Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

La première ligne de défense est la résilience des applications.
Bien que vous puissiez investir beaucoup de temps pour écrire votre propre framework de résilience, ces produits existent déjà.
Polly est une bibliothèque complète de résilience .NET et de gestion des erreurs temporaires qui permet aux développeurs d’exprimer des stratégies de résilience de manière fluent et thread-safe. Polly cible les applications générées avec .NET Framework ou .NET 7. Le tableau suivant décrit les fonctionnalités de résilience, appelées policies, disponibles dans la bibliothèque Polly. Elles peuvent être appliquées individuellement ou regroupées.
| Stratégie | Expérience |
|---|---|
| Réessayer | Configure les opérations de nouvelle tentative sur les opérations désignées. |
| Disjoncteur | Bloque les opérations demandées pour une période prédéfinie lorsque les erreurs dépassent un seuil configuré |
| Délai d'attente | Limite la durée pendant laquelle un appelant peut attendre une réponse. |
| Cloisonnement | Limite les actions à un pool de ressources de taille fixe pour éviter que des appels défaillants ne saturent une ressource. |
| Cache | Stocke automatiquement les réponses. |
| Rubrique de base | Définit un comportement structuré en cas d’échec. |
Notez comment, dans la figure précédente, les stratégies de résilience s’appliquent aux messages de requête, qu’ils proviennent d’un client externe ou d’un service back-end. L’objectif est de compenser la demande d’un service qui peut être momentanément indisponible. Ces interruptions de courte durée se manifestent généralement avec les codes d’état HTTP indiqués dans le tableau suivant.
| Code d’état HTTP | La cause |
|---|---|
| 404 | Introuvable |
| 4:08 | Délai d’expiration de la demande |
| 429 | Trop de requêtes (une limitation a probablement été appliquée) |
| 502 | Passerelle incorrecte |
| 503 | Service indisponible |
| 504 | Délai d’expiration de la passerelle |
Question : Réessayez-vous un code d’état HTTP de 403 - Interdit ? Non. Ici, le système fonctionne correctement, mais informe l’appelant qu’il n’est pas autorisé à effectuer l’opération demandée. Vous devez prendre soin de réessayer uniquement ces opérations causées par des défaillances.
Comme recommandé dans le chapitre 1, les développeurs Microsoft qui construisent des applications natives cloud doivent cibler la plateforme .NET. La version 2.1 a introduit la bibliothèque HTTPClientFactory pour la création d’instances de client HTTP pour interagir avec les ressources basées sur l’URL. Remplaçant la classe HTTPClient d’origine, la classe de fabrique prend en charge de nombreuses fonctionnalités améliorées, dont l'une est une intégration étroite avec la bibliothèque de résilience Polly. Avec elle, vous pouvez facilement définir des stratégies de résilience dans la classe de démarrage de l’application pour gérer les défaillances partielles et les problèmes de connectivité.
Ensuite, nous allons développer les modèles de nouvelle tentative et de disjoncteur.
Modèle Nouvelle tentative
Dans un environnement cloud-natif distribué, les appels aux services et aux ressources cloud peuvent échouer en raison d’échecs temporaires (de courte durée), ce qui se corrige généralement après une courte période de temps. L’implémentation d’une stratégie de nouvelle tentative permet à un service natif cloud d’atténuer ces scénarios.
Le modèle nouvelle tentative permet à un service de réessayer une opération de demande ayant échoué un nombre (configurable) de fois avec une durée d’attente exponentiellement croissante. La figure 6-2 montre une nouvelle tentative en action.
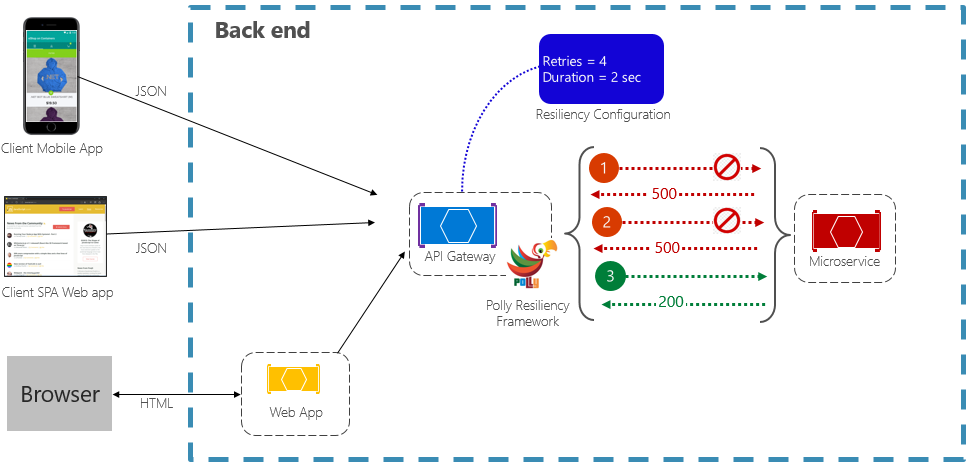
Figure 6-2. Modèle de tentative de réessai en action
Dans la figure précédente, un modèle de nouvelle tentative a été implémenté pour une opération de demande. Il est configuré pour permettre jusqu’à quatre nouvelles tentatives avant d’échouer avec un intervalle d’interruption (temps d’attente) commençant à deux secondes, ce qui double de manière exponentielle pour chaque tentative suivante.
