Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Remarque
Il s’agit d’instructions pour l’interface de création de cluster UI,et elles ne sont incluses que pour la précision historique. Tous les clients doivent utiliser l’interface utilisateur de création de cluster mise à jour.
Cet article explique les options de configuration disponibles lorsque vous créez et modifiez des clusters Azure Databricks. Il se concentre sur la création et la modification de clusters à l’aide de l’interface utilisateur. Pour d’autres méthodes, consultez l’interface CLI Databricks, l’API Clusters et le fournisseur Terraform Databricks.
Pour vous aider à déterminer quelle combinaison d’options de configuration convient le mieux à vos besoins, consultez les meilleures pratiques de configuration de cluster.

Stratégie de cluster
Une stratégie de cluster limite la possibilité de configurer des clusters en fonction d’un ensemble de règles. Les règles de stratégie limitent les attributs ou les valeurs d’attributs disponibles pour la création du cluster. Les stratégies de cluster ont des listes de contrôle d’accès qui limitent leur utilisation à des utilisateurs et des groupes spécifiques et limitent donc les stratégies que vous pouvez sélectionner lorsque vous créez un cluster.
Pour configurer une stratégie de cluster, sélectionnez la stratégie de cluster dans la liste déroulante Stratégie .

Remarque
Si aucune stratégie n’a été créée dans l’espace de travail, la liste déroulante Stratégie ne s’affiche pas.
Si vous avez :
- L’autorisation de création de cluster vous permet de sélectionner la stratégie illimitée et de créer des clusters entièrement configurables. La stratégie illimitée ne limite pas les attributs de cluster ou les valeurs d’attribut.
- Les deux clusters créent des autorisations et l’accès aux stratégies de cluster, vous pouvez sélectionner la stratégie sans restriction et les stratégies à laquelle vous avez accès.
- Accès aux stratégies de cluster uniquement, vous pouvez sélectionner les stratégies auxquelles vous avez accès.
Mode Cluster
Remarque
Cet article décrit l’interface utilisateur des clusters héritée. Pour plus d’informations sur la nouvelle interface utilisateur des clusters (en préversion), consultez la référence de configuration de calcul. Cela inclut certaines modifications terminologiques pour les types et modes d’accès au cluster. Pour une comparaison entre les nouveaux types de clusters et les clusters hérités, voir les modifications apportées à l’interface utilisateur des clusters et les modes d’accès au cluster. Dans l’interface utilisateur en préversion :
- Les clusters en mode standard sont désormais appelés clusters sans isolation en mode d’accès partagé.
- Les clusters à haute concurrence avec les ACL des tables sont désormais appelés clusters en mode d'accès partagé.
Azure Databricks prend en charge trois modes de cluster : Standard, Haute concurrence et Nœud unique. Le mode de cluster par défaut est Standard.
Important
- Si votre espace de travail est affecté à un metastore du catalogue Unity , les clusters à haute concurrence ne sont pas disponibles. Au lieu de cela, vous utilisez le mode d’accès pour garantir l’intégrité des contrôles d’accès et appliquer des garanties d’isolation fortes. Consultez également Access modes.
- Vous ne pouvez pas modifier le mode de cluster après la création d’un cluster. Si vous souhaitez utiliser un autre mode de cluster, vous devez créer un nouveau cluster.
La configuration du cluster inclut un paramètre d’arrêt automatique dont la valeur par défaut dépend du mode cluster :
- Les clusters standard et à nœud unique se terminent automatiquement après 120 minutes par défaut.
- Les clusters à accès concurrentiel élevé ne se terminent pas automatiquement par défaut.
Clusters Standard
Avertissement
Les clusters en mode standard (parfois appelés clusters partagés sans isolation) peuvent être partagés par plusieurs utilisateurs, sans isolation entre les utilisateurs. Si vous utilisez le mode Cluster à concurrence élevée sans paramètres de sécurité supplémentaires tels que des listes de contrôle d’accès aux tables ou le passage des informations d’identification, les mêmes paramètres sont utilisés comme clusters en mode Standard. Les administrateurs de compte peuvent empêcher la génération automatique d’informations d’identification internes pour les administrateurs de l’espace de travail Databricks sur ces types de cluster. Pour des options plus sécurisées, Databricks recommande des alternatives telles que des clusters haute concurrence avec des listes de contrôle d’accès de table.
