Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment utiliser Apache Kafka en tant que source ou récepteur lors de l’exécution de charges de travail Structured Streaming sur Azure Databricks.
Pour plus d’informations sur Kafka, consultez la documentation Kafka.
Lire les données de Kafka
Voici un exemple pour une lecture en continu à partir de Kafka :
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks prend également en charge la sémantique de lecture par lots pour les sources de données Kafka, comme illustré dans l’exemple suivant :
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Pour le chargement par lots incrémentiel, Databricks recommande d’utiliser Kafka avec Trigger.AvailableNow. Consultez Configuration du traitement par lots incrémentiel.
Dans Databricks Runtime 13.3 LTS et versions ultérieures, Azure Databricks propose une fonction SQL pour lire les données Kafka. La diffusion en continu avec SQL est prise en charge uniquement dans les pipelines déclaratifs Spark Lakeflow ou avec des tables de diffusion en continu dans Databricks SQL. Consultez read_kafkaTVF.
Configurer le lecteur Kafka de flux structuré
Azure Databricks fournit le mot clé kafka en tant que format de données pour configurer les connexions à Kafka 0.10+.
Voici les configurations les plus courantes pour Kafka :
Il existe plusieurs façons de spécifier des rubriques auxquelles s’abonner. Vous ne devez fournir qu’un seul de ces paramètres :
| Choix | Valeur | Descriptif |
|---|---|---|
| s’inscrire | Liste séparée par des virgules des rubriques. | Liste de rubriques auxquelles s’abonner. |
| subscribePattern | Chaîne regex Java. | Modèle utilisé pour s’abonner à une ou plusieurs rubriques. |
| attribuer | Chaîne JSON {"topicA":[0,1],"topic":[2,4]}. |
TopicPartitions spécifique à consommer. |
Autres configurations notables :
| Choix | Valeur | Valeur par défaut | Descriptif |
|---|---|---|---|
| kafka.bootstrap.servers | Liste séparée par des virgules de host:port. | vide | [Obligatoire] Configuration de bootstrap.servers Kafka. Si vous constatez qu’il n’y a aucune donnée de Kafka, vérifiez d’abord la liste d’adresses du répartiteur. Si la liste d’adresses du répartiteur est incorrecte, il se peut qu’il n’y ait aucune erreur. Cela est dû au fait que le client Kafka part du principe que les répartiteurs deviendront finalement disponibles et qu’en cas d’erreurs réseau, ils effectueront de nouvelles tentatives indéfiniment. |
| failOnDataLoss |
true ou false. |
true |
[Facultatif] Indique s’il faut échouer la requête lorsqu’il est possible que les données soient perdues. Les requêtes peuvent échouer de façon permanente à lire des données à partir de Kafka dans de nombreux cas, tels que la suppression de rubriques, une troncation de rubrique avant traitement, etc. Nous essayons d’estimer prudemment si une perte de données est ou non possible. Cela peut parfois déclencher de fausses alarmes. Définissez cette option sur false si elle ne fonctionne pas comme prévu, ou si vous souhaitez que la requête poursuive le traitement en dépit d’une perte de données. |
| minPartitions | Entier >= 0, 0 = désactivé. | 0 (désactivé) | [Facultatif] Nombre minimal de partitions à lire à partir de Kafka. Vous pouvez configurer Spark pour utiliser un minimum arbitraire de partitions à lire à partir de Kafka à l’aide de l’option minPartitions. Normalement, Spark a un mappage de 1-1 des topicPartitions Kafka aux partitions Spark consommatrices de Kafka. Si vous définissez l’option minPartitions sur une valeur supérieure à celle de vos topicPartitions Kafka, Spark divise les partitions Kafka volumineuses en éléments plus petits. Cette option peut être définie aux heures des pics de charge, en cas d’asymétrie des données et lorsque votre flux prend du retard afin d’augmenter la vitesse de traitement. Cela a un coût lié à l’initialisation des consommateurs Kafka à chaque déclenchement, ce qui peut avoir un impact sur les performances si vous utilisez SSL lors de la connexion à Kafka. |
| kafka.group.id | ID de groupe de consommateurs Kafka | non défini | [Facultatif] ID de groupe à utiliser lors de la lecture à partir de Kafka. Utilisez cet option avec prudence. Par défaut, chaque requête génère un ID de groupe unique pour la lecture des données. Cela garantit que chaque requête a son propre groupe de consommateurs qui ne rencontre pas d’interférence de la part d’un autre consommateur, et peut donc lire toutes les partitions des rubriques auxquelles il est abonné. Dans certains cas (par exemple, autorisation basée sur un groupe Kafka), vous pouvez utiliser des ID de groupe autorisé spécifique pour lire les données. Vous pouvez éventuellement définir l’ID de groupe. Toutefois, faites cela avec une extrême prudence, car cela peut provoquer un comportement inattendu.
