Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Microsoft Fabric
Azure Data Factory
Les organisations doivent généralement collecter des données à partir de plusieurs sources dans différents formats et les déplacer vers un ou plusieurs magasins de données. La destination peut ne pas être le même type de magasin de données que la source, et les données doivent souvent être mises en forme, nettoyées ou transformées avant le chargement.
Divers outils, services et processus aident à relever ces défis. Quelle que soit l’approche, vous devez coordonner le travail et appliquer des transformations de données dans le pipeline de données. Les sections suivantes mettent en évidence les méthodes et pratiques courantes pour ces tâches.
Processus ETL (extraction, transformation et chargement)
Extraire, transformer, charger (ETL) est un processus d’intégration de données qui consolide les données provenant de diverses sources dans un magasin de données unifié. Pendant la phase de transformation, les données sont modifiées en fonction des règles métier à l’aide d’un moteur spécialisé. Cela implique souvent des tables intermédiaires qui contiennent temporairement des données au fur et à mesure qu’elles sont traitées et finalement chargées dans sa destination.

La transformation des données qui a lieu implique généralement plusieurs opérations, comme le filtrage, le tri, l’agrégation, la jointure des données, le nettoyage des données, la déduplication et la validation des données.
Souvent, les trois phases ETL s’exécutent en parallèle pour gagner du temps. Par exemple, pendant que les données sont extraites, un processus de transformation peut travailler sur les données déjà reçues et les préparer pour le chargement, et un processus de chargement peut commencer à travailler sur les données préparées, plutôt que d’attendre que l’ensemble du processus d’extraction se termine. Vous concevez généralement la parallélisation autour des limites de partition de données (date, locataire, clé de partition) pour éviter la contention d’écriture et activer les nouvelles tentatives idempotentes.
Service approprié :
Autres outils :
Extraction, chargement, transformation (ELT)
Le processus Extraction, chargement, transformation (ELT) diffère de l'ETL uniquement par l'endroit où la transformation a lieu. Dans le pipeline ELT, la transformation se produit dans le magasin de données cible. Au lieu d’utiliser un moteur de transformation distinct, les fonctionnalités de traitement du magasin de données cible sont utilisées pour transformer les données. Cela simplifie l’architecture en supprimant le moteur de transformation du pipeline. Un autre avantage de cette approche est que la montée en puissance du magasin de données cible permet également la montée en puissance des performances du pipeline ELT. Toutefois, ELT fonctionne bien uniquement lorsque le système cible est suffisamment puissant pour transformer les données de manière efficace.

Les scénarios d’utilisation classiques d’ELT concernent le domaine du Big Data. Par exemple, vous pouvez commencer par extraire des données sources dans des fichiers plats dans un stockage évolutif, tel qu’un système de fichiers distribué Hadoop (HDFS), un stockage d’objets blob Azure ou Azure Data Lake Storage Gen2. Les technologies telles que Spark, Hive ou PolyBase peuvent ensuite être utilisées pour interroger les données sources. Le point clé avec ELT est que le magasin de données utilisé pour effectuer la transformation est le même magasin de données que celui où les données sont finalement consommées. Ce magasin de données lit directement à partir du stockage évolutif, au lieu de charger les données dans son propre stockage distinct. Cette approche ignore les étapes de copie de données présentes dans ETL, ce qui peut souvent prendre du temps pour les jeux de données volumineux. Certaines charges de travail matérialisent des tables ou vues transformées pour améliorer les performances des requêtes ou appliquer des règles de gouvernance ; ELT n’implique pas toujours de transformations purement virtualisées.
La dernière phase du pipeline ELT transforme généralement les données sources dans un format plus efficace pour les types de requêtes qui doivent être pris en charge. Par exemple, les données peuvent être partitionnés par des clés couramment filtrées. ELT peut également utiliser des formats de stockage optimisés tels que Parquet, qui est un format de stockage en colonnes qui organise les données par colonne pour permettre la compression, le prédicat pushdown et des analyses analytiques efficaces.
Service Microsoft approprié :
Choix d’ETL ou ELT
Le choix entre ces approches dépend de vos besoins.
Choisissez ETL quand :
- Vous devez décharger les transformations lourdes loin d’un système cible contraint
- Les règles métier complexes nécessitent des moteurs de transformation spécialisés
- Les exigences réglementaires ou de conformité imposent des audits intermédiaires organisés avant le chargement
Choisissez ELT quand :
- Votre système cible est un entrepôt de données moderne ou lakehouse avec une mise à l’échelle élastique du calcul
- Vous devez conserver les données brutes pour l’analyse exploratoire ou l’évolution future du schéma
- La logique de transformation tire parti des fonctionnalités natives du système cible
Flux de données et flux de contrôle
Dans le contexte de pipelines de données, le flux de contrôle garantit le traitement de façon ordonnée d’un ensemble de tâches. Pour appliquer l’ordre de traitement correct de ces tâches, des contraintes de priorité sont utilisées. Vous pouvez considérer ces contraintes comme des connecteurs dans un diagramme de flux de travail, comme illustré dans l’image suivante. Chaque tâche a un résultat, comme la réussite, l’échec ou l’achèvement. Toute tâche ultérieure ne lance pas le traitement tant que son prédécesseur n’a pas terminé avec l’un de ces résultats.
Les flux de contrôle exécutent les flux de données en tant que tâche. Dans une tâche de flux de données, les données sont extraites d’une source, transformées ou chargées dans un magasin de données. La sortie d'une tâche de flux de données peut correspondre à l'entrée de la prochaine tâche de flux de données, et les flux de données peuvent s'exécuter en parallèle. Contrairement aux flux de contrôle, vous ne pouvez pas ajouter de contraintes entre les tâches d’un flux de données. Toutefois, vous pouvez ajouter une visionneuse de données afin d’observer les données lorsqu’elles sont traitées par chaque tâche.