Un cluster standard est recommandé pour un seul utilisateur. Les clusters standard peuvent exécuter des charges de travail développées en Python, SQL, R et Scala.
Clusters à haute concurrence
Un cluster à concurrence élevée est une ressource Cloud gérée. Les principaux avantages des clusters à concurrence élevée sont qu’ils fournissent un partage affiné pour une utilisation maximale des ressources et des latences de requête minimales.
Les clusters à concurrence élevée peuvent exécuter des charges de travail développées dans SQL, Python et R. Les performances et la sécurité des clusters à haute concurrence sont assurées par l’exécution de code utilisateur dans des processus distincts, ce qui n’est pas possible dans Scala.
En outre, seuls les clusters à concurrence élevée prennent en charge le contrôle d’accès aux tables.
Pour créer un cluster à accès concurrentiel élevé, définissez le mode cluster sur Haute concurrence.

Clusters à nœud unique
Un cluster à nœud unique n’a aucun travail et exécute des tâches Spark sur le nœud du pilote.
En revanche, un cluster Standard nécessite au moins un nœud Worker Spark en plus du nœud de pilote pour exécuter des travaux Spark.
Pour créer un cluster à nœud unique, définissez le mode cluster sur Nœud unique.
Pour en savoir plus sur l’utilisation des clusters à nœud unique, consultez le calcul à nœud unique.
Piscines
Pour réduire le temps de début du cluster, vous pouvez attacher un cluster à un pool prédéfini d’instances inactives, pour les nœuds de pilote et de travail. Le cluster est créé à l’aide d’instances dans les pools. Si un pool ne dispose pas de suffisamment de ressources inactives pour créer le pilote ou les nœuds de travail demandés, le pool s'étend en allouant de nouvelles instances à partir du fournisseur d'instances. Quand un cluster attaché est arrêté, les instances qu’il utilisait sont retournées au pool et peuvent être réutilisées par un autre cluster.
Si vous sélectionnez un pool pour les nœuds Worker, mais pas pour le nœud Driver, le nœud Driver hérite du pool de la configuration du nœud Worker.
Important
Si vous tentez de sélectionner un pool pour le nœud de pilote, mais pas pour les nœuds Worker, une erreur se produit et votre cluster n’est pas créé. Cette exigence empêche une situation où le nœud de pilote doit attendre la création de nœuds Worker, ou vice versa.
Consultez la référence de configuration du pool pour en savoir plus sur l’utilisation des pools dans Azure Databricks.
Databricks Runtime
Les runtimes Databricks sont l’ensemble de composants principaux qui s’exécutent sur vos clusters. Tous les runtimes Databricks incluent des Apache Spark et ajoutent des composants et des mises à jour qui améliorent la convivialité, les performances et la sécurité. Pour plus d’informations, consultez les versions et la compatibilité des notes de publication de Databricks Runtime.
Azure Databricks propose plusieurs types de runtimes et plusieurs versions de ces types d’exécution dans la liste déroulante Version du runtime Databricks lorsque vous créez ou modifiez un cluster.
Accélération Photon
Photon est disponible pour les clusters exécutant Databricks Runtime 9.1 LTS et versions ultérieures .
Pour activer l’accélération photon, cochez la case Utiliser l’accélération photon .
Si vous le souhaitez, vous pouvez spécifier le type d’instance dans la liste déroulante Type de worker et Type de pilote.
Databricks recommande les types d’instances suivants pour un prix optimal et des performances optimales :
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
Vous pouvez afficher l’activité Photon dans l’interface utilisateur Spark. La capture d’écran suivante montre les détails de la requête DAG. Il existe deux indications de photons dans le DAG. Tout d’abord, les opérateurs de photons commencent par « photons », par exemple, PhotonGroupingAgg . Deuxièmement, dans le DAG, les opérateurs et les phases de photons sont des pêches de couleur, tandis que les autres sont bleus.

