Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
Les clusters Big Data Microsoft SQL Server 2019 sont mis hors service. La prise en charge des clusters Big Data SQL Server 2019 a pris fin le 28 février 2025. Pour plus d’informations, consultez le billet de blog d’annonce et les options Big Data sur la plateforme Microsoft SQL Server.
Découvrez comment utiliser Spark &Hive Tools pour Visual Studio Code pour créer et envoyer des scripts PySpark pour Apache Spark, tout d’abord, nous allons décrire comment installer les outils Spark &Hive dans Visual Studio Code, puis nous allons découvrir comment envoyer des travaux à Spark.
Spark &Hive Tools peut être installé sur des plateformes prises en charge par Visual Studio Code, notamment Windows, Linux et macOS. Vous trouverez ci-dessous les conditions préalables pour différentes plateformes.
Prerequisites
Les éléments suivants sont requis pour effectuer les étapes décrites dans cet article :
- Un cluster SQL Server Big Data. Consultez SQL Server Big Data Clusters.
- Visual Studio Code.
- Python et l’extension Python sur Visual Studio Code.
- Mono. Mono n’est nécessaire que pour Linux et macOS.
- Configurez l’environnement interactif PySpark pour Visual Studio Code.
- Répertoire local nommé SQLBDCexample. Cet article utilise C :\SQLBDC\SQLBDCexample.
Installer l’extension Spark & Hive Tools
Une fois les prérequis terminés, vous pouvez installer Spark &Hive Tools pour Visual Studio Code. Effectuez les étapes suivantes pour installer Spark &Hive Tools :
Ouvrez Visual Studio Code.
Dans la barre de menus, accédez à Afficher>Extensions.
Dans la zone de recherche, entrez Spark & Hive.
Sélectionnez Spark &Hive Tools, publié par Microsoft, dans les résultats de la recherche, puis sélectionnez Installer.

Rechargez le cas échéant.
Ouvrir le dossier de travail
Effectuez les étapes suivantes pour ouvrir un dossier de travail et créer un fichier dans Visual Studio Code :
Dans la barre de menus, accédez à Fichier>Ouvrir le dossier...>C:\SQLBDC\SQLBDCexample, puis sélectionnez le bouton Sélectionner le dossier. Le dossier s’affiche dans l’affichage Explorateur sur la gauche.
Dans l’affichage Explorateur , sélectionnez le dossier , SQLBDCexample, puis l’icône Nouveau fichier en regard du dossier de travail.

Nommez le nouveau fichier avec l'extension de fichier script Spark
.py. Cet exemple utilise HelloWorld.py.Copiez le code suivant et collez-le dans le fichier de script :
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Connecter un cluster de Big Data SQL Server
Avant de pouvoir envoyer des scripts à vos clusters à partir de Visual Studio Code, vous devez lier un cluster Big Data SQL Server.
Dans la barre de menus, accédez à Afficher> lapalette de commandes..., puis entrez Spark /Hive : Lier un cluster.

Sélectionnez le type de cluster lié SQL Server Big Data.
Entrez le point de terminaison Big Data SQL Server.
Entrez le nom d’utilisateur du cluster Big Data SQL Server.
Entrez le mot de passe de l’administrateur utilisateur.
Définissez le nom d'affichage du cluster big data (facultatif).
Répertorier les clusters, consulter la vue OUTPUT pour la vérification.
List clusters
Dans la barre de menus, accédez à Afficher> lapalette de commandes..., puis entrez Spark/Hive : Répertorier le cluster.
Examinez l’affichage OUTPUT (SORTIE). La vue affiche votre ou vos clusters liés.

Définir le cluster par défaut
Re-Open le dossier SQLBDCexample créé précédemment s’il est fermé.
Sélectionnez le fichier HelloWorld.py créé précédemment et s’ouvre dans l’éditeur de script.
Liez un cluster si vous ne l’avez pas encore fait.
Cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez Spark /Hive : définir le cluster par défaut.
Sélectionnez un cluster comme cluster par défaut pour le fichier de script actuel. Les outils mettent automatiquement à jour le fichier de configuration . VSCode\settings.jsactivé.

Envoyer des requêtes PySpark interactives
Vous pouvez envoyer des requêtes PySpark interactives en suivant les étapes ci-dessous :
Rouvrez le dossier SQLBDCexample créé précédemment si fermé.
Sélectionnez le fichier HelloWorld.py créé précédemment et s’ouvre dans l’éditeur de script.
Liez un cluster si vous ne l’avez pas encore fait.
Choisissez tout le code et cliquez avec le bouton droit sur l’éditeur de script, sélectionnez Spark : PySpark Interactive pour envoyer la requête, ou utilisez le raccourci Ctrl + Alt + I.

Sélectionnez le cluster si vous n’avez pas spécifié de cluster par défaut. Après quelques instants, les résultats interactifs Python s’affichent sous un nouvel onglet. Les outils vous permettent également d’envoyer un bloc de code au lieu du fichier de script entier à l’aide du menu contextuel.
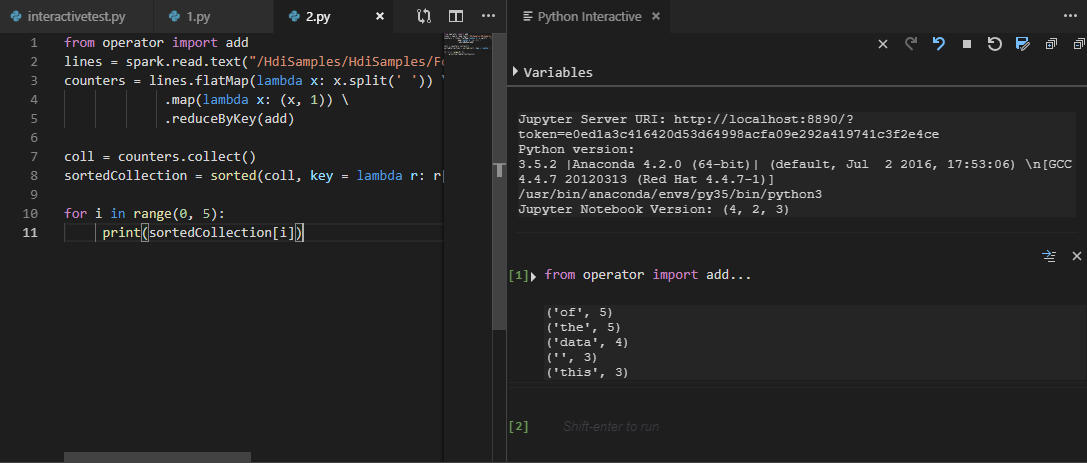
Entrez «%%info», puis appuyez sur Maj + Entrée pour afficher les informations de travail. (Optional)

