Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, Arquitectura de aplicaciones .NET nativas de nube para Azure, disponible en .NET Docs o como un PDF descargable gratuito que se puede leer sin conexión.

Como hemos visto en este libro, un enfoque nativo de la nube cambia la forma de diseñar, implementar y administrar aplicaciones. También cambia la forma de administrar y almacenar datos.
La figura 5-1 contrasta las diferencias.

Figura 5-1. Administración de datos en aplicaciones nativas de nube
Los desarrolladores experimentados reconocerán fácilmente la arquitectura en el lado izquierdo de la figura 5-1. En esta aplicación monolítica, los componentes de servicio empresarial se agrupan en un nivel de servicios compartidos y comparten datos de una base de datos relacional única.
De muchas maneras, una base de datos única mantiene la administración de datos sencilla. La consulta de datos entre varias tablas es sencilla. Los cambios en los datos se actualizan juntos o se revierten todos. Las transacciones ACID garantizan una coherencia fuerte e inmediata.
Al diseñar para la nube nativa adoptamos un enfoque diferente. En el lado derecho de la figura 5-1, observe cómo la funcionalidad empresarial se separa en microservicios pequeños e independientes. Cada microservicio encapsula una funcionalidad empresarial específica y sus propios datos. La base de datos monolítica se descompone en un modelo de datos distribuido con muchas bases de datos más pequeñas, cada una de las cuales se alinea con un microservicio. Cuando se borra el humo, emergemos con un diseño que expone una base de datos por microservicio.
Base de datos por microservicio, ¿por qué?
Esta base de datos por microservicio proporciona muchas ventajas, especialmente para los sistemas que deben evolucionar rápidamente y admitir una escala masiva. Con este modelo...
- Los datos de dominio se encapsulan dentro del servicio
- El esquema de datos puede evolucionar sin afectar directamente a otros servicios
- Cada almacén de datos puede escalar de forma independiente
- Un error de almacén de datos en un servicio no afectará directamente a otros servicios
La separación de datos también permite a cada microservicio implementar el tipo de almacén de datos que está mejor optimizado para sus patrones de carga de trabajo, almacenamiento y lectura y escritura. Las opciones incluyen almacenes de datos relacionales, documentos, clave-valor e incluso basados en grafos.
La figura 5-2 presenta el principio de persistencia políglota en un sistema nativo en la nube.
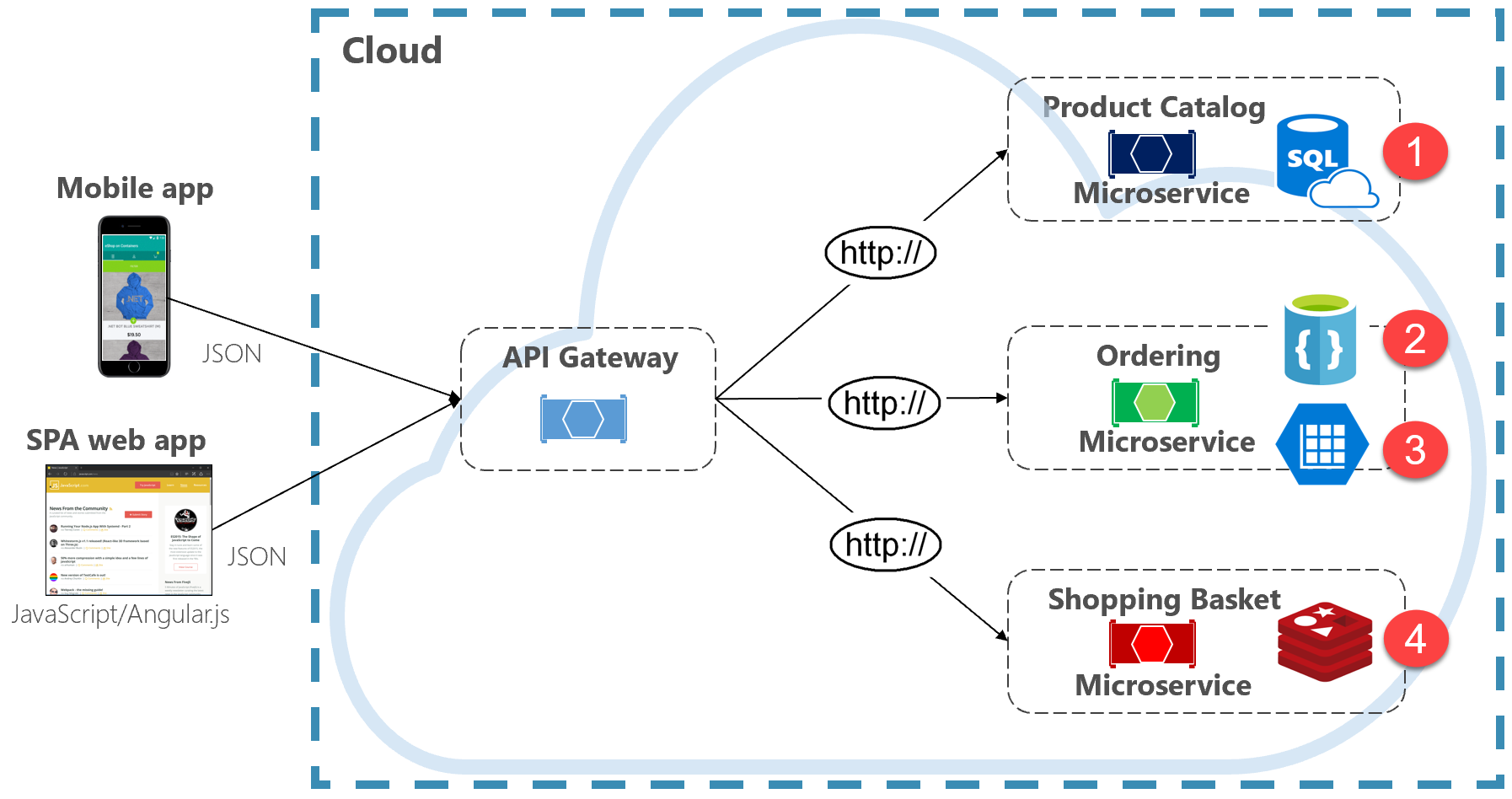
Figura 5-2. Persistencia de datos políglota
Tenga en cuenta en la ilustración anterior cómo cada microservicio admite un tipo diferente de almacén de datos.
- El microservicio del catálogo de productos consume una base de datos relacional para dar cabida a la estructura relacional enriquecida de sus datos subyacentes.
- El microservicio del carro de la compra consume una memoria caché distribuida que admite su sencillo almacén de datos de clave-valor.
- El microservicio de ordenación consume una base de datos de documentos NoSql para operaciones de escritura junto con un almacén de clave/valor altamente desnormalizado para dar cabida a grandes volúmenes de operaciones de lectura.
Aunque las bases de datos relacionales siguen siendo relevantes para los microservicios con datos complejos, las bases de datos NoSQL han ganado una popularidad considerable. Proporcionan gran escala y alta disponibilidad. Su naturaleza sin esquema permite a los desarrolladores alejarse de una arquitectura de clases de datos tipadas y ORM que hacen que el cambio sea costoso y lento. Tratamos las bases de datos NoSQL más adelante en este capítulo.
Aunque la encapsulación de datos en microservicios independientes puede aumentar la agilidad, el rendimiento y la escalabilidad, también presenta muchos desafíos. En la sección siguiente, se describen estos desafíos junto con patrones y prácticas para ayudar a superarlos.
Consultas entre servicios
Aunque los microservicios son independientes y se centran en funcionalidades funcionales específicas, como el inventario, el envío o el pedido, con frecuencia requieren integración con otros microservicios. A menudo, la integración implica que un microservicio consulte a otro para los datos. En la figura 5-3 se muestra el escenario.