Images Docker
Pour certaines versions de Databricks Runtime, vous pouvez spécifier une image d’ancrage lorsque vous créez un cluster. Les exemples de cas d’usage incluent la personnalisation de la bibliothèque, un environnement de conteneur doré qui ne change pas et l’intégration CI/CD Docker.
Vous pouvez également utiliser des images Docker pour créer des environnements personnalisés de deep learning (apprentissage profond) sur des clusters avec des périphériques GPU.
Pour obtenir des instructions, consultez Personnaliser les conteneurs avec Databricks Container Service et Databricks Container Services sur le calcul GPU.
Type de nœud de cluster
Un cluster se compose d’un nœud de pilote et de zéro ou plusieurs nœuds de travail.
Vous pouvez choisir des types d’instances de fournisseur de Cloud distincts pour les nœuds de pilote et de travail, bien que le nœud de pilote utilise par défaut le même type d’instance que le nœud Worker. Différentes familles de types d'instances correspondent à différents cas d'utilisation, tels que les charges de travail à forte intensité de mémoire ou de calcul.
Remarque
Si vos exigences de sécurité incluent l’isolation du calcul, sélectionnez une instance Standard_F72s_V2 comme type de worker. Ces types d'instance représentent des machines virtuelles isolées qui consomment la totalité de l'hôte physique et fournissent le niveau d'isolation nécessaire pour prendre en charge, par exemple, les charges de travail de niveau d'impact 5 (IL5) du ministère américain de la Défense.
Nœud de pilote
Le nœud de pilote conserve les informations d’état de tous les blocs-notes attachés au cluster. Le nœud de pilote gère également le SparkContext et interprète toutes les commandes que vous exécutez à partir d’un Notebook ou d’une bibliothèque sur le cluster, et exécute le maître Apache Spark qui coordonne avec les exécuteurs Spark.
La valeur par défaut du type de nœud du pilote est identique à celle du type de nœud Worker. Vous pouvez choisir un plus grand type de nœud de pilote avec davantage de mémoire si vous envisagez collect() de nombreuses données des Workers Spark et de les analyser dans le bloc-notes.
Conseil
Étant donné que le nœud pilote conserve toutes les informations d’état des blocs-notes attachés, veillez à détacher les blocs-notes inutilisés du nœud pilote.
Nœud Worker
Azure Databricks nœuds Worker exécutent les exécuteurs Spark et d’autres services requis pour le bon fonctionnement des clusters. Lorsque vous distribuez votre charge de travail avec Spark, tout le traitement distribué se produit sur les nœuds Worker. Azure Databricks exécute un exécuteur par nœud Worker ; par conséquent, les termes exécuteur et worker sont utilisés de manière interchangeable dans le contexte de l’architecture Azure Databricks.
Conseil
Pour exécuter un travail Spark, vous avez besoin d’au moins un nœud Worker. Si un cluster ne possède aucun Worker, vous pouvez exécuter des commandes non-Spark sur le pilote, mais les commandes Spark échouent.
Types d’instances GPU
Pour les tâches nécessitant de nombreuses ressources de calcul qui exigent des performances élevées, comme celles associées à l’apprentissage profond, Azure Databricks prend en charge les clusters accélérés avec des unités de traitement graphique (GPU). Pour plus d’informations, consultez le calcul avec GPU.
Instances spot
Pour économiser des coûts, vous pouvez choisir d’utiliser des instances spot, également appelées machines virtuelles Azure Spot en cochant la case instances Spot .

La première instance est toujours à la demande (le nœud de pilote est toujours à la demande) et les instances suivantes sont des instances de place. Si des instances ponctuelles sont évincées pour cause d'indisponibilité, des instances à la demande sont déployées pour remplacer les instances évincées.
Taille de cluster et mise à l’échelle automatique
Lorsque vous créez un cluster Azure Databricks, vous pouvez fournir un nombre fixe de workers pour le cluster ou fournir un nombre minimal et maximal de workers pour le cluster.
