Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel de 15 minutes explique comment accumuler de manière incrémentielle des données dans un lakehouse à l’aide de Dataflow Gen2.
L’accumulation incrémentielle de données dans une destination de données nécessite une technique pour charger uniquement des données nouvelles ou mises à jour dans votre destination de données. Cette technique peut être effectuée en utilisant une requête pour filtrer les données en fonction de leur destination. Ce tutoriel montre comment créer un flux de données pour charger des données à partir d’une source OData dans un lakehouse et comment ajouter une requête au flux de données pour filtrer les données en fonction de leu destination.
Les étapes générales de ce tutoriel sont les suivantes :
- Créez un flux de données pour charger des données à partir d’une source OData dans un lakehouse.
- Ajoutez une requête au flux de données pour filtrer les données en fonction de leur destination.
- (Facultatif) rechargez les données à l’aide de notebooks et de pipelines.
Prérequis
Vous devez disposer d’un espace de travail Microsoft Azure Fabric activé. Si vous n’en avez pas encore, reportez-vous à l’article Créer un espace de travail. En outre, le didacticiel suppose que vous utilisez la vue diagramme dans Dataflow Gen2. Pour vérifier si vous utilisez la Vue Diagramme, dans le ruban supérieur, accédez à Affichage et vérifiez que Vue Diagramme est sélectionnée.
Créer un flux de données pour charger des données à partir d’une source OData dans un lakehouse
Dans cette section, vous allez créer un flux de données pour charger des données à partir d’une source OData dans un lakehouse.
Créez un lakehouse dans votre espace de travail.

Créez un flux de données Gen2 dans votre espace de travail.

Ajoutez une nouvelle source au flux de données. Sélectionnez la source OData et entrez l’URL suivante :
https://services.OData.org/V4/Northwind/Northwind.svc


Sélectionnez le tableau Ordres puis Suivant.
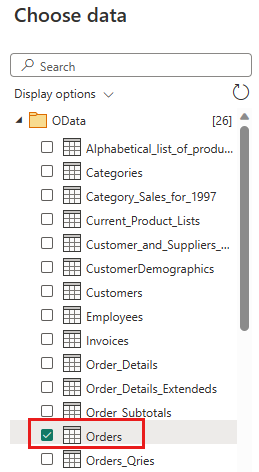
Sélectionnez les colonnes suivantes à conserver :
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry

Remplacez le type de données de
OrderDate,RequiredDateetShippedDatepardatetime.
Configurez la destination des données vers votre lakehouse à l’aide des paramètres suivants :
- Destination des données :
Lakehouse - Lakehouse : sélectionnez le lakehouse que vous avez créé à l’étape 1.
- Nouveau nom de table:
Orders - Mettre à jour la méthode :
Replace



- Destination des données :
sélectionnez Suivant et publiez le flux de données.



Vous avez maintenant créé un flux de données pour charger des données à partir d’une source OData vers un lakehouse. Ce flux de données est utilisé dans la section suivante pour ajouter une requête au flux de données afin de filtrer les données en fonction de leur destination. Après cela, vous pouvez utiliser le flux de données pour recharger des données à l’aide de notebooks et de pipelines.
Ajouter une requête au flux de données pour filtrer les données en fonction de leur destination
Cette section ajoute une requête au flux de données pour filtrer les données en fonction des données du lakehouse de destination. La requête obtient le maximum OrderID dans le lakehouse au début de l’actualisation du flux de données et utilise l’ID d’ordre maximal pour obtenir uniquement les commandes avec un ID d’ordre supérieur de à la source à ajouter à votre destination de données. Cela suppose que les commandes sont ajoutées à la source dans l’ordre croissant de OrderID. Si ce n’est pas le cas, vous pouvez utiliser une autre colonne pour filtrer les données. Par exemple, vous pouvez utiliser la colonne OrderDate pour filtrer les données.
Remarque
Les filtres OData sont appliqués dans Fabric une fois les données reçues de la source de données. Toutefois, pour les sources de base de données telles que SQL Server, le filtre est appliqué dans la requête envoyée à la source de données back-end, et seules les lignes filtrées sont retournées au service.
Après l’actualisation du flux de données, rouvrez le flux de données que vous avez créé dans la section précédente.
Créez une requête nommée
IncrementalOrderIDet obtenez des données à partir de la table Ordre dans le lakehouse que vous avez créé dans la section précédente.



Désactivez la préproduction de cette requête.

Dans l’aperçu des données, cliquez avec le bouton droit sur la colonne
OrderIDet sélectionnez Descendre dans la hiérarchie.
Dans le ruban, sélectionnez Outils de liste ->Statistiques ->Maximum.

