Comment utiliser GitHub Actions pour créer des workflow pour l’intégration continue ?
Rappelez-vous que votre objectif est d’automatiser le processus de génération et de publication du code afin que les fonctionnalités soient mises à jour chaque fois qu’un développeur ajoute une modification à la base de code.
Pour implémenter ce processus, vous allez apprendre à :
- Créez un flux de travail à partir d’un modèle.
- Évitez la duplication à l’aide de flux de travail réutilisables.
- Effectuez des tests sur plusieurs cibles.
- Séparez les travaux de génération et de test.
Créer un workflow à partir d’un modèle
Pour créer un flux de travail, il est courant de commencer à utiliser un modèle. Un modèle comporte des tâches et des étapes courantes préconfigurées pour le type spécifique d’automatisation que vous implémentez. Si vous n’êtes pas familiarisé avec les flux de travail, les travaux et les étapes, consultez le module Automatiser les tâches de développement à l’aide du module GitHub Actions .
Dans la page principale de votre dépôt GitHub, sélectionnez Actions, puis Nouveau flux de travail.
Dans la page Choisir un flux de travail , vous pouvez choisir parmi de nombreux types de modèles. L’un des exemples est le modèle Node.js. Le modèleNode.js installe Node.js et toutes les dépendances, génère le code source et exécute des tests pour différentes versions de Node.js. Un autre exemple est le modèle de package Python , qui installe Python et ses dépendances, puis exécute des tests, y compris lint, dans plusieurs versions de Python.
Pour commencer par le modèle de flux de travail Node.js, dans la zone de recherche, entrez Node.js.
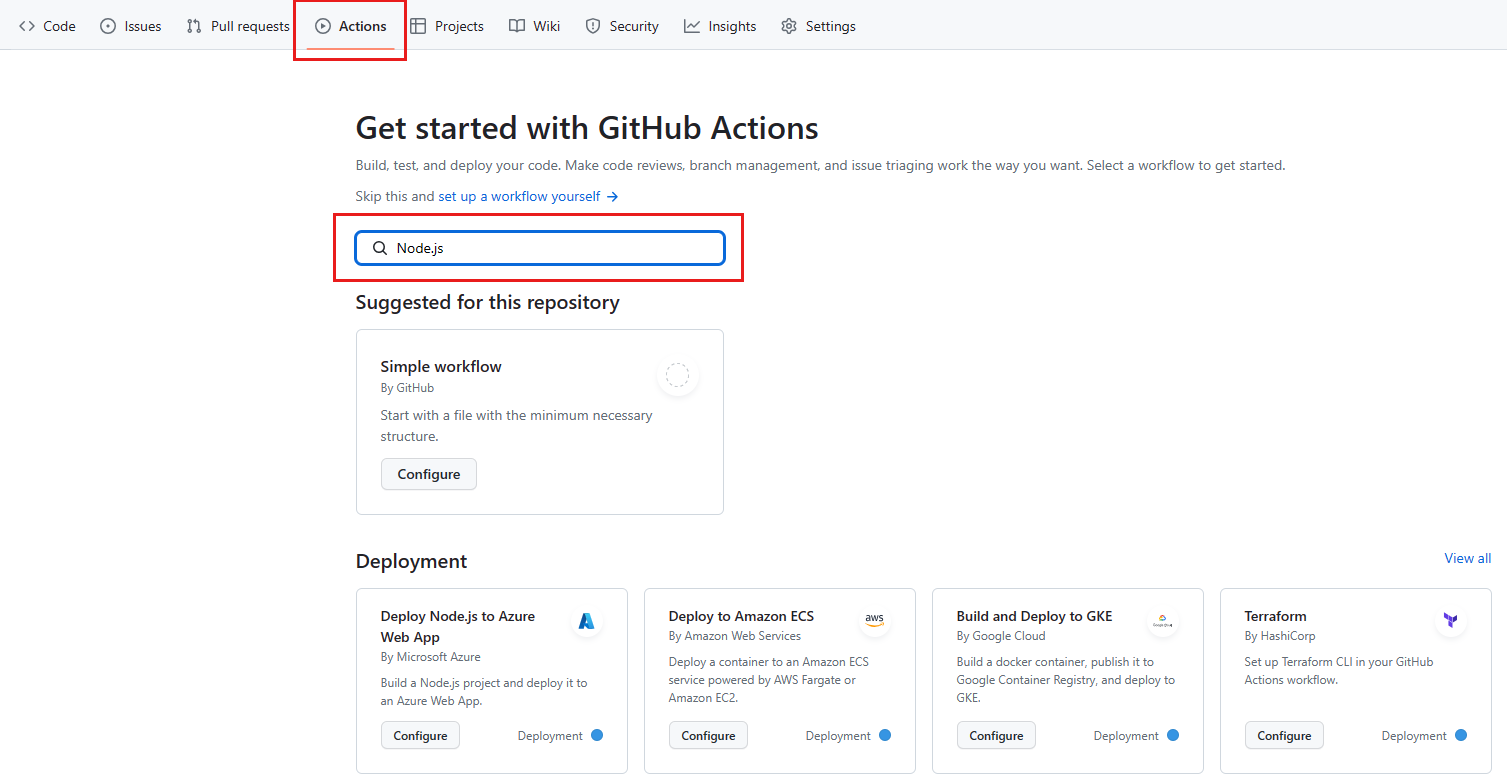
Dans les résultats de la recherche, dans le volet Node.js , sélectionnez Configurer.