Lorsque vous fournissez un cluster de taille fixe, Azure Databricks garantit que votre cluster a le nombre spécifié de threads de travail. Lorsque vous fournissez une plage pour le nombre de Workers, Azure Databricks choisit le nombre approprié de Workers requis pour exécuter votre travail. Il s’agit de la mise à l’échelle automatique.
Avec la mise à l'échelle automatique, Azure Databricks réaffecte dynamiquement les workers pour tenir compte des caractéristiques de votre travail. Certaines parties de votre pipeline peuvent être plus exigeantes en calcul que d’autres, et Databricks ajoute automatiquement des workers supplémentaires pendant ces phases de votre travail (et les supprime lorsqu’ils ne sont plus nécessaires).
La mise à l’échelle automatique facilite l’optimisation de l’utilisation du cluster, car vous n’avez pas besoin de provisionner le cluster en fonction d’une charge de travail. Cela s’applique en particulier aux charges de travail dont les exigences changent au fil du temps (comme l’exploration d’un jeu de données au cours d’une journée), mais elle peut également s’appliquer à une charge de travail unique plus rapide dont les exigences de provisionnement sont inconnues. La mise à l’échelle automatique offre donc deux avantages :
- Les charges de travail peuvent s’exécuter plus rapidement qu’avec un cluster sous-approvisionné de taille constante.
- La mise à l’échelle automatique des clusters peut réduire les coûts globaux par rapport à un cluster de taille statique.
En fonction de la taille constante du cluster et de la charge de travail, la mise à l’échelle automatique vous offre l’un ou l’autre de ces avantages en même temps. La taille du cluster peut être inférieure au nombre minimal de Workers sélectionnés lorsque le fournisseur de Cloud met fin aux instances. Dans ce cas, Azure Databricks tente continuellement de réapprovisionner les instances afin de conserver le nombre minimal de threads de travail.
Remarque
La mise à l’échelle automatique n’est pas disponible pour les travaux spark-submit.
Comportement de la mise à l'échelle automatique
- La mise à l’échelle est comprise entre min et Max en 2 étapes.
- Peut monter en puissance même si le cluster n’est pas inactif en examinant l’état de lecture aléatoire des fichiers.
- Met à l’échelle en fonction d’un pourcentage de nœuds actuels.
- Sur les clusters de travail, descend en charge si le cluster est sous-exploité au cours des 40 dernières secondes.
- Sur les clusters polyvalents, réduit l'échelle si le cluster est sous-utilisé au cours des 150 dernières secondes.
- La propriété de configuration Spark
spark.databricks.aggressiveWindowDownSspécifie, en secondes, la fréquence à laquelle un cluster prend les décisions de mise à l’échelle. Si vous augmentez la valeur, un cluster est plus lent. La valeur maximale est 600.
Activer et configurer la mise à l'échelle automatique
Pour permettre à Azure Databricks de redimensionner automatiquement votre cluster, vous activez la mise à l’échelle automatique pour le cluster et fournissez la plage de travail minimale et maximale.
Activez la mise à l’échelle automatique.
All-Purpose cluster : dans la page Créer un cluster, cochez la case Activer la mise à l’échelle automatique dans la zone Options Autopilot :

Cluster de travaux : dans la page Configurer le cluster, cochez la case Activer la mise à l’échelle automatique dans la zone Options Autopilot :

Configurez les Workers min et max.

Lorsque le cluster est en cours d’exécution, la page Détails du cluster affiche le nombre de travailleurs alloués. Vous pouvez comparer le nombre de Workers alloués à la configuration du Worker et effectuer les ajustements nécessaires.
Important
Si vous utilisez un pool d’instances :
- Vérifiez que la taille du cluster demandée est inférieure ou égale au nombre minimal d’instances inactives dans le pool. S’il est plus grand, le temps de démarrage du cluster équivaut à un cluster qui n’utilise pas de pool.
- Vérifiez que la taille maximale du cluster est inférieure ou égale à la capacité maximale du pool. Si elle est supérieure, la création du cluster échoue.
