Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Les conteneurs et les orchestrateurs sont conçus pour résoudre les problèmes courants liés aux approches de déploiement monolithiques.
Défis liés aux déploiements monolithiques
Traditionnellement, la plupart des applications ont été déployées en tant qu’unité unique. Ces applications sont appelées monolithes. Cette approche générale du déploiement d’applications en tant qu’unités uniques, même si elles sont composées de plusieurs modules ou assemblys est appelée architecture monolithique, comme illustré dans la figure 3-1.

Figure 3-1. Architecture monolithique.
Bien qu’elles aient l’avantage de simplicité, les architectures monolithiques font face à de nombreux défis :
Déploiement
En outre, ils nécessitent un redémarrage de l’application, ce qui peut avoir un impact temporaire sur la disponibilité si les techniques de temps d’arrêt zéro ne sont pas appliquées lors du déploiement.
Croissance
Une application monolithique est hébergée entièrement sur une seule instance de machine, nécessitant souvent du matériel à haute capacité. Si une partie du monolithe nécessite une mise à l’échelle, une autre copie de l’application entière doit être déployée sur un autre ordinateur. Avec un monolithe, vous ne pouvez pas mettre à l’échelle les composants d’application individuellement , c’est tout ou rien. La mise à l’échelle des composants qui ne nécessitent pas de mise à l’échelle entraîne une utilisation inefficace et coûteuse des ressources.
Environnement
Les applications monolithiques sont généralement déployées dans un environnement d’hébergement avec un système d’exploitation préinstallé, un runtime et des dépendances de bibliothèque. Cet environnement peut ne pas correspondre à celui sur lequel l’application a été développée ou testée. Les incohérences entre les environnements d’application sont une source courante de problèmes pour les déploiements monolithiques.
Couplage
Une application monolithique est susceptible d’avoir un couplage élevé entre ses composants fonctionnels. Sans limites difficiles, les changements système entraînent souvent des effets secondaires inattendus et coûteux. De nouvelles fonctionnalités/correctifs deviennent difficiles, fastidieux et coûteux à implémenter. Les mises à jour nécessitent des tests étendus. Le couplage rend également difficile la refactorisation des composants ou l’échange dans d’autres implémentations. Même lors de la construction avec une stricte séparation des préoccupations, l’érosion architecturale s’installe à mesure que la base de code monolithique se détériore avec une liste interminable de « cas spéciaux ».
Verrouillage de la plateforme
Une application monolithique est construite avec une pile de technologies unique. Tout en offrant une uniformité, cet engagement peut devenir un obstacle à l’innovation. Les nouvelles fonctionnalités et les nouveaux composants seront construits à l’aide de la pile actuelle de l’application, même lorsque des technologies plus modernes pourraient constituer un meilleur choix. Un risque à long terme est que votre infrastructure technologique devienne obsolète et dépassée. La réarchitecture d’une application entière sur une nouvelle plateforme plus moderne est au mieux coûteuse et risquée.
Quels sont les avantages des conteneurs et des orchestrateurs ?
Nous avons introduit des conteneurs dans le chapitre 1. Nous avons mis en évidence la façon dont cloud Native Computing Foundation (CNCF) classe la conteneurisation comme première étape de leur Cloud-Native Trail Map - conseils pour les entreprises qui commencent leur parcours cloud natif. Dans cette section, nous abordons les avantages des conteneurs.
{kind=link}
Docker est la plateforme de gestion des conteneurs la plus populaire. Il fonctionne avec des conteneurs sur Linux ou Windows. Les conteneurs fournissent des environnements d’application distincts mais reproductibles qui s’exécutent de la même façon sur n’importe quel système. Cet aspect les rend parfaits pour le développement et l’hébergement de services cloud natifs. Les conteneurs sont isolés les uns des autres. Deux conteneurs sur le même matériel hôte peuvent avoir différentes versions de logiciels, sans provoquer de conflits.
