Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Kusto Query Language (KQL) a des fonctions intégrées de détection et de prévision d’anomalies pour vérifier le comportement anormal. Une fois qu’un tel modèle est détecté, une analyse de la cause racine (RCA) peut être exécutée pour atténuer ou résoudre l’anomalie.
Le processus de diagnostic est complexe et long et fait par des experts du domaine. Ce processus inclut les éléments suivants :
- Extraction et jointure de données à partir de différentes sources pour la même période
- Recherche de modifications dans la distribution des valeurs sur plusieurs dimensions
- Tracer plus de variables
- Autres techniques basées sur les connaissances et l’intuition du domaine
Étant donné que ces scénarios de diagnostic sont courants, les plug-ins Machine Learning sont disponibles pour faciliter la phase de diagnostic et raccourcir la durée du RCA.
Les trois plug-ins Machine Learning suivants implémentent des algorithmes de clustering : autocluster, basketet diffpatterns. Les plugins autocluster et basket groupent un ensemble d’enregistrements unique, et le plugin diffpatterns groupe les différences entre deux ensembles d’enregistrements.
Regroupement d’un jeu d’enregistrements unique
Un scénario courant inclut un jeu de données sélectionné par des critères spécifiques tels que :
- Fenêtre de temps qui affiche un comportement anormal
- Lectures d’appareils à haute température
- Commandes de longue durée
- Principaux utilisateurs de dépenses
Vous souhaitez trouver rapidement et facilement des modèles courants (segments) dans les données. Les modèles sont un sous-ensemble du jeu de données dont les enregistrements partagent les mêmes valeurs sur plusieurs dimensions (colonnes catégorielles).
La requête suivante génère et affiche une série chronologique d’exceptions de service sur une semaine, dans des intervalles de dix minutes :
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")

Le nombre d’exceptions de service correspond au trafic global du service. Vous pouvez clairement voir le modèle quotidien pour les jours ouvrables, du lundi au vendredi. Il y a une augmentation du nombre d’exceptions de service à la mi-journée, et des baisses de nombres pendant la nuit. Des chiffres bas et stables sont visibles pendant le week-end. Les pics d’exceptions peuvent être détectés à l’aide de la détection des anomalies de série chronologique.
Le deuxième pic des données se produit le mardi après-midi. La requête suivante est utilisée pour diagnostiquer et vérifier s’il s’agit d’une hausse soudaine. La requête redessine le graphique autour de la pointe avec une résolution plus fine de huit heures dans des intervalles d'une minute. Vous pouvez alors la délimiter.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")

Vous observez une brève pointe de deux minutes de 15:00 à 15:02. Dans la requête suivante, comptez les exceptions dans cette fenêtre de deux minutes :
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Nombre |
|---|
| 972 |
Dans la requête suivante, exemple 20 exceptions sur 972 :
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Région | ScaleUnit | IdentifiantDeDéploiement | Point de trace | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Même s’il existe moins d’un millier d’exceptions, il est toujours difficile de trouver des segments communs, car il existe plusieurs valeurs dans chaque colonne. Vous pouvez utiliser le autocluster() plug-in pour extraire instantanément une courte liste de segments communs et rechercher les clusters intéressants dans les deux minutes du pic, comme indiqué dans la requête suivante :
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| Identifiant de Segment | Nombre | Pourcentage | Région | ScaleUnit | IdentifiantDeDéploiement | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5,65843621399177 | Ueo | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
Vous pouvez voir à partir des résultats ci-dessus que le segment le plus dominant contient 65,74% du total des enregistrements d’exception et partage quatre dimensions. Le segment suivant est beaucoup moins courant. Il ne contient que 9,67% des enregistrements et partage trois dimensions. Les autres segments sont encore moins courants.
Autocluster utilise un algorithme propriétaire pour l’exploration de plusieurs dimensions et l’extraction de segments intéressants. « Intéressant » signifie que chaque segment a une couverture significative de l'ensemble des enregistrements et de l'ensemble des fonctionnalités. Les segments sont également divergents, ce qui signifie que chacun est différent des autres. Un ou plusieurs de ces segments peuvent être pertinents pour le processus RCA. Pour réduire la révision et l’évaluation des segments, le cluster automatique extrait uniquement une petite liste de segments.
Vous pouvez également utiliser le basket() plug-in comme indiqué dans la requête suivante :
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| Identifiant de Segment | Nombre | Pourcentage | Région | ScaleUnit | IdentifiantDeDéploiement | Point de trace | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5,65843621399177 | Ueo | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9,25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Le panier implémente l’algorithme « Apriori » pour l’exploration de données d’ensemble d’éléments. Il extrait tous les segments dont la couverture du jeu d’enregistrements est supérieure à un seuil (5%par défaut). Vous pouvez voir que plusieurs segments ont été extraits avec des segments similaires, tels que les segments 0, 1 ou 2, 3.