Exemple de mise à l’échelle automatique
Si vous reconfigurez un cluster statique pour qu’il soit un cluster de mise à l’échelle automatique, Azure Databricks redimensionne immédiatement le cluster dans les limites minimale et maximale, puis démarre la mise à l’échelle automatique. Par exemple, le tableau suivant montre ce qui se passe aux clusters avec une certaine taille initiale si vous reconfigurez un cluster pour la mise à l’échelle automatique entre 5 et 10 nœuds.
| Taille initiale | Taille après reconfiguration |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Mise à l’échelle automatique du stockage local
Il est souvent difficile d'estimer l'espace disque que prendra une tâche particulière. Pour vous éviter d'avoir à estimer le nombre de gigaoctets de disque géré à joindre à votre cluster au moment de la création, Azure Databricks active automatiquement le stockage local à mise à l'échelle automatique sur tous les clusters Azure Databricks.
Avec la mise à l’échelle automatique du stockage local, Azure Databricks surveille la quantité d’espace disque disponible sur les workers Spark de votre cluster. Si un Worker commence à s’exécuter trop peu sur le disque, Databricks joint automatiquement un nouveau disque géré au Worker avant que l’espace disque soit insuffisant. Les disques sont attachés à une limite de 5 To d’espace disque total par machine virtuelle (y compris le stockage local initial de la machine virtuelle).
Les disques managés attachés à une machine virtuelle sont détachés uniquement quand la machine virtuelle est retournée à Azure. En d'autres termes, les disques gérés ne sont jamais détachés d'une machine virtuelle tant qu'elle fait partie d'un cluster en cours d'exécution. Pour réduire l’utilisation du disque managé, Azure Databricks recommande d’utiliser cette fonctionnalité dans un cluster configuré avec la taille du cluster et la mise à l’échelle automatique ou l’arrêt automatique.
Chiffrement de disque local
Important
Cette fonctionnalité est disponible en préversion publique.
Certains types d’instances que vous utilisez pour exécuter des clusters peuvent avoir des disques attachés localement. Azure Databricks pouvez stocker des données de lecture aléatoire ou des données éphémères sur ces disques attachés localement. Pour vous assurer que toutes les données au repos sont chiffrées pour tous les types de stockage, y compris les données aléatoires stockées temporairement sur les disques locaux de votre cluster, vous pouvez activer le chiffrement de disque local.
Important
Vos charges de travail peuvent s’exécuter plus lentement en raison de l’impact sur les performances de la lecture et de l’écriture de données chiffrées vers et à partir des volumes locaux.
Lorsque le chiffrement de disque local est activé, Azure Databricks génère une clé de chiffrement localement qui est unique pour chaque nœud de cluster et est utilisée pour chiffrer toutes les données stockées sur les disques locaux. La portée de la clé est locale pour chaque nœud de cluster et est détruite en même temps que le nœud de cluster lui-même. Pendant sa durée de vie, la clé se trouve dans la mémoire pour le chiffrement et le déchiffrement et est stockée chiffrée sur le disque.
Pour activer le chiffrement de disque local, vous devez utiliser l’API Clusters. Lors de la création ou de la modification d’un cluster, définissez :
{
"enable_local_disk_encryption": true
}
Consultez l’API Clusters pour obtenir des exemples d’appel de ces API.
Voici un exemple d’un appel de création de cluster qui active le chiffrement de disque local :
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Mode de sécurité
Si votre espace de travail est attribué à un metastore Unity Catalog, vous utilisez le mode de sécurité au lieu du mode Cluster à concurrence élevée pour garantir l’intégrité des contrôles d’accès et appliquer des garanties d’isolation forte. Le mode de cluster à concurrence élevée n’est pas disponible avec Unity Catalog.
Sous Options avancées, sélectionnez les modes de sécurité de cluster suivants :
- Aucun : Aucune isolation. N’applique ni le contrôle d’accès aux tables à l’échelle de l’espace de travail, ni le passage directe des informations d’identification. Ne peut pas accéder aux données Unity Catalog.