Les conteneurs sont définis par des fichiers texte simples qui deviennent des artefacts de projet et sont archivés dans le contrôle de code source. Bien que les serveurs complets et les machines virtuelles nécessitent un effort manuel pour mettre à jour, les conteneurs sont facilement contrôlés par la version. Les applications créées pour s’exécuter dans des conteneurs peuvent être développées, testées et déployées à l’aide d’outils automatisés dans le cadre d’un pipeline de génération.
Les conteneurs sont immuables. Une fois que vous avez défini un conteneur, vous pouvez le recréer et l’exécuter exactement de la même façon. Cette immuabilité se prête à la conception basée sur les composants. Si certaines parties d’une application évoluent différemment des autres, pourquoi redéployer l’ensemble de l’application quand vous pouvez simplement déployer les parties qui changent le plus fréquemment ? Différentes fonctionnalités et préoccupations croisées d’une application peuvent être divisées en unités distinctes. La figure 3-2 montre comment une application monolithique peut tirer parti des conteneurs et des microservices en déléguant certaines fonctionnalités ou fonctionnalités. Les fonctionnalités restantes de l’application elle-même ont également été conteneurisées.
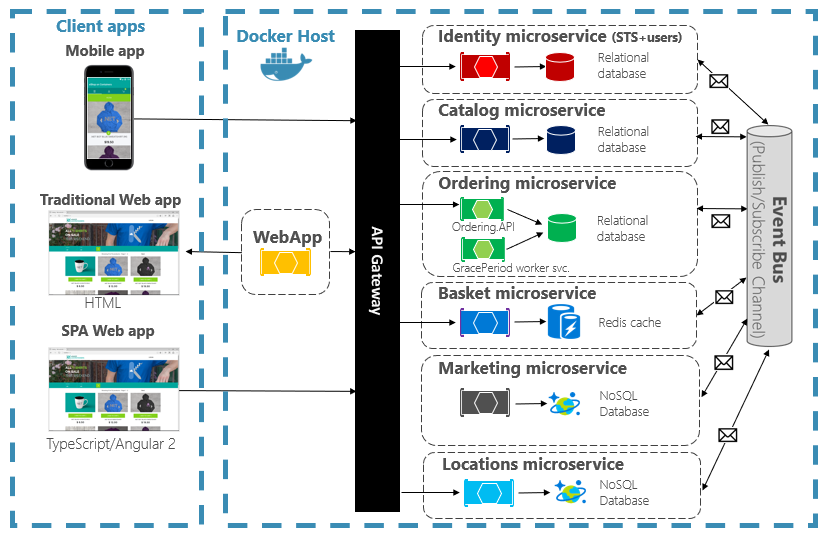
Figure 3-2. Décomposition d’une application monolithique pour adopter des microservices.
Chaque service natif cloud est créé et déployé dans un conteneur distinct. Chacune peut être mise à jour en fonction des besoins. Les services individuels peuvent être hébergés sur des nœuds avec des ressources appropriées pour chaque service. L’environnement dans lequel chaque service s’exécute est immuable, partagé entre les environnements de développement, de test et de production, et facilement versionné. Le couplage entre différentes zones de l’application se produit explicitement en tant qu’appels ou messages entre les services, et non sous forme de dépendances au moment de la compilation dans le monolithe. Vous pouvez également choisir la technologie qui convient le mieux à une fonctionnalité donnée sans nécessiter de modifications apportées au reste de l’application.
Les services conteneurisés nécessitent une gestion automatisée. Il n’est pas possible d’administrer manuellement un grand ensemble de conteneurs déployés indépendamment. Par exemple, tenez compte des tâches suivantes :
- Comment les instances de conteneur seront-elles approvisionnées sur un cluster de nombreux ordinateurs ?
- Une fois déployés, comment les conteneurs vont-ils découvrir et communiquer entre eux ?
- Comment les conteneurs peuvent-ils être mis à l’échelle à la demande ?
