Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, Arquitectura de aplicaciones .NET nativas de nube para Azure, disponible en .NET Docs o como un PDF descargable gratuito que se puede leer sin conexión.

Al igual que se han desarrollado patrones para ayudar en el diseño de código en las aplicaciones, hay patrones para las aplicaciones operativas de una manera confiable. Han surgido tres patrones útiles para mantener aplicaciones: registro, supervisión y alertas.
Cuándo usar el registro
Independientemente de lo cuidadoso que seamos, las aplicaciones casi siempre se comportan de maneras inesperadas en producción. Cuando los usuarios notifican problemas con una aplicación, resulta útil poder ver lo que estaba ocurriendo con la aplicación cuando se produjo el problema. Una de las formas más probadas y verdaderas de capturar información sobre lo que hace una aplicación mientras se ejecuta es hacer que la aplicación anote lo que está haciendo. Este proceso se conoce como registro. Siempre que se produzcan errores o problemas en producción, el objetivo debe ser reproducir las condiciones en las que se produjeron los errores, en un entorno que no sea de producción. Contar con un buen sistema de registro proporciona una hoja de ruta para que los desarrolladores puedan duplicar problemas en un entorno que permite realizar pruebas y experimentación.
Desafíos al iniciar sesión con aplicaciones nativas de la nube
En las aplicaciones tradicionales, los archivos de registro se almacenan normalmente en el equipo local. De hecho, en sistemas operativos similares a Unix, hay una estructura de carpetas definida para contener los registros, normalmente en /var/log.
 Figura 7-1. Registro en un archivo en una aplicación monolítica.
Figura 7-1. Registro en un archivo en una aplicación monolítica.
La utilidad de registrar en un archivo plano en una sola máquina se reduce enormemente en un entorno de nube. Es posible que las aplicaciones que producen registros no tengan acceso al disco local o que el disco local sea muy transitorio, ya que los contenedores se ordenan aleatoriamente en torno a las máquinas físicas. Incluso un simple escalado vertical de aplicaciones monolíticas en varios nodos puede dificultar la localización de un archivo de registro basado en archivos.
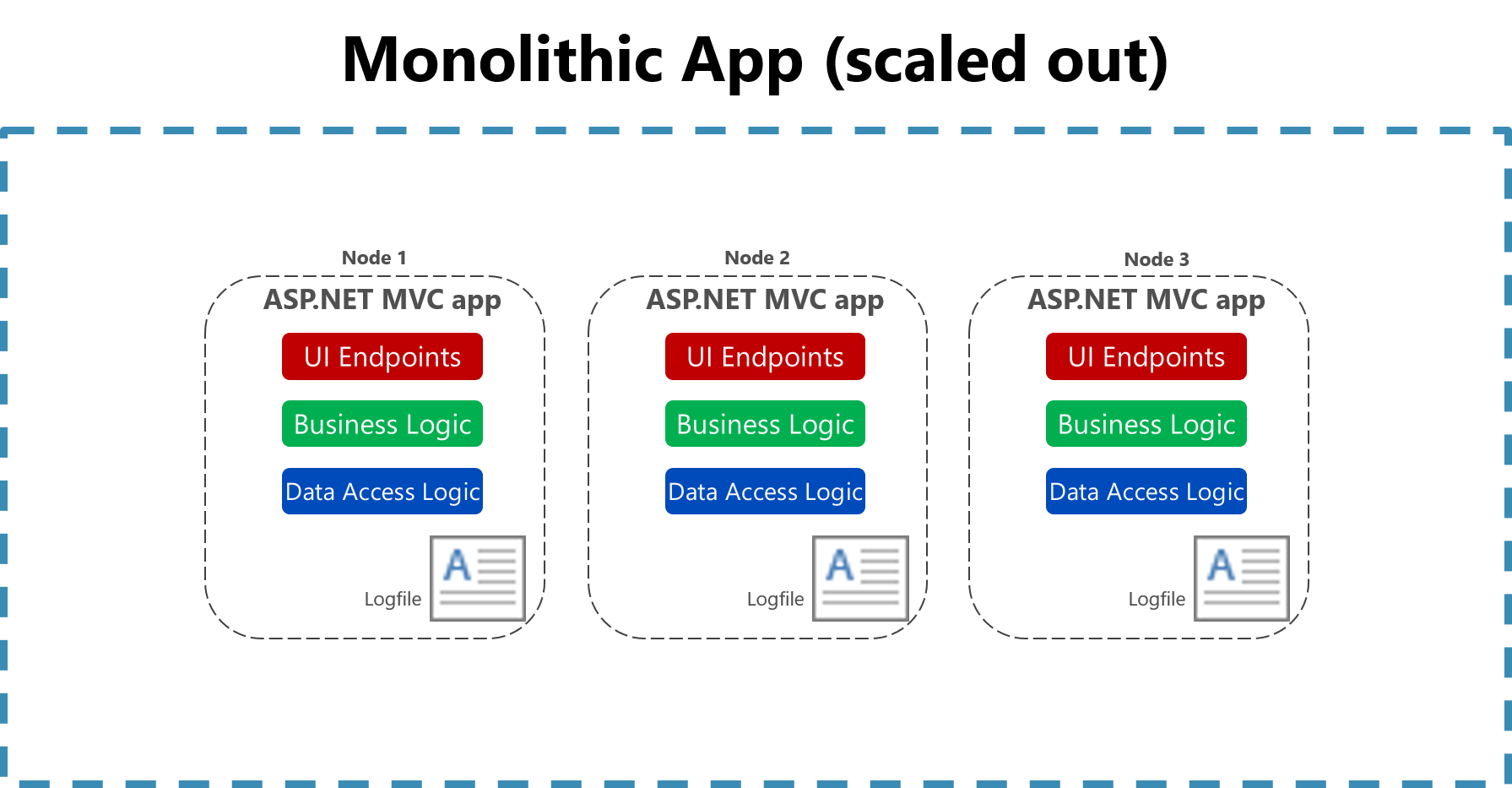 Figura 7-2. Registro en archivos en una aplicación monolítica escalada.
Figura 7-2. Registro en archivos en una aplicación monolítica escalada.
Las aplicaciones nativas de la nube desarrolladas mediante una arquitectura de microservicios también suponen algunos desafíos para los registradores basados en archivos. Las solicitudes de usuario ahora pueden abarcar varios servicios que se ejecutan en máquinas diferentes y pueden incluir funciones sin servidor sin acceso a un sistema de archivos local en absoluto. Sería muy difícil correlacionar los registros de un usuario o una sesión en estos muchos servicios y máquinas.