- Utilisateur unique : ne peut être utilisé que par un seul utilisateur (par défaut, l’utilisateur qui a créé le cluster). Les autres utilisateurs ne peuvent pas s’attacher au cluster. Lorsque vous accédez à une vue à partir d’un cluster avec le mode de sécurité mono-utilisateur , la vue est exécutée avec les autorisations de l’utilisateur. Les clusters mono-utilisateurs prennent en charge les charges de travail à l’aide de scripts Python, Scala et R. Les scripts Init, l’installation de bibliothèque et les montages DBFS sont pris en charge sur des clusters mono-utilisateurs. Les travaux automatisés doivent utiliser des clusters à utilisateur unique.
- Isolation de l’utilisateur : peut être partagée par plusieurs utilisateurs. Seules les charges de travail SQL sont prises en charge. L’installation de bibliothèque, les scripts d’initialisation et les montages DBFS sont désactivés afin d’appliquer une isolation stricte entre les utilisateurs du cluster.
- Liste de contrôle d’accès aux tables (hérité) : applique un contrôle d’accès aux tables à l’échelle de l’espace de travail, mais ne peut pas accéder aux données Unity Catalog.
- Passage direct uniquement (hérité) : applique le passage direct des informations d’identification à l’échelle de l’espace de travail, mais ne peut pas accéder aux données Unity Catalog.
Les seuls modes de sécurité pris en charge pour les charges de travail du catalogue Unity sont utilisateur unique et isolation utilisateur.
Pour plus d’informations, consultez modes d'accès.
Configuration Spark
Pour affiner les travaux Spark, vous pouvez fournir des propriétés de configuration Spark personnalisées dans une configuration de cluster.
Dans la page de configuration du cluster, cliquez sur le bouton bascule Options avancées .
Cliquez sur l’onglet Spark .

Dans la configuration Spark, entrez les propriétés de configuration comme une paire clé-valeur par ligne.
Lorsque vous configurez un cluster à l’aide de l’API cluster, définissez les propriétés Spark dans le spark_conf champ dans l’API Créer une API de cluster ou mettre à jour l’API de configuration du cluster.
Databricks ne recommande pas d'utiliser des scripts d'initialisation globaux.
Pour définir des propriétés Spark pour tous les clusters, créez un script d’init global :
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Récupérer une propriété de configuration Spark à partir d’un secret
Databricks recommande de stocker des informations sensibles, telles que des mots de passe, dans un secret plutôt que du texte en clair. Pour référencer une clé secrète dans la configuration Spark, utilisez la syntaxe suivante :
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Par exemple, pour définir une propriété de configuration Spark appelée password sur la valeur du secret stocké dans secrets/acme_app/password :
spark.password {{secrets/acme-app/password}}
Pour plus d’informations, consultez Gérer les secrets.
Variables d’environnement
Vous pouvez configurer des variables d’environnement personnalisées auxquelles vous pouvez accéder à partir de scripts init s’exécutant sur un cluster. Databricks fournit également des variables d’environnement prédéfinies que vous pouvez utiliser dans des scripts init. Vous ne pouvez pas remplacer ces variables d’environnement prédéfinies.
Dans la page de configuration du cluster, cliquez sur le bouton bascule Options avancées .
Cliquez sur l’onglet Spark .
Définissez les variables d’environnement dans le champ Variables d’environnement .
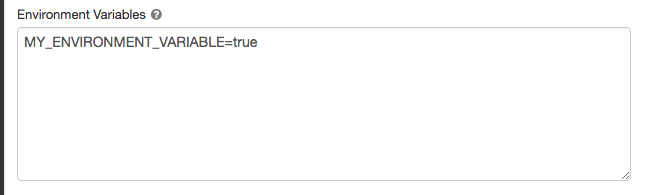
Vous pouvez également définir des variables d’environnement à l’aide du spark_env_vars champ dans l’API Créer une API de cluster ou mettre à jour l’API de configuration du cluster.