- Comment surveiller l’intégrité de chaque conteneur ?
- Comment protéger un conteneur contre les défaillances matérielles et logicielles ?
- Comment mettre à niveau des conteneurs pour une application dynamique sans temps d’arrêt ?
Les orchestrateurs de conteneurs traitent et automatisent ces problèmes et d’autres problèmes.
Dans l’éco-système natif du cloud, Kubernetes est devenu l’orchestrateur de conteneur de facto. Il s’agit d’une plateforme open source gérée par Cloud Native Computing Foundation (CNCF). Kubernetes automatise le déploiement, la mise à l’échelle et les problèmes opérationnels des charges de travail conteneurisées sur un cluster d’ordinateurs. Toutefois, l’installation et la gestion de Kubernetes sont notoirement complexes.
Une approche bien meilleure consiste à tirer parti de Kubernetes en tant que service managé d’un fournisseur de cloud. Le cloud Azure propose une plateforme Kubernetes entièrement managée intitulée Azure Kubernetes Service (AKS). AKS extrait la complexité et la surcharge opérationnelle de la gestion de Kubernetes. Vous utilisez Kubernetes en tant que service cloud ; Microsoft prend la responsabilité de la gestion et de la prise en charge de celui-ci. AKS s’intègre également étroitement à d’autres services Azure et outils de développement.
AKS est une technologie basée sur un cluster. Un pool de machines virtuelles fédérées, ou de nœuds, est déployé dans le cloud Azure. Ensemble, ils forment un environnement hautement disponible ou un cluster. Le cluster s’affiche sous la forme d’une entité unique transparente pour votre application native cloud. Sous le capot, AKS déploie vos services conteneurisés sur ces nœuds en suivant une stratégie prédéfinie qui distribue uniformément la charge.
Quels sont les avantages de la mise à l’échelle ?
Les services basés sur des conteneurs peuvent tirer parti des avantages de mise à l’échelle fournis par des outils d’orchestration tels que Kubernetes. Par conception, les conteneurs ne savent qu’eux-mêmes. Une fois que vous avez plusieurs conteneurs qui doivent fonctionner ensemble, vous devez les organiser à un niveau supérieur. Organiser un grand nombre de conteneurs et leurs dépendances partagées, telles que la configuration du réseau, est là que les outils d’orchestration interviennent pour vous faciliter la tâche ! Kubernetes crée une couche d’abstraction sur des groupes de conteneurs et les organise en pods. Les pods s’exécutent sur des machines Worker appelées nœuds. Cette structure organisée est appelée cluster. La figure 3-3 montre les différents composants d’un cluster Kubernetes.
 Figure 3-3. Composants du cluster Kubernetes.
Figure 3-3. Composants du cluster Kubernetes.
La mise à l’échelle des charges de travail conteneurisées est une fonctionnalité clé des orchestrateurs de conteneurs. AKS prend en charge la mise à l’échelle automatique sur deux dimensions : les instances de conteneur et les nœuds de calcul. Ensemble, ils offrent à AKS la possibilité de répondre rapidement et efficacement aux pics de demande et d’ajouter des ressources supplémentaires. Nous abordons la mise à l’échelle dans AKS plus loin dans ce chapitre.
Déclarative et impérative
Kubernetes prend en charge la configuration déclarative et impérative. L’approche impérative implique l’exécution de différentes commandes qui indiquent à Kubernetes quoi faire à chaque étape du processus. Exécutez cette image. Supprimez ce pod. Exposez ce port. Avec l’approche déclarative, vous créez un fichier de configuration, appelé manifeste, pour décrire ce que vous souhaitez au lieu de ce qu’il faut faire. Kubernetes lit le manifeste et transforme votre état final souhaité en état final réel.
