Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Table des matières
- Résumé
- Paramétrage
- Exécuter l’exemple de toy
- Exécuter pascal VOC
- Entraîner CNTK Fast R-CNN sur vos propres données
- Détails techniques
- Détails de l’algorithme
Résumé


Ce tutoriel explique comment utiliser CNTK Fast R-CNN avec BrainScript et cntk.exe. R-CNN rapide utilisant l’API Python CNTK est décrit ici.
Les exemples ci-dessus sont des exemples d’images et d’annotations d’objets pour le jeu de données d’épicerie (première image) et le jeu de données Pascal VOC (deuxième image) utilisé dans ce didacticiel.
Fast R-CNN est un algorithme de détection d’objets proposé par Ross Girshick en 2015. Le document est accepté à ICCV 2015 et archivé à https://arxiv.org/abs/1504.08083. R-CNN rapide s’appuie sur les travaux précédents pour classifier efficacement les propositions d’objets à l’aide de réseaux convolutionnels profonds. Par rapport au travail précédent, Fast R-CNN utilise une région de regroupement d’intérêts qui permet de réutiliser les calculs des couches convolutionnelles.
Matériel supplémentaire : un didacticiel détaillé pour la détection d’objets à l’aide de CNTK Fast R-CNN avec BrainScript (y compris l’entraînement SVM facultatif et la publication du modèle entraîné en tant qu’API Rest) sont disponibles ici.
Programme d’installation
Pour exécuter le code dans cet exemple, vous avez besoin d’un environnement Python CNTK (voir ici pour obtenir de l’aide sur l’installation). Vous devez également installer quelques packages supplémentaires. Accédez au dossier FastRCNN et exécutez :
pip install -r requirements.txt
Problème connu : pour installer scikit-learn, vous devrez peut-être exécuter conda install scikit-learn si vous utilisez Anaconda Python.
Vous aurez besoin de Scikit-Image et d’OpenCV pour exécuter ces exemples.
Téléchargez les packages de roue correspondants et installez-les manuellement. Sur Linux, vous pouvez conda install scikit-image opencv.
Pour les utilisateurs Windows, visitez http://www.lfd.uci.edu/~gohlke/pythonlibs/et téléchargez :
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
Une fois que vous avez téléchargé les fichiers binaires de roue respectifs, installez-les avec :
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! REMARQUE] : si vous voyez le message No module nommé auparavant lors de l’exécution des scripts, exécutez pip install future.
Ce code de tutoriel suppose que vous utilisez la version 64bits de Python 3.5 ou 3.6, car les fichiers DLL R-CNN rapides requis sous utils sont prédéfinis pour ces versions. Si votre tâche nécessite l’utilisation d’une autre version de Python, recompilez ces fichiers DLL vous-même dans l’environnement approprié (voir ci-dessous).
Le tutoriel part du principe que le dossier où se trouve cntk.exe réside dans votre variable d’environnement PATH. (Pour ajouter le dossier à votre chemin d’accès, vous pouvez exécuter la commande suivante à partir d’une ligne de commande (en supposant que le dossier où cntk.exe se trouve sur votre ordinateur est C:\src\CNTK\x64\Release) : set PATH=C:\src\CNTK\x64\Release;%PATH%.)
Fichiers binaires précompilés pour la régression de zone englobante et la suppression non maximale
Le dossier Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils contient des fichiers binaires précompilés requis pour l’exécution de Fast R-CNN. Les versions qui sont actuellement contenues dans le référentiel sont Python 3.5 et 3.6, toutes les versions 64 bits. Si vous avez besoin d’une autre version, vous pouvez la compiler comme suit :
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmake- Au lieu de
makevous pouvez exécuterpython setup.py build_ext --inplaceà partir du même dossier. Sur Windows, vous devrez peut-être commenter les args de compilation supplémentaires dans lib/setup.py :
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]- Au lieu de
copiez les fichiers binaires générés
cython_bboxcython_nmsà partir de$FRCN_ROOT/lib/utils$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils.
Exemple de modèle de base et de données
Nous utilisons un modèle AlexNet préentraîné comme base pour la formation Fast-R-CNN. L’AlexNet préentraîné est disponible à l’adresse https://www.cntk.ai/Models/AlexNet/AlexNet.model. Stockez le modèle à l’adresse $CNTK_ROOT/PretrainedModels. Pour télécharger les données, exécutez
python install_grocery.py
à partir du Examples/Image/DataSets/Grocery dossier.