|
| startingOffsets | la plus ancienne, la plus récente | le plus récent | [Facultatif] Point de départ lors du démarrage d’une requête, soit « earliest » qui correspond aux décalages les plus précoces, soit une chaîne json spécifiant un décalage de départ pour chaque TopicPartition. Dans le json, -2 peut être utilisé pour indiquer le décalage le plus précoce, -1 pour indiquer le décalage le plus récent. Remarque : pour les requêtes par lot, le décalage le plus récent (implicitement ou à l’aide de -1 en json) n’est pas autorisé. Pour les requêtes de diffusion en continu, cela ne s’applique que lors du lancement d’une nouvelle requête, et la reprise reprendra toujours là où la requête s’est arrêtée. Les partitions nouvellement découvertes au cours d’une requête démarreront au plus tôt. |
Pour d’autres configurations facultatives, consultez le Guide d’intégration de diffusion en continu structurée Kafka.
Schéma pour les enregistrements Kafka
Le schéma des enregistrements Kafka est le suivant :
| Colonne | Type |
|---|---|
| clé | binaire |
| value | binaire |
| sujet | ficelle |
| partition | int |
| offset | long |
| horodatage | long |
| timestampType | int |
Les key et value sont toujours désérialisées en tant que tableaux d’octets avec le ByteArrayDeserializer. Utilisez des opérations DataFrame (telles que cast("string")) pour désérialiser explicitement les clés et les valeurs.
Écrire des données dans Kafka
Voici un exemple ci-après pour une écriture en streaming dans Kafka :
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks prend également en charge la sémantique d’écriture dans des récepteurs de données Kafka, comme illustré dans l’exemple suivant :
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Configurer la fonction d’écriture Kafka de flux structuré
Importante
Databricks Runtime 13.3 LTS et versions ultérieures incluent une version plus récente de la bibliothèque kafka-clients qui active par défaut les écritures idempotentes. Si un récepteur Kafka utilise la version 2.8.0 ou antérieure avec des listes de contrôle d’accès configurées, mais sans activation de IDEMPOTENT_WRITE, l’écriture échoue avec le message d’erreur org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state.
Pour résoudre cette erreur, mettez à jour vers Kafka version 2.8.0 ou supérieure, ou définissez l’option .option(“kafka.enable.idempotence”, “false”) pendant la configuration de la fonction d’écriture de flux structurés.
