Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Comme nous l’avons vu dans ce livre, une approche native cloud change la façon dont vous concevez, déployez et gérez des applications. Il modifie également la façon dont vous gérez et stockez des données.
La figure 5-1 contraste les différences.
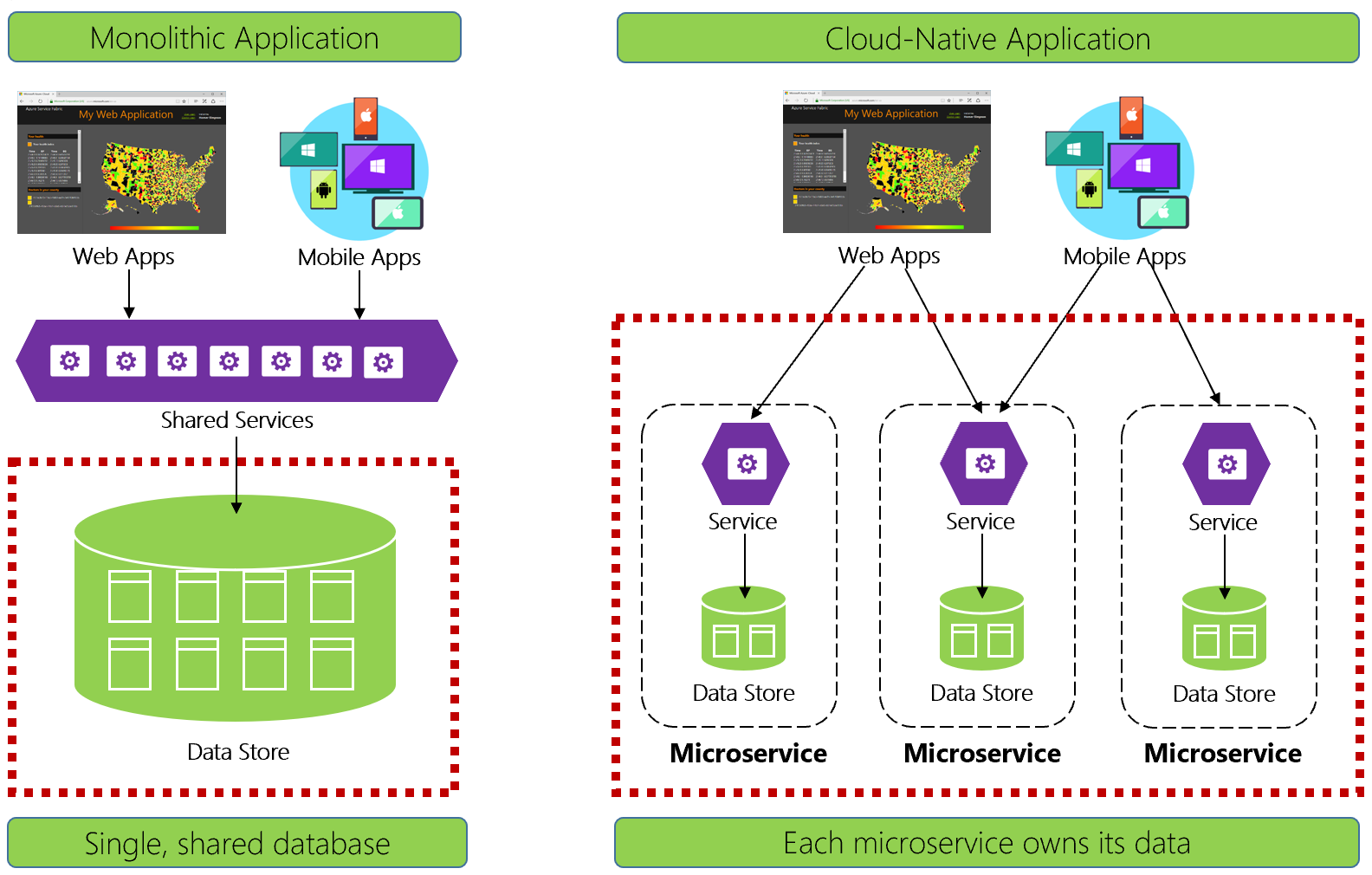
Figure 5-1. Gestion des données dans les applications natives cloud
Les développeurs expérimentés reconnaîtront facilement l’architecture sur le côté gauche de la figure 5-1. Dans cette application monolithique, les composants de service métier se trouvent regroupés dans un même niveau de services partagés, utilisant ensemble les données d’une base de données relationnelle unique.
