Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Note
Cet article se concentre sur une architecture de solution à partir des architectures de solution CI/CD et ALM (Gestion du cycle de vie des applications) pour Dataflow Gen2 qui s’appuie sur la fonctionnalité de mode paramètres publics et s’applique uniquement à la prise en charge CI/CD.
Les paramètres dans Fabric Dataflow Gen2 vous permettent de définir des entrées réutilisables qui modélisent la façon dont un dataflow est conçu, et avec le mode de paramètres publics , ces entrées peuvent être définies au moment de l’exécution via des pipelines ou des API. Il rend un flux de données unique hautement flexible et polyvalent, car vous pouvez réutiliser la même logique dans de nombreux scénarios simplement en passant des valeurs différentes, en activant des flux de travail dynamiques et automatisés sans jamais avoir besoin de réécrire ou de dupliquer les transformations.
Ce tutoriel vous guide tout au long d’un exemple qui vous montre comment :
- Paramétrer une source : utilisation d’un Lakehouse avec l’exemple de jeu de données WideWorldImporters comme source
- Paramétrer la logique : utilisation des widgets d’entrée disponibles tout au long de l’expérience dataflow
- Paramétrer la destination : utilisation d’un entrepôt comme destination
- Envoyer une demande d’exécution avec des valeurs de paramètre : passage de valeurs de paramètre par l'intermédiaire de l'expérience d'activité flux de données au sein d’un pipeline Fabric.

Note
Les concepts présentés dans cet article sont universels pour Dataflow Gen2 et s’appliquent à d’autres sources et destinations au-delà de celles présentées ici.
Scénario

Le flux de données utilisé dans ce scénario est simple, mais les principes fondamentaux décrits s’appliquent à tous les types de dataflows. Il se connecte à la table nommée dimension_city à partir de l’exemple de jeu de données Wide World Importers stocké dans un Lakehouse. Il filtre les lignes où la colonne SalesTerritory est égale au Sud-Est et charge le résultat dans une nouvelle table appelée City in a Warehouse. Tous les composants ( Lakehouse, Warehouse et Dataflow) se trouvent dans le même espace de travail. Pour rendre le flux de données dynamique, vous paramétrez la table source, la valeur de filtre et la table de destination. Ces modifications permettent au dataflow de s’exécuter avec des valeurs spécifiques au lieu de celles codées en dur.
Avant de continuer, activez le mode paramètres publics en accédant à l’onglet Accueil , en sélectionnant Options et dans la section Paramètres , cochez la case Activer les paramètres à découvrir et remplacer pour l’exécution et autoriser votre dataflow à accepter des paramètres pendant l’exécution.

Paramétrer la source
Lorsque vous utilisez l’un des connecteurs Fabric, tels que Lakehouse, Warehouse ou Fabric SQL, ils suivent toutes la même structure de navigation et utilisent le même format d’entrée. Dans ce scénario, aucun des connecteurs n’a besoin d’une entrée manuelle pour établir une connexion. Toutefois, chacun affiche l’espace de travail et l’élément auquel il se connecte via les étapes de navigation de votre requête. Par exemple, la première étape de navigation inclut l’id d’espace de travail auquel la requête se connecte.

L’objectif est de remplacer les valeurs codées en dur dans la barre de formule par des paramètres. Plus précisément, vous devez créer un paramètre pour workspaceId et un autre pour LakehouseId. Pour créer des paramètres, accédez à l’onglet Accueil du ruban, sélectionnez Gérer les paramètres, puis choisissez Nouveau paramètre dans le menu déroulant.

Lorsque vous créez les paramètres, vérifiez que les deux sont marqués comme requis et définis sur le type de texte . Pour leurs valeurs actuelles, utilisez celles qui correspondent aux valeurs correspondantes de votre environnement spécifique.