Le schéma fourni à DataStreamWriter interagit avec le récepteur Kafka. Vous pouvez utiliser les champs suivants :
| Nom de la colonne | Obligatoire ou facultatif | Type |
|---|---|---|
key |
facultatif |
STRING ou BINARY |
value |
requis |
STRING ou BINARY |
headers |
facultatif | ARRAY |
topic |
facultatif (ignoré si topic est défini comme option d’enregistreur) |
STRING |
partition |
facultatif | INT |
Voici les options courantes définies lors de l’écriture dans Kafka :
| Choix | Valeur | Valeur par défaut | Descriptif |
|---|---|---|---|
kafka.boostrap.servers |
Une liste des machines virtuelles séparée par des virgules de <host:port> |
aucun | [Obligatoire] Configuration de bootstrap.servers Kafka. |
topic |
STRING |
non défini | [Facultatif] Définit la rubrique pour toutes les lignes à écrire. Cette option remplace toute colonne de rubrique qui existe dans les données. |
includeHeaders |
BOOLEAN |
false |
[Facultatif] Indique s’il faut inclure les en-têtes Kafka dans la ligne. |
Pour d’autres configurations facultatives, consultez le Guide d’intégration de diffusion en continu structurée Kafka.
Récupérer des métriques Kafka
Vous pouvez obtenir la moyenne, le minimum et le maximum du nombre de décalages de requête de diffusion en continu par rapport au dernier décalage disponible parmi toutes les rubriques souscrites avec les métriques avgOffsetsBehindLatest, maxOffsetsBehindLatest et minOffsetsBehindLatest. Consultez Lecture des métriques de manière interactive.
Note
Disponible dans Databricks Runtime 9.1 et versions ultérieures.
Obtenez le nombre total estimé d’octets que le processus de requête n’a pas consommés à partir des rubriques souscrites en examinant la valeur de estimatedTotalBytesBehindLatest. Cette estimation est basée sur les lots qui ont été traités au cours des 300 dernières secondes. La période sur laquelle l’estimation est basée peut être modifiée en définissant l’option bytesEstimateWindowLength sur une valeur différente. Par exemple, pour la définir sur 10 minutes :
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Si vous exécutez le flux dans un notebook, vous pouvez voir ces métriques sous l’onglet Données brutes du tableau de bord de progression des requêtes de diffusion en continu :
{
"sources": [
{
"description": "KafkaV2[Subscribe[topic]]",
"metrics": {
"avgOffsetsBehindLatest": "4.0",
"maxOffsetsBehindLatest": "4",
"minOffsetsBehindLatest": "4",
"estimatedTotalBytesBehindLatest": "80.0"
}
}
]
}
Utiliser SSL pour connecter Azure Databricks à Kafka
Pour activer les connexions SSL à Kafka, suivez les instructions fournies dans la documentation de Confluent Chiffrement et authentification avec SSL. Vous pouvez fournir les configurations décrites ici, préfixées par kafka., comme options. Par exemple, vous spécifiez l’emplacement du magasin de confiance dans la propriété kafka.ssl.truststore.location.
Databricks vous recommande de :
- Stocker vos certificats dans le stockage d’objets cloud. Vous pouvez restreindre l’accès aux certificats uniquement aux clusters qui peuvent accéder à Kafka. Consultez la gouvernance des données avec Azure Databricks.
- Stockez vos mots de passe de certificat en tant que secrets dans une étendue de secrets.
L’exemple suivant utilise des emplacements de stockage d’objets et des secrets Databricks pour activer une connexion SSL :
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Connecter Kafka sur HDInsight à Azure Databricks
Créez un cluster Kafka sur HDInsight.
Pour obtenir des instructions, consultez Se connecter à Kafka sur HDInsight via un réseau virtuel Azure.
Configurez les répartiteurs Kafka pour qu’ils publient l’adresse correcte.
Suivez les instructions fournies dans Configurer Kafka pour la publication d’adresses IP. Si vous gérez Kafka vous-même sur des machines virtuelles Azure, assurez-vous que la configuration
advertised.listenersdes courtiers est définie sur l’adresse IP interne des hôtes.Créez un cluster Azure Databricks
Appairez le cluster Kafka au cluster Azure Databricks.
Suivez les instructions fournies dans Appairer des réseaux virtuels.
