Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Use Azure Synapse Link para conectar sus datos de Microsoft Dataverse a Azure Synapse Analytics para explorar sus datos y acelerar el tiempo de conclusión. En este artículo se muestra cómo ejecutar canalizaciones de Azure Synapse o Azure Data Factory para copiar datos de Azure Data Lake Storage Gen2 en una instancia de Azure SQL Database con la característica de actualizaciones incrementales habilitada en Azure Synapse Link.
Nota:
Azure Synapse Link para Microsoft Dataverse se conocía anteriormente como Export to data lake. El nombre del servicio se cambió a partir de mayo de 2021 y seguirá exportando datos a Azure Data Lake, así como a Azure Synapse Analytics. Esta plantilla es un ejemplo de código. Le recomendamos que use esta plantilla como guía para probar la funcionalidad de recuperar datos de Azure Data Lake Storage Gen2 a Azure SQL Database mediante la canalización proporcionada.
Prerrequisitos
- Azure Synapse Link para Dataverse. En esta guía se da por supuesto que ya ha cumplido los requisitos previos para crear una instancia de Azure Synapse Link con Azure Data Lake. Más información: Requisitos de Azure Synapse Link para Dataverse con Azure Data Lake
- Cree un Azure Synapse Workspace o Azure Data Factory bajo el mismo inquilino de Microsoft Entra que su inquilino de Power Apps.
- Cree una instancia de Azure Synapse Link para Dataverse con la actualización incremental de carpetas habilitada para establecer el intervalo de tiempo. Más información: Consultar y analizar las actualizaciones incrementales
- El proveedor de Microsoft.EventGrid debe estar registrado para desencadenarse. Más información: Azure Portal. Nota: Si usa esta característica en Azure Synapse Analytics, asegúrese de que la suscripción también está registrada con el proveedor de recursos de Data Factory; de lo contrario, recibirá un error que indica que se produjo un error en la creación de una "suscripción de eventos".
- Cree una base de datos de Azure SQL con la opción Permitir que los servicios y recursos de Azure accedan a esta propiedad de servidor habilitada. Más información: ¿Qué debo saber al configurar mi instancia de Azure SQL Database (PaaS)?
- Cree y configure una instancia de Azure Integration Runtime. Más información: Creación del entorno de ejecución de integración de Azure: Azure Data Factory y Azure Synapse
Importante
El uso de esta plantilla puede incurrir en costos adicionales. Estos costos están relacionados con el uso de la canalización del área de trabajo de Azure Data Factory o Synapse y se facturan mensualmente. El costo de usar canalizaciones depende principalmente del intervalo de tiempo para la actualización incremental y los volúmenes de datos. Para planear y administrar el costo de usar esta característica, vaya a: Supervisión de los costos en el nivel de canalización con análisis de costos
Es importante tener en cuenta estos costos adicionales al decidir usar esta plantilla, ya que no son opcionales y deben pagarse para seguir usando esta característica.
Uso de la plantilla de solución
- Vaya a Azure Portal y abra el área de trabajo de Azure Synapse.
- Seleccione Integrar>Galería de navegación.
- Seleccione Copy Dataverse data into Azure SQL using Synapse Link (Copiar datos de Dataverse en Azure SQL mediante Synapse Link ) en la galería de integración.
Configuración de la plantilla de solución
Cree un servicio vinculado a Azure Data Lake Storage Gen2, que está conectado a Dataverse mediante el tipo de autenticación adecuado. Para ello, seleccione Probar conexión para validar la conectividad y, a continuación, seleccione Crear.
De forma similar a los pasos anteriores, cree un servicio vinculado a Azure SQL Database donde se sincronizarán los datos de Dataverse.
Una vez configuradas las entradas , seleccione Usar esta plantilla.