Dans le diagramme, il existe plusieurs tâches dans le flux de contrôle, dont l’une est une tâche de flux de données. L’une des tâches est imbriquée dans un conteneur. Les conteneurs peuvent être utilisés pour donner une structure aux tâches, fournissant une unité de travail. La répétition d’éléments dans une collection, comme des fichiers dans un dossier ou des instructions dans une base de données, en est un exemple.
Service approprié :
ETL inversé
L’ETL inverse est le processus de déplacement de données transformées, modélisées de systèmes analytiques en outils opérationnels et applications. Contrairement à l’ETL classique, qui transfère les données des systèmes opérationnels à l’analytique, etL inverse active les insights en renvoyant les données organisées à l’endroit où les utilisateurs professionnels peuvent agir dessus. Dans un pipeline ETL inverse, les flux de données provenant d’entrepôts de données, de lakehouses ou d’autres magasins analytiques vers des systèmes opérationnels tels que :
- Plateformes de gestion des relations client (CRM)
- Outils d’automatisation marketing
- Systèmes de support client
- Bases de données de charge de travail
L’approche suit toujours un processus d’extraction, de transformation et de chargement. L’étape de transformation consiste à convertir à partir du format spécifique utilisé par votre entrepôt de données ou un autre système d’analytique pour vous aligner sur les systèmes cibles.
Pour obtenir un exemple , consultez extraction inversée, transformation et chargement (ETL) avec Azure Cosmos DB pour NoSQL .
Architectures de flux de données et de chemin d’accès chaud
Lorsque vous avez besoin d’un chemin d’accès chaud Lambda ou d’architectures Kappa, vous pouvez vous abonner à des sources de données à mesure que des données sont générées. Contrairement à ETL ou ELT, qui fonctionnent sur des jeux de données dans des lots planifiés, le streaming en temps réel traite les données à mesure qu’elles arrivent, ce qui permet des insights et des actions immédiats.
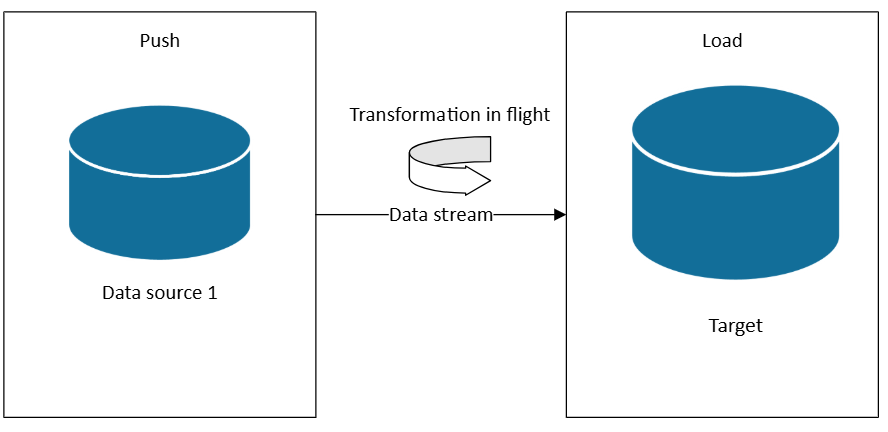
Dans une architecture de diffusion en continu, les données sont ingérées à partir de sources d’événements dans un répartiteur de messages ou un hub d’événements (par exemple, Azure Event Hubs ou Kafka), puis traitées par un processeur de flux (par exemple, Fabric Real-Time Intelligence, Azure Stream Analytics ou Apache Flink). Le processeur applique des transformations telles que le filtrage, l’agrégation, l’enrichissement ou la jointure avec des données de référence, toutes en mouvement, avant de router les résultats vers des systèmes en aval tels que des tableaux de bord, des alertes ou des bases de données.
Cette approche est idéale pour les scénarios où les mises à jour continues et à faible latence sont essentielles, telles que :
- Surveillance de l’équipement de fabrication pour les anomalies
- Détection d’une fraude dans les transactions financières
- Alimentation des tableaux de bord en temps réel pour la logistique ou les opérations
- Déclenchement d’alertes basées sur des seuils de capteur
Considérations relatives à la fiabilité pour la diffusion en continu
- Utiliser le point de contrôle pour garantir au moins une fois le traitement et la récupération contre les défaillances
- Transformations de conception à idempotentes pour gérer le traitement en double potentiel
- Implémenter le filigrane pour les événements arrivés en retard et le traitement hors commande
- Utiliser des files d’attente de lettres mortes pour les messages qui ne peuvent pas être traités
Choix de technologie
Magasins de données :
- Magasins de données de traitement transactionnel en ligne (OLTP)
- Magasins de données de traitement analytique en ligne (OLAP)
- Entrepôts de données
Pipeline et orchestration :
- Orchestration de pipeline
- Microsoft Fabric Data Factory (orchestration moderne)
- Azure Data Factory (scénarios hybrides et non-Fabric)
Lakehouse et l’analytique moderne :