Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Tout comme les modèles ont été développés pour faciliter la disposition du code dans les applications, il existe des modèles pour l’exploitation d’applications de manière fiable. Trois modèles utiles pour la maintenance des applications ont émergé : journalisation, surveillance et alertes.
Quand utiliser la journalisation
Peu importe la prudence dont nous faisons preuve, les applications se comportent presque toujours de manière inattendue en production. Lorsque les utilisateurs signalent des problèmes avec une application, il est utile de voir ce qui se passait avec l’application lorsque le problème s’est produit. L’une des méthodes les plus essayées et les plus vraies de capturer des informations sur ce qu’une application fait pendant son exécution consiste à faire en sorte que l’application écrive ce qu’elle fait. Ce processus est appelé journalisation. Chaque fois que des défaillances ou des problèmes se produisent en production, l’objectif doit être de reproduire les conditions dans lesquelles les défaillances se sont produites, dans un environnement hors production. Mettre en place une bonne journalisation fournit une feuille de route pour que les développeurs puissent reproduire les problèmes dans un environnement qui peut être testé et expérimenté.
Défis liés à la journalisation avec des applications natives cloud
Dans les applications traditionnelles, les fichiers journaux sont généralement stockés sur l’ordinateur local. En fait, sur les systèmes d’exploitation de type Unix, il existe une structure de dossiers définie pour contenir tous les journaux, généralement sous /var/log.
 Figure 7-1. Journalisation sur un fichier dans une application monolithique.
Figure 7-1. Journalisation sur un fichier dans une application monolithique.
L’utilité de la journalisation dans un fichier plat sur un seul ordinateur est largement réduite dans un environnement cloud. Les applications produisant des journaux d’activité peuvent ne pas avoir accès au disque local ou le disque local peut être très temporaire, car les conteneurs sont mélangés autour de machines physiques. Même un simple scale-up d’applications monolithiques sur plusieurs nœuds peut compliquer la localisation du fichier journal basé sur fichiers approprié.
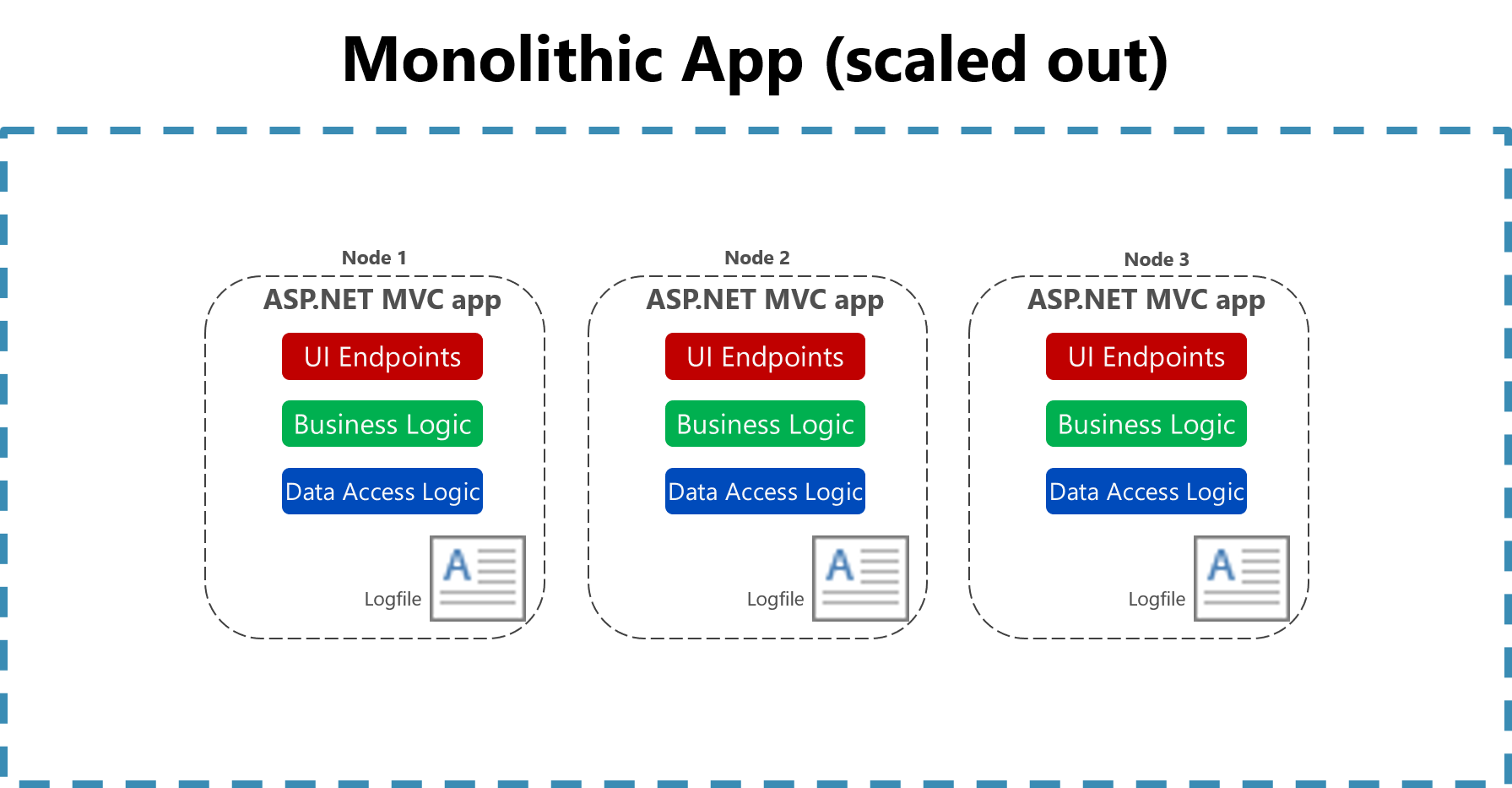 Figure 7-2. Journalisation sur fichiers dans une application monolithique mise à l’échelle.
