Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel vous guide tout au long des notions de base de l’exécution d’une analyse exploratoire des données (EDA) à l’aide de Python dans un notebook Azure Databricks, du chargement de données à la génération d’insights via des visualisations de données.
Le notebook utilisé dans ce tutoriel examine les données globales sur l’énergie et les émissions et montre comment charger, nettoyer et explorer les données.
Vous pouvez suivre l’utilisation de l’exemple de bloc-notes ou créer votre propre bloc-notes à partir de zéro.
Qu’est-ce que EDA ?
L’analyse exploratoire des données (EDA) est une étape initiale critique du processus de science des données qui implique l’analyse et la visualisation des données dans :
- Découvrez ses principales caractéristiques.
- Identifiez les modèles et les tendances.
- Détecter les anomalies.
- Comprendre les relations entre les variables.
EDA fournit des insights sur le jeu de données, facilitant les décisions éclairées sur d’autres analyses statistiques ou modélisation.
Avec les notebooks Azure Databricks, les scientifiques des données peuvent effectuer EDA à l’aide d’outils familiers. Par exemple, ce didacticiel utilise certaines bibliothèques Python courantes pour gérer et tracer des données, notamment :
- Numpy: bibliothèque fondamentale pour l’informatique numérique, fournissant la prise en charge des tableaux, des matrices et un large éventail de fonctions mathématiques pour fonctionner sur ces structures de données.
- pandas: une bibliothèque puissante de manipulation et d’analyse des données, basée sur NumPy, qui offre des structures de données telles que des DataFrames pour gérer efficacement les données structurées.
- Plotly: bibliothèque de visualisation interactive qui permet la création de visualisations interactives de haute qualité pour l’analyse et la présentation des données.
- Matplotlib: bibliothèque complète permettant de créer des visualisations statiques, animées et interactives dans Python.
Azure Databricks fournit également des fonctionnalités intégrées pour vous aider à explorer vos données dans la sortie du notebook, telles que le filtrage et la recherche de données dans des tables et le zoom avant sur les visualisations. Vous pouvez également utiliser l’Assistant Databricks pour vous aider à écrire du code pour EDA.
Avant de commencer
Pour suivre ce didacticiel, vous avez besoin des éléments suivants :
- Vous devez avoir l’autorisation d’utiliser une ressource de calcul existante ou de créer une ressource de calcul. Consultez Calcul.
- [Facultatif] Ce tutoriel explique comment utiliser l’Assistant pour vous aider à générer du code. Pour plus d’informations, consultez Utiliser l’Assistant Databricks.
Télécharger le jeu de données et importer le fichier CSV
Ce tutoriel montre les techniques EDA en examinant les données globales sur l’énergie et les émissions. Pour suivre, téléchargez le jeu de données consommation d’énergie par Notre monde dans les données à partir de Kaggle. Ce didacticiel utilise le fichier owid-energy-data.csv.
Pour importer le jeu de données dans votre espace de travail Azure Databricks :
Dans la barre latérale de l’espace de travail, cliquez sur espace de travail pour accéder au navigateur de l’espace de travail.
Faites glisser et déposez le fichier CSV,
owid-energy-data.csvdans votre espace de travail.Cela ouvre le mode Importer. Notez le dossier cible répertorié ici. Ce paramètre est défini sur votre dossier actif dans le navigateur de l’espace de travail et devient la destination du fichier importé.
Cliquez sur Importer. Le fichier doit apparaître dans le dossier cible de votre espace de travail.
Vous avez besoin du chemin d’accès au fichier pour charger le fichier dans votre bloc-notes ultérieurement. Recherchez le fichier dans votre navigateur d’espace de travail. Pour copier le chemin du fichier dans le Presse-papiers, cliquez avec le bouton droit sur le nom du fichier, puis sélectionnez Copier l’URL/chemin d’accès>chemin d’accès complet.
