Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La capture de données modifiées (CDC) est un modèle d’intégration de données qui capture les modifications apportées aux données dans un système source, telles que les insertions, les mises à jour et les suppressions. Ces modifications, représentées sous la forme d’une liste, sont couramment appelées flux CDC. Vous pouvez traiter vos données beaucoup plus rapidement si vous utilisez un flux cdc, au lieu de lire l’intégralité du jeu de données source. Les bases de données transactionnelles telles que SQL Server, MySQL et Oracle génèrent des flux CDC. Les tables delta génèrent leur propre flux CDC, appelé flux de données modifiées (CDF).
Le diagramme suivant montre que lorsqu’une ligne d’une table source qui contient des données d’employé est mise à jour, elle génère un nouvel ensemble de lignes dans un flux CDC qui contient uniquement les modifications. Chaque ligne du flux CDC contient généralement des métadonnées supplémentaires, notamment l’opération telle UPDATE qu’une colonne qui peut être utilisée pour classer de manière déterministe chaque ligne du flux CDC afin de pouvoir gérer les mises à jour hors ordre. Par exemple, la sequenceNum colonne du diagramme suivant détermine l’ordre des lignes dans le flux CDC :

Traitement d’un flux de données modifiées : conservez uniquement les données les plus récentes et conservez les versions historiques des données
Le traitement d’un flux de données modifié est connu sous le nom de dimensions à variation lente (SCD). Lorsque vous traitez un flux CDC, vous avez le choix entre :
- Conservez-vous uniquement les données les plus récentes (autrement dit, remplacez les données existantes) ? Il s’agit du type SCD 1.
- Ou conservez-vous un historique des modifications apportées aux données ? Il s’agit du type SCD 2.
Le traitement SCD Type 1 implique de remplacer les anciennes données avec de nouvelles données chaque fois qu’une modification se produit. Cela signifie qu’aucun historique des modifications n’est conservé. Seule la dernière version des données est disponible. Il s’agit d’une approche simple et est souvent utilisée lorsque l’historique des modifications n’est pas important, comme la correction d’erreurs ou la mise à jour de champs non critiques comme les adresses e-mail des clients.

Le traitement SCD Type 2 conserve un enregistrement historique des modifications de données en créant des enregistrements supplémentaires pour capturer différentes versions des données au fil du temps. Chaque version des données est horodatée ou marquée avec des métadonnées qui permet aux utilisateurs de suivre lorsqu’une modification s’est produite. Cela est utile lorsqu’il est important de suivre l’évolution des données, telles que le suivi des modifications d’adresse client au fil du temps à des fins d’analyse.