Étiquettes de cluster
Les étiquettes de cluster vous permettent de superviser facilement le coût des ressources cloud utilisées par différents groupes de votre organisation. Vous pouvez spécifier des balises en tant que paires clé-valeur lorsque vous créez un cluster, et Azure Databricks applique ces étiquettes aux ressources cloud telles que les machines virtuelles et les volumes de disque, ainsi que les rapports d’utilisation DBU.
Pour les clusters lancés à partir de pools, les balises de cluster personnalisées sont appliquées uniquement aux rapports d’utilisation DBU et ne se propagent pas aux ressources Cloud.
Pour plus d’informations sur le fonctionnement des types d’étiquettes de pool et de cluster, consultez Utiliser des balises pour attribuer et suivre l’utilisation.
Pour plus de commodité, Azure Databricks applique des étiquettes par défaut à chaque cluster : Vendor, Creator, ClusterName et ClusterId.
En outre, sur les clusters de travail, Azure Databricks applique deux balises par défaut : RunName et JobId .
Sur les ressources utilisées par Databricks SQL, Azure Databricks applique également l’étiquette par défaut suivante SqlWarehouseId:
Avertissement
N’assignez pas de balise personnalisée avec la clé Name à un cluster. Chaque cluster possède une balise Name dont la valeur est définie par Azure Databricks. Si vous modifiez la valeur associée à la clé Name , le suivi du cluster ne peut plus être effectué par Azure Databricks. Par conséquent, il se peut que le cluster ne se termine pas après avoir été inactif et continue à entraîner des coûts d’utilisation.
Vous pouvez également ajouter des étiquettes personnalisées lors de la création d’un cluster. Pour configurer des étiquettes de cluster :
Dans la page de configuration du cluster, cliquez sur le bouton bascule Options avancées .
En bas de la page, cliquez sur l’onglet Étiquettes.

Ajoutez une paire clé-valeur pour chaque balise personnalisée. Vous pouvez ajouter jusqu’à 43 étiquettes personnalisées.
Accès SSH aux clusters
Pour des raisons de sécurité, dans Azure Databricks le port SSH est fermé par défaut. Si vous souhaitez activer l’accès SSH à vos clusters Spark, contactez le support technique Azure Databricks.
Remarque
SSH ne peut être activé que si votre espace de travail est déployé dans votre propre réseau virtuel Azure.
Remise de journal de cluster
Lorsque vous créez un cluster, vous pouvez spécifier un emplacement pour la remise des journaux du nœud du pilote Spark, des nœuds de travail et des événements. Les journaux sont remis toutes les cinq minutes à la destination choisie. Lorsqu’un cluster est terminé, Azure Databricks garantit la remise de tous les journaux générés jusqu’à la fin du cluster.
La destination des journaux dépend de l’ID du cluster. Si la destination spécifiée est dbfs:/cluster-log-delivery, les journaux de cluster pour 0630-191345-leap375 sont remis à dbfs:/cluster-log-delivery/0630-191345-leap375.
Pour configurer l’emplacement de remise des journaux :
Dans la page de configuration du cluster, cliquez sur le bouton bascule Options avancées .
Cliquez sur l’onglet Journalisation .

Sélectionnez un type de destination.
Entrez le mot de passe de connexion au cluster.
Remarque
Cette fonctionnalité est également disponible dans l’API REST. Consultez l’API Clusters.
Scripts d'initialisation
Un script d’initialisation de nœud de cluster (ou init) est un script d’interpréteur de commandes qui s’exécute au démarrage de chaque nœud de cluster avant le démarrage du pilote Spark ou du JVM worker. Vous pouvez utiliser des scripts init pour installer des packages et des bibliothèques qui ne sont pas inclus dans le runtime Databricks, modifier le classpath du système JVM, définir les propriétés système et les variables d’environnement utilisées par JVM, ou modifier les paramètres de configuration Spark, parmi d’autres tâches de configuration.
Vous pouvez attacher des scripts init à un cluster en développant la section Options avancées et en cliquant sur l’onglet Scripts Init .
Pour obtenir des instructions détaillées, consultez Qu’est-ce que les scripts init ?.