Créer un bloc-notes
Pour créer un bloc-notes dans votre dossier d’accueil utilisateur, cliquez sur ![]() Nouvelle dans la barre latérale, puis sélectionnez Bloc-notes dans le menu.
Nouvelle dans la barre latérale, puis sélectionnez Bloc-notes dans le menu.
En haut, en regard du nom du bloc-notes, sélectionnez Python comme langue par défaut pour le bloc-notes.
Pour en savoir plus sur la création et la gestion de notebooks, consultez Gérer les blocs-notes.
Ajoutez chacun des exemples de code de cet article à une nouvelle cellule de votre bloc-notes. Vous pouvez également utiliser le carnet d'exemple fourni pour suivre le didacticiel.
Charger le fichier CSV
Dans une nouvelle cellule de notebook, chargez le fichier CSV. Pour ce faire, importez numpy et pandas. Il s’agit de bibliothèques Python utiles pour la science et l’analyse des données.
Créez un DataFrame pandas à partir du jeu de données pour faciliter le traitement et la visualisation. Remplacez le chemin du fichier ci-dessous par celui que vous avez copié précédemment.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
Exécutez la cellule. La sortie doit retourner le DataFrame pandas, y compris une liste de chaque colonne et son type.
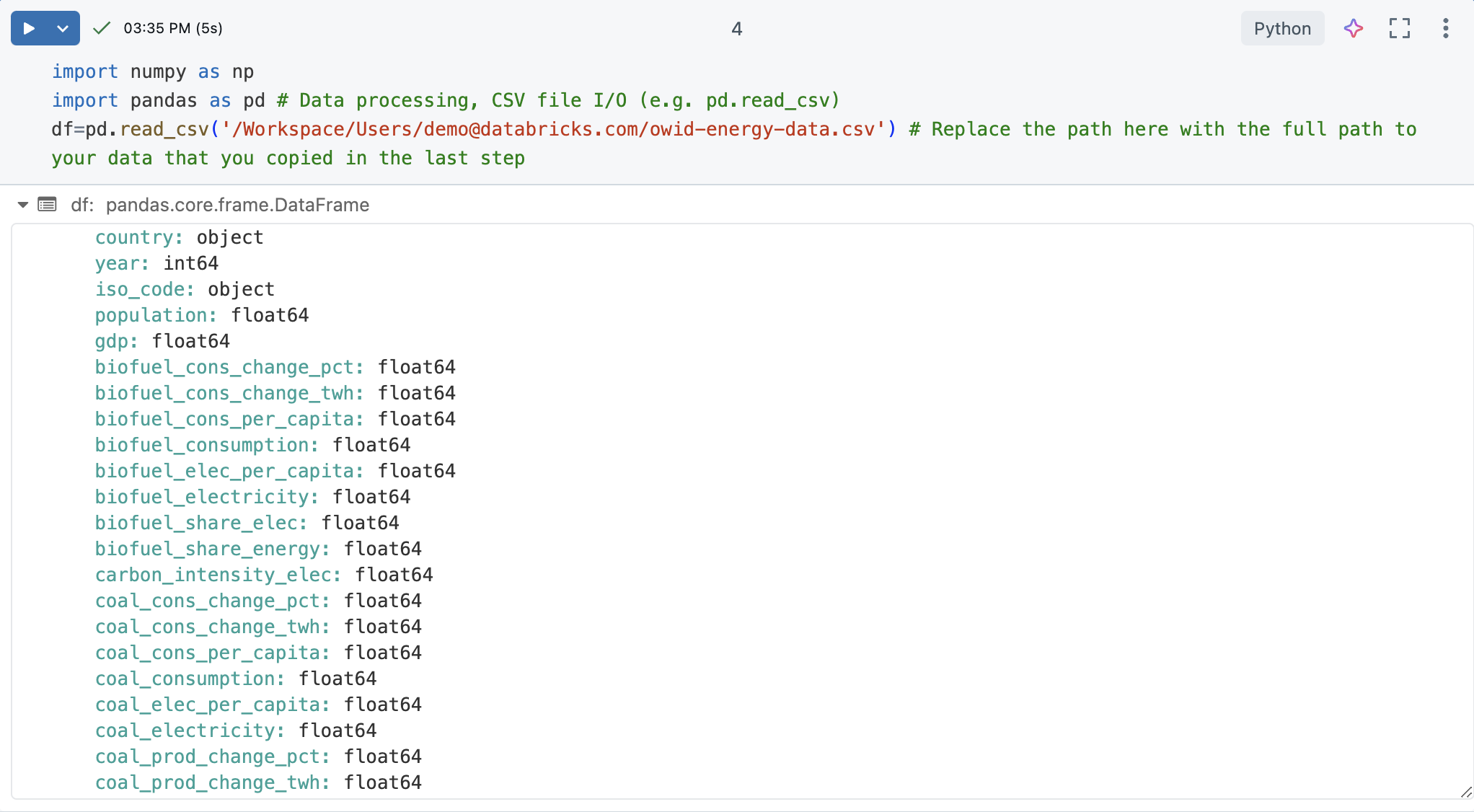
Comprendre les données
Comprendre les principes de base du jeu de données est crucial pour n’importe quel projet de science des données. Il implique de se familiariser avec la structure, les types et la qualité des données à portée de main.
Dans un notebook Azure Databricks, vous pouvez utiliser la commande display(df) pour afficher le jeu de données.

Étant donné que le jeu de données comporte plus de 10 000 lignes, cette commande retourne un jeu de données tronqué. À gauche de chaque colonne, vous pouvez voir le type de données de la colonne. Pour plus d’informations, consultez Mettre en forme des colonnes.
Utiliser pandas pour obtenir des aperçus des données.
Pour comprendre efficacement votre jeu de données, utilisez les commandes pandas suivantes :
La commande