Exécuter l’exemple de toy
Dans l’exemple de toy, nous entraînerons un modèle CNTK Fast R-CNN pour détecter les articles d’épicerie dans un réfrigérateur.
Tous les scripts requis sont inclus $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
Guide rapide
Pour exécuter l’exemple de toy, assurez-vous qu’il PARAMETERS.pydataset est défini sur "Grocery".
- Exécutez
A1_GenerateInputROIs.pypour générer les ROIs d’entrée pour l’entraînement et le test. - Exécutez
A2_RunWithBSModel.pypour entraîner et tester à l’aide de cntk.exe et BrainScript. - Exécutez
A3_ParseAndEvaluateOutput.pypour calculer le mAP (précision moyenne moyenne) du modèle entraîné.
La sortie du script A3 doit contenir les éléments suivants :
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
Pour visualiser les zones englobantes et les étiquettes prédites, vous pouvez exécuter B3_VisualizeOutputROIs.py (cliquez sur les images à agrandir) :





Détails de l’étape
A1 : Le script A1_GenerateInputROIs.py génère d’abord des candidats roi pour chaque image à l’aide de la recherche sélective.
Il les stocke ensuite dans un format de texte CNTK comme entrée pour cntk.exe.
En outre, les fichiers d’entrée CNTK requis pour les images et les étiquettes de vérité de base sont générés.
Le script génère les dossiers et fichiers suivants sous le FastRCNN dossier :
proc- Dossier racine pour le contenu généré.grocery_2000- contient tous les dossiers et fichiers générés pour l’exemplegroceryutilisant2000des ROIs. Si vous réexécutez avec un autre nombre de ROIs, le nom du dossier change en conséquence.rois- contient les coordonnées roi brutes pour chaque image stockée dans des fichiers texte.cntkFiles- contient les fichiers d’entrée CNTK mis en forme pour les images (train.txtettest.txt), les coordonnées roi (xx.rois.txt) et les étiquettes roi (xx.roilabels.txt) pourtrainettest. (Les détails du format sont fournis ci-dessous.)
Tous les paramètres sont contenus dans PARAMETERS.py, par exemple, modifiez cntk_nrRois = 2000 le nombre de roIs utilisés pour l’apprentissage et le test. Nous décrivons les paramètres de la section Paramètres ci-dessous.
A2 : Le script A2_RunWithBSModel.py exécute cntk à l’aide de cntk.exe et d’un fichier de configuration BrainScript (détails de la configuration).
Le modèle entraîné est stocké dans le dossier cntkFiles/Output du sous-dossier correspondant proc .
Le modèle entraîné est testé séparément sur le jeu d’entraînement et le jeu de tests.
Pendant le test de chaque image et chaque ROI correspondant, une étiquette est prédite et stockée dans les fichiers test.z et train.z dans le cntkFiles dossier.
A3 : L’étape d’évaluation analyse la sortie CNTK et calcule le mAP en comparant les résultats prédits avec les annotations de vérité de base.
La suppression non maximale est utilisée pour fusionner les roIs qui se chevauchent. Vous pouvez définir le seuil de suppression non maximale dans PARAMETERS.py (détails).
Scripts supplémentaires
Il existe trois scripts facultatifs que vous pouvez exécuter pour visualiser et analyser les données :
B1_VisualizeInputROIs.pyvisualise les roIs d’entrée candidates.B2_EvaluateInputROIs.pycalcule le rappel des roIs de vérité sur le terrain en ce qui concerne les ROIs candidats.B3_VisualizeOutputROIs.pyvisualisez les zones englobantes et les étiquettes prédites.
Exécuter pascal VOC
Les données Pascal VOC (PASCAL Visual Object Classes) sont un ensemble bien connu d’images standardisées pour la reconnaissance de classe d’objets. L’entraînement ou le test de CNTK Fast R-CNN sur les données Pascal VOC nécessite un GPU avec au moins 4 Go de RAM. Vous pouvez également exécuter à l’aide du processeur, ce qui prendra toutefois un certain temps.
Obtention des données VOC Pascal
Vous avez besoin des données 2007 (trainval et test) et 2012 (trainval) ainsi que des RO précomputés utilisés dans le papier d’origine.
Vous devez suivre la structure de dossiers décrite ci-dessous.
Les scripts supposent que les données Pascal résident dans $CNTK_ROOT/Examples/Image/DataSets/Pascal.
