Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Pour que votre modèle de données soit stocké dans une base de données, il doit être converti dans un format que la base de données peut comprendre. Différentes bases de données nécessitent différents schémas et formats de stockage. Certains ont un schéma strict qui doit être respecté, tandis que d’autres autorisent le schéma à être défini par l’utilisateur.
Les connecteurs de stockage de vecteurs fournis par le Noyau Sémantique ont des mappeurs intégrés qui associeront votre modèle de données entre votre modèle de données et les schémas de base de données. Consultez la page pour chaque connecteur pour plus d’informations sur la façon dont les mappeurs intégrés mappent les données de chaque base de données.
Pour que votre modèle de données soit défini comme une classe ou comme une définition à stocker dans une base de données, il doit être sérialisé dans un format que la base de données peut comprendre.
Il existe deux façons de procéder, soit à l’aide de la sérialisation intégrée fournie par le Semantic Kernel, soit en fournissant votre propre logique de sérialisation.
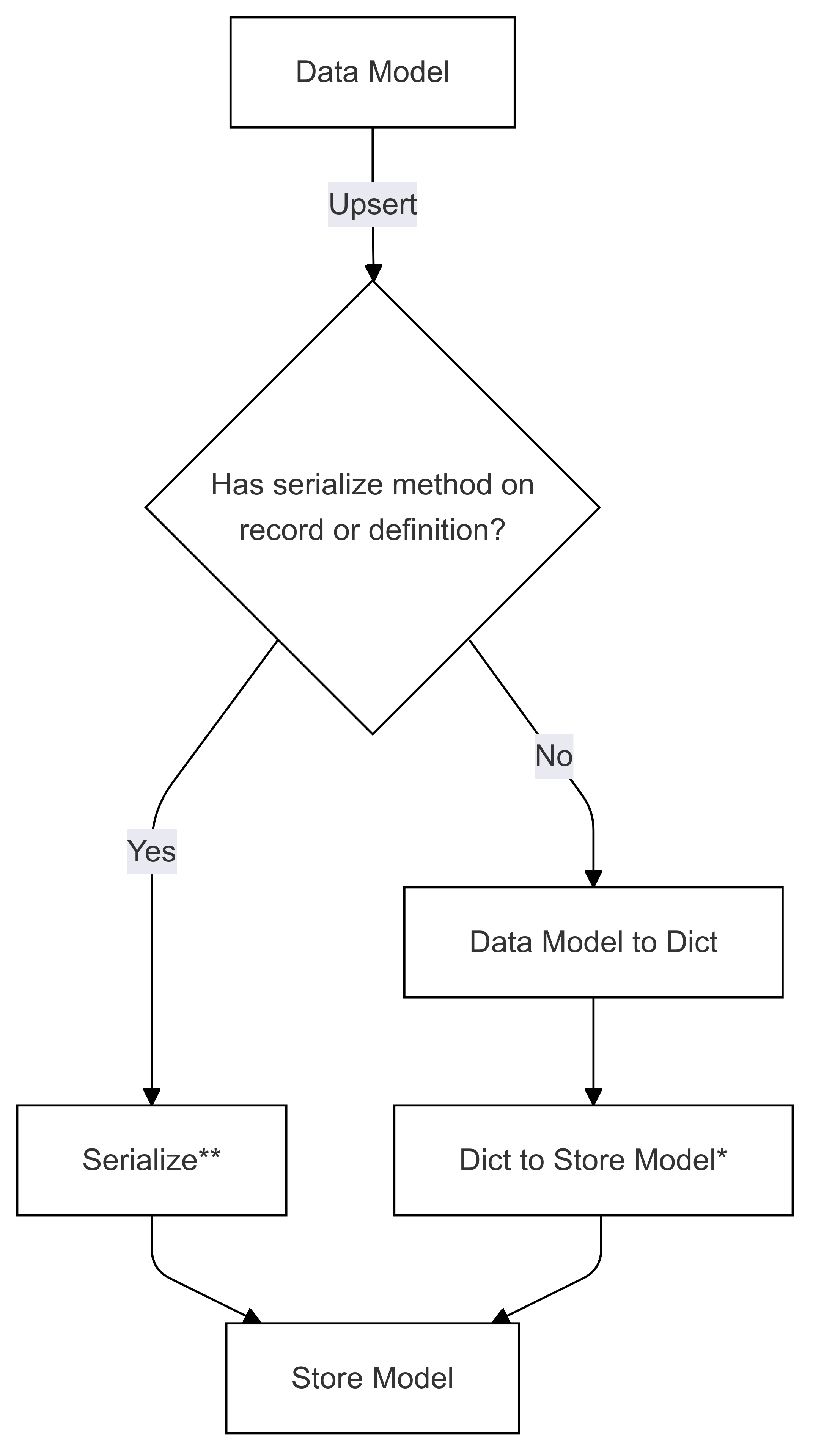
Les deux diagrammes suivants montrent les flux pour la sérialisation et la désérialisation des modèles de données vers et depuis un modèle de magasin.