df.shaperetourne les dimensions du DataFrame, ce qui vous donne une vue d’ensemble rapide du nombre de lignes et de colonnes.
La commande
df.dtypesfournit les types de données de chaque colonne, ce qui vous aide à comprendre le type de données avec laquelle vous traitez. Vous pouvez également voir le type de données de chaque colonne dans la table de résultats.
La commande
df.describe()génère des statistiques descriptives pour les colonnes numériques, telles que la moyenne, l’écart type et les centiles, qui peuvent vous aider à identifier des modèles, détecter des anomalies et comprendre la distribution de vos données. Utilisezdisplay()pour afficher les statistiques récapitulatives dans un format tabulaire avec lequel vous pouvez interagir. Consultez Explorer les données à l’aide de la table de sortie du notebook Databricks.
Générer un profil de données
Remarque
Disponible dans Databricks Runtime 9.1 LTS et ultérieur.
Les notebooks Azure Databricks incluent des fonctionnalités intégrées de profilage des données. Lorsque vous affichez un DataFrame avec la fonction d’affichage Azure Databricks, vous pouvez générer un profil de données à partir de la sortie de la table.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)

Cliquez sur +>profil de données en regard de la table dans la sortie. Cette commande exécute une nouvelle commande qui génère un profil des données dans le DataFrame.

Le profil de données inclut des statistiques récapitulatives pour les colonnes numériques, chaînes et dates, ainsi que des histogrammes des distributions de valeurs pour chaque colonne. Vous pouvez également générer des profils de données par programmation. Consultez la commande summarize (dbutils.data.summarize).
Nettoyer les données
Le nettoyage des données est une étape essentielle de l’EDA pour garantir que le jeu de données est précis, cohérent et prêt à être analysé de manière significative. Ce processus implique plusieurs tâches clés pour s’assurer que les données sont prêtes à être analysées, notamment :
- Identification et suppression de toutes les données dupliquées.