- Le premier appel échoue et retourne un code d’état HTTP de 500. L’application attend deux secondes et réessaye l’appel.
- Le deuxième appel échoue également et retourne un code d’état HTTP de 500. L’application double désormais l’intervalle d’interruption à quatre secondes et retente l’appel.
- Enfin, le troisième appel réussit.
- Dans ce scénario, l’opération de nouvelle tentative aurait tenté jusqu’à quatre nouvelles tentatives tout en doublant la durée d’interruption avant de faire échouer l’appel.
- Si la quatrième nouvelle tentative avait échoué, une stratégie de secours aurait été appelée pour gérer correctement le problème.
Il est important d’augmenter la période d’interruption avant de réessayer l’appel pour permettre au service de se corriger automatiquement. Il est recommandé d’implémenter une interruption exponentiellement croissante (doublement de la période de chaque nouvelle tentative) pour prévoir un temps de correction suffisant.
Modèle Disjoncteur
Bien que le modèle de nouvelle tentative puisse aider à récupérer une demande enchevêtrée dans une défaillance partielle, il existe des situations où des défaillances peuvent être provoquées par des événements imprévus qui nécessitent des périodes de temps plus longues à résoudre. Ces erreurs peuvent aller d’une perte partielle de connectivité à la défaillance complète d’un service. Dans ces situations, il est inutile qu'une application recommence continuellement une opération qui a peu de chances de réussir.
Pour aggraver les choses, l’exécution d’opérations de nouvelle tentative continue sur un service non réactif peut vous déplacer dans un scénario de déni de service auto-imposé où vous inondez votre service avec des appels continus qui épuisent les ressources telles que la mémoire, les threads et les connexions de base de données, provoquant une défaillance dans des parties non liées du système qui utilisent les mêmes ressources.
Dans ces situations, il serait préférable que l’opération échoue immédiatement et tente uniquement d’appeler le service s’il est susceptible de réussir.
Le modèle Disjoncteur peut empêcher qu’une application ne tente d’exécuter à répétition une opération qui échouera probablement. Après un nombre prédéfinis d’appels ayant échoué, il bloque tout le trafic vers le service. Périodiquement, il permettra un appel de test pour déterminer si le problème a été résolu. La figure 6-3 montre le schéma Disjoncteur en action.

Figure 6-3. Modèle Disjoncteur en action
Dans la figure précédente, un modèle Disjoncteur a été ajouté au modèle de nouvelle tentative d’origine. Notez comment après 100 demandes ayant échoué, les disjoncteurs s’ouvrent et n’autorisent plus les appels au service. La valeur CheckCircuit, définie à 30 secondes, spécifie la fréquence à laquelle la bibliothèque permet à une demande de passer au service. Si cet appel réussit, le circuit se ferme et le service est à nouveau disponible pour le trafic.
N’oubliez pas que l’intention du modèle Disjoncteur est différente de celle du modèle Nouvelle tentative. Le modèle nouvelle tentative permet à une application de réessayer une opération dans l’attente qu’elle réussira. Le modèle Disjoncteur empêche une application d’effectuer une opération susceptible d’échouer. En règle générale, une application combine ces deux modèles à l’aide du modèle Nouvelle tentative pour appeler une opération par le biais d’un disjoncteur.
Test de résilience
Les tests de résilience ne peuvent pas toujours être effectués de la même façon que vous testez les fonctionnalités de l’application (en exécutant des tests unitaires, des tests d’intégration, etc.). Au lieu de cela, vous devez tester la façon dont la charge de travail de bout en bout fonctionne dans des conditions d’échec, qui se produisent uniquement par intermittence. Par exemple : injecter des échecs en faisant planter des processus, utiliser des certificats expirés, rendre les services dépendants indisponibles, etc. Des cadres comme chaos-monkey peuvent être utilisés pour ces tests de chaos.
La résilience des applications est un must pour gérer les opérations demandées problématiques. Mais c’est seulement la moitié de l’histoire. Ensuite, nous abordons les fonctionnalités de résilience disponibles dans le cloud Azure.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.