Une fois les deux paramètres créés, vous pouvez mettre à jour le script de requête pour les utiliser au lieu de valeurs codées en dur. Cela implique de remplacer manuellement les valeurs d’origine dans la barre de formule par des références aux paramètres ID d’espace de travail et ID Lakehouse. Le script de requête d’origine ressemble à ceci :
let
Source = Lakehouse.Contents([]),
#"Navigation 1" = Source{[workspaceId = "8b325b2b-ad69-4103-93ae-d6880d9f87c6"]}[Data],
#"Navigation 2" = #"Navigation 1"{[lakehouseId = "2455f240-7345-4c8b-8524-c1abbf107d07"]}[Data],
#"Navigation 3" = #"Navigation 2"{[Id = "dimension_city", ItemKind = "Table"]}[Data],
#"Filtered rows" = Table.SelectRows(#"Navigation 3", each ([SalesTerritory] = "Southeast")),
#"Removed columns" = Table.RemoveColumns(#"Filtered rows", {"ValidFrom", "ValidTo", "LineageKey"})
in
#"Removed columns"
Une fois que vous avez mis à jour les références dans les étapes de navigation, votre nouveau script mis à jour peut ressembler à ceci :
let
Source = Lakehouse.Contents([]),
#"Navigation 1" = Source{[workspaceId = WorkspaceId]}[Data],
#"Navigation 2" = #"Navigation 1"{[lakehouseId = LakehouseId]}[Data],
#"Navigation 3" = #"Navigation 2"{[Id = "dimension_city", ItemKind = "Table"]}[Data],
#"Filtered rows" = Table.SelectRows(#"Navigation 3", each ([SalesTerritory] = "Southeast")),
#"Removed columns" = Table.RemoveColumns(#"Filtered rows", {"ValidFrom", "ValidTo", "LineageKey"})
in
#"Removed columns"
Vous remarquerez également qu’il évalue toujours correctement l’aperçu des données dans l’éditeur dataflow.