Exemples de traitement SCD Type 1 et Type 2 avec des pipelines déclaratifs Spark Lakeflow
Les exemples de cette section vous montrent comment utiliser SCD Type 1 et Type 2.
Étape 1 : Préparer des exemples de données
Dans cet exemple, vous allez générer un exemple de flux CDC. Tout d’abord, créez un bloc-notes et collez-y le code suivant. Mettez à jour les variables au début du bloc de code vers un catalogue et un schéma où vous êtes autorisé à créer des tables et des vues.
Ce code crée une table Delta qui contient plusieurs enregistrements de modification. Le schéma est le suivant :
-
id- Entier, identificateur unique de cet employé -
name- Chaîne de caractères, nom de l’employé -
role- Chaîne, rôle de l’employé -
country- Chaîne, code pays, où l'employé travaille -
operation- Modifier le type(par exemple,INSERT,UPDATEouDELETE) -
sequenceNum- Entier, identifie l’ordre logique des événements CDC dans les données sources. Lakeflow Spark Declarative Pipelines utilise ce séquencement pour gérer les événements de modification qui arrivent hors ordre.
# update these to the catalog and schema where you have permissions
# to create tables and views.
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
def write_employees_cdf_to_delta():
data = [
(1, "Alex", "chef", "FR", "INSERT", 1),
(2, "Jessica", "owner", "US", "INSERT", 2),
(3, "Mikhail", "security", "UK", "INSERT", 3),
(4, "Gary", "cleaner", "UK", "INSERT", 4),
(5, "Chris", "owner", "NL", "INSERT", 6),
# out of order update, this should be dropped from SCD Type 1
(5, "Chris", "manager", "NL", "UPDATE", 5),
(6, "Pat", "mechanic", "NL", "DELETE", 8),
(6, "Pat", "mechanic", "NL", "INSERT", 7)
]
columns = ["id", "name", "role", "country", "operation", "sequenceNum"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.{employees_cdf_table}")
write_employees_cdf_to_delta()
Vous pouvez afficher un aperçu de ces données à l’aide de la commande SQL suivante :
SELECT *
FROM mycatalog.myschema.employees_cdf
Étape 2 : Utiliser SCD Type 1 pour conserver uniquement les données les plus récentes
Nous vous recommandons d’utiliser l’API AUTO CDC dans un pipeline déclaratif Spark Lakeflow pour traiter un flux de données modifiées dans une table SCD Type 1.
- Créez un nouveau notebook.
- Collez le code suivant.
- Créez et connectez-vous à un pipeline.
La employees_cdf fonction lit la table que nous venons de créer ci-dessus en tant que flux, car l’API create_auto_cdc_flow , que vous utiliserez pour le traitement de capture de données modifiées, attend un flux de modifications en tant qu’entrée. Vous l’encapsulez avec un décorateur @dp.temporary_view , car vous ne souhaitez pas matérialiser ce flux dans une table.
Ensuite, vous utilisez dp.create_target_table pour créer une table de diffusion en continu qui contient le résultat du traitement de ce flux de données modifiées.
Enfin, vous utilisez dp.create_auto_cdc_flow pour traiter le flux de données modifiées. Examinons chaque argument :
-
target- La table de diffusion ciblée en continu, que vous avez définie précédemment. -
source- Vue sur le flux d’enregistrements de modification que vous avez défini précédemment. -
keys- Identifie les lignes uniques dans le flux de modification. Étant donné que vous utilisezidcomme identificateur unique, indiquezidsimplement la seule colonne d’identification. -
sequence_by- Nom de colonne qui spécifie l’ordre logique des événements CDC dans les données sources. Vous avez besoin de ce séquencement pour gérer les événements de changement qui arrivent dans le désordre. FournissezsequenceNumcomme colonne de séquencement. -
apply_as_deletes- Étant donné que l'exemple de données contient des opérations de suppression, vous utilisezapply_as_deletespour indiquer quand un événement CDC doit être traité comme unDELETE, plutôt qu'une mise à jour/ajout (upsert). -
except_column_list- Contient une liste de colonnes que vous ne souhaitez pas inclure dans la table cible. Dans cet exemple, vous allez utiliser cet argument pour excluresequenceNumetoperation. -
stored_as_scd_type- Indique le type SCD que vous souhaitez utiliser.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr, lit, when
from pyspark.sql.types import StringType, ArrayType
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table_current = "employees_current"
employees_table_historical = "employees_historical"
@dp.temporary_view
def employees_cdf():
return spark.readStream.format("delta").table(f"{catalog}.{schema}.{employees_cdf_table}")
dp.create_target_table(f"{catalog}.{schema}.{employees_table_current}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_current}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
Exécutez ce pipeline en cliquant sur Démarrer.
Exécutez ensuite la requête suivante dans l’éditeur SQL pour vérifier que les enregistrements de modification ont été traités correctement :
SELECT *
FROM mycatalog.myschema.employees_current
Note
La mise à jour hors ordre de l’employé Chris a été supprimée correctement, car son rôle est toujours défini sur Propriétaire au lieu du Responsable.
**

Étape 3 : Utiliser SCD Type 2 pour conserver les données historiques
Dans cet exemple, vous créez une deuxième table cible, appelée employees_historical, qui contient un historique complet des modifications apportées aux enregistrements des employés.
Ajoutez ce code à votre pipeline. La seule différence ici est que stored_as_scd_type est réglé à 2 au lieu de 1.
dp.create_target_table(f"{catalog}.{schema}.{employees_table_historical}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_historical}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 2
)
Exécutez ce pipeline en cliquant sur Démarrer.
Exécutez ensuite la requête suivante dans l’éditeur SQL pour vérifier que les enregistrements de modification ont été traités correctement :
SELECT *
FROM mycatalog.myschema.employees_historical
Vous verrez toutes les modifications apportées aux employés, y compris ceux qui ont été supprimés, tels que Pat.