- Gestion des valeurs manquantes, ce qui peut impliquer de les remplacer par une valeur spécifique ou de supprimer les lignes affectées.
- Normalisation des types de données (par exemple, conversion de chaînes en
datetime) via des conversions et des transformations pour garantir la cohérence. Vous pouvez également convertir des données dans un format plus facile à utiliser.
Cette phase de nettoyage est essentielle, car elle améliore la qualité et la fiabilité des données, ce qui permet une analyse plus précise et plus approfondie.
Conseil : Utiliser l’Assistant Databricks pour faciliter les tâches de nettoyage des données
Vous pouvez utiliser l’Assistant Databricks pour vous aider à générer du code. Créez une nouvelle cellule de code et cliquez sur le lien générer ou utilisez l’icône d’assistant en haut à droite pour ouvrir l’assistant. Entrez une requête pour l’assistant. L’Assistant peut générer du code Python ou SQL ou générer une description de texte. Pour différents résultats, cliquez sur Régénérer.
Par exemple, essayez les instructions suivantes pour utiliser l'assistant pour vous aider à nettoyer les données :
- Vérifiez si
dfcontient des colonnes ou des lignes en double. Imprimez les doublons. Ensuite, supprimez les doublons. - Dans quel format les colonnes de date sont-elles affichées ? Remplacez-le par
'YYYY-MM-DD'. - Je ne vais pas utiliser la
XXXcolonne. Supprime-le.
Consultez Obtenez de l'aide en matière de codage par l'Assistant Databricks.
Supprimer les données dupliquées
Vérifiez si les données ont des lignes ou des colonnes en double. Si c’est le cas, supprimez-les.
Conseil
Utiliser l’Assistant pour générer du code pour vous.
Essayez d’entrer l’invite : « Vérifiez si df contient des colonnes ou des lignes dupliquées. Imprimez les doublons. Ensuite, supprimez les doublons. L’Assistant peut générer du code comme l’exemple ci-dessous.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
Dans ce cas, le jeu de données n’a pas de données en double.
Gérer les valeurs Null ou manquantes
Un moyen courant de traiter les valeurs NaN ou Null consiste à les remplacer par 0 pour faciliter le traitement mathématique.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
Cela garantit que toutes les données manquantes dans le DataFrame sont remplacées par 0, ce qui peut être utile pour les étapes suivantes d’analyse ou de traitement des données où des valeurs manquantes peuvent entraîner des problèmes.
Reformater les dates
Les dates sont souvent mises en forme de différentes manières dans différents jeux de données. Elles peuvent être au format de date, chaînes ou entiers.
Pour cette analyse, traitez la colonne year en tant qu’entier. Le code suivant est un moyen de procéder comme suit :
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
Cela garantit que la colonne year contient uniquement des valeurs d'année sous forme d'entier, avec toutes les entrées non valides converties en NaT (Pas une date).