Note
Lorsque l’extension Python activée est désactivée dans les paramètres (le paramètre par défaut est activé), les résultats d’interaction pyspark soumis utilisent l’ancienne fenêtre.

Envoyer le travail de traitement par lots PySpark
Rouvrez le dossier SQLBDCexample créé précédemment si fermé.
Sélectionnez le fichier HelloWorld.py créé précédemment et s’ouvre dans l’éditeur de script.
Liez un cluster si vous ne l’avez pas encore fait.
Cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez Spark : Lot PySpark, ou utilisez le raccourci Ctrl + Alt + H.
Sélectionnez le cluster si vous n’avez pas spécifié de cluster par défaut. Une fois que vous avez envoyé un travail Python, les journaux d’envoi s’affichent dans la fenêtre OUTPUT (SORTIE) de Visual Studio Code. L’URL de l’interface utilisateur Spark et l’URL de l’interface utilisateur Yarn sont également affichées. Vous pouvez ouvrir l’URL dans un navigateur web pour suivre l’état du travail.

Configuration d’Apache Livy
La configuration d’Apache Livy est prise en charge, elle peut être définie à l’adresse . VSCode\settings.jsactivé dans le dossier espace de travail. Actuellement, la configuration Livy prend uniquement en charge le script Python. Pour plus d’informations, consultez Livy README.
Guide pratique pour déclencher la configuration Livy
Method 1
- Dans la barre de menus, accédez à Fichier>Préférences>Paramètres.
- Dans la zone de texte Paramètres de recherche, entrez Soumission de tâches HDInsight : Livy Conf.
- Sélectionnez Modifier dans settings.json pour le résultat de recherche approprié.
Method 2
Envoyez un fichier, notez que le .vscode dossier est ajouté automatiquement au dossier de travail. Vous trouverez la configuration Livy en sélectionnant settings.json sous .vscode.
Paramètres du projet :

Note
Pour les paramètres driverMemory et executorMemory, définissez la valeur avec une unité, par exemple 1 Go ou 1024 Mo.
Configurations Livy prises en charge
POST /batches
Request body
| name | description | type |
|---|---|---|
| file | Fichier contenant l’application à exécuter | path (required) |
| proxyUser | Utilisateur dont l’identité doit être empruntée lors de l’exécution du travail | string |
| className | Classe principale Java/Spark de l’application | string |
| args | Arguments de ligne de commande pour l’application | Liste de chaînes |
| jars | jars à utiliser dans cette session | Liste de chaînes |
| pyFiles | Fichiers Python à utiliser dans cette session | Liste de chaînes |
| files | fichiers à utiliser dans cette session | Liste de chaînes |
| driverMemory | Quantité de mémoire à utiliser pour le processus de pilote | string |
| driverCores | Nombre de cœurs à utiliser pour le processus de pilote | int |
| executorMemory | Quantité de mémoire à utiliser par processus d’exécuteur | string |
| executorCores | Nombre de cœurs à utiliser pour chaque exécuteur | int |
| numExecutors | Nombre d’exécuteurs à lancer pour cette session | int |
| archives | Archives à utiliser dans cette session | Liste de chaînes |
| queue | Nom de la file d’attente YARN à laquelle l’envoi | string |
| name | Nom de cette session | string |
| conf | Propriétés de configuration Spark | Mappage clé=valeur |
| :- | :- | :- |
Response Body
Objet batch créé.
| name | description | type |
|---|---|---|
| id | ID de session | int |
| appId | ID d’application de cette session | String |
| appInfo | Informations détaillées sur l’application | Mappage clé=valeur |
| log | Lignes du fichier journal | Liste de chaînes |
| state | État du lot | string |
| :- | :- | :- |
Note
La configuration Livy affectée s’affiche dans le volet de sortie lors de l’envoi du script.
Additional features
Spark &Hive pour Visual Studio Code prend en charge les fonctionnalités suivantes :
IntelliSense autocomplete. Les suggestions s’affichent pour les mots clés, les méthodes, les variables, etc. Différentes icônes représentent différents types d’objets.

Marqueur d’erreur IntelliSense. Le service de langage souligne les erreurs de modification du script Hive.
Syntax highlights. Le service de langage utilise différentes couleurs pour différencier les variables, les mots clés, le type de données, les fonctions, etc.
Mises en surbrillance de la syntaxe Spark & Hive Tools pour Visual Studio Code
Unlink cluster
Dans la barre de menus, accédez à Afficher> lapalette de commandes..., puis entrez Spark /Hive : dissocier un cluster.
Sélectionnez le cluster pour dissocier.
Examinez l’affichage OUTPUT (SORTIE).
Next steps
Pour plus d’informations sur le cluster Big Data SQL Server et les scénarios connexes, consultez clusters Big Data SQL Server.