Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
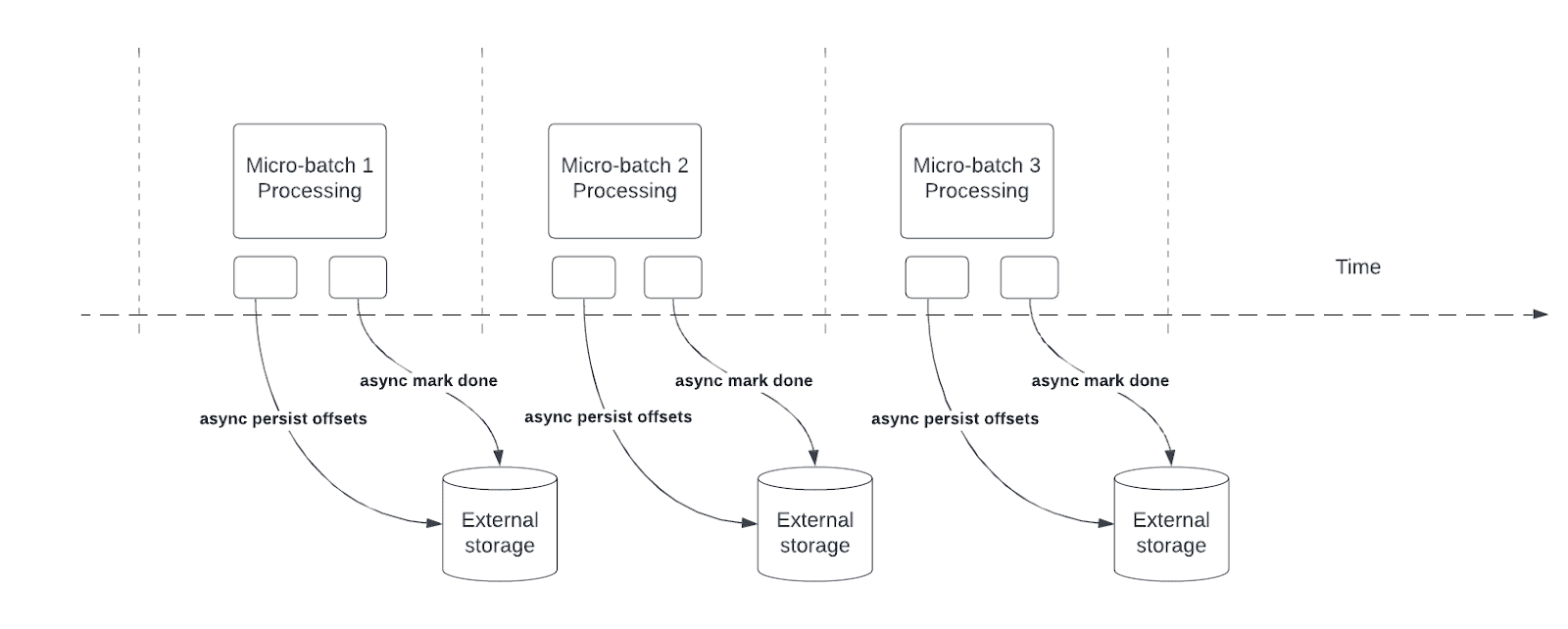
Le suivi de progression asynchrone permet aux pipelines Structured Streaming de contrôler la progression de manière asynchrone et parallèle au traitement réel des données au sein d’un micro-lot, ce qui réduit la latence associée à la maintenance de l’objet offsetLog et commitLog.
Note
Le suivi de progression asynchrone ne fonctionne pas avec les déclencheurs Trigger.once ou Trigger.availableNow. La tentative d’activation de cette fonctionnalité avec ces déclencheurs entraîne l’échec de la requête.
Comment le suivi de progression asynchrone fonctionne-t-il pour réduire la latence ?
Structured Streaming s’appuie sur la persistance et la gestion des décalages en tant qu’indicateurs de progression pour le traitement des requêtes. L’opération de gestion de décalage a un impact direct sur la latence de traitement, car aucun traitement des données ne peut se produire tant que ces opérations ne sont pas terminées. Le suivi de progression asynchrone permet aux pipelines Structured Streaming de vérifier la progression sans être affectés par les opérations de gestion des décalages.
Quand devez-vous configurer la fréquence de point de contrôle ?
Les utilisateurs peuvent configurer la fréquence à laquelle la progression est point de contrôle. Les paramètres par défaut de la fréquence de point de contrôle fournissent un débit correct pour la plupart des requêtes. La configuration de la fréquence est utile pour les scénarios dans lesquels les opérations de gestion de décalage se produisent à un taux plus élevé qu’ils peuvent être traités, ce qui crée un backlog toujours croissant des opérations de gestion de décalage. Pour contenir ce backlog croissant, le traitement des données est bloqué ou ralenti, ce qui rétablit essentiellement le comportement de traitement, éliminant ainsi les avantages du suivi de progression asynchrone.
Note
Le temps de récupération des défaillances augmente avec l'augmentation de l'intervalle de temps des points de contrôle. En cas de défaillance, un pipeline doit retraiter toutes les données avant le point de contrôle réussi précédent. Les utilisateurs peuvent envisager ce compromis entre une latence inférieure pendant le traitement régulier et le temps de récupération en cas de défaillance.
Quelles configurations sont associées au suivi de progression asynchrone ?
| Choix | Valeur | Par défaut | Descriptif |
|---|---|---|---|
| suiviProgrèsAsynchroneActivé | true/false | false | activer ou désactiver le suivi de progression asynchrone |
| IntervalDeVerificationDuSuiviAsynchroneMs | millisecondes | 1 000 | intervalle dans lequel nous validons les décalages et les validations d’achèvement |
Comment les utilisateurs peuvent-ils activer le suivi de progression asynchrone ?
Les utilisateurs peuvent utiliser du code similaire au code ci-dessous pour activer cette fonctionnalité :
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Désactivation du suivi de progression asynchrone
Lorsque le suivi de progression asynchrone est activé, l’infrastructure ne contrôle pas la progression de chaque lot. Pour résoudre ce problème, avant de désactiver le suivi de progression asynchrone, traitez au moins deux micro-lots avec les paramètres suivants :
.option("asyncProgressTrackingEnabled", "true").option("asyncProgressTrackingCheckpointIntervalMs", 0)
Arrêtez la requête une fois qu’au moins deux micro-lots ont terminé le traitement. Vous pouvez maintenant désactiver en toute sécurité le suivi de progression asynchrone et redémarrer la requête.
Si vous avez désactivé le suivi de progression asynchrone sans effectuer cette étape, vous pouvez rencontrer l’erreur suivante :
java.lang.IllegalStateException: batch x doesn't exist
Dans les journaux du pilote, l’erreur suivante peut s’afficher :
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
En suivant les instructions de cette section pour désactiver le suivi de progression asynchrone, vous pouvez résoudre ces erreurs et réparer votre charge de travail de diffusion en continu.
Limitations avec suivi de progression asynchrone
Cette fonctionnalité présente les limitations suivantes :
- Le suivi de progression asynchrone est uniquement pris en charge dans les pipelines sans état lors de l’utilisation de Kafka en tant que puits.
- Un traitement de bout en bout à exécution unique n'est pas garanti avec le suivi de progression asynchrone, car les plages d'offset pour le traitement par lots peuvent être modifiées en cas de défaillance. Certains récepteurs, tels que Kafka, ne fournissent jamais de garanties exactement une fois.