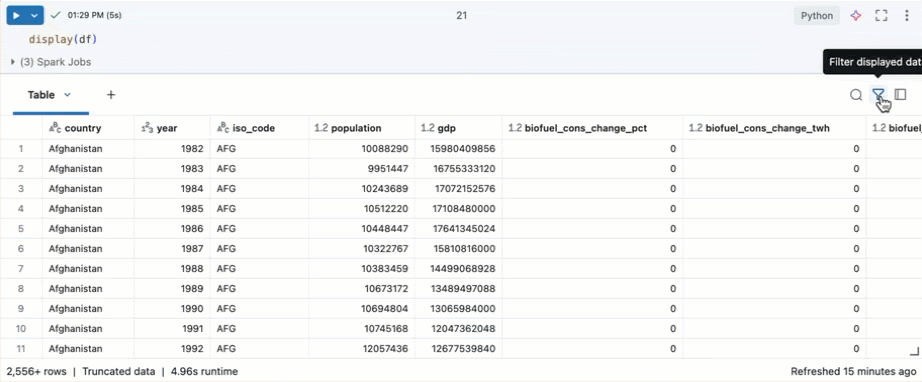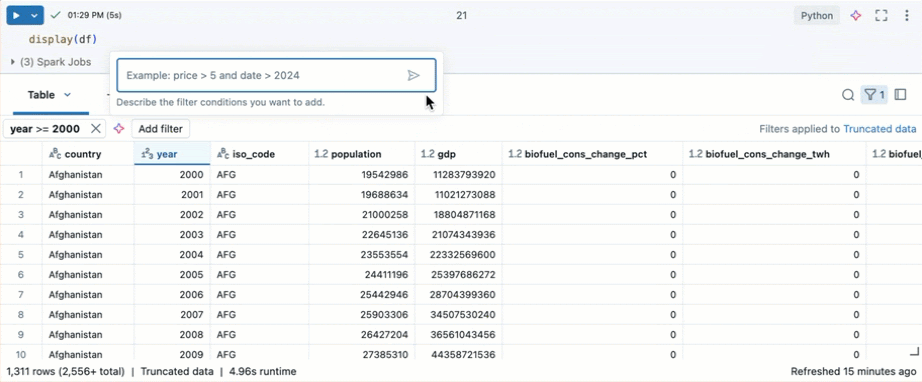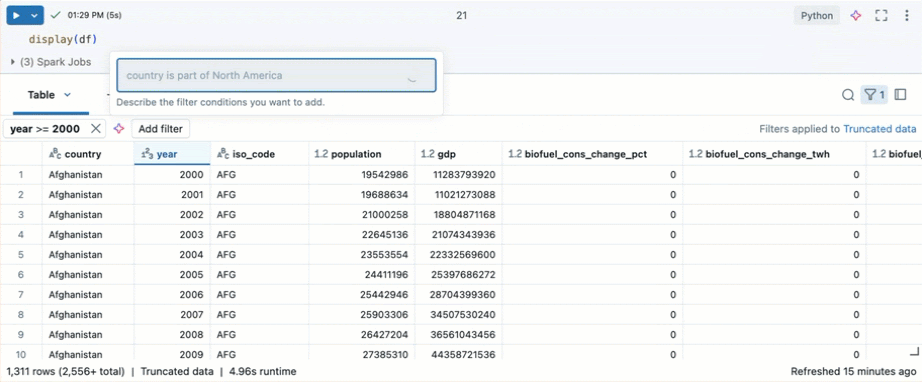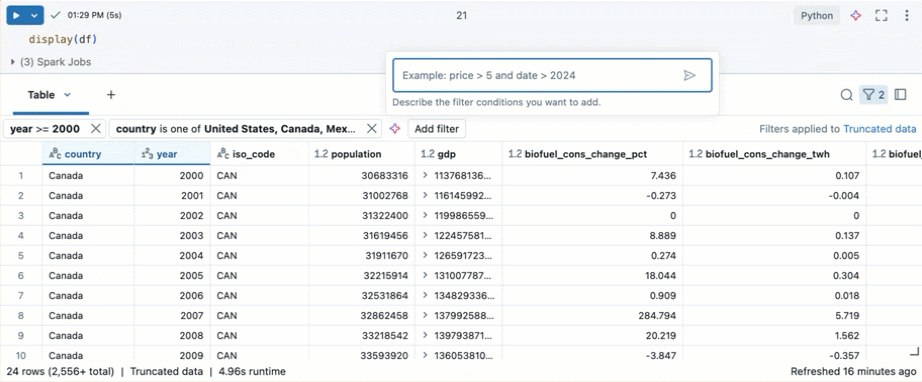
Explorer les données à l’aide de la table de sortie du notebook Databricks
Azure Databricks fournit des fonctionnalités intégrées pour vous aider à explorer vos données à l’aide de la table de sortie.