Les commandes impératives sont idéales pour l’apprentissage et l’expérimentation interactive. Toutefois, vous souhaiterez créer de manière déclarative des fichiers manifeste Kubernetes pour adopter une infrastructure en tant qu’approche de code, ce qui fournit des déploiements fiables et reproductibles. Le fichier manifeste devient un artefact de projet et est utilisé dans votre pipeline CI/CD pour automatiser les déploiements Kubernetes.
Si vous avez déjà configuré votre cluster à l’aide de commandes impératives, vous pouvez exporter un manifeste déclaratif à l’aide kubectl get svc SERVICENAME -o yaml > service.yamlde . Cette commande produit un manifeste similaire à celui indiqué ci-dessous :
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2019-09-13T13:58:47Z"
labels:
component: apiserver
provider: kubernetes
name: kubernetes
namespace: default
resourceVersion: "153"
selfLink: /api/v1/namespaces/default/services/kubernetes
uid: 9b1fac62-d62e-11e9-8968-00155d38010d
spec:
clusterIP: 10.96.0.1
ports:
- name: https
port: 443
protocol: TCP
targetPort: 6443
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
Lorsque vous utilisez la configuration déclarative, vous pouvez afficher un aperçu des modifications qui seront apportées avant de les valider à l’aide kubectl diff -f FOLDERNAME du dossier où se trouvent vos fichiers de configuration. Une fois que vous êtes sûr de vouloir appliquer les modifications, exécutez kubectl apply -f FOLDERNAME. Ajoutez -R pour traiter de manière récursive une hiérarchie de dossiers.
Vous pouvez également utiliser la configuration déclarative avec d’autres fonctionnalités Kubernetes, dont l’un est le déploiement. Les déploiements déclaratifs permettent de gérer les versions, les mises à jour et la mise à l’échelle. Ils demandent au contrôleur de déploiement Kubernetes de déployer de nouvelles modifications, d’effectuer un scale-out ou de revenir à une révision précédente. Si un cluster est instable, un déploiement déclaratif retourne automatiquement le cluster à un état souhaité. Par exemple, si un nœud venait à se bloquer, le mécanisme de déploiement pourra redéployer un remplacement pour rétablir l'état souhaité.
L’utilisation de la configuration déclarative permet à l’infrastructure d’être représentée en tant que code qui peut être archivé et versionné en même temps que le code de l’application. Il fournit un contrôle des modifications amélioré et une meilleure prise en charge du déploiement continu à l’aide d’un pipeline de génération et de déploiement.
Quels scénarios sont idéaux pour les conteneurs et les orchestrateurs ?
Les scénarios suivants sont idéaux pour l’utilisation de conteneurs et d’orchestrateurs.
Applications nécessitant une durée de fonctionnement et une scalabilité élevées
Les applications individuelles qui ont des exigences élevées en matière de temps d’activité et d’extensibilité sont idéales pour les architectures natives cloud à l’aide de microservices, de conteneurs et d’orchestrateurs. Ils peuvent être développés dans des conteneurs, testés dans des environnements avec version et déployés en production sans temps d’arrêt. L’utilisation de clusters Kubernetes assure que ces applications peuvent également s'adapter à la demande et récupérer automatiquement après des pannes de nœud.
Grand nombre d’applications
Les organisations qui déploient et gèrent un grand nombre d’applications bénéficient de conteneurs et d’orchestrateurs. L’effort initial de configuration des environnements conteneurisés et des clusters Kubernetes est principalement un coût fixe. Le déploiement, la maintenance et la mise à jour d’applications individuelles ont un coût qui varie en fonction du nombre d’applications. Au-delà de quelques applications, la complexité de la maintenance manuelle des applications personnalisées dépasse le coût d’implémentation d’une solution à l’aide de conteneurs et d’orchestrateurs.
Quand devez-vous éviter d’utiliser des conteneurs et des orchestrateurs ?
