Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette procédure pas à pas montre comment utiliser C++ AMP pour accélérer l’exécution de la multiplication de matrices. Deux algorithmes sont présentés, un sans mosaïques et un avec mosaïques.
Prérequis
Avant de commencer :
- Lire la vue d’ensemble de L’AMP C++.
- Lire à l’aide de vignettes.
- Vérifiez que vous exécutez au moins Windows 7 ou Windows Server 2008 R2.
Remarque
Les en-têtes AMP C++ sont déconseillés à partir de Visual Studio 2022 version 17.0.
L’inclusion d’en-têtes AMP génère des erreurs de génération. Définissez _SILENCE_AMP_DEPRECATION_WARNINGS avant d’inclure tous les en-têtes AMP pour silence les avertissements.
Pour créer le projet
Les instructions de création d’un projet varient en fonction de la version de Visual Studio que vous avez installée. Pour consulter la documentation sur votre version préférée de Visual Studio, utilisez le contrôle de sélection de Version . Il se trouve en haut de la table des matières de cette page.
Pour créer le projet dans Visual Studio
Dans la barre de menus, choisissez Fichier>Nouveau>Projet pour ouvrir la boîte de dialogue Créer un projet.
En haut de la boîte de dialogue, définissez Langage sur C++, Plateforme sur Windows et Type de projet sur Console.
Dans la liste filtrée des types de projets, choisissez Projet vide, puis Suivant. Dans la page suivante, entrez MatrixMultiply dans la zone Nom pour spécifier un nom pour le projet, puis spécifiez l’emplacement du projet si vous le souhaitez.

Choisissez le bouton Créer pour créer le projet client.
Dans Explorateur de solutions, ouvrez le menu contextuel des fichiers sources, puis choisissez >.
Dans la boîte de dialogue Ajouter un nouvel élément , sélectionnez Fichier C++ (.cpp), entrez MatrixMultiply.cpp dans la zone Nom , puis choisissez le bouton Ajouter .
Pour créer un projet dans Visual Studio 2017 ou 2015
Dans la barre de menus de Visual Studio, choisissez Fichier>Nouveau>Projet.
Sous Installé dans le volet modèles, sélectionnez Visual C++.
Sélectionnez Projet vide, entrez MatrixMultiply dans la zone Nom , puis choisissez le bouton OK .
Choisissez le bouton Suivant.
Dans Explorateur de solutions, ouvrez le menu contextuel des fichiers sources, puis choisissez >.
Dans la boîte de dialogue Ajouter un nouvel élément , sélectionnez Fichier C++ (.cpp), entrez MatrixMultiply.cpp dans la zone Nom , puis choisissez le bouton Ajouter .
Multiplication sans mosaïcage
Dans cette section, tenez compte de la multiplication de deux matrices, A et B, qui sont définies comme suit :


A est une matrice de 3 par 2 et B est une matrice de 2 par 3. Le produit de la multiplication de A par B est la matrice suivante de 3 à 3. Le produit est calculé en multipliant les lignes d’A par les colonnes de l’élément B par élément.

Pour multiplier sans utiliser L’AMP C++
Ouvrez MatrixMultiply.cpp et utilisez le code suivant pour remplacer le code existant.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }L’algorithme est une implémentation simple de la définition de la multiplication de matrices. Il n’utilise aucun algorithme parallèle ou thread pour réduire le temps de calcul.
Dans la barre de menus, sélectionnez Fichier>Enregistrer tout.
Choisissez le raccourci clavier F5 pour démarrer le débogage et vérifiez que la sortie est correcte.
Choisissez Entrée pour quitter l’application.
Pour multiplier à l’aide de C++ AMP
Dans MatrixMultiply.cpp, ajoutez le code suivant avant la
mainméthode.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Le code AMP ressemble au code non AMP. L’appel à
parallel_for_eachdémarrer un thread pour chaque élément dansproduct.extent, remplace lesforboucles de ligne et de colonne. La valeur de la cellule à la ligne et à la colonne est disponible dansidx. Vous pouvez accéder aux éléments d’unarray_viewobjet à l’aide de l’opérateur[]et d’une variable d’index, ou de l’opérateur()et des variables de ligne et de colonne. L’exemple illustre les deux méthodes. Laarray_view::synchronizeméthode copie les valeurs de laproductvariable vers laproductMatrixvariable.Ajoutez les instructions suivantes
includeenusinghaut de MatrixMultiply.cpp.#include <amp.h> using namespace concurrency;Modifiez la
mainméthode pour appeler laMultiplyWithAMPméthode.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Appuyez sur le raccourci clavier Ctrl+F5 pour démarrer le débogage et vérifier que la sortie est correcte.
Appuyez sur La barre d’espace pour quitter l’application.
Multiplication avec mosaïcage
Le tiling est une technique dans laquelle vous partitionnez des données en sous-ensembles de taille égale, appelées vignettes. Trois choses changent lorsque vous utilisez le mosaïme.
Vous pouvez créer des
tile_staticvariables. L’accès aux données danstile_staticl’espace peut être plusieurs fois plus rapide que l’accès aux données dans l’espace global. Une instance d’unetile_staticvariable est créée pour chaque vignette, et tous les threads de la vignette ont accès à la variable. Le principal avantage de la mosaïne est le gain de performances en raison de l’accèstile_static.Vous pouvez appeler la méthode tile_barrier ::wait pour arrêter tous les threads d’une vignette à une ligne de code spécifiée. Vous ne pouvez pas garantir l’ordre dans lequel les threads s’exécutent, uniquement que tous les threads d’une vignette s’arrêtent à l’appel
tile_barrier::waitavant qu’ils continuent l’exécution.Vous avez accès à l’index du thread par rapport à l’objet entier
array_viewet à l’index par rapport à la vignette. En utilisant l’index local, vous pouvez faciliter la lecture et le débogage de votre code.
Pour tirer parti de la mosaïque en multiplication de matrices, l’algorithme doit partitionner la matrice en vignettes, puis copier les données de vignette dans des tile_static variables pour un accès plus rapide. Dans cet exemple, la matrice est partitionnée en sous-entités de taille égale. Le produit est trouvé en multipliant les submatrices. Les deux matrices et leur produit dans cet exemple sont les suivants :
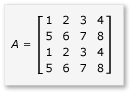