Si vous utilisez un autre dossier, définissez-le pascalDataDirPARAMETERS.py de manière correspondante.
- Télécharger et décompresser les données d’apprentissage 2012 vers
DataSets/Pascal/VOCdevkit2012 - Télécharger et décompresser les données d’apprentissage 2007 vers
DataSets/Pascal/VOCdevkit2007 - Télécharger et décompresser les données de test 2007 dans le même dossier
DataSets/Pascal/VOCdevkit2007 - Télécharger et décompresser les ROIs précalculés sur
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
Le VOCdevkit2007 dossier doit ressembler à ceci (similaire pour 2012) :
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Exécution de CNTK sur Pascal VOC
Pour s’exécuter sur les données VOC Pascal, assurez-vous qu’il PARAMETERS.pydataset est défini "pascal"sur .
- Exécutez
A1_GenerateInputROIs.pypour générer les fichiers d’entrée au format CNTK pour l’entraînement et le test à partir des données de retour sur investissement téléchargées. - Exécutez
A2_RunWithBSModel.pypour entraîner un modèle R-CNN rapide et les résultats des tests de calcul. - Exécutez
A3_ParseAndEvaluateOutput.pypour calculer le mAP (moyenne précision moyenne) du modèle entraîné.- Notez qu’il s’agit d’un travail en cours et que les résultats sont préliminaires, car nous formons de nouveaux modèles de base.
- Veillez à disposer de la dernière version de CNTK master pour les fichiers fastRCNN/pascal_voc.py et fastRCNN/voc_eval.py pour éviter les erreurs d’encodage.
Effectuer l’apprentissage sur vos propres données
Préparer un jeu de données personnalisé
Option n° 1 : Outil visual Object Tagging Tool (recommandé)
L’outil Visual Object Tagging Tool (VOTT) est un outil d’annotation multiplateforme pour le balisage des ressources vidéo et d’image.

VOTT fournit les fonctionnalités suivantes :
- Balisage assisté par ordinateur et suivi d’objets dans des vidéos à l’aide de l’algorithme de suivi Camshift.
- Exportation d’étiquettes et de ressources au format CNTK Fast-RCNN pour entraîner un modèle de détection d’objet.
- Exécution et validation d’un modèle de détection d’objet CNTK entraîné sur de nouvelles vidéos pour générer des modèles plus forts.
Comment annoter avec VOTT :
- Télécharger la dernière version
- Suivez le fichier Lisez-moi pour exécuter un travail d’étiquetage
- Après l’étiquetage des balises Exporter vers le répertoire du jeu de données
Option n° 2 : Utilisation de scripts d’annotation
Pour entraîner un modèle CNTK Fast R-CNN sur votre propre jeu de données, nous fournissons deux scripts pour annoter des régions rectangulaires sur des images et affecter des étiquettes à ces régions.
Les scripts stockent les annotations dans le format approprié, selon les besoins de la première étape de l’exécution de Fast R-CNN (A1_GenerateInputROIs.py).
Tout d’abord, stockez vos images dans la structure de dossiers suivante
<your_image_folder>/negative- images utilisées pour l’entraînement qui ne contiennent aucun objet<your_image_folder>/positive- images utilisées pour l’entraînement qui contiennent des objets<your_image_folder>/testImages- images utilisées pour les tests qui contiennent des objets
Pour les images négatives, vous n’avez pas besoin de créer d’annotations. Pour les deux autres dossiers, utilisez les scripts fournis :
- Exécuter
C1_DrawBboxesOnImages.pypour dessiner des zones englobantes sur les images.- Dans le jeu
imgDir = <your_image_folder>de scripts (/positiveou/testImages) avant l’exécution. - Ajoutez des annotations à l’aide du curseur de la souris. Une fois que tous les objets d’une image sont annotés, le fait d’appuyer sur la touche 'n' écrit le fichier .bboxes.txt, puis passe à l’image suivante, 'u' annule (c’est-à-dire supprime) le dernier rectangle et 'q' quitte l’outil d’annotation.
- Dans le jeu
- Exécutez
C2_AssignLabelsToBboxes.pypour affecter des étiquettes aux zones englobantes.- Dans le jeu
imgDir = <your_image_folder>de scripts (/positiveou/testImages) avant l’exécution... - ... et adapter les classes du script pour refléter vos catégories d’objets, par exemple
classes = ("dog", "cat", "octopus"). - Le script charge ces rectangles annotés manuellement pour chaque image, les affiche un par un et demande à l’utilisateur de fournir la classe d’objet en cliquant sur le bouton correspondant à gauche de la fenêtre. Les annotations de vérité de base marquées comme « indécidées » ou « exclure » sont entièrement exclues du traitement ultérieur.