Authentification par principal de service avec Microsoft Entra ID et Azure Event Hubs
Azure Databricks prend en charge l’authentification des travaux Spark avec les services Event Hubs. Cette authentification se fait par le biais d’OAuth avec Microsoft Entra ID.
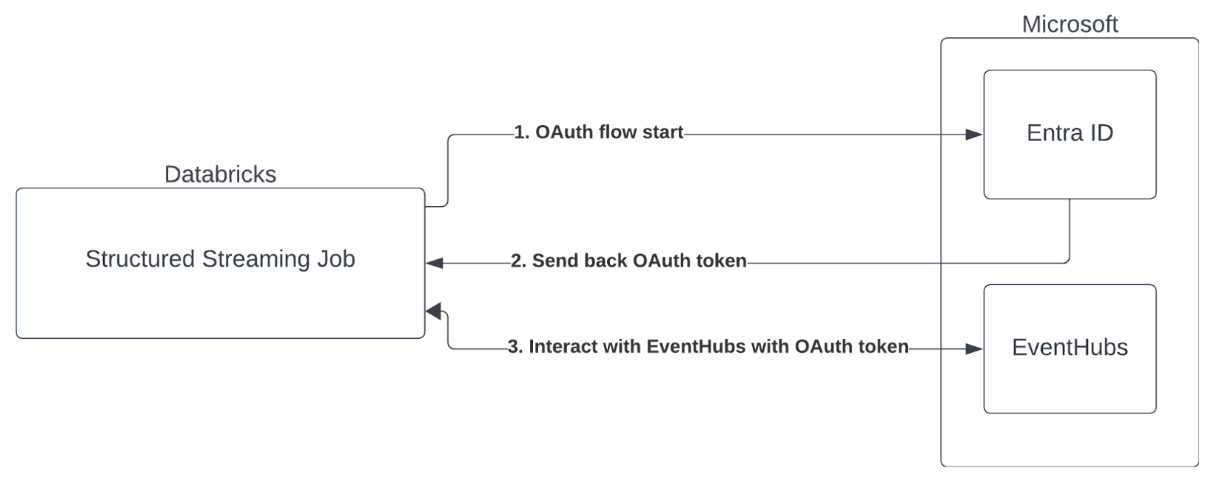
Azure Databricks prend en charge l’authentification Microsoft Entra ID avec un ID client et une clé secrète client dans les environnements Compute suivants :
- Databricks Runtime 12.2 LTS et versions ultérieures sur le calcul configuré avec le mode d’accès dédié (anciennement mode d’accès utilisateur unique).
- Databricks Runtime 14.3 LTS et versions ultérieures sur le calcul configuré avec le mode d’accès standard (anciennement mode d’accès partagé).
- Pipelines déclaratifs Spark Lakeflow configurés sans catalogue Unity.
Azure Databricks ne prend pas en charge l’authentification Microsoft Entra ID avec un certificat dans un environnement de calcul ou dans les pipelines déclaratifs Spark Lakeflow configurés avec le catalogue Unity.
Cette authentification ne fonctionne pas sur le calculateur avec le mode d'accès standard ni sur les pipelines déclaratifs Spark de Lakeflow du catalogue Unity.
Prise en charge des informations d’identification du service Unity Catalog pour AWS MSK et Azure Event Hubs
Depuis la publication de Databricks Runtime 16.1, Azure Databricks prend en charge les informations d’identification du service Catalogue Unity pour l’authentification de l’accès à AWS Managed Streaming pour Apache Kafka (MSK) et Azure Event Hubs. Azure Databricks recommande cette approche pour exécuter le streaming Kafka sur des clusters partagés et lors de l’utilisation de calcul serverless.
Pour utiliser les informations d’identification d’un service catalogue Unity pour l’authentification, procédez comme suit :
- Créez un identifiant de service pour Unity Catalog. Si vous n’êtes pas familiarisé avec ce processus, consultez Créer des informations d’identification de service pour obtenir des instructions sur la création d’un processus.
