Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’un des scénarios courants qui se produisent lorsque vous intégrez des données dans Dataverse le maintient synchronisé avec la source. À l’aide du dataflow standard, vous pouvez charger des données dans Dataverse. Cet article explique comment conserver les données synchronisées avec le système source.
Importance de la colonne clé
Si vous utilisez un système de base de données relationnelle comme source, normalement, vous avez des colonnes clés dans les tables, et les données sont dans un format approprié pour être chargées dans Dataverse. Toutefois, les données des fichiers Excel ne sont pas toujours aussi propres. Vous disposez souvent d’un fichier Excel avec des feuilles de données sans avoir de colonne clé. Dans les considérations relatives au mappage de champs pour les dataflows standard, vous pouvez voir que s’il existe une colonne clé dans la source, elle peut être facilement utilisée comme autre clé dans le mappage de champ du flux de données.

L’utilisation d’une colonne clé est importante pour la table dans Dataverse. La colonne clé est l’identificateur de ligne ; cette colonne contient des valeurs uniques dans chaque ligne. L’utilisation d’une colonne clé permet d’éviter les lignes en double, et elle permet également de synchroniser les données avec le système source. Si une ligne est supprimée du système source, la présence d’une colonne clé est utile pour la trouver et la supprimer de Dataverse.
Création d’une colonne clé
Si vous n’avez pas de colonne clé dans votre source de données (Excel, fichier texte ou toute autre source), vous pouvez en générer une à l’aide de la méthode suivante :
Nettoyez vos données.
La première étape de création de la colonne clé consiste à supprimer toutes les lignes inutiles, à nettoyer les données, à supprimer les lignes vides et à supprimer les doublons possibles.
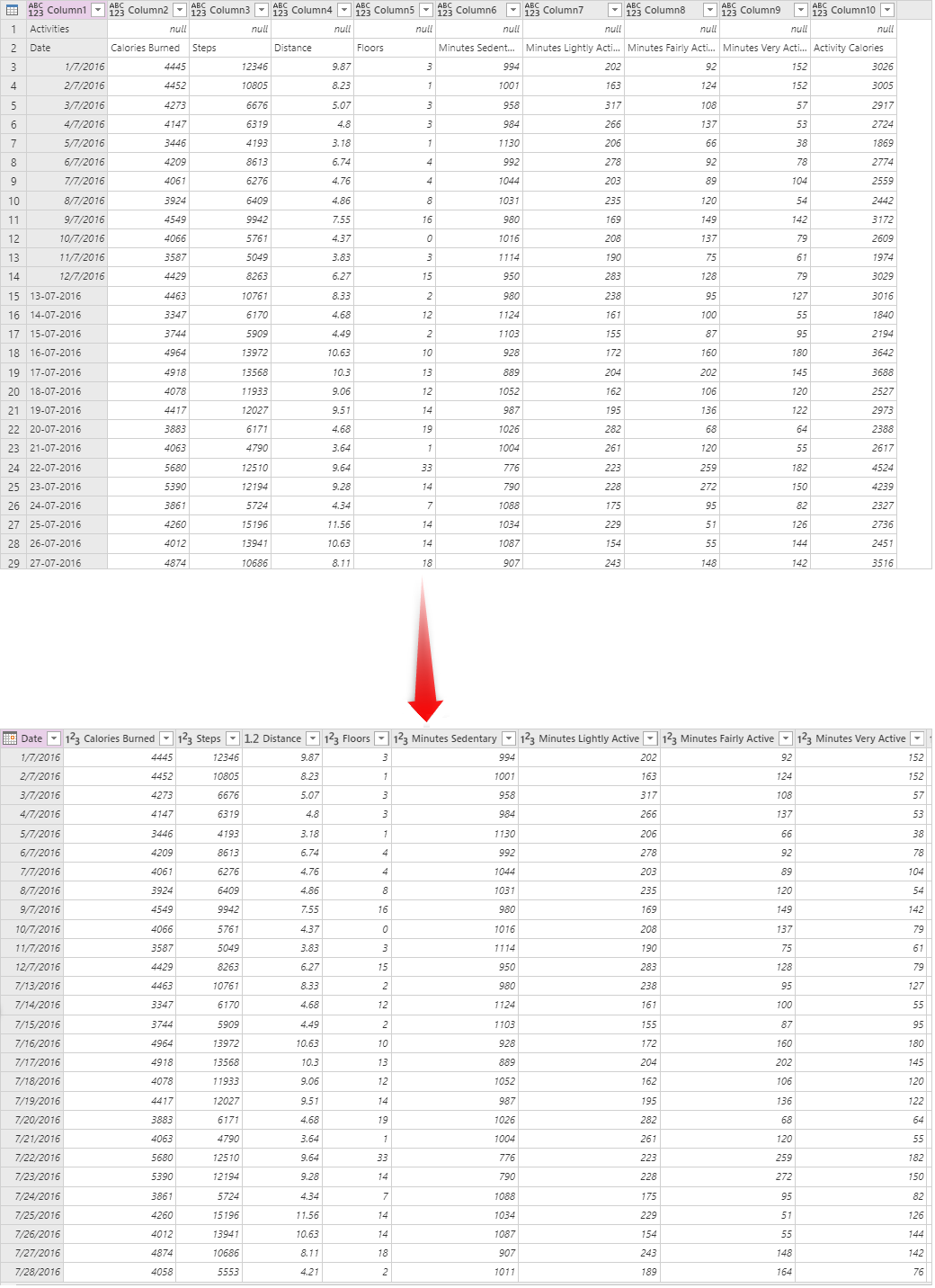
Ajoutez une colonne d’index.
Une fois les données nettoyées, l’étape suivante consiste à lui attribuer une colonne clé. Vous pouvez utiliser Ajouter une colonne d’index à partir de l’onglet Ajouter une colonne à cet effet.