- Dans le jeu
Effectuer l’apprentissage sur un jeu de données personnalisé
Avant d’exécuter CNTK Fast R-CNN à l’aide de scripts A1-A3, vous devez ajouter votre jeu de données à PARAMETERS.py:
- Ensemble
dataset = "CustomDataset" - Ajoutez les paramètres de votre jeu de données sous la classe
CustomDatasetPython. Vous pouvez commencer par copier les paramètres à partir deGroceryParameters- Adaptez les classes pour refléter vos catégories d’objets. En suivant l’exemple ci-dessus, cela ressemblerait
self.classes = ('__background__', 'dog', 'cat', 'octopus')à . - Définissez
self.imgDir = <your_image_folder>. - Si vous le souhaitez, vous pouvez ajuster davantage de paramètres, par exemple pour la génération et la taille du retour sur investissement (voir la section Paramètres ).
- Adaptez les classes pour refléter vos catégories d’objets. En suivant l’exemple ci-dessus, cela ressemblerait
Prêt à s’entraîner sur vos propres données ! (Utilisez les mêmes étapes que pour l’exemple de toy.)
Détails techniques
Paramètres
Les principaux paramètres sont PARAMETERS.py les suivants :
dataset- quel jeu de données utilisercntk_nrRois- nombre de ROIs à utiliser pour l’entraînement et le testnmsThreshold- Seuil de suppression non maximal (dans la plage [0,1]). Plus les ROIs sont inférieurs à ceux qui seront combinés. Il est utilisé à la fois pour l’évaluation et la visualisation.
Tous les paramètres de génération de retour sur investissement, tels que la largeur et la hauteur minimales et maximales, sont décrits dans PARAMETERS.py la classe ParametersPython. Ils sont tous définis sur une valeur par défaut qui est raisonnable.
Vous pouvez les remplacer dans la # project-specific parameters section correspondant au jeu de données que vous utilisez.
Configuration de CNTK
Le fichier de configuration CNTK BrainScript utilisé pour entraîner et tester Fast R-CNN est fastrcnn.cntk.
La partie qui construit le réseau est la BrainScriptNetworkBuilder section de la Train commande :
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
Dans la première ligne, l’AlexNet préentraîné est chargé comme modèle de base. Les deux parties suivantes du réseau sont clonées : convLayers contient les couches convolutionnelles avec des poids constants, c’est-à-dire qu’elles ne sont pas entraînées plus loin.
fcLayers contient les couches entièrement connectées avec les poids préentraînés, qui seront entraînées plus loin.
Les noms network.featuresde nœud, network.conv5_y etc. peuvent être dérivés de l’analyse de la sortie du journal de l’appel cntk.exe (contenu dans la sortie du journal du A2_RunWithBSModel.py script).
La définition de modèle (model (features, rois) = ...) normalise d’abord les caractéristiques en soustrayant 114 pour chaque canal et pixel.
Ensuite, les fonctionnalités normalisées sont poussées par le convLayers suivi par le ROIPooling et enfin le fcLayers.
La forme de sortie (largeur:hauteur) de la couche de regroupement roi est définie (6:6) , car il s’agit de la taille nd de forme attendue par le fcLayers modèle AlexNet. La sortie de l’objet fcLayers est alimentée dans une couche dense qui prédit une valeur par étiquette (NumLabels) pour chaque retour sur investissement.
Les six lignes suivantes définissent l’entrée :
- image de taille 1 000 x 1 000 x 3 (
$ImageH$:$ImageW$:$ImageC$), - étiquettes de vérité de base pour chaque ROI (
$NumLabels$:$NumTrainROIs$) - et quatre coordonnées par ROI (
4:$NumTrainROIs$) correspondant à (x, y, w, h), toutes relatives à la largeur et à la hauteur totale de l’image.
z = model (features, rois) alimente les images d’entrée et les URI d’entrée dans le modèle réseau défini et affecte la sortie à z.
Le critère (CrossEntropyWithSoftmax) et l’erreur (ClassificationError) sont spécifiés pour axis = 1 tenir compte de l’erreur de prédiction par roi.