Flux de sérialisation (utilisé dans Upsert)
Flux de désérialisation (utilisé dans Get and Search)
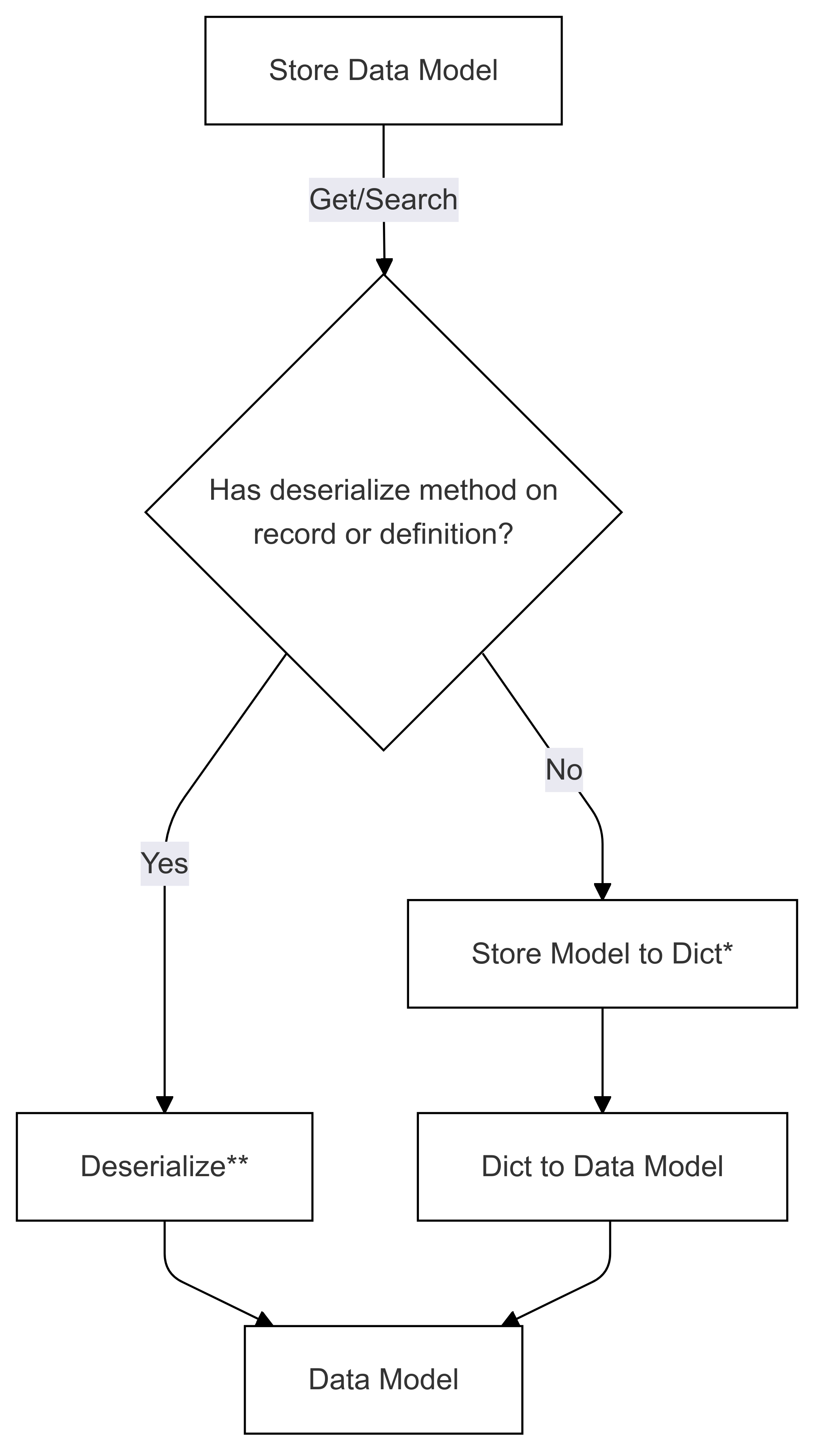
Les étapes marquées avec * (dans les deux diagrammes) sont implémentées par le développeur d’un connecteur spécifique et sont différentes pour chaque magasin. Les étapes marquées avec ** (dans les deux diagrammes) sont fournies sous la forme d’une méthode sur un enregistrement ou dans le cadre de la définition d’enregistrement, celle-ci est toujours fournie par l’utilisateur, consultez de sérialisation directe pour plus d’informations.