Les deux plug-ins sont puissants et faciles à utiliser. Leur limitation est qu’ils clusternt un jeu d’enregistrements unique de manière non supervisée sans étiquettes. Il n’est pas clair si les modèles extraits caractérisent le jeu d’enregistrements sélectionné, les enregistrements anormaux ou le jeu d’enregistrements global.
Groupement de la différence entre deux ensembles d’enregistrements
Le diffpatterns() plug-in dépasse la limitation de autocluster et basket.
Diffpatterns prend deux jeux d’enregistrements et extrait les segments principaux qui sont différents. En général, un ensemble contient le jeu de données d'anomalies en cours d'analyse. On est analysé par autocluster et basket. L’autre jeu contient le jeu d’enregistrements de référence, la base de référence.
Dans la requête suivante, diffpatterns recherche des clusters intéressants dans les deux minutes du pic, qui sont différents des clusters au sein de la base de référence. La fenêtre de référence est définie comme étant les huit minutes avant 15:00, lorsque le pic a démarré. Vous étendez par une colonne binaire (AB) et spécifiez si un enregistrement spécifique appartient à la base de référence ou à l’ensemble anormal.
Diffpatterns implémente un algorithme d’apprentissage supervisé, où les deux étiquettes de classe ont été générées par le drapeau anormal par rapport au drapeau de référence (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| Identifiant de Segment | CountA | CountB | Pourcentage A | PercentB | Différence en pourcentage AB | Région | ScaleUnit | IdentifiantDeDéploiement | Point de trace |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | Vingt-et-un | 65.74 | 1.7 | 64.04 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 3:56 | 9.47 | 28,9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25,81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5,66 | 20.45 | 14.8 | Ueo | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
Le segment le plus dominant est le même segment qui a été extrait par autocluster. Sa couverture sur la fenêtre anormale de deux minutes est également de 65,74%. Toutefois, sa couverture sur la fenêtre de référence de huit minutes est seulement de 1,7%. La différence est de 64,04%. Cette différence semble être liée au pic anormal. Pour vérifier cette hypothèse, la requête suivante fractionne le graphique d’origine en enregistrements appartenant à ce segment problématique et les enregistrements des autres segments.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
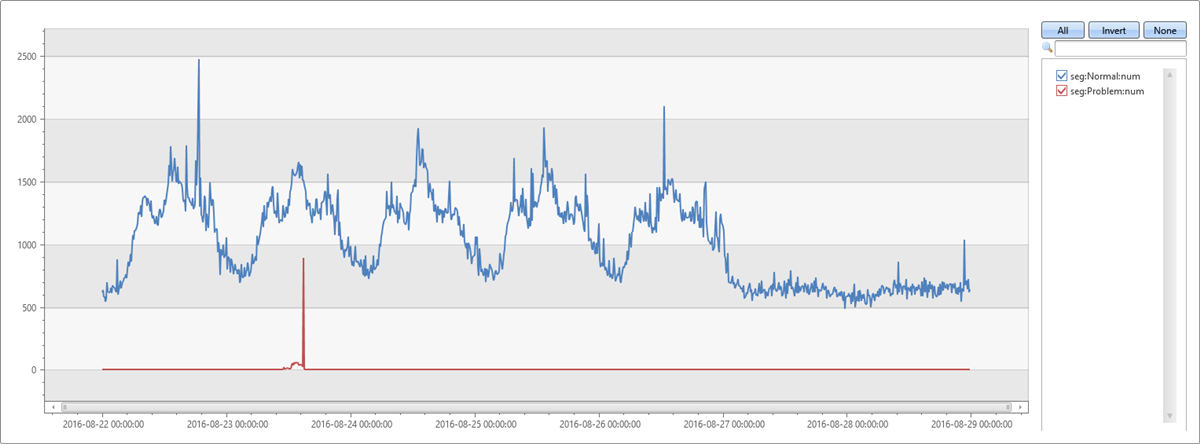
Ce graphique nous permet de voir que le pic du mardi après-midi était dû à des exceptions de ce segment spécifique, découvert à l’aide du diffpatterns plug-in.
Résumé
Les plug-ins Machine Learning sont utiles pour de nombreux scénarios. L’algorithme autocluster d’apprentissage non supervisé et basket implémente et implémente un algorithme d’apprentissage non supervisé.
Diffpatterns implémente un algorithme d’apprentissage supervisé et, bien que plus complexe, il est plus puissant pour extraire des segments de différenciation pour rca.
Ces plug-ins sont utilisés de manière interactive dans des scénarios ad hoc et dans des services de surveillance en temps quasi réel automatiques. La détection des anomalies de série chronologique est suivie d’un processus de diagnostic. Le processus est hautement optimisé pour répondre aux normes de performances nécessaires.