Figura 5-3. Consulta entre microservicios
En la ilustración anterior, vemos un microservicio de cesta de la compra que agrega un artículo a la cesta de la compra de un usuario. Aunque el almacén de datos de este microservicio contiene datos de artículos de cesta y línea, no mantiene los datos de productos ni precios. En su lugar, esos elementos de datos son propiedad del catálogo y los microservicios de precios. Este aspecto presenta un problema. ¿Cómo puede el microservicio de cesta de la compra agregar un producto a la cesta de la compra del usuario cuando no tiene datos de productos ni precios en su base de datos?
Una opción que se describe en el capítulo 4 es una llamada HTTP directa desde la cesta de la compra al catálogo y a los microservicios de precios. Sin embargo, en el capítulo 4, dijimos que las llamadas HTTP sincrónicas vinculan microservicios juntos, reduciendo su autonomía y disminuyendo sus ventajas arquitectónicas.
También podríamos implementar un patrón de solicitud-respuesta con colas entrantes y salientes independientes para cada servicio. Sin embargo, este patrón es complicado y requiere fontanería para correlacionar mensajes de solicitud y respuesta. Aunque desacopla las llamadas a los microservicios del backend, el servicio que realiza la llamada todavía debe esperar sincrónicamente a que se complete la llamada. Congestión de red, errores transitorios o un microservicio sobrecargado pueden dar lugar a operaciones de larga duración e incluso con errores.
En su lugar, un patrón ampliamente aceptado para quitar dependencias entre servicios es el patrón de vista materializado, que se muestra en la figura 5-4.
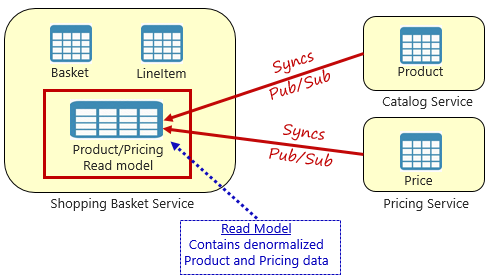
Figura 5-4. Patrón de vista materializado
Con este patrón, se coloca una tabla de datos local (conocida como modelo de lectura) en el servicio de carrito de compras. Esta tabla contiene una copia desnormalizada de los datos necesarios de los microservicios de producto y precios. Copiar los datos directamente en el microservicio de cesta de la compra elimina la necesidad de llamadas de servicio cruzado costosas. Con los datos locales para el servicio, se mejora el tiempo de respuesta y la confiabilidad del servicio. Además, tener su propia copia de los datos hace que el servicio de cesta de la compra sea más resistente. Si el servicio de catálogo no debería estar disponible, no afectaría directamente al servicio de cesta de la compra. La cesta de la compra puede seguir funcionando con los datos de su propia tienda.
El inconveniente de este enfoque es que ahora tiene datos duplicados en su sistema. Sin embargo, la duplicación estratégica de datos en sistemas nativos en la nube es una práctica establecida y no se considera un antipatrón o una mala práctica. Tenga en cuenta que uno y solo un servicio pueden poseer un conjunto de datos y tener autoridad sobre él. Deberá sincronizar los modelos de lectura cuando se actualice el sistema de registro. Normalmente, la sincronización se implementa mediante mensajería asincrónica con un patrón de publicación o suscripción, como se muestra en la figura 5.4.
Transacciones distribuidas
Aunque la consulta de datos entre microservicios es difícil, la implementación de una transacción en varios microservicios es aún más compleja. El desafío inherente de mantener la coherencia de los datos entre fuentes de datos independientes en distintos microservicios no puede ser subestimado. La falta de transacciones distribuidas en aplicaciones nativas de nube significa que debe administrar transacciones distribuidas mediante programación. Se mueve desde un mundo de coherencia inmediata a uno de coherencia eventual.
En la figura 5-5 se muestra el problema.

