Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Un modèle MLflow est un format standard pour l’empaquetage de modèles Machine Learning qui peuvent être utilisés dans divers outils en aval, par exemple l’inférence par lots sur Apache Spark ou la mise en service en temps réel via une API REST. Le format définit une convention qui vous permet d’enregistrer un modèle dans différentes saveurs (python-function, pytorch, sklearn, etc.), qui peuvent être comprises par différentes plateformes d’inférence et de mise en service de modèle.
Pour savoir comment journaliser et noter un modèle de diffusion en continu, consultez Comment enregistrer et charger un modèle de diffusion en continu.
MLflow 3 introduit des améliorations significatives apportées aux modèles MLflow en introduisant un nouvel objet dédié LoggedModel avec ses propres métadonnées, telles que les métriques et les paramètres. Pour plus d’informations, consultez Suivre et comparer des modèles à l’aide de modèles journalisés MLflow.
Journaliser et charger des modèles
Lorsque vous journalisez un modèle, MLflow journalise automatiquement des fichiers requirements.txt et conda.yaml. Vous pouvez utiliser ces fichiers pour recréer l’environnement de développement de modèle et réinstaller les dépendances en utilisant virtualenv (recommandé) ou conda.
Important
Anaconda Inc. a mis à jour ses conditions d’utilisation du service pour les canaux anaconda.org. En fonction des nouvelles conditions d’utilisation, vous pouvez exiger une licence commerciale si vous vous appuyez sur l’emballage et la distribution d’Anaconda. Pour plus d’informations, consultez le Forum aux questions sur l’édition commerciale d’Anaconda. Votre utilisation des canaux Anaconda est régie par leurs conditions d’utilisation du service.
Les modèles MLflow enregistrés avant la version 1.18 (Databricks Runtime 8.3 ML ou version antérieure) étaient enregistrés par défaut avec le canal conda defaults (https://repo.anaconda.com/pkgs/) en tant que dépendance. En raison de cette modification de licence, Databricks a arrêté l’utilisation du canal defaults pour les modèles enregistrés à l’aide de MLflow v1.18 et versions ultérieures. Le canal par défaut journalisé est maintenant conda-forge, qui pointe vers https://conda-forge.org/, géré par la communauté.
Si vous avez enregistré un modèle avant MLflow v1.18 sans exclure le canal defaults de l’environnement conda pour le modèle, ce modèle peut avoir une dépendance sur le canal defaults que vous n’avez peut-être pas prévue.
Pour vérifier manuellement si un modèle a cette dépendance, vous pouvez examiner la valeur channel dans le fichier conda.yaml empaqueté avec le modèle journalisé. Par exemple, un modèle avec une conda.yaml dépendance de defaults canal peut ressembler à ceci :
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Étant donné que Databricks ne peut pas déterminer si votre utilisation du référentiel Anaconda pour interagir avec vos modèles est autorisée dans votre relation avec Anaconda, Databricks n’oblige pas ses clients à apporter des modifications. Si votre utilisation du dépôt Anaconda.com par le biais de l’utilisation de Databricks est autorisée sous les termes d’Anaconda, vous n’avez pas besoin d’effectuer d’action.
Si vous souhaitez modifier le canal utilisé dans l’environnement d’un modèle, vous pouvez réinscrire le modèle dans le registre de modèles avec un nouveau conda.yaml. Pour ce faire, spécifiez le canal dans le paramètre conda_env de log_model().
Pour plus d’informations sur l’API log_model(), consultez la documentation MLflow pour la version de modèle que vous utilisez, par exemple, log_model pour scikit-learn.
Pour plus d’informations sur les fichiers conda.yaml, consultez la documentation MLflow.
Commandes d’API
Pour journaliser un modèle sur le serveur de suivi MLflow, utilisez mlflow.<model-type>.log_model(model, ...).
Pour charger un modèle journalisé en vue d’une inférence ou d’un développement supplémentaire, utilisez mlflow.<model-type>.load_model(modelpath) , où modelpath est l’un des éléments suivants :
- un chemin d’accès de modèle (comme
models:/{model_id}) (MLflow 3 uniquement) - Un chemin relatif à l’exécution (par exemple,
runs:/{run_id}/{model-path}) - un chemin d’accès de volumes catalogue Unity (par exemple
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - un chemin de stockage d’artefact géré par MLflow commençant par
dbfs:/databricks/mlflow-tracking/ - Un chemin de modèle inscrit (tel que
models:/{model_name}/{model_stage}).