Si vous ne parvenez pas à générer votre application en suivant les principes de l’application Twelve-Factor, vous devez envisager d’éviter les conteneurs et les orchestrateurs. Dans ces cas, envisagez une plateforme d’hébergement basée sur une machine virtuelle, ou éventuellement un système hybride. Avec cela, vous pouvez toujours déplacer certaines fonctionnalités dans des conteneurs distincts ou même des fonctions sans serveur.
Ressources de développement
Cette section présente une courte liste de ressources de développement qui peuvent vous aider à commencer à utiliser des conteneurs et des orchestrateurs pour votre application suivante. Si vous recherchez des conseils sur la conception de votre application d’architecture de microservices natives dans le cloud, lisez le compagnon de ce livre, .NET Microservices : Architecture pour les applications .NET en conteneur.
Développement Kubernetes local
Les déploiements Kubernetes offrent une grande valeur dans les environnements de production, mais peuvent également s’exécuter localement sur votre machine de développement. Bien que vous puissiez travailler indépendamment sur des microservices individuels, il peut arriver que vous deviez exécuter l’ensemble du système localement, tout comme il s’exécutera lors du déploiement en production. Il existe plusieurs outils qui peuvent vous aider : Minikube et Docker Desktop. Visual Studio fournit également des outils pour le développement Docker.
Minikube
Qu’est-ce que Minikube ? Le projet Minikube indique « Minikube implémente un cluster Kubernetes local sur macOS, Linux et Windows ». Ses principaux objectifs sont « d’être le meilleur outil pour le développement d’applications Kubernetes local et de prendre en charge toutes les fonctionnalités Kubernetes adaptées ». L’installation de Minikube est distincte de Docker, mais Minikube prend en charge différents hyperviseurs que Docker Desktop. Les fonctionnalités Kubernetes suivantes sont actuellement prises en charge par Minikube :
- Système de noms de domaine (DNS)
- NodePorts
- ConfigMaps et secrets
- Tableaux de bord
- Runtimes de conteneur : Docker, rkt, CRI-O et containerd
- Activation de l’interface réseau de conteneur (CNI)
- Entrée
Après avoir installé Minikube, vous pouvez rapidement commencer à l’utiliser en exécutant la minikube start commande, qui télécharge une image et démarre le cluster Kubernetes local. Une fois le cluster démarré, vous interagissez avec lui à l’aide des commandes Kubernetes kubectl standard.
Docker Desktop
Vous pouvez également utiliser Kubernetes directement à partir de Docker Desktop sur Windows. Il s’agit de votre seule option si vous utilisez des conteneurs Windows et est également un excellent choix pour les conteneurs non-Windows. La figure 3-4 montre comment activer la prise en charge locale de Kubernetes lors de l’exécution de Docker Desktop.

Figure 3-4. Configuration de Kubernetes dans Docker Desktop.
Docker Desktop est l’outil le plus populaire pour configurer et exécuter des applications conteneurisées localement. Lorsque vous travaillez avec Docker Desktop, vous pouvez développer localement sur le même ensemble d’images conteneur Docker que celles que vous allez déployer en production. Docker Desktop est conçu pour « générer, tester et expédier » des applications conteneurisées localement. Il prend en charge les conteneurs Linux et Windows. Une fois que vous envoyez vos images à un registre d’images, comme Azure Container Registry ou Docker Hub, AKS peut les extraire et les déployer en production.
Outils Docker de Visual Studio
Visual Studio prend en charge le développement Docker pour les applications web. Lorsque vous créez une application ASP.NET Core, vous avez la possibilité de la configurer avec la prise en charge de Docker, comme illustré dans la figure 3-5.