La section lecteur de la configuration CNTK est répertoriée ci-dessous. Il utilise trois désérialiseurs :
ImageDeserializerpour lire les données d’image. Il récupère les noms des fichiers image à partir detrain.txt, met à l’échelle l’image à la largeur et à la hauteur souhaitées tout en conservant les proportions (remplissage de zones vides avec114) et transpose le tenseur pour avoir la forme d’entrée correcte.- L’une
CNTKTextFormatDeserializerpour lire les coordonnées roi à partir detrain.rois.txt. - Une seconde
CNTKTextFormatDeserializerpour lire les étiquettes roi à partir detrain.roislabels.txt.
Les formats de fichier d’entrée sont décrits dans la section suivante.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
Format du fichier d’entrée CNTK
Il existe trois fichiers d’entrée pour CNTK Fast R-CNN correspondant aux trois désérialiseurs décrits ci-dessus :
train.txtcontient dans chaque ligne d’abord un numéro de séquence, puis un nom de fichier d’image et enfin un0(qui est actuellement nécessaire pour les raisons héritées de l’ImageReader).
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(Format de texte CNTK) contient dans chaque ligne d’abord un numéro de séquence, puis l’identificateur|roissuivi d’une séquence de nombres. Il s’agit de groupes de quatre nombres correspondant à (x, y, w, h) d’un roi, tous relatifs à la largeur et à la hauteur totale de l’image. Il y a un total de 4 * nombres de rois par ligne.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(Format de texte CNTK) contient dans chaque ligne d’abord un numéro de séquence, puis l’identificateur|roiLabelssuivi d’une séquence de nombres. Il s’agit de groupes de nombres d’étiquettes (zéro ou un) par retour sur investissement encodant la classe de vérité de base dans une représentation à chaud. Il existe un nombre total d’étiquettes * nombre de rois par ligne.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Détails de l’algorithme
R-CNN rapide
Les R-CNN pour la détection d’objets ont été présentés en 2014 par Ross Girshick et al., et ont été montrés pour mettre hors service les approches antérieures de l’état de l’art sur l’un des principaux défis de reconnaissance d’objets dans le domaine : Pascal VOC. Depuis lors, deux documents de suivi ont été publiés qui contiennent des améliorations significatives de vitesse : Fast R-CNN et Faster R-CNN.
L’idée de base de R-CNN est de prendre un réseau neuronal profond qui a été initialement entraîné pour la classification des images à l’aide de millions d’images annotées et de le modifier à des fins de détection d’objets. L’idée de base du premier document R-CNN est illustrée dans la figure ci-dessous (extraite du papier) : (1) Étant donné une image d’entrée, (2) dans une première étape, un grand nombre de propositions de région sont générées. (3) Ces propositions de région, ou régions d’intérêts (ROIs), sont ensuite envoyées indépendamment par le biais du réseau qui génère un vecteur de valeurs à virgule flottante 4096 pour chaque roi. Enfin, (4) un classifieur est appris qui prend la représentation 4096 float ROI comme entrée et génère une étiquette et une confiance à chaque ROI.
Bien que cette approche fonctionne bien en termes de précision, il est très coûteux de calculer, car le réseau neuronal doit être évalué pour chaque roi. R-CNN rapide traite cet inconvénient en évaluant uniquement la plupart du réseau (pour être spécifique : les couches de convolution) une seule fois par image. Selon les auteurs, cela entraîne une accélération de 213 fois pendant les tests et une vitesse de 9x pendant l’entraînement sans perte de précision. Cette opération est obtenue à l’aide d’une couche de regroupement de rois qui projette le roi sur la carte des caractéristiques convolutionnelles et effectue un regroupement maximal pour générer la taille de sortie souhaitée attendue par la couche suivante. Dans l’exemple AlexNet utilisé dans ce tutoriel, la couche de regroupement de rois est placée entre la dernière couche convolutionnelle et la première couche entièrement connectée (voir le code BrainScript).
L’implémentation Caffe originale utilisée dans les journaux R-CNN est disponible dans GitHub : RCNN, Fast R-CNN et Faster R-CNN. Ce didacticiel utilise certains du code de ces référentiels, notamment (mais pas exclusivement) pour l’apprentissage et l’évaluation du modèle SVM.
Formation SVM vs NN
Patrick Buehler fournit des instructions sur l’apprentissage d’une SVM sur la sortie CNTK Fast R-CNN (à l’aide des fonctionnalités 4096 de la dernière couche entièrement connectée) ainsi qu’une discussion sur les pros et les inconvénients ici.
