas materializadas y tablas de streaming. Consulte Aplicación de cambios en los archivos de datos de Parquet.
Eliminación de datos en orígenes ascendentes
El RGPD y la CCPA se aplican a todos los datos, incluidos los datos de orígenes fuera de Delta Lake, como Kafka, archivos y bases de datos. Además de eliminar datos en Databricks, también debe recordar eliminar datos en fuentes ascendentes, como colas y almacenamiento en la nube.
Nota:
Antes de implementar flujos de trabajo de eliminación de datos, es posible que tenga que exportar datos del área de trabajo con fines de cumplimiento o copia de seguridad. Consulte Exportación de datos del área de trabajo.
La eliminación completa es preferible a ofuscación
Tiene que elegir entre eliminar datos y ofuscarlos. La ofuscación se puede implementar mediante la seudonimización, el enmascaramiento de datos, etc. Sin embargo, la opción más segura es la eliminación completa porque, en la práctica, eliminar el riesgo de reidentificación a menudo requiere una eliminación completa de los datos de PII.
Eliminar datos en la capa de bronce y, a continuación, propagar eliminaciones a capas de plata y oro
Se recomienda iniciar el cumplimiento del RGPD y la CCPA eliminando primero los datos de la capa de bronce, mediante un trabajo programado que consulta una tabla de solicitudes de eliminación. Después de eliminar los datos de la capa de bronce, los cambios se pueden propagar a las capas de plata y oro.
Mantener periódicamente tablas para quitar datos de archivos históricos
De manera predeterminada, Delta Lake conserva el historial de tablas durante 30 días, incluidos los registros borrados, y hace que esté disponible para viajes en el tiempo y reversiones. Pero incluso si se quitan versiones anteriores de los datos, los datos todavía se conservan en el almacenamiento en la nube. Por lo tanto, debe mantener periódicamente los conjuntos de datos para quitar versiones anteriores de los datos. La forma recomendada es Optimización predictiva para las tablas administradas por el catálogo de Unity, que mantiene de forma inteligente tanto las tablas de streaming como las vistas materializadas.
- En el caso de las tablas administradas por optimización predictiva, Lakeflow Spark Declarative Pipelines mantiene inteligentemente las tablas de streaming y las vistas materializadas, en función de los patrones de uso.
- En el caso de las tablas sin la optimización predictiva habilitada, Lakeflow Spark Declarative Pipelines realiza automáticamente tareas de mantenimiento en un plazo de 24 horas a partir de las tablas de streaming y las vistas materializadas que se actualizan.
Si no usa la optimización predictiva o las canalizaciones declarativas de Spark de Lakeflow, debe ejecutar un VACUUM comando en tablas Delta para quitar permanentemente versiones anteriores de datos. De forma predeterminada, esto reducirá las funcionalidades de desplazamiento de tiempo a 7 días, que es una configuración configurabley quitará también las versiones históricas de los datos en cuestión del almacenamiento en la nube.
Eliminar datos PII de la capa de bronce
Según el diseño de almacén de lago de datos, es posible que puedas evitar el vínculo entre los datos de usuario de PII y no PII. Por ejemplo, si usa una clave no natural, como user_id en lugar de una clave natural como el correo electrónico, puede eliminar datos PII, lo que deja los datos que no son de PII en su lugar.
El resto de este artículo controla RTBF eliminando completamente los registros de usuario de todas las tablas bronze. Puede eliminar datos ejecutando un comando DELETE, como se muestra en el código siguiente:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
Al eliminar un gran número de registros juntos al mismo tiempo, se recomienda usar el comando MERGE. En el código siguiente se supone que tiene una tabla de control denominada gdpr_control_table que contiene una columna de user_id. Inserte un registro en esta tabla para cada usuario que haya solicitado el "derecho a olvidarse" en esta tabla.
El comando MERGE especifica la condición para las filas coincidentes. En este caso, se emparejan los registros de target_table con los registros de gdpr_control_table en función del user_id. Si hay una coincidencia (por ejemplo, un user_id tanto en el target_table como en el gdpr_control_table), se elimina la fila del target_table. Después de que este comando MERGE se realice correctamente, actualice la tabla de control para confirmar que la solicitud se ha procesado.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Propagación de cambios de bronce a plata y oro
Después de eliminar los datos en la capa de bronce, debe propagar los cambios a las tablas de las capas de plata y oro.