Figura 5-5. Implementación de una transacción entre microservicios
En la ilustración anterior, cinco microservicios independientes participan en una transacción distribuida que crea un pedido. Cada microservicio mantiene su propio almacén de datos e implementa una transacción local para su almacén. Para crear el pedido, la transacción local para cada microservicio individual debe tener éxito, de lo contrario todas deben anularse y revertir la operación. Aunque la compatibilidad transaccional integrada está disponible dentro de cada uno de los microservicios, no hay compatibilidad con una transacción distribuida que abarque los cinco servicios para mantener los datos coherentes.
En su lugar, debe construir esta transacción distribuida mediante programación.
Un patrón popular para agregar compatibilidad transaccional distribuida es el patrón Saga. Se implementa mediante la agrupación de transacciones locales mediante programación y la invocación secuencial de cada una. Si se produce un error en alguna de las transacciones locales, la Saga anula la operación e invoca un conjunto de transacciones de compensación. Las transacciones de compensación deshace los cambios realizados por las transacciones locales anteriores y restauran la coherencia de los datos. En la figura 5-6 se muestra una transacción fallida con el patrón Saga.

Figura 5-6. Revertir una transacción
En la ilustración anterior, se produjo un error en la operación Actualizar inventario en el microservicio Inventario. Saga invoca un conjunto de transacciones de compensación (en rojo) para ajustar los recuentos de inventario, cancelar el pago y el pedido, y devolver los datos de cada microservicio a un estado coherente.
Los patrones de Saga se suelen coreografiar como una serie de eventos relacionados o se orquestan como un conjunto de comandos relacionados. En el capítulo 4 analizamos el patrón del agregador de servicios que sería la base para una implementación orquestada de Saga. También discutimos la gestión de eventos junto con los temas de Azure Service Bus y Azure Event Grid, que serían la base para una implementación de saga coreografiada.
Datos de gran volumen
Las aplicaciones nativas de nube de gran tamaño suelen admitir requisitos de datos de gran volumen. En estos escenarios, las técnicas tradicionales de almacenamiento de datos pueden provocar cuellos de botella. En el caso de sistemas complejos que se implementan a gran escala, la segregación de responsabilidades de comandos y consultas (CQRS) y Event Sourcing pueden mejorar el rendimiento de la aplicación.
CQRS
CQRS, es un patrón arquitectónico que puede ayudar a maximizar el rendimiento, la escalabilidad y la seguridad. El patrón separa las operaciones que leen datos de esas operaciones que escriben datos.
En escenarios normales, se usan el mismo modelo de entidad y el objeto de repositorio de datos para las operaciones de lectura y escritura.
Sin embargo, un escenario de datos de gran volumen puede beneficiarse de modelos independientes y tablas de datos para lecturas y escrituras. Para mejorar el rendimiento, la operación de lectura podría consultar una representación altamente desnormalizada de los datos para evitar combinaciones de tablas repetitivas costosas y bloqueos de tabla. La operación de escritura , conocida como comando, se actualizaría con una representación totalmente normalizada de los datos que garantizarían la coherencia. A continuación, debe implementar un mecanismo para mantener sincronizadas ambas representaciones. Normalmente, cada vez que se modifica la tabla de escritura, publica un evento que replica la modificación en la tabla de lectura.
En la figura 5-7 se muestra una implementación del patrón CQRS.