De nombreuses façons, une base de données unique permet de simplifier la gestion des données. L’interrogation de données sur plusieurs tables est simple. Modifications apportées aux données ensemble, ou restauration de toutes les données. Les transactions ACID garantissent une cohérence forte et immédiate.
Lorsqu'on conçoit pour le cloud natif, nous adoptons une approche différente. Sur le côté droit de la figure 5-1, notez comment les fonctionnalités métier séparent les petites microservices indépendantes. Chaque microservice encapsule une fonctionnalité métier spécifique et ses propres données. La base de données monolithique se décompose en un modèle de données distribué avec de nombreuses bases de données plus petites, chacune s’alignant sur un microservice. Lorsque la fumée s’efface, nous émergeons avec une conception qui expose une base de données par microservice.
Base de données par microservice, pourquoi ?
Cette base de données par microservice offre de nombreux avantages, en particulier pour les systèmes qui doivent évoluer rapidement et prendre en charge une grande échelle. Avec ce modèle...
- Les données de domaine sont encapsulées dans le service
- Le schéma de données peut évoluer sans impact direct sur d’autres services
- Chaque magasin de données peut être mis à l'échelle de manière indépendante.
- Une défaillance du magasin de données dans un service n’aura pas d’impact direct sur d’autres services
La séparation des données permet également à chaque microservice d’implémenter le type de magasin de données qui est le mieux optimisé pour sa charge de travail, ses besoins de stockage et ses modèles de lecture/écriture. Les choix incluent les magasins de données relationnels, les documents, les clés-valeurs et même les magasins de données basés sur des graphiques.
La figure 5-2 présente le principe de persistance polyglotte dans un système natif cloud.