 Figura 7-3. Registro en archivos locales en una aplicación de microservicios.
Figura 7-3. Registro en archivos locales en una aplicación de microservicios.
Por último, el número de usuarios de algunas aplicaciones nativas de la nube es elevado. Imagine que cada usuario genera cien líneas de mensajes de registro cuando inicia sesión en una aplicación. De forma aislada, es manejable, pero multiplica eso por 100 000 usuarios y el volumen de registros se vuelve lo suficientemente grande como para que se necesiten herramientas especializadas para respaldar el uso eficaz de los registros.
Registro en aplicaciones nativas de la nube
Cada lenguaje de programación tiene herramientas que permiten escribir registros y, normalmente, la sobrecarga para escribir estos registros es baja. Muchas de las bibliotecas de registro permiten registrar diferentes niveles de criticidad, que se pueden ajustar en tiempo de ejecución. Por ejemplo, la biblioteca Serilog es una conocida biblioteca de registro estructurado para .NET que proporciona los siguientes niveles de registro:
- Verboso
- Depurar
- Información
- Advertencia
- Error
- Grave
Estos distintos niveles de registro proporcionan granularidad en el registro. Cuando la aplicación funciona correctamente en producción, puede configurarse para registrar solo mensajes importantes. Cuando la aplicación se comporta mal, se puede aumentar el nivel de registro para que se recopilen registros más detallados. Esto equilibra el rendimiento y la facilidad de depuración.
El alto rendimiento de las herramientas de registro y la capacidad de ajuste del nivel de detalle deben animar a los desarrolladores a registrar con frecuencia. Muchos favorecen un patrón de registro de la entrada y salida de cada método. Este enfoque puede parecer excesivo, pero es poco frecuente que los desarrolladores deseen menos registro. De hecho, no es raro realizar implementaciones con el único fin de agregar registros sobre un método problemático. Es mejor realizar demasiados registros que demasiados pocos. Algunas herramientas se pueden usar para proporcionar automáticamente este tipo de registro.
Debido a los desafíos asociados al uso de registros basados en archivos en aplicaciones nativas de nube, se prefieren los registros centralizados. Las aplicaciones recopilan los registros y se envían a una aplicación de registro central que indexa y almacena los registros. Esta clase de sistema puede ingerir decenas de gigabytes de registros todos los días.