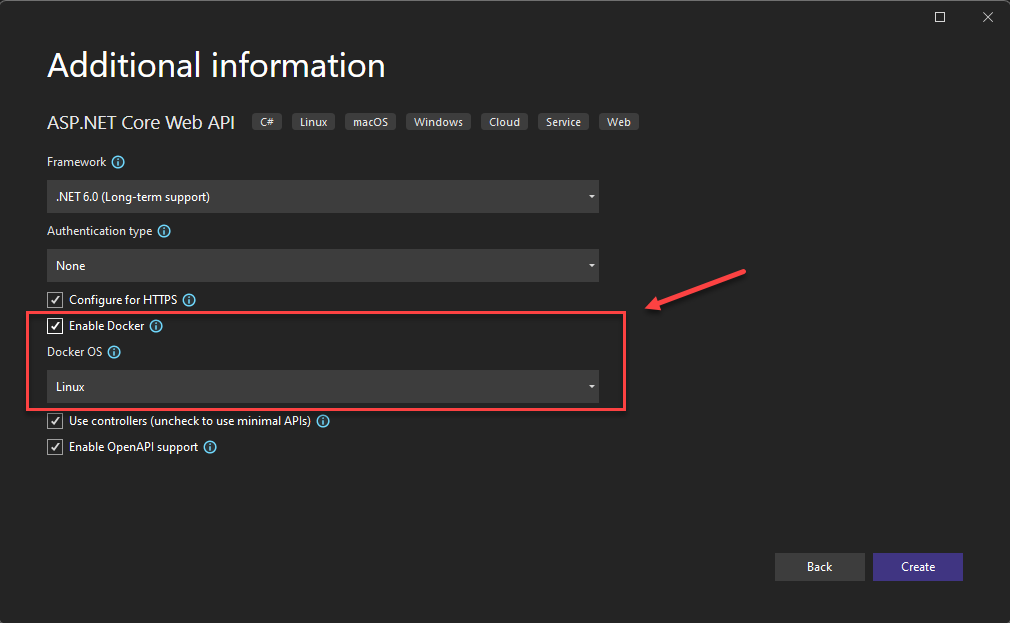
Figure 3-5. Activer la prise en charge de Docker dans Visual Studio
Lorsque cette option est sélectionnée, le projet est créé avec une Dockerfile racine, qui peut être utilisée pour générer et héberger l’application dans un conteneur Docker. Un exemple de fichier Dockerfile est illustré dans la figure 3-6.
FROM mcr.microsoft.com/dotnet/aspnet:7.0 AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443
FROM mcr.microsoft.com/dotnet/sdk:7.0 AS build
WORKDIR /src
COPY ["eShopWeb/eShopWeb.csproj", "eShopWeb/"]
RUN dotnet restore "eShopWeb/eShopWeb.csproj"
COPY . .
WORKDIR "/src/eShopWeb"
RUN dotnet build "eShopWeb.csproj" -c Release -o /app/build
FROM build AS publish
RUN dotnet publish "eShopWeb.csproj" -c Release -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "eShopWeb.dll"]
Figure 3-6. Fichier Dockerfile généré par Visual Studio
Une fois la prise en charge ajoutée, vous pouvez exécuter votre application dans un conteneur Docker dans Visual Studio. La figure 3-7 montre les différentes options d’exécution disponibles à partir d’un nouveau projet ASP.NET Core créé avec la prise en charge de Docker ajoutée.

Figure 3-7. Options d’exécution De Visual Studio Docker
En outre, à tout moment, vous pouvez ajouter la prise en charge de Docker à une application ASP.NET Core existante. Dans l’Explorateur de solutions Visual Studio, cliquez avec le bouton droit sur le projet et sélectionnez Ajouter> unsupport Docker, comme illustré dans la figure 3-8.