Pour obtenir la liste complète des options de chargement des modèles MLflow, consultez Référencement d’artefacts dans la documentation MLflow.
Pour les modèles Python MLflow, une autre option consiste à utiliser mlflow.pyfunc.load_model() pour charger le modèle en tant que fonction Python générique.
Vous pouvez utiliser l’extrait de code suivant pour charger le modèle et noter les points de données.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Vous pouvez également exporter le modèle en tant que fonction définie par l’utilisateur Apache Spark à utiliser pour le scoring sur un cluster Spark, sous forme de programme de traitement par lots ou de travail de streaming Spark en temps réel.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Enregistrer les dépendances du modèle
Pour charger avec précision un modèle, vous devez vérifier que les dépendances du modèle sont chargées avec les versions appropriées dans l’environnement de notebook. Dans Databricks Runtime 10.5 ML et versions ultérieures, MLflow vous avertit si une incompatibilité est détectée entre l’environnement actuel et les dépendances du modèle.
Des fonctionnalités supplémentaires pour simplifier la restauration des dépendances de modèle sont incluses dans Databricks Runtime 11.0 ML et versions ultérieures. Dans Databricks Runtime 11.0 ML et versions ultérieures, pour les modèles de saveur pyfunc, vous pouvez appeler mlflow.pyfunc.get_model_dependencies pour récupérer et télécharger les dépendances de modèle. Cette fonction retourne un chemin au fichier de dépendances que vous pouvez ensuite installer avec %pip install <file-path>. Quand vous chargez un modèle en tant qu’UDF PySpark, spécifiez env_manager="virtualenv" dans l’appel mlflow.pyfunc.spark_udf. Cela restaure les dépendances du modèle dans le contexte de l’UDF PySpark et n’affecte pas l’environnement extérieur.
Vous pouvez également utiliser cette fonctionnalité dans Databricks Runtime 10.5 ou version inférieure en installant manuellement MLflow version 1.25.0 ou version ultérieure :
%pip install "mlflow>=1.25.0"
Si vous souhaitez obtenir plus d’informations sur la journalisation des dépendances de modèle (Python et non-Python) et des artefacts, consultez Dépendances de modèle de journal.
Découvrez comment journaliser des dépendances de modèle et des artefacts personnalisés pour un service de modèle :
- Déployer des modèles avec des dépendances
- Utiliser des bibliothèques personnalisées Python un service de modèle
- Package d’artefacts personnalisés pour un service de modèle
Extraits de code générés automatiquement dans l’interface utilisateur MLflow
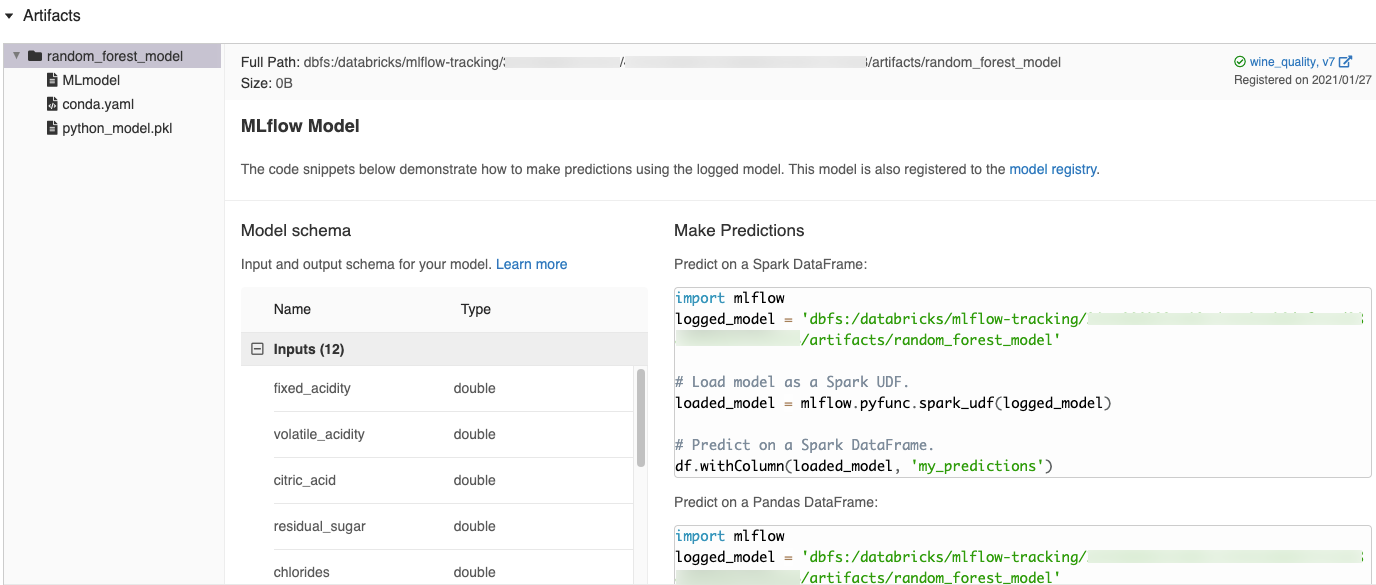
Quand vous journalisez un modèle dans un notebook Azure Databricks, Azure Databricks génère automatiquement des extraits de code que vous pouvez copier et utiliser pour charger et exécuter le modèle. Pour afficher ces extraits de code :
- Accédez à l’écran Exécutions pour l’exécution qui a généré le modèle. (Consultez Afficher l’expérience du notebook pour savoir comment afficher l’écran Exécutions.)
- Faites défiler jusqu’à la section Artefacts.