También es útil seguir algunos procedimientos estándar al crear registros que abarquen muchos servicios. Por ejemplo, generar un identificador de correlación al principio de una interacción larga y, a continuación, registrarlo en cada mensaje relacionado con esa interacción facilita la búsqueda de todos los mensajes relacionados. Solo necesita encontrar un solo mensaje y extraer el identificador de correlación para buscar todos los mensajes relacionados. Otro ejemplo es asegurarse de que el formato de registro es el mismo para cada servicio, independientemente del idioma o la biblioteca de registro que use. Esta normalización facilita la lectura de registros. En la figura 7-4 se muestra cómo una arquitectura de microservicios puede aprovechar el registro centralizado como parte de su flujo de trabajo.
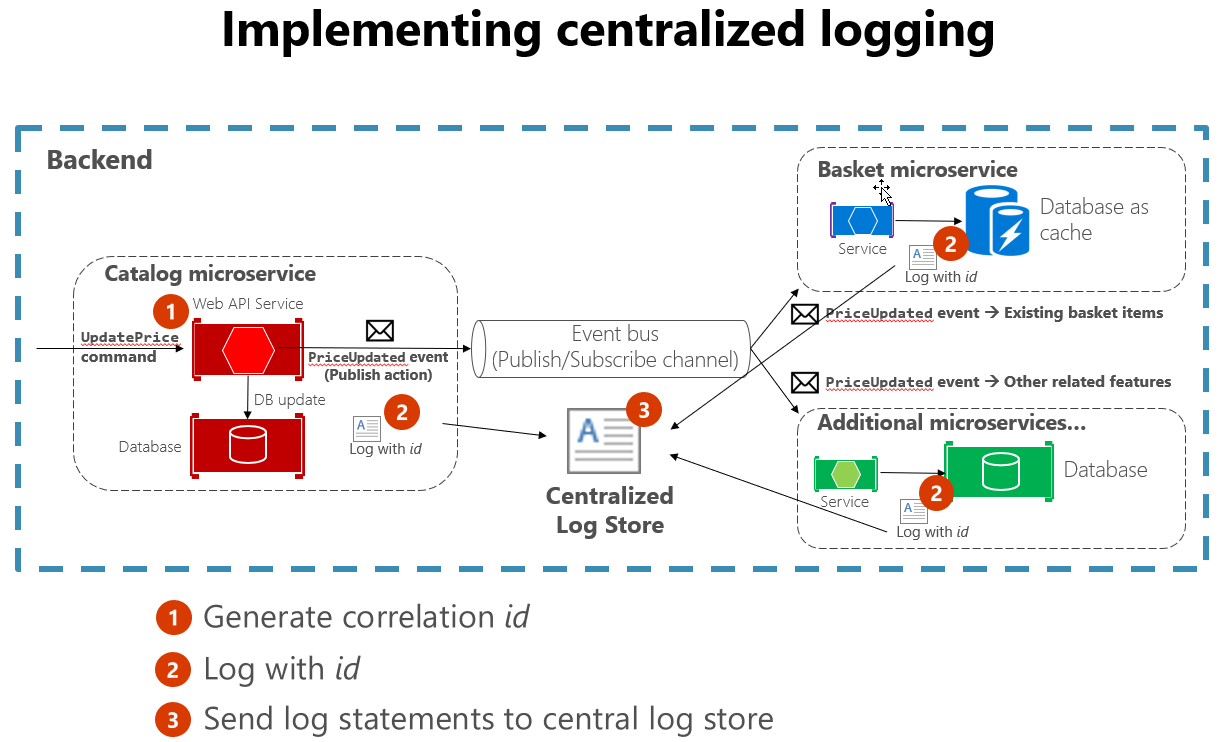 Figura 7-4. Los logs de varios orígenes se integran en un repositorio de logs centralizado.
Figura 7-4. Los logs de varios orígenes se integran en un repositorio de logs centralizado.
Desafíos con la detección y respuesta a posibles problemas de estado de la aplicación
Algunas aplicaciones no son críticas. Quizá solo se usen internamente y, cuando se produzca un problema, el usuario puede ponerse en contacto con el equipo responsable y se puede reiniciar la aplicación. Sin embargo, los clientes suelen tener mayores expectativas para las aplicaciones que consumen. Debe saber cuándo se producen problemas con la aplicación antes de que los usuarios lo hagan o antes de que los usuarios le notifiquen. De lo contrario, la primera vez que se entere de un problema puede ser cuando se dé cuenta de un diluvio de publicaciones enfadadas en redes sociales que ridiculizan su aplicación o incluso su organización.
Algunos escenarios que puede tener en cuenta son:
- Un servicio de la aplicación sigue fallando y reiniciando, lo que da lugar a respuestas lentas intermitentes.