Étape 4 : Nettoyer les ressources
Lorsque vous avez terminé, nettoyez les ressources en procédant comme suit :
Supprimez le pipeline :
Note
Lorsque vous supprimez le pipeline, il supprime automatiquement les tables
employeesetemployees_historical.- Cliquez sur Tâches & Pipelines, puis trouvez le nom du pipeline que vous souhaitez supprimer.
- Cliquez sur
 Dans la même ligne que le nom du pipeline, puis cliquez sur Supprimer.
Dans la même ligne que le nom du pipeline, puis cliquez sur Supprimer.
Supprimez le bloc-notes.
Supprimez la table qui contient le flux de données modifiées :
- Cliquez sur Nouvelle > requête.
- Collez et exécutez le code SQL suivant, en ajustant le catalogue et le schéma selon les besoins :
DROP TABLE mycatalog.myschema.employees_cdf
Inconvénients de l’utilisation MERGE INTO et foreachBatch de la capture des données modifiées
Databricks fournit une MERGE INTO commande SQL que vous pouvez utiliser avec l’API foreachBatch pour insérer ou mettre à jour des lignes dans une table Delta. Cette section explique comment cette technique peut être utilisée pour des cas d’usage simples, mais cette méthode devient de plus en plus complexe et fragile lorsqu’elle est appliquée à des scénarios réels.
Dans cet exemple, vous allez utiliser l’exemple de flux de données de modification utilisé dans les exemples précédents.
Implémentation naive avec MERGE INTO et foreachBatch
Créez un bloc-notes et copiez le code suivant dans celui-ci. Modifiez les variables catalog, schema et employees_table selon les besoins. Les variables catalog et schema doivent être définies sur des emplacements dans Unity Catalog où vous pouvez créer des tables.
Lorsque vous exécutez le notebook, il effectue les opérations suivantes :
- Crée la table cible dans le
create_table. Contrairementcreate_auto_cdc_flowà , qui gère automatiquement cette étape, vous devez spécifier le schéma. - Lit le flux de modification des données en tant que flux. Chaque microbatch est traité à l’aide de la
upsertToDeltaméthode, qui exécute uneMERGE INTOcommande.
catalog = "jobs"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table = "employees_merge"
def upsertToDelta(microBatchDF, batchId):
microBatchDF.createOrReplaceTempView("updates")
microBatchDF.sparkSession.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING)
""")
create_table()
cdcData = spark.readStream.table(f"{catalog}.{schema}.{employees_cdf_table}")
cdcData.writeStream \
.foreachBatch(upsertToDelta) \
.outputMode("append") \
.start()
Pour afficher les résultats, exécutez la requête SQL suivante :
SELECT *
FROM mycatalog.myschema.employees_merge
Malheureusement, les résultats sont incorrects, comme indiqué ci-dessous :