Recherche sélective
La recherche sélective est une méthode permettant de trouver un grand ensemble d’emplacements d’objets possibles dans une image, indépendamment de la classe de l’objet réel. Il fonctionne en clustering des pixels d’image en segments, puis en effectuant un clustering hiérarchique pour combiner des segments du même objet en propositions d’objets.



Pour compléter les ROIs détectés à partir de la recherche sélective, nous ajoutons des ROIs qui couvrent l’image à différentes échelles et ratios d’aspect. La première image montre un exemple de sortie de la recherche sélective, où chaque emplacement d’objet possible est visualisé par un rectangle vert. Les ROIs trop petits, trop volumineux, etc. sont ignorés (deuxième image) et enfin les ROIs qui couvrent uniformément l’image sont ajoutées (troisième image). Ces rectangles sont ensuite utilisés en tant que régions d’intérêts (ROIs) dans le pipeline R-CNN.
L’objectif de la génération de roi est de trouver un petit ensemble de ROIs qui couvrent toutefois étroitement autant d’objets dans l’image que possible. Ce calcul doit être suffisamment rapide, tout en recherchant des emplacements d’objet à différentes échelles et ratios d’aspect. La recherche sélective a été montrée pour effectuer bien cette tâche, avec une bonne précision pour accélérer les compromis.
NMS (suppression non maximale)
Les méthodes de détection d’objets génèrent souvent plusieurs détections qui couvrent entièrement ou partiellement le même objet dans une image.
Ces ROIs doivent être fusionnés pour pouvoir compter des objets et obtenir leurs emplacements exacts dans l’image.
Ceci est traditionnellement effectué à l’aide d’une technique appelée Suppression non maximale (NMS). La version de NMS que nous utilisons (et qui a également été utilisée dans les publications R-CNN) ne fusionne pas les ROIs, mais essaie plutôt d’identifier les roIs qui couvrent le mieux les emplacements réels d’un objet et ignore toutes les autres ROIs. Cette opération est implémentée en sélectionnant de manière itérative le roi avec plus de confiance et en supprimant tous les autres ROIs qui chevauchent considérablement ce ROI et sont classés comme étant de la même classe. Le seuil de chevauchement peut être défini dans PARAMETERS.py (détails).
Résultats de détection avant (première image) et après (deuxième image) Suppression non maximale :

mAP (moyenne précision moyenne)
Une fois entraîné, la qualité du modèle peut être mesurée à l’aide de différents critères, tels que la précision, le rappel, la précision, la zone sous-courbe, etc. Une métrique commune utilisée pour le défi de reconnaissance d’objet VOC Pascal consiste à mesurer la précision moyenne (AP) pour chaque classe. La description suivante de la précision moyenne est extraite d’Everingham et. al. La précision moyenne moyenne (mAP) est calculée en prenant la moyenne sur les adresses IP de toutes les classes.
Pour une tâche et une classe donnée, la courbe de précision/rappel est calculée à partir de la sortie classée d’une méthode. Le rappel est défini comme la proportion de tous les exemples positifs classés au-dessus d’un classement donné. Précision est la proportion de tous les exemples au-dessus de ce classement qui proviennent de la classe positive. L’AP récapitule la forme de la courbe de précision/rappel, et est définie comme précision moyenne à un ensemble de onze niveaux de rappel également espacés [0,0,1, . . . ,1]:

La précision à chaque niveau de rappel r est interpolée en prenant la précision maximale mesurée pour une méthode pour laquelle le rappel correspondant dépasse r :
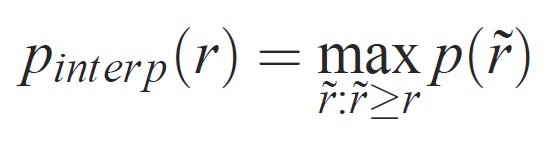
où p( ̃r) est la précision mesurée au rappel ̃r. L’intention d’interpoler la courbe de précision/de rappel de cette façon consiste à réduire l’impact des « wiggles » dans la courbe de précision/rappel, causée par de petites variations dans le classement des exemples. Il faut noter que pour obtenir un score élevé, une méthode doit avoir une précision à tous les niveaux de rappel : cela pénalise les méthodes qui récupèrent uniquement un sous-ensemble d’exemples avec une précision élevée (par exemple, vues latérales des voitures).