- En algunos momentos del día, el tiempo de respuesta de la aplicación es lento.
- Después de una implementación reciente, la carga en la base de datos se ha tripledo.
La supervisión se puede implementar correctamente para informarle sobre las condiciones que provocarán problemas, lo que le permite abordar las condiciones subyacentes antes de que produzcan cualquier impacto significativo en el usuario.
Supervisión de aplicaciones nativas de la nube
Algunos sistemas de registro centralizados tienen un rol adicional de recopilar telemetría fuera de los registros puros. Pueden recopilar métricas, como el tiempo para ejecutar una consulta de base de datos, el tiempo medio de respuesta de un servidor web e incluso los promedios de carga de CPU y la presión de memoria, según lo notificado por el sistema operativo. Junto con los registros, estos sistemas pueden proporcionar una vista holística del estado de los nodos en el sistema y la aplicación en su conjunto.
Las funcionalidades de recopilación de métricas de las herramientas de supervisión también se pueden alimentar manualmente desde dentro de la aplicación. Los flujos empresariales que son de especial interés, como los nuevos usuarios que se registran o los pedidos que se realizan, se pueden instrumentar de forma que incrementen un contador en el sistema de supervisión central. Este aspecto desbloquea las herramientas de supervisión para no solo supervisar el estado de la aplicación, sino el estado de la empresa.
Las consultas se pueden construir en las herramientas de agregación de registros para buscar determinadas estadísticas o patrones, que luego se pueden mostrar en formato gráfico, en paneles personalizados. Con frecuencia, los equipos invertirán en pantallas grandes y montadas en pared que giran a través de las estadísticas relacionadas con una aplicación. De este modo, es fácil ver los problemas a medida que se producen.
Las herramientas de supervisión nativas de la nube proporcionan telemetría en tiempo real e información sobre las aplicaciones, independientemente de si son aplicaciones monolíticas de un solo proceso o arquitecturas de microservicios distribuidos. Incluyen herramientas que permiten la recopilación de datos de la aplicación, así como herramientas para consultar y mostrar información sobre el estado de la aplicación.
Desafíos con la reacción a problemas críticos en aplicaciones nativas de la nube
Si necesita reaccionar ante problemas con la aplicación, necesita alguna manera de alertar al personal adecuado. Este es el tercer patrón de observabilidad de aplicaciones nativas de la nube y depende del registro y la supervisión. Tu aplicación necesita tener un registro de eventos para permitir el diagnóstico de problemas y, en algunos casos, alimentar herramientas de supervisión. Necesita supervisión para agregar métricas de aplicación y datos de estado en un solo lugar. Una vez establecido esto, se pueden crear reglas que desencadenarán alertas cuando determinadas métricas se encuentran fuera de los niveles aceptables.
Por lo general, las alertas se superponen a la supervisión, de modo que ciertas condiciones desencadenan alertas adecuadas para notificar a los miembros del equipo problemas urgentes. Algunos escenarios que pueden requerir alertas incluyen:
- Uno de los servicios de la aplicación no responde después de 1 minuto de tiempo de inactividad.
- La aplicación devuelve respuestas HTTP incorrectas a más del 1 % de las solicitudes.
- El tiempo medio de respuesta de la aplicación para los puntos de conexión de clave supera los 2000 ms.
Alertas en aplicaciones nativas de la nube
Puede crear consultas en las herramientas de supervisión para buscar condiciones de error conocidas. Por ejemplo, las consultas podrían buscar en los registros entrantes indicaciones del código de estado HTTP 500, lo que indica un problema en un servidor web. Tan pronto como se detecte una de estas, se podría enviar un correo electrónico o un SMS al propietario del servicio de origen que puede empezar a investigar.
Sin embargo, normalmente, un único error 500 no es suficiente para determinar que se ha producido un problema. Podría significar que un usuario ha escrito mal su contraseña o ha escrito algunos datos con formato incorrecto. Las consultas de alerta pueden crearse de modo que solo se activen cuando se detecte un número superior a la media de errores 500.
Uno de los patrones más perjudiciales en las alertas es desencadenar demasiadas alertas para que los humanos investiguen. Los propietarios de servicios se dessensitizarán rápidamente a los errores que han investigado anteriormente y han detectado que son benignos. Después, cuando se produzcan errores de verdad, se perderán en el ruido que generan cientos de falsos positivos. La parábola de El niño que gritó 'lobo' es frecuentemente contada a los niños para advertirles de este peligro. Es importante asegurarse de que las alertas que se activan indiquen un problema real.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.