Les matrices sont partitionnées en quatre matrices 2x2, qui sont définies comme suit :


Le produit de A et B peut maintenant être écrit et calculé comme suit :

Étant donné que les matrices a à travers h sont des matrices 2x2, tous les produits et les sommes d’entre eux sont également des matrices 2x2. Il suit également que le produit de A et B est une matrice 4x4, comme prévu. Pour vérifier rapidement l’algorithme, calculez la valeur de l’élément dans la première ligne, première colonne du produit. Dans l’exemple, il s’agirait de la valeur de l’élément dans la première ligne et la première colonne de ae + bg. Vous devez uniquement calculer la première colonne, la première ligne et aebg pour chaque terme. Cette valeur est ae(1 * 1) + (2 * 5) = 11. La valeur pour bg laquelle est (3 * 1) + (4 * 5) = 23. La valeur finale est 11 + 23 = 34, qui est correcte.
Pour implémenter cet algorithme, le code :
Utilise un
tiled_extentobjet au lieu d’unextentobjet dans l’appelparallel_for_each.Utilise un
tiled_indexobjet au lieu d’unindexobjet dans l’appelparallel_for_each.Crée des
tile_staticvariables pour contenir les sous-atrices.Utilise la
tile_barrier::waitméthode pour arrêter les threads pour le calcul des produits des submatrices.
Pour multiplier à l’aide d’AMP et de mosaïne
Dans MatrixMultiply.cpp, ajoutez le code suivant avant la
mainméthode.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Cet exemple est sensiblement différent de l’exemple sans mosaïne. Le code utilise ces étapes conceptuelles :
Copiez les éléments de la vignette[0,0] dans
alocA. Copiez les éléments de la vignette[0,0] dansblocB. Notez qu’ilproductest en mosaïque, pasaetb. Par conséquent, vous utilisez des index globaux pour accédera, bà , etproduct. L’appel esttile_barrier::waitessentiel. Il arrête tous les threads de la vignette jusqu’à ce que les deux etlocAsoientlocBremplis.Multipliez et placez
locAles résultats enlocB.productCopiez les éléments de la vignette[0,1] dans
alocA. Copiez les éléments de la vignette [1,0] dansblocB.Multipliez
locAetlocBajoutez-les aux résultats déjà présentsproduct.La multiplication de la vignette[0,0] est terminée.
Répétez pour les quatre autres vignettes. Il n’existe aucune indexation spécifique pour les vignettes et les threads peuvent s’exécuter dans n’importe quel ordre. À mesure que chaque thread s’exécute, les
tile_staticvariables sont créées pour chaque vignette de manière appropriée et l’appel auxtile_barrier::waitcontrôles du flux de programme.Lorsque vous examinez étroitement l’algorithme, notez que chaque sous-matrix est chargé dans une
tile_staticmémoire deux fois. Ce transfert de données prend du temps. Toutefois, une fois que les données sont entile_staticmémoire, l’accès aux données est beaucoup plus rapide. Étant donné que le calcul des produits nécessite un accès répété aux valeurs des submatrices, il existe un gain global de performances. Pour chaque algorithme, l’expérimentation est nécessaire pour trouver l’algorithme optimal et la taille de vignette.
Dans les exemples non AMP et non-vignettes, chaque élément de A et B est accessible quatre fois à partir de la mémoire globale pour calculer le produit. Dans l’exemple de vignette, chaque élément est accessible deux fois à partir de la mémoire globale et quatre fois à partir de la
tile_staticmémoire. Ce n’est pas un gain de performance significatif. Toutefois, si les matrices A et B étaient de 1024 x 1024 et que la taille des mosaïques était de 16, il y aurait un gain de performances significatif. Dans ce cas, chaque élément est copié entile_staticmémoire seulement 16 fois et accessible à partir detile_staticla mémoire 1024 fois.Modifiez la méthode principale pour appeler la
MultiplyWithTilingméthode, comme indiqué.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Appuyez sur le raccourci clavier Ctrl+F5 pour démarrer le débogage et vérifier que la sortie est correcte.
Appuyez sur la barre d’espace pour quitter l’application.
Voir aussi
C++ AMP (Parallélisme Massif Accéléré en C++)
Procédure pas-à-pas : débogage d’une application C++ AMP