Dans une nouvelle cellule, utilisez display(df) pour afficher le jeu de données sous forme de table.

À l’aide de la table de sortie, vous pouvez explorer vos données de plusieurs façons :
- Rechercher les données d’une chaîne ou d’une valeur spécifique
- filtre pour des conditions spécifiques
- Créer des visualisations à l’aide du jeu de données
Rechercher des données pour une chaîne ou une valeur spécifique
Cliquez sur l’icône de recherche en haut à droite du tableau et entrez votre recherche.

Filtre pour des conditions spécifiques
Vous pouvez utiliser des filtres de table intégrés pour filtrer vos colonnes pour des conditions spécifiques. Il existe plusieurs façons de créer un filtre. Consultez résultats du filtre.
Conseil
Utilisez l’Assistant Databricks pour créer des filtres. Cliquez sur l’icône de filtre dans le coin supérieur droit du tableau. Entrez votre condition de filtre. L’Assistant Databricks génère automatiquement un filtre pour vous.
Créer des visualisations à l’aide du jeu de données
En haut de la table de sortie, cliquez sur +>Visualisation pour ouvrir l’éditeur de visualisation.

Sélectionnez le type de visualisation et les colonnes que vous souhaitez visualiser. L’éditeur affiche un aperçu du graphique en fonction de votre configuration. Par exemple, l’image ci-dessous montre comment ajouter plusieurs graphiques en courbes pour afficher la consommation de diverses sources d’énergie renouvelable au fil du temps.
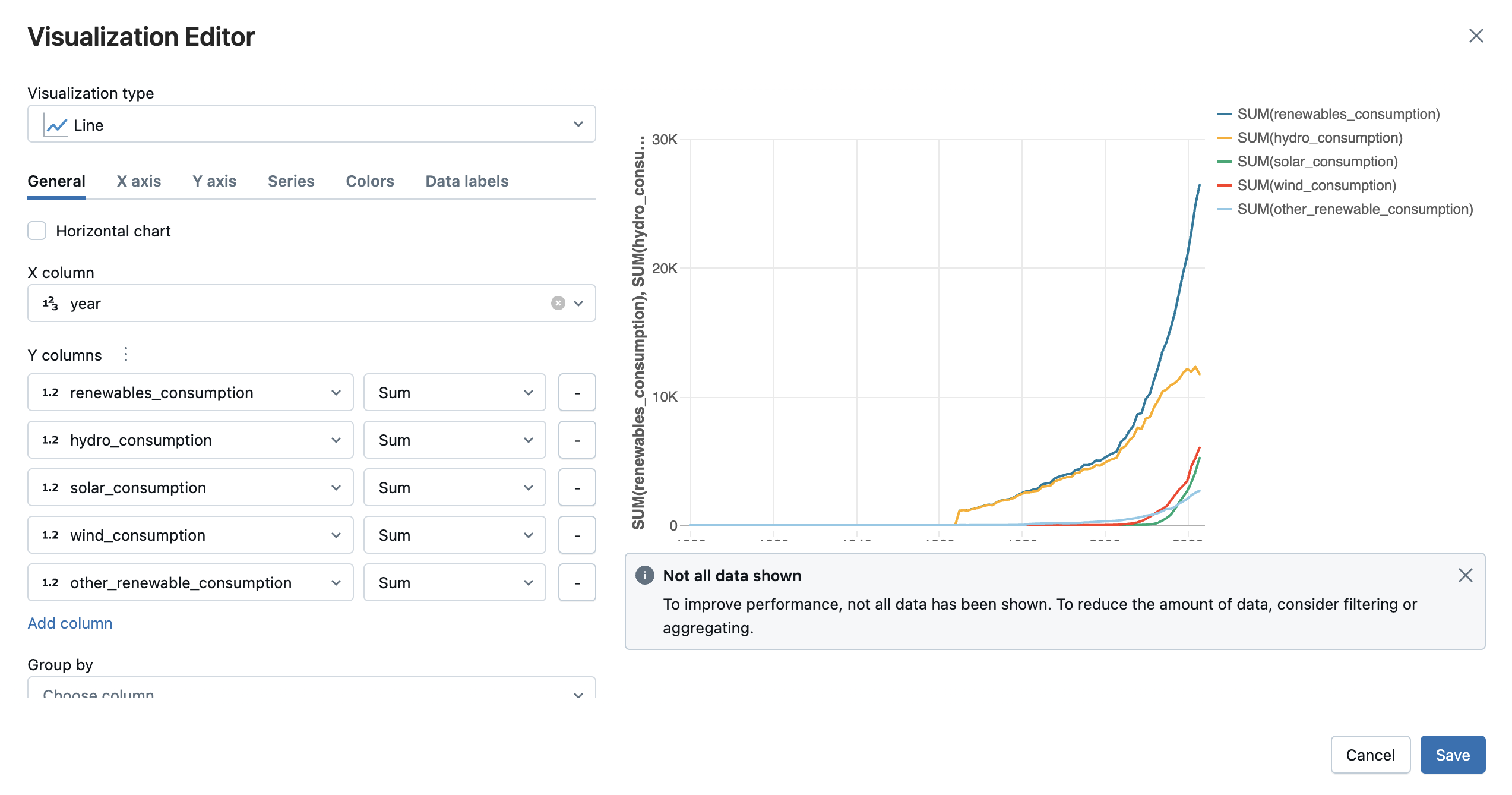
Cliquez sur Enregistrer pour ajouter la visualisation sous forme d’onglet dans la sortie de la cellule.
Voir Créer une nouvelle visualisation.
Explorer et visualiser les données à l’aide de bibliothèques Python
L’exploration des données à l’aide de visualisations est un aspect fondamental de l’EDA. Les visualisations permettent de découvrir des modèles, des tendances et des relations au sein des données qui peuvent ne pas être immédiatement apparentes par le biais d’une analyse numérique seule. Utilisez des bibliothèques telles que Plotly ou Matplotlib pour les techniques de visualisation