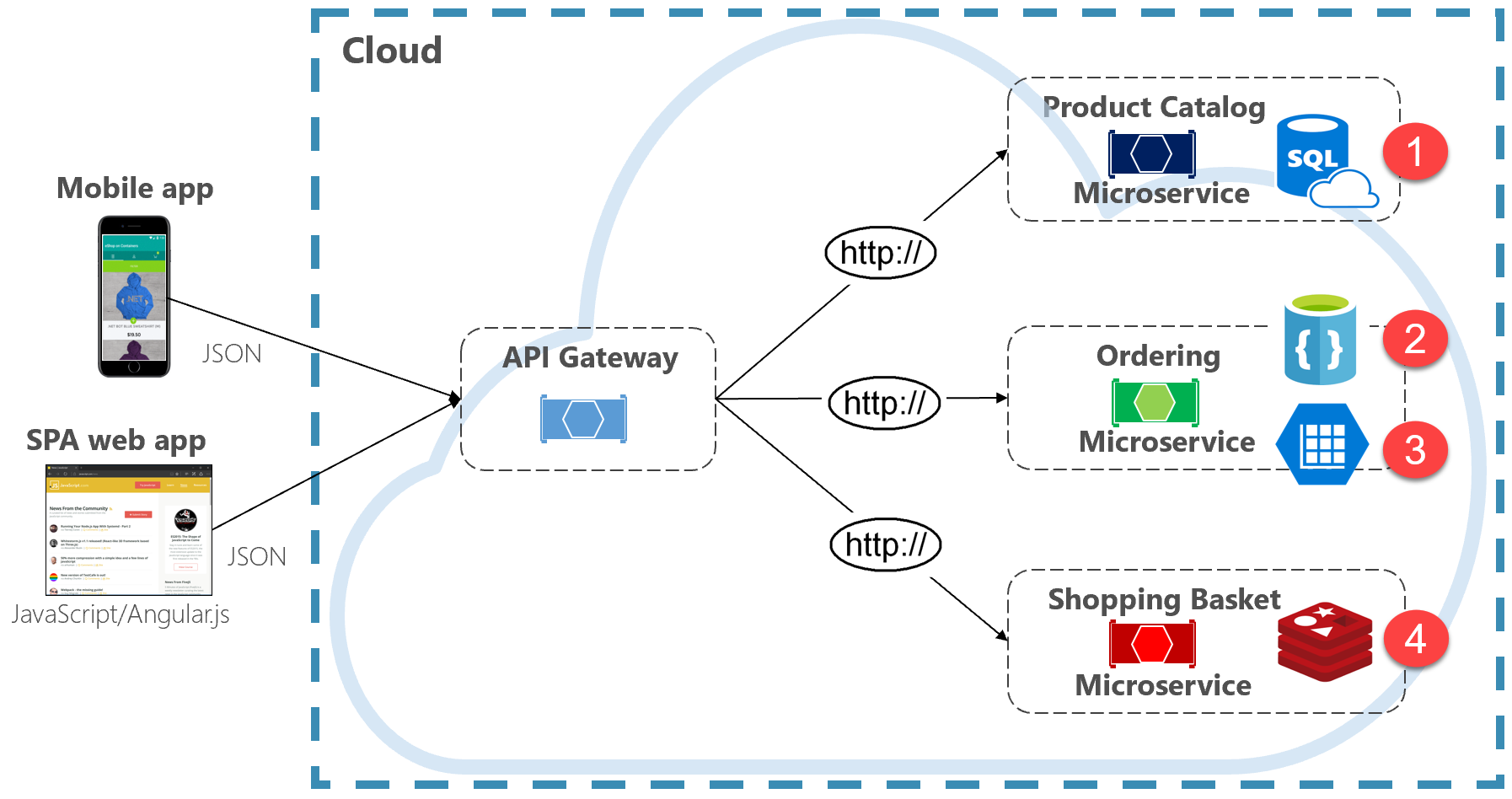
Figure 5-2. Persistance des données polyglottes
Notez dans la figure précédente comment chaque microservice prend en charge un type de magasin de données différent.
- Le microservice du catalogue de produits consomme une base de données relationnelle pour prendre en charge la structure relationnelle riche de ses données sous-jacentes.
- Le microservice du panier d’achat utilise un cache distribué qui prend en charge son stockage de données simple et structuré en clé-valeur.
- Le microservice de commande consomme à la fois une base de données de documents NoSql pour les opérations d’écriture, ainsi qu’un magasin de clés/valeurs hautement dénormalisé pour prendre en charge des volumes élevés d’opérations de lecture.
Bien que les bases de données relationnelles restent pertinentes pour les microservices avec des données complexes, les bases de données NoSQL ont acquis une popularité considérable. Elles fournissent une grande mise à l’échelle et une haute disponibilité. Leur nature sans schéma permet aux développeurs de s’éloigner d’une architecture de classes de données typées et d’ORM qui rendent les modifications coûteuses et fastidieuses. Nous abordons les bases de données NoSQL plus loin dans ce chapitre.
Bien que l’encapsulation de données dans des microservices distincts puisse augmenter l’agilité, les performances et l’extensibilité, il présente également de nombreux défis. Dans la section suivante, nous abordons ces défis avec les modèles et les pratiques pour les surmonter.
Requêtes interservices
Bien que les microservices soient indépendants et se concentrent sur des fonctionnalités fonctionnelles spécifiques, telles que l’inventaire, l’expédition ou la commande, ils nécessitent souvent une intégration avec d’autres microservices. Souvent, l’intégration implique qu’un microservice interroge un autre pour obtenir des données. La figure 5-3 montre le scénario.