Figure 7-2. Journalisation sur fichiers dans une application monolithique mise à l’échelle.
Les applications natives cloud développées à l’aide d’une architecture de microservices présentent également des défis pour les enregistreurs d’événements basés sur des fichiers. Les demandes utilisateur peuvent désormais s’étendre sur plusieurs services exécutés sur différents ordinateurs et peuvent inclure des fonctions serverless sans accès à un système de fichiers local du tout. Il serait très difficile de mettre en corrélation les journaux d’activité d’un utilisateur ou d’une session sur ces nombreux services et machines.
 Figure 7-3. Journalisation sur des fichiers locaux dans une application de microservices.
Figure 7-3. Journalisation sur des fichiers locaux dans une application de microservices.
Enfin, le nombre d’utilisateurs dans certaines applications natives cloud est élevé. Imaginez que chaque utilisateur génère une centaine de lignes de messages de journal lorsqu’il se connecte à une application. Isolé, cela est gérable, mais multipliez cela par plus de 100 000 utilisateurs et le volume de logs devient suffisamment grand pour que des outils spécialisés soient nécessaires pour soutenir une utilisation efficace des logs.
Journalisation dans les applications natives cloud
Chaque langage de programmation dispose d'outils qui permettent d'écrire des logs, et généralement la surcharge liée à l'écriture de ces logs est faible. La plupart des bibliothèques de journalisation offrent la journalisation de différents niveaux de criticité, qui peuvent être ajustés au moment de l'exécution. Par exemple, la bibliothèque Serilog est une bibliothèque de journalisation structurée populaire pour .NET qui fournit les niveaux de journalisation suivants :
- Verbeux
- Déboguer
- Informations
- Avertissement
- Erreur
- Erreur irrécupérable
Ces différents niveaux de journalisation fournissent une granularité dans la journalisation. Lorsque l’application fonctionne correctement en production, elle peut être configurée pour journaliser uniquement les messages importants. Lorsque l'application ne se comporte pas correctement, le niveau de journalisation peut être augmenté afin que des journaux plus détaillés soient collectés. Cela crée un équilibre entre les performances et la facilité de débogage.
Les performances élevées des outils de journalisation et le réglage de la verbosité devraient encourager les développeurs à journaliser souvent. Beaucoup privilégient un modèle de journalisation de l’entrée et de la sortie de chaque méthode. Cette approche peut sembler excessive, mais il est peu fréquent que les développeurs souhaitent moins de journalisation. En fait, il n’est pas rare d’effectuer des déploiements dans le seul but d’ajouter une journalisation autour d’une méthode problématique. Mieux vaut choisir trop de journalisation que pas assez. Certains outils peuvent être utilisés pour fournir automatiquement ce type de journalisation.
En raison des défis liés à l’utilisation de journaux basés sur des fichiers dans des applications cloud natives, les journaux centralisés sont préférés. Les journaux sont collectés par les applications et envoyés à une application de journalisation centrale qui indexe et stocke les journaux. Cette catégorie de systèmes peut ingérer des dizaines de gigaoctets de logs chaque jour.