Plusieurs mises à jour de la même clé dans le même microbatch
Le premier problème est que le code ne gère pas plusieurs mises à jour vers la même clé dans le même microbatch. Par exemple, vous utilisez INSERT pour insérer l’employé Chris, puis mettre à jour son rôle du propriétaire au responsable. Cela doit entraîner une ligne, mais il existe deux lignes.
Quel changement gagne lorsqu’il existe plusieurs mises à jour de la même clé dans un microbatch ?
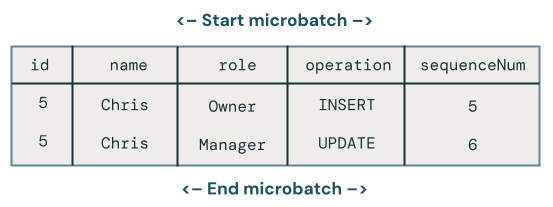
La logique devient plus complexe. L’exemple de code suivant récupère la ligne sequenceNum la plus récente et fusionne uniquement ces données dans la table cible comme suit :
- Regroupe par la clé primaire,
id. - Prend toutes les colonnes de la ligne possédant le maximum
sequenceNumdans le lot pour cette clé. - Explose la ligne en arrière.
Mettez à jour la upsertToDelta méthode comme indiqué ci-dessous, puis exécutez le code :
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
Lorsque vous interrogez la table cible, vous voyez que l’employé nommé Chris a le rôle approprié, mais qu’il existe encore d’autres problèmes à résoudre, car vous avez toujours supprimé les enregistrements affichés dans la table cible.
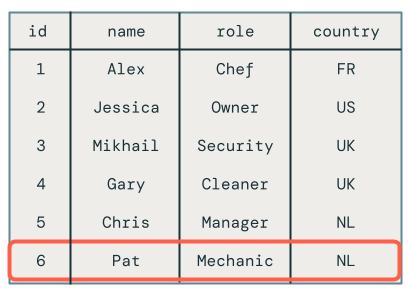
Mises à jour hors commande sur les microbatches
Cette section explore le problème des mises à jour hors ordre sur les microbatches. Le diagramme suivant illustre le problème : que se passe-t-il si la ligne pour Chris a une opération UPDATE dans le premier micro-lot suivie d'une opération INSERT dans un micro-lot suivant ? Le code ne gère pas cela correctement.
Quel changement gagne lorsqu’il existe des mises à jour hors ordre de la même clé sur plusieurs microbatches ?

Pour résoudre ce problème, développez le code pour stocker une version dans chaque ligne comme suit :
- Stockez, dans le
sequenceNum, la date et l'heure de la dernière mise à jour d'une ligne. - Pour chaque nouvelle ligne, vérifiez si l’horodatage est supérieur à celui stocké, puis appliquez la logique suivante :
- Si la valeur est supérieure, utilisez les nouvelles données de la cible.
- Sinon, conservez les données dans la source.
Tout d’abord, mettez à jour la createTable méthode pour stocker le sequenceNum , car vous l’utiliserez pour versionner chaque ligne :
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING, sequenceNum INT)
""")
Ensuite, mettez à jour upsertToDelta pour gérer les versions de ligne. La clause UPDATE SET de MERGE INTO doit gérer chaque colonne séparément.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Gestion des suppressions
Malheureusement, le code a toujours un problème. Il ne gère pas les opérations DELETE, comme en témoigne le fait que l’employé Pat est toujours dans la table cible.
Supposons que les suppressions arrivent dans le même microbatch. Pour les gérer, mettez à jour à nouveau la upsertToDelta méthode pour supprimer la ligne lorsque l’enregistrement de données modifiées indique la suppression, comme indiqué ci-dessous :
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN DELETE
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Gestion des mises à jour arrivant dans le désordre après des suppressions
Malheureusement, le code ci-dessus n’est toujours pas tout à fait correct, car il ne gère pas les cas lorsqu’un DELETE est suivi d’un UPDATE hors ordre dans les micro-lots.

L’algorithme à gérer dans ce cas doit mémoriser les suppressions afin qu’elle puisse gérer les mises à jour obsolètes suivantes. Pour ce faire :
- Au lieu de supprimer immédiatement des lignes, supprimez-les de manière réversible avec un horodatage ou
sequenceNum. Les lignes supprimées de manière réversible sont tombstoned. - Redirigez tous vos utilisateurs vers une vue qui filtre les tombstones.
- Créez un travail de nettoyage qui supprime les pierres tombales au fil du temps.
Utilisez le code suivant :
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Vos utilisateurs ne peuvent pas utiliser directement la table cible. Créez donc une vue qu’ils peuvent interroger :
CREATE VIEW employees_v AS
SELECT * FROM employees_merge
WHERE DELETED_AT = NULL
Enfin, créez un travail de nettoyage qui supprime régulièrement les lignes tombstoned :
DELETE FROM employees_merge
WHERE DELETED_AT < now() - INTERVAL 1 DAY