Figure 5-3. Requêtes à travers des microservices
Dans la figure précédente, nous voyons un microservice de panier d’achat qui ajoute un élément au panier d’achat d’un utilisateur. Bien que le stockage de données de ce microservice contienne des données de panier et de ligne d'article, il ne conserve pas les données de produit ou de prix. Au lieu de cela, ces éléments de données appartiennent au catalogue et aux microservices tarifaires. Cet aspect présente un problème. Comment le microservice de panier d’achat peut-il ajouter un produit au panier d’achat de l’utilisateur lorsqu’il n’a pas de données de produit ni de tarification dans sa base de données ?
L’une des options décrites dans le chapitre 4 est un appel HTTP direct à partir du panier d’achat vers le catalogue et les microservices tarifaires. Toutefois, dans le chapitre 4, nous avons dit que les appels HTTP synchrones couplent les microservices ensemble, réduisant leur autonomie et réduisant leurs avantages architecturaux.
Nous pourrions également implémenter un modèle de demande-réponse avec des files d’attente entrantes et sortantes distinctes pour chaque service. Toutefois, ce modèle est compliqué et nécessite une plomberie pour mettre en corrélation les messages de demande et de réponse. Bien qu’il dissocie les appels de microservice back-end, le service appelant doit toujours attendre de façon synchrone que l’appel se termine. La congestion du réseau, les erreurs temporaires ou un microservice surchargé peuvent entraîner des opérations de longue durée et même d’échec.
Au lieu de cela, un modèle largement accepté pour la suppression des dépendances entre services est le modèle d’affichage matérialisé, illustré à la figure 5-4.
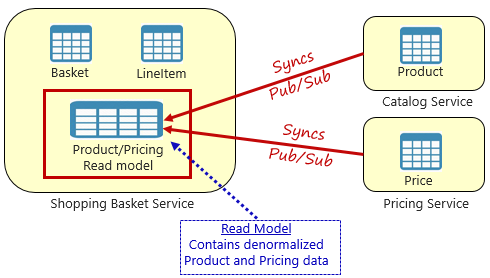
Figure 5-4. Modèle d’affichage matérialisé
Avec ce modèle, vous placez une table de données locale (appelée modèle de lecture) dans le service panier d’achat. Ce tableau contient une copie dénormalisée des données nécessaires à partir du produit et des microservices de tarification. La copie des données directement dans le microservice du panier d’achat élimine le besoin d’appels interservices coûteux. Avec les données locales du service, vous améliorez le temps de réponse et la fiabilité du service. En outre, avoir sa propre copie des données rend le service de panier d’achat plus résilient. Si le service catalogue doit devenir indisponible, il n’a pas d’impact direct sur le service panier d’achat. Le panier d’achat peut continuer à fonctionner avec les données de son propre magasin.
Le problème avec cette approche est que vous avez maintenant des données en double dans votre système. Toutefois, la duplicatation stratégique des données dans les systèmes natifs cloud est une pratique établie et n’est pas considérée comme un anti-modèle ou une mauvaise pratique. N’oubliez pas qu’un seul service peut posséder un jeu de données et avoir l’autorité sur celui-ci. Vous devez synchroniser les modèles de lecture lorsque le système d’enregistrement est mis à jour. La synchronisation est généralement implémentée via la messagerie asynchrone avec un modèle de publication/abonnement, comme illustré dans la figure 5.4.
Transactions distribuées
Bien que l’interrogation de données sur plusieurs microservices soit difficile, l’implémentation d’une transaction sur plusieurs microservices est encore plus complexe. Le défi inhérent à la maintenance de la cohérence des données entre les sources de données indépendantes dans différents microservices ne peut pas être sous-estimé. L’absence de transactions distribuées dans les applications natives cloud signifie que vous devez gérer les transactions distribuées par programmation. Vous passez d’un monde de cohérence immédiate à celle de la cohérence éventuelle.
La figure 5-5 montre le problème.