Approches de (dé)sérialisation
Sérialisation directe (modèle de données pour stocker le modèle)
La sérialisation directe est la meilleure façon de garantir un contrôle total sur la façon dont vos modèles sont sérialisés et pour optimiser les performances. L’inconvénient est qu’il est spécifique à un magasin de données, et par conséquent, lors de l’utilisation de ce paramètre, il n’est pas aussi facile de basculer entre différents magasins avec le même modèle de données.
Vous pouvez l’utiliser en implémentant une méthode qui suit le protocole SerializeMethodProtocol dans votre modèle de données ou en ajoutant des fonctions qui suivent les SerializeFunctionProtocol à votre définition d’enregistrement, les deux sont disponibles dans semantic_kernel/data/vector_store_model_protocols.py.
Lorsque l’une de ces fonctions est présente, elle est utilisée pour sérialiser directement le modèle de données vers le modèle de magasin.
Vous pouvez même n'implémenter qu'un des deux et utiliser la (dé)sérialisation intégrée dans l'autre sens, cela peut par exemple être utile pour gérer une collection créée en dehors de votre contrôle, c'est-à-dire quand vous devez faire des personnalisations à la façon dont elle est désérialisée, et qu'un upsert n'est pas possible de toute façon.
(Dé)sérialisation intégrée (du modèle de données vers dict et de dict vers le modèle de magasin, et inversement)
La sérialisation intégrée est effectuée en convertissant d’abord le modèle de données en dictionnaire, puis en sérialisant le modèle que le magasin comprend, pour chaque magasin différent défini dans le cadre du connecteur intégré. La désérialisation est effectuée dans l’ordre inverse.
Étape 1 de sérialisation : Modèle de données en Dict
Selon le type de modèle de données dont vous disposez, les étapes sont effectuées de différentes manières. Il existe quatre façons de sérialiser le modèle de données dans un dictionnaire :
- Méthode
to_dictsur la définition (s’aligne sur l’attribut to_dict du modèle de données, en suivantToDictFunctionProtocol) - vérifier si l’enregistrement est un
ToDictMethodProtocolet utiliser la méthodeto_dict - vérifiez si l’enregistrement est un modèle Pydantic et utilisez la
model_dumpdu modèle, consultez la note ci-dessous pour plus d’informations. - parcourir les champs de la définition et créer le dictionnaire
Facultatif : Intégration
Lorsque vous disposez d’un modèle de données avec un embedding_generator champ ou que la collection possède un embedding_generator champ, l’incorporation est générée et ajoutée au dictionnaire avant d’être sérialisée dans le modèle de magasin.
Étape 2 de sérialisation : Dict to Store Model
Une méthode doit être fournie par le connecteur pour convertir le dictionnaire en modèle de magasin. Cela est réalisé par le développeur du connecteur et varie selon chaque magasin.
Désérialisation, étape 1 : Stocker le modèle sur Dict
Une méthode doit être fournie par le connecteur pour convertir le modèle de magasin en dictionnaire. Cela est réalisé par le développeur du connecteur et varie selon chaque magasin.
Désérialisation, étape 2 : de dict vers le modèle de données
La désérialisation est effectuée dans l’ordre inverse, elle tente ces options :
- Méthode
from_dictsur la définition (s’aligne sur l’attribut from_dict du modèle de données, en suivantFromDictFunctionProtocol) - vérifier si l’enregistrement est un
FromDictMethodProtocolet utiliser la méthodefrom_dict - vérifiez si l’enregistrement est un modèle Pydantic et utilisez la
model_validatedu modèle, consultez la note ci-dessous pour plus d’informations. - boucle dans les champs de la définition et définit les valeurs, puis ce dict est transmis au constructeur du modèle de données en tant qu’arguments nommés (sauf si le modèle de données est un dict lui-même, dans ce cas il est retourné tel quel)
Remarque
Utilisation de Pydantic avec sérialisation intégrée
Lorsque vous définissez votre modèle à l’aide d’un BaseModel Pydantic, il utilise les méthodes model_dump et model_validate pour sérialiser et désérialiser le modèle de données vers et à partir d’un dict. Pour ce faire, utilisez la méthode model_dump sans paramètres, si vous souhaitez contrôler cela, envisagez d’implémenter l'ToDictMethodProtocol sur votre modèle de données, car cela est essayé en premier.
Bientôt disponible
Plus d’informations prochainement.