Vistas materializadas: controlar automáticamente las eliminaciones
Las vistas materializadas controlan automáticamente las eliminaciones en orígenes. Por lo tanto, no es necesario hacer nada especial para asegurarse de que una vista materializada no contenga datos eliminados de un origen. Debe actualizar una vista materializada y ejecutar el mantenimiento para asegurarse de que las eliminaciones se procesan por completo.
Una vista materializada siempre devuelve el resultado correcto porque usa el cálculo incremental si es más barato que la recomputación completa, pero nunca a costa de la corrección. En otras palabras, la eliminación de datos de un origen podría provocar que una vista materializada se vuelva a calcular completamente.

Tablas de streaming: eliminar datos y leer el origen de streaming mediante skipChangeCommits
Las tablas de streaming procesan datos de solo adición cuando se transmiten desde orígenes de tablas Delta. Cualquier otra operación, como actualizar o eliminar un registro de un origen de streaming, no se admite y interrumpe la secuencia.
Nota:
Para una implementación de streaming más sólida, transmita desde las fuentes de cambios de las tablas Delta en su lugar y controle las actualizaciones y eliminaciones en el código de procesamiento. Consulte Opción 1: Transmisión desde una fuente de captura de cambios de datos (CDC).

Dado que el streaming de tablas Delta solo controla los nuevos datos, debe controlar los cambios en los datos usted mismo. El método recomendado consiste en: (1) eliminar datos de las tablas delta de origen mediante DML( 2) eliminar datos de la tabla de streaming mediante DML y, a continuación, (3) actualizar la lectura de streaming para usar skipChangeCommits. Esta marca indica que la tabla de streaming debe omitir algo distinto de las inserciones, como actualizaciones o eliminaciones.

Como alternativa, puede (1) eliminar datos del origen y luego (2) actualizar completamente la tabla de streaming. Al actualizar completamente una tabla de streaming, borra el estado de streaming de la tabla y vuelve a procesar todos los datos. Cualquier origen de datos ascendente que esté más allá de su período de retención (por ejemplo, un tema de Kafka que agote los datos después de 7 días) no se procesará de nuevo, lo que podría provocar la pérdida de datos. Se recomienda esta opción para las tablas de streaming solo en el escenario en el que los datos históricos están disponibles y el procesamiento de nuevo no será costoso.

Ejemplo: RGPD y cumplimiento de CCPA para una empresa de comercio electrónico
En el diagrama siguiente se muestra una arquitectura de medallón para una empresa de comercio electrónico en la que se debe implementar el cumplimiento del RGPD y la CCPA. Aunque se eliminen los datos de un usuario, es posible que quiera contar sus actividades en agregaciones de nivel inferior.
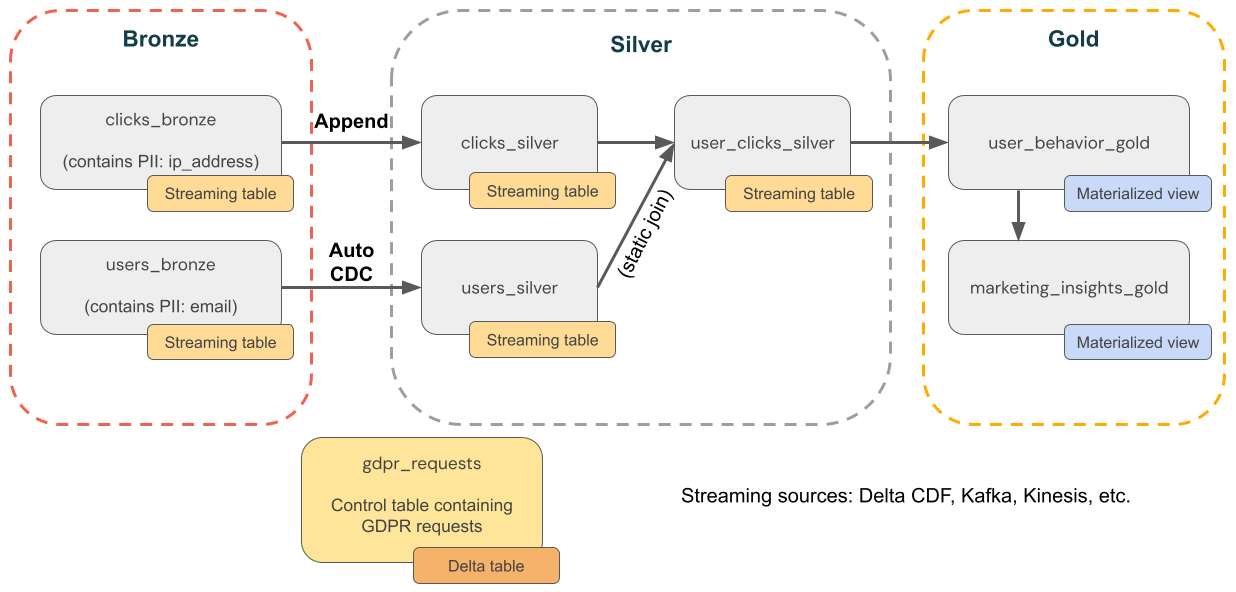
-
Tablas de origen
-
source_users- una tabla de origen de streaming de usuarios (por ejemplo, creada aquí). Los entornos de producción suelen usar Kafka, Kinesis o plataformas de streaming similares. -
source_clicks- Una tabla de origen de streaming de clics (por ejemplo, creada aquí). Los entornos de producción suelen usar Kafka, Kinesis o plataformas de streaming similares.
-
-
Tabla de control
-