Figura 5-7. Implementación de CQRS
En la ilustración anterior, se implementan modelos de consulta y comandos independientes. Cada operación de escritura de datos se guarda en el almacén de escritura y, a continuación, se propaga al almacén de lectura. Preste atención a cómo funciona el proceso de propagación de datos en el principio de consistencia eventual. El modelo de lectura se sincroniza finalmente con el modelo de escritura, pero puede haber algún retraso en el proceso. En la sección siguiente se describe la coherencia final.
Esta separación permite que las lecturas y escrituras escalen independientemente. Las operaciones de lectura usan un esquema optimizado para consultas, mientras que las escrituras usan un esquema optimizado para actualizaciones. Las consultas de lectura se aplican a datos desnormalizados, mientras que la lógica empresarial compleja se puede aplicar al modelo de escritura. Además, podría imponer una seguridad más estricta en las operaciones de escritura que las que exponen las lecturas.
La implementación de CQRS puede mejorar el rendimiento de las aplicaciones para los servicios nativos de la nube. Sin embargo, resulta en un diseño más complejo. Aplique este principio cuidadosa y estratégicamente a esas secciones de la aplicación nativa de la nube que se beneficiarán de ella. Para obtener más información sobre CQRS, consulte el libro de Microsoft Microservicios de .NET: Arquitectura para aplicaciones .NET en contenedor.
Aprovisionamiento de eventos
Otro enfoque para optimizar escenarios de datos de gran volumen implica Event Sourcing.
Normalmente, un sistema almacena el estado actual de una entidad de datos. Si un usuario cambia su número de teléfono, por ejemplo, el registro del cliente se actualiza con el nuevo número. Siempre sabemos el estado actual de una entidad de datos, pero cada actualización sobrescribe el estado anterior.
En la mayoría de los casos, este modelo funciona bien. Sin embargo, en sistemas de gran volumen, la sobrecarga del bloqueo transaccional y las operaciones de actualización frecuentes pueden afectar al rendimiento, la capacidad de respuesta y la escalabilidad del límite de la base de datos.
Event Sourcing adopta un enfoque diferente para capturar datos. Cada operación que afecta a los datos se conserva en un almacén de eventos. En lugar de actualizar el estado de un registro de datos, anexamos cada cambio a una lista secuencial de eventos anteriores, similar al libro de contabilidad de un contador. El Almacén de eventos se convierte en el sistema de registro de los datos. Se usa para propagar varias vistas materializadas dentro del contexto limitado de un microservicio. En la figura 5.8 se muestra el patrón.

Figura 5-8. Aprovisionamiento de eventos
En la ilustración anterior, fíjate en cómo se añade cada entrada (en azul) para la cesta de compras de un usuario a un almacén de eventos subyacente. En la vista materializada adyacente, el sistema proyecta el estado actual reproduciendo todos los eventos asociados a cada carro de la compra. Esta vista, o modelo de lectura, se expone de nuevo a la interfaz de usuario. Los eventos también se pueden integrar con aplicaciones y sistemas externos o consultar para determinar el estado actual de una entidad. Con este enfoque, se mantiene el historial. Sabe no solo el estado actual de una entidad, sino también cómo alcanzó este estado.
En términos mecánicos, el aprovisionamiento de eventos simplifica el modelo de escritura. No hay actualizaciones ni eliminaciones. Anexar cada entrada de datos como un evento inmutable minimiza los conflictos de contención, bloqueo y simultaneidad asociados a bases de datos relacionales. La creación de modelos de lectura con el patrón de vista materializado permite desacoplar la vista del modelo de escritura y elegir el mejor almacén de datos para optimizar las necesidades de la interfaz de usuario de la aplicación.
Para este patrón, tome en consideración un almacén de datos que admita directamente el aprovisionamiento de eventos. Azure Cosmos DB, MongoDB, Cassandra, CouchDB y RavenDB son buenos candidatos.
Al igual que con todos los patrones y tecnologías, implemente estratégicamente y cuando sea necesario. Aunque el aprovisionamiento de eventos puede proporcionar un mayor rendimiento y escalabilidad, se produce a costa de la complejidad y una curva de aprendizaje.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.