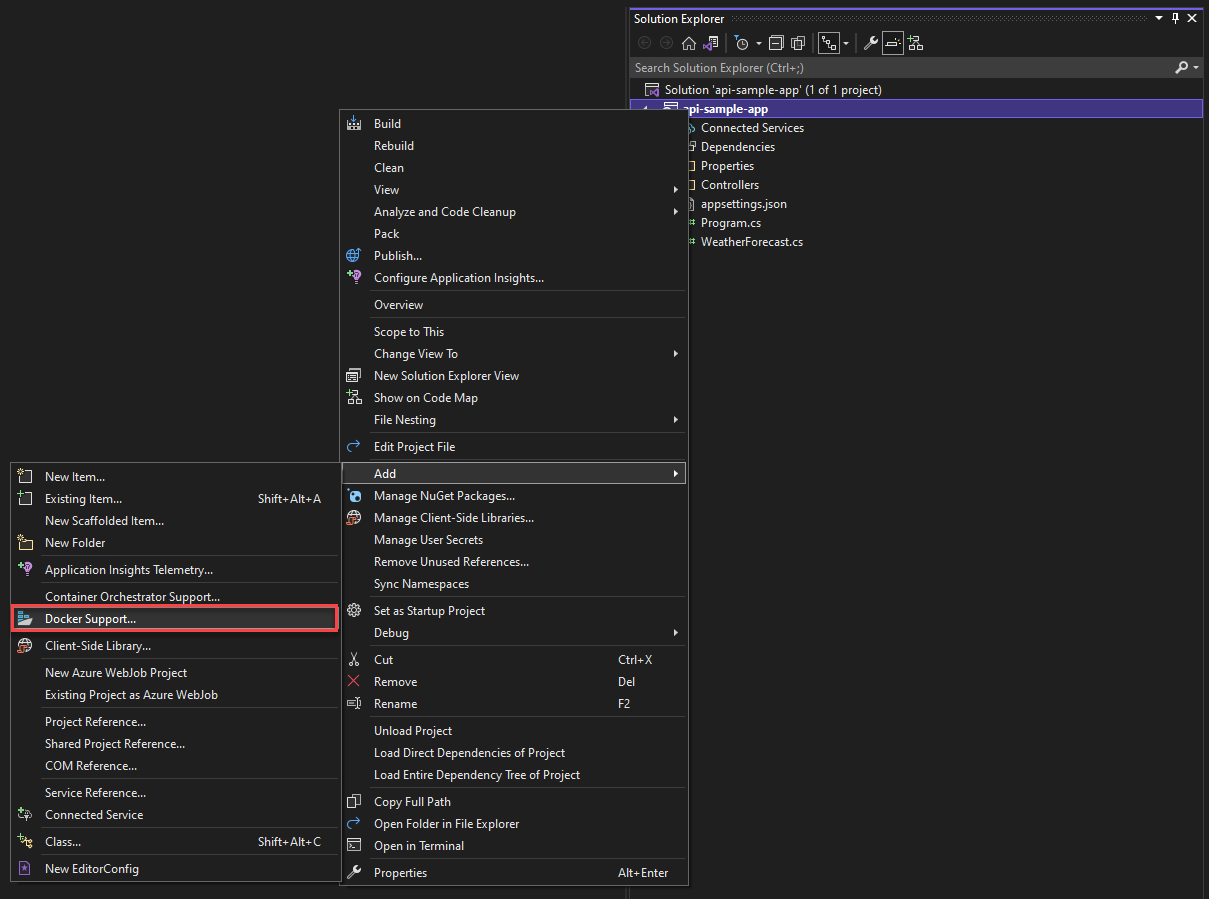
Figure 3-8. Ajout de la prise en charge de Docker à Visual Studio
Outils de Docker pour Visual Studio Code
De nombreuses extensions sont disponibles pour Visual Studio Code qui prennent en charge le développement Docker.
Microsoft fournit l’extension Docker pour Visual Studio Code. Cette extension simplifie le processus d’ajout de la prise en charge des conteneurs aux applications. Il génère des fichiers requis, génère des images Docker et vous permet de déboguer votre application à l’intérieur d’un conteneur. L’extension propose un explorateur visuel qui facilite l’exécution d’actions sur des conteneurs et des images tels que le démarrage, l’arrêt, l’inspection, la suppression et bien plus encore. L’extension prend également en charge Docker Compose, ce qui vous permet de gérer plusieurs conteneurs en cours d’exécution en tant qu’unité unique.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.