gdpr_requests: tabla de control que contiene identificadores de usuario sujetos a "derecho a olvidar". Cuando un usuario solicita que se quite, agréguelos aquí.
-
-
capa de bronce
-
users_bronze: dimensiones de usuario. Contiene PII (por ejemplo, dirección de correo electrónico). -
clicks_bronze: haga clic en eventos. Contiene PII (por ejemplo, dirección IP).
-
-
Capa de plata
-
clicks_silver- Limpia y normaliza los datos de clics. -
users_silver- Datos de usuario limpios y estandarizados. -
user_clicks_silver- Combinaclicks_silver(transmisión) con una instantánea deusers_silver.
-
-
Capa de oro
-
user_behavior_gold- Métricas de comportamiento de usuario agregadas. -
marketing_insights_gold- Segment de usuario para información del mercado.
-
Paso 1: Rellenar tablas con datos de ejemplo
El código siguiente crea estas dos tablas para este ejemplo y las rellena con datos de ejemplo:
-
source_userscontiene datos dimensionales sobre los usuarios. Esta tabla contiene una columna PII denominadaemail. -
source_clickscontiene datos de eventos sobre las actividades realizadas por los usuarios. Contiene una columna PII denominadaip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Paso 2: Creación de una canalización que procesa datos PII
El código siguiente crea capas de bronce, plata y oro de la arquitectura de medallón mostrada anteriormente.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dp.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dp.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dp.create_streaming_table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dp.view
@dp.expect_or_drop('valid_email', "email IS NOT NULL")
def users_bronze_view():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.users_silver",
source="users_bronze_view",
keys=["user_id"],
sequence_by="registration_date",
)
@dp.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dp.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dp.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame - each refresh
# will use a snapshot of the users_silver table.
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame.
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join - join of a static dataset with a
# streaming dataset creates a streaming table.
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dp.materialized_view(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dp.materialized_view(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Paso 3: Eliminar datos en tablas de origen
En este paso, elimine los datos de todas las tablas donde se haya encontrado PII. La función siguiente elimina todas las instancias de la PII de un usuario de las tablas con PII.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Paso 4: Agregar skipChangeCommits a definiciones de tablas de streaming afectadas
En este paso, debe indicar a las Canalizaciones Declarativas de Spark de Lakeflow que omitan las filas no añadibles. Agregue la opción skipChangeCommits a los métodos siguientes. No es necesario actualizar las definiciones de vistas materializadas porque controlarán automáticamente las actualizaciones y eliminaciones.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
El código siguiente muestra cómo actualizar el método users_bronze:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
Al volver a ejecutar la canalización, se actualizará correctamente.