Vous disposez maintenant d’une requête qui retourne l’ID d’ordre maximal dans le lakehouse. Cette requête est utilisée pour filtrer les données de la source OData. La section suivante ajoute une requête au flux de données pour filtrer les données à partir de la source OData en fonction de l’ID d’ordre maximal dans le lakehouse.
Retour à la requête Ordres et ajoutez une nouvelle étape pour filtrer les données. Utilisez les paramètres suivants :
- Colonne :
OrderID - Opération :
Greater than - Valeur : paramètre
IncrementalOrderID

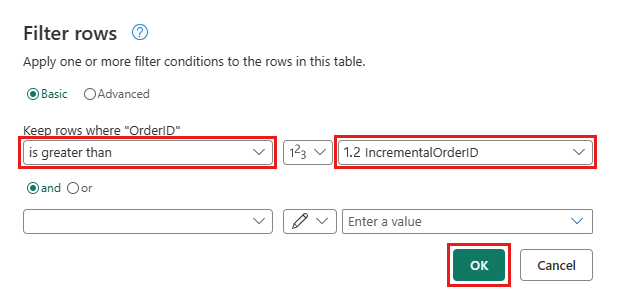
- Colonne :
Autorisez la combinaison des données de la source OData et du lakehouse en confirmant la boîte de dialogue suivante :

Mettez à jour la destination des données pour utiliser les paramètres suivants :
- Mettre à jour la méthode :
Append

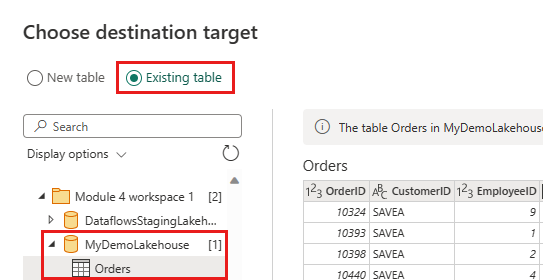

- Mettre à jour la méthode :
Publiez le flux de données.
Votre flux de données contient désormais une requête qui filtre les données de la source OData en fonction de l’ID d’ordre maximal dans lakehouse. Cela signifie que seules les données nouvelles ou mises à jour sont chargées dans le lakehouse. La section suivante utilise le flux de données pour recharger les données à l’aide de notebooks et de pipelines.
(Facultatif) recharger des données à l’aide de notebooks et de pipelines
Si vous le souhaitez, vous pouvez recharger des données spécifiques à l’aide de notebooks et de pipelines. Avec du code Python personnalisé dans le notebook, vous supprimez les anciennes données du lakehouse. En créant ensuite un pipeline dans lequel vous exécutez d’abord le notebook et exécutez séquentiellement le flux de données, vous rechargez les données de la source OData dans le lakehouse. Les notebooks prennent en charge plusieurs langages, mais ce tutoriel utilise PySpark. Pyspark est une API Python pour Spark et est utilisé dans ce tutoriel pour exécuter des requêtes Spark SQL.
Créer un nouveau notebook dans votre espace de travail.
Ajoutez le code PySpark suivant à votre notebook :
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Exécutez le notebook pour vérifier que les données sont supprimées du lakehouse.
Créez un nouveau pipeline dans votre espace de travail.

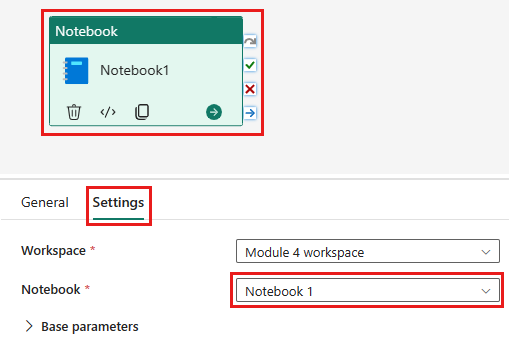
Ajoutez une nouvelle activité de notebook au pipeline et sélectionnez le notebook que vous avez créé à l’étape précédente.

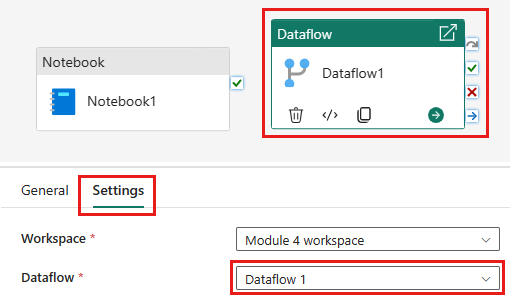
Ajoutez une nouvelle activité de flux de données au pipeline et sélectionnez le flux de données que vous avez créé dans la section précédente.

Liez l’activité du notebook à l’activité de flux de données avec un déclencheur de réussite.

Enregistrez et exécutez le pipeline.


Vous disposez maintenant d’un pipeline qui supprime les anciennes données du lakehouse et recharge les données de la source OData dans lakehouse. Avec cette configuration, vous pouvez recharger régulièrement les données de la source OData dans l'entrepôt de données.