Il est également utile de suivre certaines pratiques standard lors de la création d’une journalisation qui englobe de nombreux services. Par exemple, la génération d’un ID de corrélation au début d’une longue interaction, puis la journalise dans chaque message lié à cette interaction, facilite la recherche de tous les messages associés. Il n’est nécessaire de trouver qu’un seul message et d’extraire l’ID de corrélation pour rechercher tous les messages associés. Un autre exemple consiste à s’assurer que le format du journal est le même pour chaque service, quelle que soit la langue ou la bibliothèque de journalisation qu’elle utilise. Cette normalisation facilite beaucoup la lecture des journaux. La figure 7-4 montre comment une architecture de microservices peut tirer parti de la journalisation centralisée dans le cadre de son workflow.
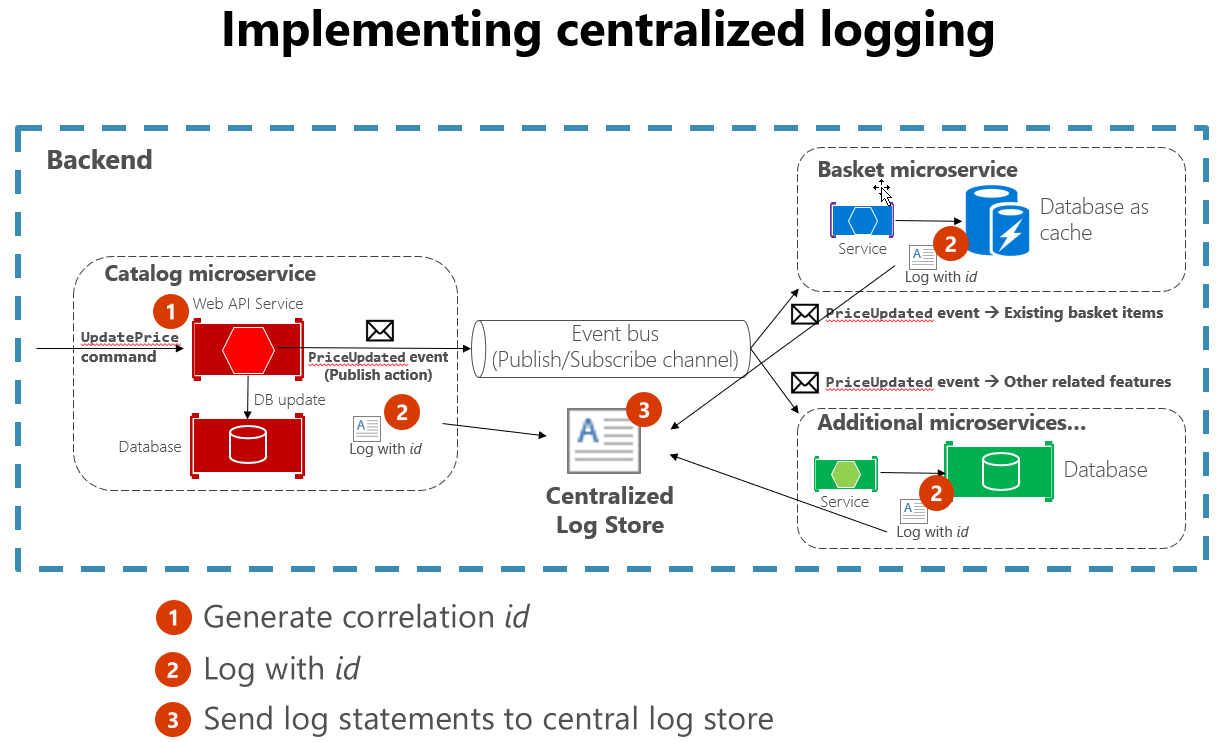 Figure 7-4. Des journaux de sources diverses sont ingérés dans un magasin de journaux centralisé.
Figure 7-4. Des journaux de sources diverses sont ingérés dans un magasin de journaux centralisé.
Défis liés à la détection et à la réponse aux problèmes potentiels d’intégrité des applications
Certaines applications ne sont pas critiques. Peut-être qu’ils sont utilisés uniquement en interne et lorsqu’un problème se produit, l’utilisateur peut contacter l’équipe responsable et l’application peut être redémarrée. Toutefois, les clients ont souvent des attentes plus élevées pour les applications qu’ils consomment. Vous devez savoir quand des problèmes se produisent avec votre application avant que les utilisateurs ne le fassent, ou avant que les utilisateurs vous avertissent. Sinon, la première fois que vous pourriez être informé d'un problème, c'est lorsque vous remarquez un déluge de publications sur les réseaux sociaux critiquant vivement votre application ou même votre organisation.
Voici quelques scénarios que vous devrez peut-être prendre en compte :
- Un service de votre application continue d’échouer et de redémarrer, ce qui entraîne des réponses lentes intermittentes.
- À certains moments de la journée, le temps de réponse de votre application est lent.