Figure 5-5. Implémentation d’une transaction entre microservices
Dans la figure précédente, cinq microservices indépendants participent à une transaction distribuée qui crée une commande. Chaque microservice gère son propre magasin de données et implémente une transaction locale pour son magasin. Pour créer la commande, la transaction locale pour chaque microservice individuel doit réussir, ou tous doivent abandonner et restaurer l’opération. Bien que la prise en charge transactionnelle intégrée soit disponible à l’intérieur de chacun des microservices, il n’existe aucune prise en charge d’une transaction distribuée qui s’étend sur les cinq services pour assurer la cohérence des données.
Au lieu de cela, vous devez construire cette transaction distribuée par programme.
Un modèle populaire pour l’ajout d’une prise en charge transactionnelle distribuée est le modèle Saga. Elle est implémentée en regroupant les transactions locales par programmation et en appelant séquentiellement chacun d’eux. Si l’une des transactions locales échoue, la Saga abandonne l’opération et appelle un ensemble de transactions de compensation. Les transactions de compensation annulent les modifications apportées par les transactions locales précédentes et restaurent la cohérence des données. La figure 5-6 montre une transaction ayant échoué avec le modèle Saga.

Figure 5-6. Restauration d’une transaction
Dans la figure précédente, l’opération Update Inventory a échoué dans le microservice Inventory. La Saga appelle un ensemble de transactions de compensation (en rouge) pour ajuster le nombre d’inventaires, annuler le paiement et la commande, et retourner les données de chaque microservice à un état cohérent.
Les modèles saga sont généralement chorégraphiés sous la forme d’une série d’événements connexes ou orchestrés sous la forme d’un ensemble de commandes connexes. Dans le chapitre 4, nous avons abordé le modèle d'agrégateur de services, qui constituerait la base pour l'implémentation d'une saga orchestrée. Nous avons également abordé la gestion des événements, ainsi que les rubriques Azure Service Bus et Azure Event Grid, qui constitueraient une base pour une implémentation de saga chorégraphiée.
Données volumineuses
Les applications natives cloud volumineuses prennent souvent en charge les besoins en données volumineuses. Dans ces scénarios, les techniques de stockage de données traditionnelles peuvent entraîner des goulots d’étranglement. Pour les systèmes complexes qui se déploient à grande échelle, la séparation des responsabilités de commande et de requête (CQRS) et l’approvisionnement en événements peuvent améliorer les performances des applications.
CQRS
CQRS est un modèle architectural qui peut vous aider à optimiser les performances, l’extensibilité et la sécurité. Le modèle sépare les opérations qui lisent les données de ces opérations qui écrivent des données.
Pour les scénarios normaux, le même modèle d’entité et le même objet de référentiel de données sont utilisés pour les opérations de lecture et d’écriture.
Toutefois, un scénario de données volumineux peut tirer parti de modèles et de tables de données distincts pour les lectures et les écritures. Pour améliorer les performances, l’opération de lecture peut interroger sur une représentation hautement dénormalisée des données afin d’éviter les jointures de tables répétitives coûteuses et les verrous de table. L’opération d’écriture , appelée commande, est mise à jour par rapport à une représentation entièrement normalisée des données qui garantirait la cohérence. Vous devez ensuite implémenter un mécanisme pour conserver les deux représentations synchronisées. En règle générale, chaque fois que la table d’écriture est modifiée, elle publie un événement qui réplique la modification dans la table de lecture.
La figure 5-7 montre une implémentation du modèle CQRS.
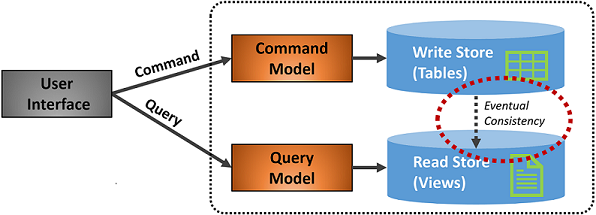
Figure 5-7. Implémentation de CQRS
Dans la figure précédente, des modèles de commande et de requête distincts sont implémentés. Chaque opération d’écriture de données est enregistrée dans le magasin d’écriture, puis propagée au magasin de lecture. Attention particulière à la façon dont le processus de propagation des données fonctionne sur le principe de cohérence éventuelle. Le modèle de lecture se synchronise finalement avec le modèle d’écriture, mais il peut y avoir un décalage dans le processus. Nous abordons la cohérence éventuelle dans la section suivante.