Lorsque vous ajoutez la colonne d’index, vous disposez de certaines options pour la personnaliser, par exemple des personnalisations sur le numéro de départ ou le nombre de valeurs à sauter à chaque fois. La valeur de début par défaut est zéro et incrémente une valeur à chaque fois.
Utiliser la colonne clé comme autre clé
Maintenant que vous disposez des colonnes clés, vous pouvez affecter le mappage de champs du flux de données à la clé secondaire.

Le paramètre est simple, vous devez simplement définir la clé secondaire. Toutefois, si vous avez plusieurs fichiers ou tables, il a une autre étape à prendre en compte.
Si vous avez plusieurs fichiers
Si vous n’avez qu’un seul fichier Excel (ou feuille ou tableau), les étapes de la procédure précédente sont suffisantes pour définir la clé de remplacement. Toutefois, si vous avez plusieurs fichiers (ou feuilles ou tables) avec la même structure (mais avec des données différentes), vous devez les ajouter ensemble.
Si vous obtenez des données à partir de plusieurs fichiers Excel, l’option Combiner des fichiers de Power Query ajoute automatiquement toutes les données, et votre sortie ressemble à l’image suivante.
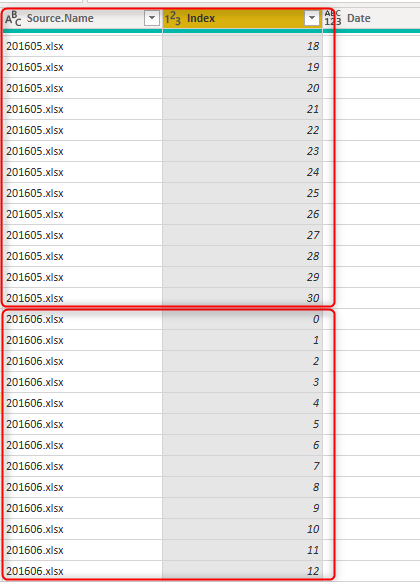
Comme indiqué dans l’image précédente, outre le résultat d’ajout, Power Query apporte également la colonne Source.Name, qui contient le nom de fichier. La valeur d’index dans chaque fichier peut être unique, mais elle n’est pas unique sur plusieurs fichiers. Toutefois, la combinaison de la colonne Index et de la colonne Source.Name est une combinaison unique. Choisissez une autre clé composite pour ce scénario.

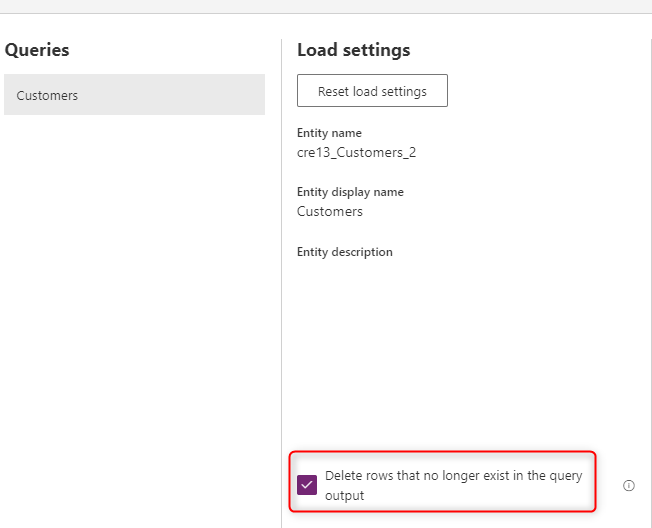
Supprimer des lignes qui n’existent plus dans la sortie de la requête
La dernière étape consiste à sélectionner les lignes Supprimer qui n’existent plus dans la sortie de la requête. Cette option compare les données de la table Dataverse aux données provenant de la source en fonction de la clé alternative (qui peut être une clé composite) et supprime les lignes qui n’existent plus. Par conséquent, vos données dans Dataverse sont toujours synchronisées avec votre source de données.