Paramétrer la logique
Maintenant que la source utilise des paramètres, vous pouvez vous concentrer sur le paramétrage de la logique de transformation du flux de données. Dans ce scénario, l’étape de filtre est l’emplacement où la logique est appliquée et la valeur filtrée, actuellement codée en dur comme sud-est, doit être remplacée par un paramètre. Pour ce faire, créez un paramètre nommé Territory, définissez son type de données sur texte, marquez-le comme non requis et définissez sa valeur actuelle sur Mideast.

Étant donné que votre étape de filtre a été créée à l’aide de l’interface utilisateur, vous pouvez passer à l’étape des lignes filtrées, double-cliquez sur elle pour ouvrir la boîte de dialogue des paramètres de l'étape de filtre. Cette boîte de dialogue vous permet de sélectionner, via le widget d’entrée, si vous souhaitez utiliser un paramètre au lieu d’une valeur statique :
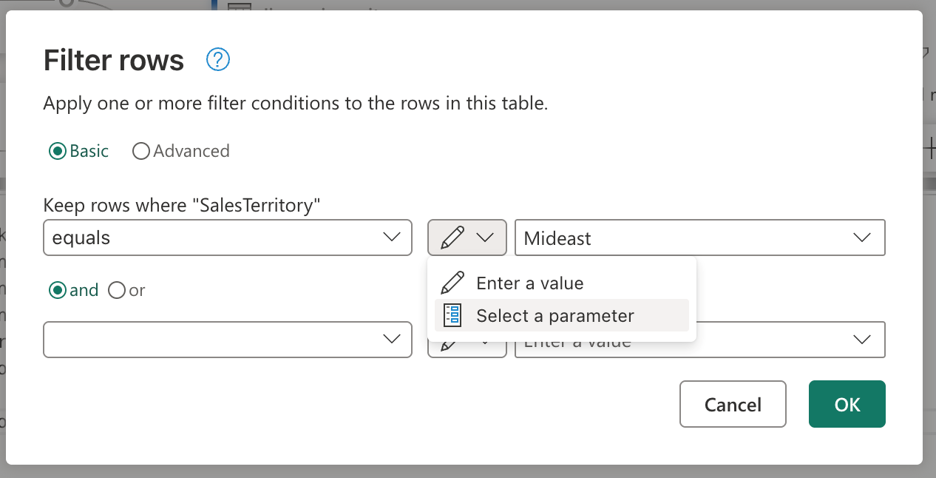
Après avoir sélectionné l’option Sélectionner un paramètre, une liste déroulante s’affiche pour afficher tous les paramètres disponibles qui correspondent au type de données requis. Dans cette liste, vous pouvez sélectionner le paramètre Territory nouvellement créé.
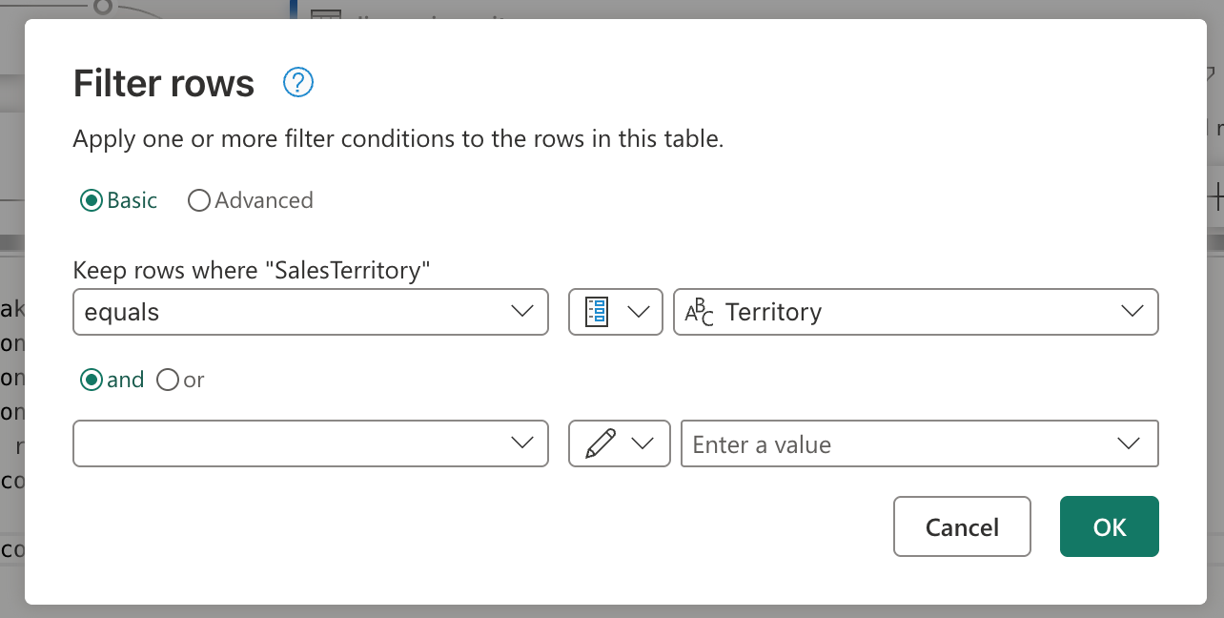
Une fois que vous avez sélectionné OK, notez que la vue de diagramme a déjà créé le lien entre le paramètre nouvellement créé et la requête en cours d’utilisation. L’aperçu des données affiche maintenant des informations pour le territoire du Moyen-Orient, non seulement cela.