- Cliquez sur le nom du modèle journalisé. Un panneau s’ouvre à droite avec le code que vous pouvez utiliser pour charger le modèle journalisé et effectuer des prédictions sur les DataFrames Spark ou pandas.
Exemples
Pour obtenir des exemples de journalisation de modèles, consultez les exemples fournis dans Exemples de suivi d’exécutions d’entraînement de Machine Learning.
Inscrire des modèles dans le Registre de modèles
Vous pouvez inscrire des modèles dans le registre des modèles MLflow, magasin de modèles centralisé qui fournit une interface utilisateur et un ensemble d’API permettant de gérer le cycle de vie complet des modèles MLflow. Pour savoir comment utiliser le Registre des modèles afin de gérer les modèles dans Unity Catalog de Databricks, consultez Gérer le cycle de vie des modèles dans Unity Catalog. Pour utiliser le registre de modèles d’espace de travail, consultez Gérer le cycle de vie du modèle avec le registre de modèles d’espace de travail (hérité).
Lorsque les modèles créés avec MLflow 3 sont inscrits dans le registre des modèles de catalogue Unity, vous pouvez afficher des données telles que des paramètres et des métriques dans un emplacement central, dans toutes les expériences et espaces de travail. Pour plus d’informations, consultez les améliorations apportées au Registre de modèles avec MLflow 3.
Pour inscrire un modèle à l’aide de l’API, utilisez la commande suivante :
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Enregistrer des modèles dans des volumes de catalogue Unity
Pour enregistrer un modèle localement, utilisez mlflow.<model-type>.save_model(model, modelpath).
modelpath doit être un chemin d’accès aux volumes du catalogue Unity. Par exemple, si vous utilisez un emplacement dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models de volumes catalogue Unity pour stocker le travail de votre projet, vous devez utiliser le chemin /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_modelsdu modèle :
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
Pour les modèles MLlib, utilisez les pipelines ML.
Télécharger les artefacts de modèle
Vous pouvez télécharger les artefacts de modèle journalisé (tels que les fichiers de modèle, les tracés et les métriques) pour un modèle inscrit avec différentes API.
Exemple d’API Python :
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Exemple d’API Java :
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Exemple de commande CLI :
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Déployer des modèles pour la mise en service en ligne
Remarque
Avant de déployer votre modèle, il est utile de vérifier que le modèle est capable d’être servi. Consultez la documentation MLflow pour savoir comment utiliser mlflow.models.predict pour valider des modèles avant le déploiement.
Utilisez Mosaic AI Model Serving pour héberger des modèles d'apprentissage automatique enregistrés dans le registre de modèles Unity Catalog en tant que points de terminaison REST. Ces points de terminaison sont mis à jour automatiquement en fonction de la disponibilité des versions du modèle.