Cette séparation permet aux lectures et aux écritures de se mettre à l’échelle indépendamment. Les opérations de lecture utilisent un schéma optimisé pour les requêtes, tandis que les écritures utilisent un schéma optimisé pour les mises à jour. Les requêtes en lecture vont sur des données dénormalisées, tandis que la logique métier complexe peut être appliquée au modèle d’écriture. De plus, vous pouvez imposer une sécurité plus stricte sur les opérations d’écriture que sur celles qui exposent des lectures.
L’implémentation de CQRS peut améliorer les performances des applications pour les services natifs cloud. Toutefois, elle entraîne une conception plus complexe. Appliquez ce principe soigneusement et stratégiquement à ces sections de votre application native cloud qui en bénéficieront. Pour plus d’informations sur CQRS, consultez le livre Microsoft .NET Microservices : Architecture for Containerized .NET Applications.
Provisionnement en événements
Une autre approche de l’optimisation des scénarios de données à volume élevé implique l’approvisionnement en événements.
Un système stocke généralement l’état actuel d’une entité de données. Si un utilisateur modifie son numéro de téléphone, par exemple, l’enregistrement client est mis à jour avec le nouveau numéro. Nous connaissons toujours l’état actuel d’une entité de données, mais chaque mise à jour remplace l’état précédent.
Dans la plupart des cas, ce modèle fonctionne correctement. Toutefois, dans les systèmes à volume élevé, la surcharge liée au verrouillage transactionnel et aux opérations de mise à jour fréquentes peut avoir un impact sur les performances de la base de données, la réactivité et la limitation de l’extensibilité.
L’approvisionnement en événements prend une approche différente pour capturer des données. Chaque opération qui affecte les données est conservée dans un journal d’événements. Au lieu de mettre à jour l’état d’un enregistrement de données, nous ajoutons chaque modification à une liste séquentielle d’événements passés, semblable au registre d’un comptable. Le Magasin d’événements devient le système d’enregistrement des données. Il est utilisé pour propager différentes vues matérialisées dans le contexte délimité d’un microservice. La figure 5.8 montre le modèle.

Figure 5-8. Approvisionnement en événements
Dans la figure précédente, notez comment chaque entrée (en bleu) pour le panier d’achat d’un utilisateur est ajoutée à un magasin d’événements sous-jacent. Dans la vue matérialisée adjacente, le système projette l’état actuel en relectant tous les événements associés à chaque panier d’achat. Cette vue, ou modèle de lecture, est ensuite exposée à l’interface utilisateur. Les événements peuvent également être intégrés à des systèmes et applications externes ou interrogés pour déterminer l’état actuel d’une entité. Avec cette approche, vous conservez l’historique. Vous connaissez non seulement l’état actuel d’une entité, mais également la façon dont vous avez atteint cet état.
Mécaniquement parlant, l’approvisionnement en événements simplifie le modèle d’écriture. Il n’existe aucune mise à jour ni suppression. L’ajout de chaque entrée de données en tant qu’événement immuable réduit la contention, le verrouillage et les conflits d’accès concurrentiel associés aux bases de données relationnelles. La création de modèles de lecture avec le modèle d’affichage matérialisé vous permet de dissocier la vue du modèle d’écriture et de choisir le meilleur magasin de données pour optimiser les besoins de l’interface utilisateur de votre application.
Pour ce modèle, envisagez un magasin de données qui prend directement en charge l’approvisionnement en événements. Azure Cosmos DB, MongoDB, Cassandra, CouchDB et RavenDB sont de bons candidats.
Comme avec tous les modèles et technologies, implémentez stratégiquement et si nécessaire. Bien que le sourcing d'événements puisse offrir des performances et une scalabilité accrues, cela se fait au prix d'une complexité et d'une courbe d'apprentissage.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.