courantes, notamment les nuages de points, les graphiques à barres, les graphiques en courbes et les histogrammes. Ces outils visuels permettent aux scientifiques des données d’identifier les anomalies, de comprendre les distributions de données et d’observer les corrélations entre les variables. Par exemple, les diagrammes de dispersion peuvent mettre en évidence les valeurs hors norme, tandis que les graphiques de séries chronologiques peuvent révéler les tendances et la saisonnalité.
- Créer un tableau pour les pays uniques
- Graphique des tendances d'émission pour les 10 principaux émetteurs (200-2022)
- Filtrer et graphiquer les émissions par région
- Calculer et graphe la croissance des parts d’énergie renouvelable
- Nuage de points : Afficher l’impact de l’énergie renouvelable pour les émetteurs principaux
- modèle de prévision de la consommation énergétique mondiale
Créer un tableau pour des pays uniques
Examinez les pays inclus dans le jeu de données en créant un tableau pour des pays uniques. La création d’un tableau affiche les entités répertoriées en tant que country.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
sortie :

Insight :
La country colonne comprend diverses entités, notamment world, pays à revenu élevé, Asie et États-Unis, qui ne sont pas toujours directement comparables. Il peut être plus utile de filtrer les données par région.
Tendances des émissions de graphique pour les 10 principaux émetteurs (200-2022)
Supposons que vous souhaitiez concentrer votre enquête sur les 10 pays avec les émissions de gaz à effet de serre les plus élevées dans les années 2000. Vous pouvez filtrer les données des années que vous souhaitez examiner et les 10 premiers pays ayant le plus d’émissions, puis utiliser le tracé pour créer un graphique en courbes montrant leurs émissions au fil du temps.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
sortie :

Insight :
Les émissions de gaz à effet de serre ont tendance à augmenter de 2000 à 2022, à l’exception de quelques pays où les émissions étaient relativement stables avec une légère baisse au fil du temps.
