Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit les principales différences entre le traitement par lots et le streaming, deux sémantiques de traitement des données différentes utilisées pour les charges de travail d’ingénierie des données, notamment l’ingestion, la transformation et le traitement en temps réel.
La diffusion en continu est généralement associée à une faible latence et un traitement continu à partir de bus de messages, tels qu’Apache Kafka.
Toutefois, dans Azure Databricks, il a une définition plus étendue. Le moteur sous-jacent des pipelines déclaratifs Lakeflow Spark (Apache Spark et Structured Streaming) possède une architecture unifiée pour le traitement des lots et en flux continu :
- Le moteur peut traiter des sources telles que le stockage d’objets cloud et Delta Lake comme des sources de streaming pour un traitement incrémentiel efficace.
- Le traitement de streaming peut être exécuté de manière déclenchée et continue, ce qui vous donne la possibilité de contrôler les compromis entre coûts et performances pour vos charges de travail de diffusion en continu.
Vous trouverez ci-dessous les différences sémantiques fondamentales qui distinguent les lots et la diffusion en continu, y compris leurs avantages et inconvénients, et les considérations à prendre en compte pour les choisir pour vos charges de travail.
Sémantique du traitement par lot
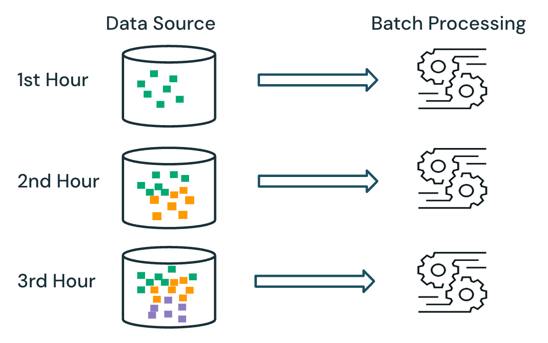
Avec le traitement par lots, le moteur ne suit pas les données déjà traitées dans la source. Toutes les données actuellement disponibles dans la source sont traitées au moment du traitement. Dans la pratique, une source de données par lots est généralement partitionnée logiquement, par exemple, par jour ou région, pour limiter le retraitement des données.
Par exemple, le calcul du prix moyen des ventes d’articles, agrégé à une granularité horaire, pour un événement de vente exécuté par une société de commerce électronique peut être planifié comme traitement par lots pour calculer le prix moyen des ventes toutes les heures. Avec le traitement en lot, les données des heures précédentes sont traitées à nouveau une fois par heure, et les résultats calculés précédemment sont écrasés afin de refléter les derniers résultats.
Sémantique du streaming
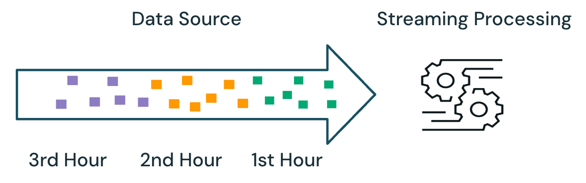
Avec le traitement en streaming, le moteur effectue le suivi des données en cours de traitement et traite uniquement les nouvelles données dans les exécutions suivantes. Dans l’exemple ci-dessus, vous pouvez planifier le traitement de streaming au lieu du traitement par lots pour calculer le prix de vente moyen toutes les heures. Avec la diffusion en continu, seules les nouvelles données ajoutées à la source depuis la dernière exécution sont traitées. Les résultats nouvellement calculés doivent être ajoutés aux résultats calculés précédemment pour vérifier les résultats complets.
Traitement par lots et streaming de données
Dans l’exemple ci-dessus, la diffusion en continu est préférable au traitement par lots, car elle ne traite pas les mêmes données traitées dans les exécutions précédentes. Toutefois, le traitement de streaming devient plus complexe avec des scénarios tels que les données hors séquence et de retard d'arrivée dans la source.
Voici un exemple de données d’arrivée tardive si certaines données de ventes de la première heure n’arrivent pas à la source jusqu’à la deuxième heure :
- Dans le traitement par lots, les données d’arrivée tardives de la première heure seront traitées avec les données de la deuxième heure et les données existantes à partir de la première heure. Les résultats précédents de la première heure seront remplacés et corrigés avec les données d’arrivée tardive.
- Dans le traitement en streaming, les données arrivant à la fin de la première heure seront traitées sans aucune autre donnée de première heure qui a été traitée. La logique de traitement doit stocker les informations de somme et de comptage des calculs moyens de la première heure pour mettre à jour correctement les résultats précédents.
Ces complexités de streaming sont généralement introduites lorsque le traitement est avec gestion d'état, comme les jointures, les agrégations et les déduplications.
Pour le traitement en flux continu sans état, tel que l’ajout de nouvelles données à partir de la source, la gestion des données hors ordre et des données arrivant en retard est moins complexe, car ces dernières peuvent être ajoutées aux résultats précédents au fur et à mesure que les données arrivent dans la source.
Le tableau ci-dessous présente les avantages et inconvénients du traitement par lots et de diffusion en continu et les différentes fonctionnalités de produit qui prennent en charge ces deux sémantiques de traitement dans Databricks Lakeflow.
| Sémantique de traitement | Avantages | Inconvénients | Produits d’ingénierie des données |
|---|---|---|---|
| Lot |
|
|
|
| Diffusion en continu |
|
|
|
Recommandations
Le tableau ci-dessous présente la sémantique de traitement recommandée en fonction des caractéristiques des charges de travail de traitement des données à chaque couche de l’architecture de médaillon.
| Couche de médaillon | Caractéristiques de la charge de travail | Recommandation |
|---|---|---|
| Bronze |
|
|
| Argent |
|
|
| Or |
|
|