Paramétrer la destination
Note
Il est recommandé de vous familiariser avec le concept de destinations de données dans Dataflow Gen2 et la façon dont son script mashup est créé à partir de l’article sur les destinations de données et les paramètres managés
Le dernier composant à paramétrer dans ce scénario est la destination. Bien que les informations sur la destination des données soient disponibles dans l’éditeur de flux de données, pour paramétrer cette partie du flux de données, vous devez utiliser Git ou l’API REST.

Ce tutoriel vous montre comment apporter les modifications via Git. Avant de pouvoir apporter des modifications via Git, veillez à :
- Créez un paramètre portant le nom WarehouseId : veillez à utiliser l’ID correspondant de votre entrepôt comme valeur actuelle, définissez-le comme requis et du type de données texte.
- Enregistrez le flux de données : utilisez le bouton Enregistrer sous l’onglet Accueil du ruban.
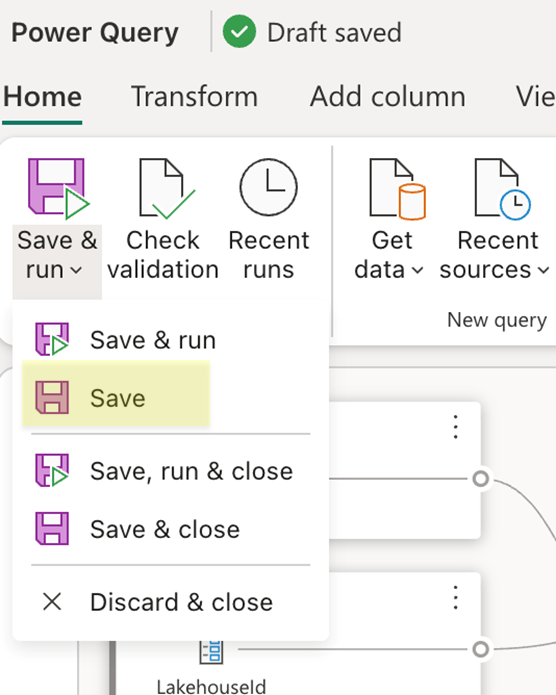
Une fois votre dataflow enregistré, veillez à valider les modifications apportées à votre dépôt Git et à accéder à votre dépôt pour afficher le fichier mashup.pq de votre dataflow. Lorsque vous examinez le fichier mashup.pq , recherchez la requête avec laquelle vous avez associé la destination des données. Dans ce scénario, le nom de cette requête est dimension_city. Vous voyez un attribut d’enregistrement au-dessus de ce nom de requête :
[DataDestinations = {[Definition = [Kind = "Reference", QueryName = "dimension_city_DataDestination", IsNewTarget = true], Settings = [Kind = "Manual", AllowCreation = true, ColumnSettings = [Mappings = {[SourceColumnName = "CityKey", DestinationColumnName = "CityKey"], [SourceColumnName = "WWICityID", DestinationColumnName = "WWICityID"], [SourceColumnName = "City", DestinationColumnName = "City"], [SourceColumnName = "StateProvince", DestinationColumnName = "StateProvince"], [SourceColumnName = "Country", DestinationColumnName = "Country"], [SourceColumnName = "Continent", DestinationColumnName = "Continent"], [SourceColumnName = "SalesTerritory", DestinationColumnName = "SalesTerritory"], [SourceColumnName = "Region", DestinationColumnName = "Region"], [SourceColumnName = "Subregion", DestinationColumnName = "Subregion"], [SourceColumnName = "Location", DestinationColumnName = "Location"], [SourceColumnName = "LatestRecordedPopulation", DestinationColumnName = "LatestRecordedPopulation"]}], DynamicSchema = false, UpdateMethod = [Kind = "Replace"], TypeSettings = [Kind = "Table"]]]}]
shared dimension_city = let
Cet enregistrement d’attribut a un champ portant le nom QueryName, qui contient le nom de la requête qui a toutes les logiques de destination de données associées à cette requête. Cette requête se présente comme suit :
shared dimension_city_DataDestination = let
Pattern = Fabric.Warehouse([HierarchicalNavigation = null, CreateNavigationProperties = false]),
Navigation_1 = Pattern{[workspaceId = "8b325b2b-ad69-4103-93ae-d6880d9f87c6"]}[Data],
Navigation_2 = Navigation_1{[warehouseId = "527ba9c1-4077-433f-a491-9ef370e9230a"]}[Data],
TableNavigation = Navigation_2{[Item = "City", Schema = "dbo"]}?[Data]?
in
TableNavigation
Vous remarquez que, de la même façon que le script de la source pour Lakehouse, ce script pour la destination a un modèle similaire où il code en dur le workspaceid qui doit être utilisé et également le warehouseId. Remplacez ces valeurs fixes par les identificateurs des paramètres et votre script doit se présenter comme suit :
shared dimension_city_DataDestination = let
Pattern = Fabric.Warehouse([HierarchicalNavigation = null, CreateNavigationProperties = false]),
Navigation_1 = Pattern{[workspaceId = WorkspaceId]}[Data],
Navigation_2 = Navigation_1{[warehouseId = WarehouseId]}[Data],
TableNavigation = Navigation_2{[Item = "City", Schema = "dbo"]}?[Data]?
in
TableNavigation
Vous pouvez maintenant valider cette modification et mettre à jour votre flux de données à l’aide des modifications de votre flux de données via la fonctionnalité de contrôle de code source dans votre espace de travail. Vous pouvez vérifier que toutes les modifications sont en place en ouvrant votre dataflow et en examinant la destination des données et toutes les références de paramètres précédentes ajoutées. Cela finalise tout le paramétrage de votre dataflow et vous pouvez maintenant passer à l’exécution de votre dataflow en passant des valeurs de paramètre pour l’exécution.
Exécuter la requête avec des valeurs de paramètre
Vous pouvez utiliser l’API REST Fabric pour envoyer une demande d’exécution avec une charge utile personnalisée qui contient vos valeurs de paramètre pour cette opération d’exécution spécifique et vous pouvez également utiliser l’API REST pour découvrir les paramètres de flux de données et comprendre ce que le flux de données attend afin qu’il puisse déclencher une exécution. Dans ce tutoriel, vous allez utiliser l’expérience trouvée dans l’activité Dataflow pour les pipelines Fabric. Commencez par créer un pipeline et ajouter une nouvelle activité de flux de données au canevas . Dans les paramètres de l’activité, recherchez l’espace de travail où se trouve votre dataflow, puis sélectionnez le flux de données dans la liste déroulante.

Une section de paramètres de dataflow peut être développée pour afficher tous les paramètres disponibles dans le dataflow et leurs valeurs par défaut. Vous pouvez remplacer toutes les valeurs ici et les valeurs passées seront utilisées pour définir les sources, la logique et la destination qui doivent être utilisées pour évaluer votre exécution de flux de données. Vous pouvez également donner à de nouveaux scénarios une tentative en créant un entrepôt et en modifiant l’WarehouseId pour l’évaluation ou en utilisant ce modèle dans un pipeline de déploiement où workspaceId et d’autres paramètres doivent être passés pour pointer vers les éléments corrects dans l’environnement correspondant.