- Après un déploiement récent, la charge sur la base de données a triplé.
Implémenté correctement, la surveillance peut vous informer des conditions qui entraîneront des problèmes, vous permettant de résoudre les conditions sous-jacentes avant qu’elles n’entraînent un impact significatif sur l’utilisateur.
Surveillance des applications natives cloud
Certains systèmes de journalisation centralisés prennent un rôle supplémentaire pour collecter des données de télémétrie en dehors des journaux purs. Ils peuvent collecter des métriques, telles que le temps d’exécution d’une requête de base de données, le temps de réponse moyen à partir d’un serveur web, et même les moyennes de charge processeur et la sollicitation de la mémoire, comme indiqué par le système d’exploitation. Conjointement avec les journaux de bord, ces systèmes peuvent fournir une vue globale de l'état des nœuds du système et de l'application dans son ensemble.
Les fonctionnalités de collecte des métriques des outils de surveillance peuvent également être alimentées manuellement à partir de l’application. Les flux métier qui sont d’intérêt particulier, tels que les nouveaux utilisateurs qui s’inscrivent ou les commandes en cours de placement, peuvent être instrumentés afin qu’ils incrémentent un compteur dans le système de surveillance central. Cet aspect déverrouille les outils de surveillance pour surveiller non seulement l’intégrité de l’application, mais aussi l’intégrité de l’entreprise.
Les requêtes peuvent être construites dans les outils d’agrégation de journaux pour rechercher certaines statistiques ou modèles, qui peuvent ensuite être affichés sous forme graphique, sur des tableaux de bord personnalisés. Fréquemment, les équipes investiront dans de grands écrans montés sur mur qui pivotent dans les statistiques liées à une application. De cette façon, il est simple de voir les problèmes à mesure qu’ils se produisent.
Les outils de supervision natifs du cloud fournissent des données de télémétrie en temps réel et des insights sur les applications, qu’elles soient des applications monolithiques à processus unique ou des architectures de microservice distribuées. Ils incluent des outils qui permettent la collecte de données à partir de l'application, ainsi que des outils permettant d'interroger et d'afficher des informations sur l'état de santé de l'application.
Défis liés à la réaction aux problèmes critiques dans les applications natives cloud
Si vous avez besoin de réagir aux problèmes liés à votre application, vous avez besoin d’un moyen d’alerter le personnel approprié. Il s’agit du troisième modèle d’observabilité des applications natives cloud et dépend de la journalisation et de la supervision. Votre application doit disposer d’une journalisation pour permettre le diagnostic des problèmes et, dans certains cas, alimenter des outils de surveillance. Il a besoin d’une surveillance pour agréger les métriques d’application et les données de santé en un seul endroit. Une fois cette opération établie, des règles peuvent être créées pour déclencher des alertes lorsque certaines métriques tombent en dehors des niveaux acceptables.
En règle générale, les alertes sont superposées à la surveillance afin que certaines conditions déclenchent des alertes appropriées pour informer les membres de l’équipe des problèmes urgents. Voici quelques scénarios qui peuvent nécessiter des alertes :
- L’un des services de votre application ne répond pas après 1 minute de temps d’arrêt.
- Votre application retourne des réponses HTTP infructueuses à plus de 1% de requêtes.
- Le temps de réponse moyen de votre application pour les points de terminaison clés dépasse 2 000 ms.
Alertes dans les applications natives cloud
Vous pouvez créer des requêtes sur les outils de surveillance pour rechercher des conditions d’échec connues. Par exemple, les requêtes peuvent rechercher dans les journaux entrants des indications du code d’état HTTP 500, ce qui indique un problème sur un serveur web. Dès qu’un de ces messages est détecté, un e-mail ou un SMS peut être envoyé au propriétaire du service d’origine qui peut commencer à enquêter.
En règle générale, toutefois, une seule erreur 500 n’est pas suffisante pour déterminer qu’un problème s’est produit. Cela peut signifier qu’un utilisateur a mal tapé son mot de passe ou entré des données incorrectes. Les requêtes d’alerte peuvent être conçues pour être déclenchées uniquement lorsqu’un nombre supérieur à 500 erreurs est détecté.
L’un des modèles les plus nuisibles dans les alertes consiste à déclencher trop d’alertes pour que les humains enquêtent. Les propriétaires de services seront rapidement désensitisés aux erreurs qu’ils ont précédemment examinées et trouvées comme étant bénignes. Ensuite, quand des erreurs vraies se produisent, elles seront perdues dans le bruit de centaines de faux positifs. La parable du garçon qui criait loup est fréquemment racontée aux enfants pour les avertir de ce danger. Il est important de s’assurer que les alertes qui se déclenchent indiquent un problème réel.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.