Ahora se puede agregar un desencadenador para automatizar esta canalización, de modo que la canalización siempre pueda procesar archivos cuando las actualizaciones incrementales se completen periódicamente. Vaya a Administrar>desencadenador y cree un desencadenador con las siguientes propiedades:
- Nombre: escriba un nombre para el desencadenador, como triggerModelJson.
- Tipo: eventos de almacenamiento.
- Suscripción de Azure: seleccione la suscripción que tiene Azure Data Lake Storage Gen2.
- Nombre de la cuenta de almacenamiento: seleccione el almacenamiento que tiene datos de Dataverse.
- Nombre del contenedor: seleccione el contenedor creado por Azure Synapse Link.
- La ruta de acceso del blob termina con: /model.json
- Evento: Blob creado.
- Omitir blobs vacíos: Sí.
- Desencadenador de inicio: habilite el desencadenador Inicio al crearlo.
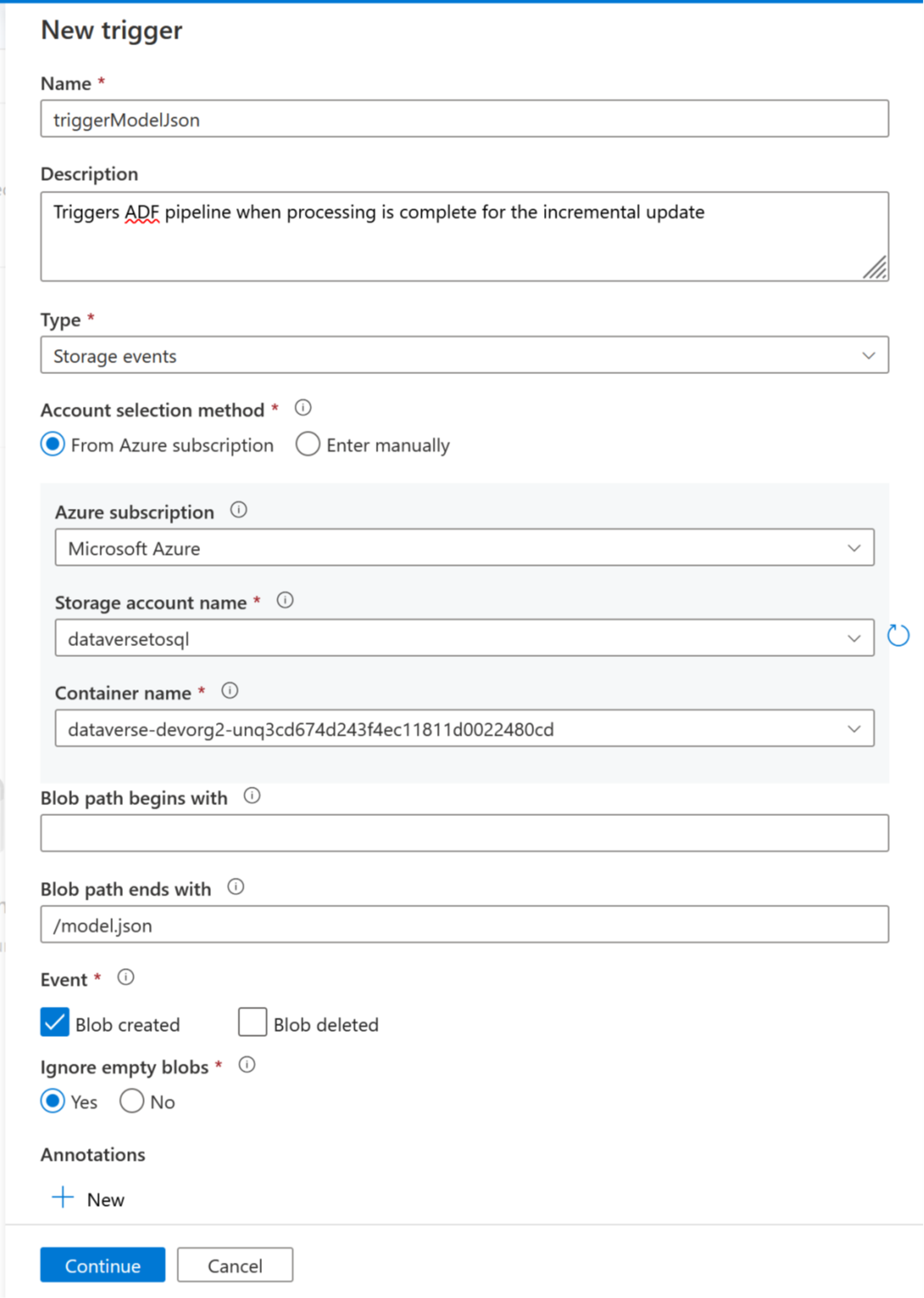
Seleccione Continuar para continuar con la siguiente pantalla.
En la pantalla siguiente, el desencadenador valida los archivos coincidentes. Seleccione Aceptar para crear el desencadenador.
Asocie el desencadenador a una canalización. Vaya a la canalización importada anteriormente y seleccione Agregar desencadenador>Nuevo/Editar.

Seleccione el desencadenador en el paso anterior y, a continuación, seleccione Continuar para continuar con la siguiente pantalla donde el desencadenador valida los archivos coincidentes.
Seleccione Continuar para continuar con la siguiente pantalla.
En la sección Trigger Run Parameter (Parámetro de ejecución del desencadenador ), escriba los parámetros siguientes y, a continuación, seleccione Aceptar.
-
Contenedor:
@split(triggerBody().folderPath,'/')[0] -
Carpeta:
@split(triggerBody().folderPath,'/')[1]
-
Contenedor:
Después de asociar el desencadenador con la canalización, seleccione Validar todo.
Una vez que la validación se realiza correctamente, seleccione Publicar todo.

Seleccione Publicar para publicar todos los cambios.



Adición de un filtro de suscripción de eventos
Para asegurarse de que el desencadenador se activa solo cuando se completa la creación de model.json, es necesario actualizar los filtros avanzados para la suscripción de eventos del desencadenador. Un evento se registra en la cuenta de almacenamiento la primera vez que se ejecuta el desencadenador.
Una vez completada la ejecución de un desencadenador, vaya a la cuenta de almacenamiento >Eventos>Suscripciones de eventos.
Seleccione el evento que se registró para el desencadenador de model.json.

Seleccione la pestaña Filtros y, a continuación, seleccione Agregar nuevo filtro.

Cree el filtro:
- Clave: asunto
- Operador: La cadena no termina con
- Valor: /blobs/model.json
Quite el parámetro CopyBlob de la matriz data.apiValue .
Seleccione Guardar para implementar el filtro adicional.