Filtrer et graphiquer les émissions par région
Filtrez les données par région et calculez le total des émissions pour chaque région. Tracez ensuite les données sous la forme d’un graphique à barres :
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
sortie :

Insight :
L’Asie a les émissions de gaz à effet de serre les plus élevées. L’Océanie, l’Amérique du Sud et l’Afrique produisent les émissions de gaz à effet de serre les plus faibles.
Calculer et graphe la croissance des parts d’énergie renouvelable
Créez une nouvelle fonctionnalité/colonne qui calcule la part d’énergie renouvelable en tant que ratio de la consommation d’énergie renouvelable par rapport à la consommation d’énergie primaire. Ensuite, classez les pays en fonction de leur part moyenne d’énergie renouvelable. Pour les 10 premiers pays, tracez leur part d’énergie renouvelable au fil du temps :
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
sortie :

Insight :
La Norvège et l’Islande sont à la tête du monde en énergie renouvelable, avec plus de la moitié de leur consommation provenant d’énergie renouvelable.
L’Islande et la Suède ont connu la plus grande croissance de leur part d’énergie renouvelable. Tous les pays ont connu des baisses et des hausses occasionnelles, ce qui montre comment la croissance des parts d’énergie renouvelable n’est pas nécessairement linéaire. Intéressant, l’Afrique du Moyen-Orient a connu un recul au début des années 2010, mais a rebondi en 2020.
Diagramme de dispersion : Montrer l'impact de l'énergie renouvelable pour les principaux émetteurs
Filtrez les données des 10 premiers émetteurs, puis utilisez un nuage de points pour examiner le partage d’énergie renouvelable et les émissions de gaz à effet de serre au fil du temps.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
sortie :

Insight :
Comme un pays utilise plus d’énergie renouvelable, il a également plus d’émissions de gaz à effet de serre, ce qui signifie que sa consommation totale d’énergie augmente plus rapidement que sa consommation renouvelable. L’Amérique du Nord est une exception dans la mesure où ses émissions de gaz à effet de serre sont restées relativement constantes au cours des années, car sa part renouvelable a continué d’augmenter.
Modèle de projection de la consommation mondiale d’énergie
Agréger la consommation mondiale d’énergie primaire par année, puis construire un modèle de moyenne mobile intégrée intégrée (ARIMA) pour projeter la consommation totale d’énergie mondiale pour les prochaines années. Tracer la consommation d’énergie historique et prévue à l’aide de Matplotlib.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
sortie :

Insight :
Ce modèle projette que la consommation mondiale d’énergie continuera à augmenter.
Exemple de notebook
Utilisez le bloc-notes suivant pour effectuer les étapes décrites dans cet article. Pour obtenir des instructions sur l’importation d’un notebook dans un espace de travail Azure Databricks, consultez Importer un notebook.
Tutoriel : EDA avec des données énergétiques globales
Étapes suivantes
Maintenant que vous avez effectué une analyse exploratoire initiale des données sur votre jeu de données, procédez comme suit :
- Consultez l’annexe de l’exemple de bloc-notes pour obtenir d’autres exemples de visualisation EDA.
- Si vous rencontrez des erreurs lors de ce didacticiel, essayez d’utiliser le débogueur intégré pour parcourir votre code. Voir Déboguer lesblocs-notes.
- partager votre bloc-notes avec votre équipe afin qu’ils puissent comprendre votre analyse. Selon les autorisations que vous leur accordez, ils peuvent aider à développer du code pour approfondir l’analyse ou ajouter des commentaires et des suggestions pour une investigation plus approfondie.
- Une fois que vous avez finalisé votre analyse, créez un tableau de bord de notebook ou un tableau de bord IA/BI avec les visualisations clés à partager avec les parties prenantes.