- Indiquez le nom de vos informations d’identification du service catalogue Unity en tant qu’option source dans votre configuration Kafka. Définissez l’option
databricks.serviceCredentialsur le nom de votre identifiant de service.
Remarque : Lorsque vous fournissez des informations d’identification de service catalogue Unity à Kafka, ne spécifiez pas ces options, car elles ne sont plus nécessaires :
kafka.sasl.mechanismkafka.sasl.jaas.configkafka.security.protocolkafka.sasl.client.callback.handler.classkafka.sasl.oauthbearer.token.endpoint.url
Configuration du connecteur Kafka de flux structurés
Pour effectuer l’authentification avec l’ID Microsoft Entra, vous devez avoir les valeurs suivantes :
Un ID de locataire. Vous pouvez le trouver dans l’onglet des services Microsoft Entra ID.
Un ID client (également appelé ID d’application).
Une clé secrète client. Une fois que vous l’avez, vous devez l’ajouter en tant que clé secrète à votre espace de travail Databricks. Pour ajouter cette clé secrète, consultez Gestion des secrets.
Une rubrique EventHubs. Vous pouvez trouver la liste des rubriques dans la section Event Hubs sous la section Entités, sur une page spécifique d’un Espace de noms Event Hubs. Pour utiliser plusieurs rubriques, vous pouvez définir un rôle IAM au niveau d’Event Hubs.
Un serveur EventHubs. Vous pouvez le trouver sur la page de présentation de votre espace de noms Event Hubs spécifique :

En outre, pour utiliser Entra ID, nous devons indiquer à Kafka d’utiliser le mécanisme OAuth SASL (SASL est un protocole générique, et OAuth est un type de « mécanisme » SASL) :
-
kafka.security.protocoldoit êtreSASL_SSL -
kafka.sasl.mechanismdoit êtreOAUTHBEARER -
kafka.sasl.login.callback.handler.classdoit être un nom complet de la classe Java avec la valeurkafkashadedsur le gestionnaire de rappel de connexion de notre classe Kafka ombrée. Consultez l’exemple suivant pour connaître la classe exacte.
Exemple
Examinons ensuite un exemple en cours d’exécution :
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Langage de programmation Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Gestion des erreurs potentielles
Les options de diffusion ne sont pas prises en charge.
Si vous essayez d’utiliser ce mécanisme d’authentification dans les pipelines déclaratifs Spark Lakeflow configurés avec le catalogue Unity, vous pouvez recevoir l’erreur suivante :

Pour résoudre cette erreur, utilisez une configuration de calcul prise en charge. Consultez Authentification par principal de service avec Microsoft Entra ID et Azure Event Hubs.
Échec de la création d’un nouveau
KafkaAdminClient.Il s’agit d’une erreur interne que Kafka génère si l’une des options d’authentification suivantes est incorrecte :
- ID client (également appelé ID d’application)
- ID client
- Serveur EventHubs
Pour résoudre cette erreur, vérifiez que les valeurs sont correctes pour ces options.
En outre, vous pouvez voir cette erreur si vous modifiez les options de configuration fournies par défaut dans l’exemple (qu’on vous a invité à ne pas modifier), comme
kafka.security.protocol.Aucun enregistrement retourné
Si vous essayez d’afficher ou de traiter votre DataFrame, mais que vous n’obtenez pas de résultats, vous verrez ce qui suit dans l’interface utilisateur.

Ce message signifie que l’authentification a réussi, mais EventHubs n’a retourné aucune donnée. Parmi les causes possibles (non exhaustives) :
- Vous avez spécifié une rubrique EventHubs incorrecte.
- L’option de configuration Kafka par défaut est
startingOffsetslatest, et vous ne recevez actuellement aucune donnée via la rubrique. Vous pouvez définirstartingOffsetssurearliestpour commencer à lire des données à partir des décalages les plus anciens de Kafka.