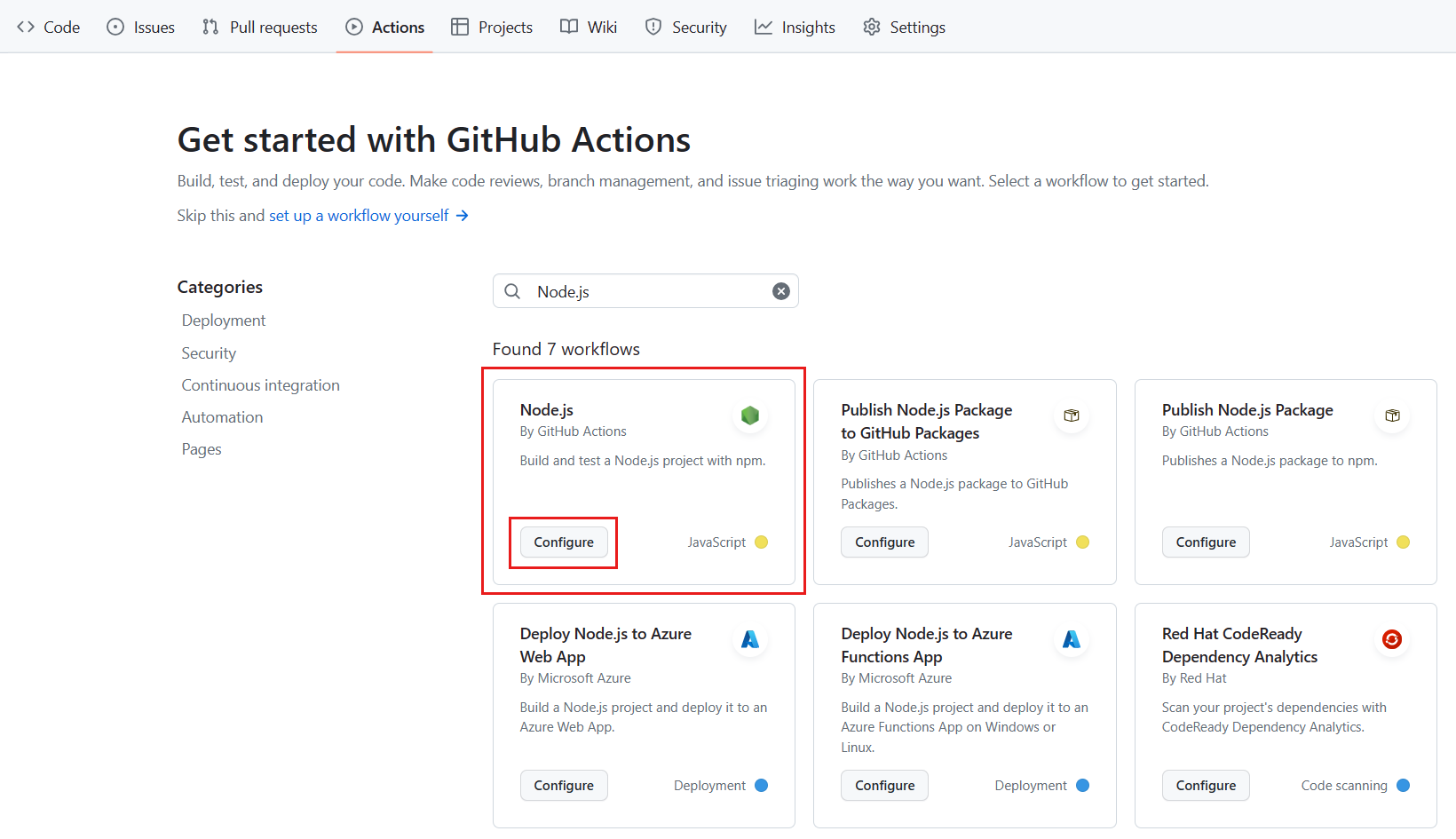
Un node.js.yml fichier pour votre projet est créé à partir du modèle :
name: Node.js CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x, 16.x, 18.x]
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
- run: npm ci
- run: npm run build --if-present
- run: npm test
Comme indiqué dans l’attribut on , cet exemple de flux de travail s’exécute en réponse à un envoi (push) au référentiel ou lorsqu’une demande de tirage (pull request) est créée sur la branche principale.
Ce flux de travail exécute un travail, indiqué par l’attribut job .
L’attribut runs-on spécifie que, pour le système d’exploitation, le workflow s’exécute sur ubuntu-latest. L’attribut node-version spécifie qu’il existe trois builds, une pour Node.js version 14.x, 16.x et 18.x. L’attribut matrix est décrit en profondeur plus loin dans le module.
Dans l’attribut jobs , les étapes utilisent l’action Actions GitHub/checkout@v3 pour obtenir le code de votre dépôt dans une machine virtuelle et des actions/setup-node@v3 pour configurer la version correcte de Node.js. Vous spécifiez que vous souhaitez tester trois versions de Node.js à l’aide de l’attribut ${{ matrix.node-version }} . Cet attribut fait référence à la matrice que vous avez définie précédemment. L’attribut cache spécifie un gestionnaire de package pour la mise en cache dans le répertoire par défaut.
La dernière partie de cette étape exécute des commandes qu'utilisent les projets Node.js. La npm ci commande installe les dépendances à partir du package-lock.json fichier. npm run build --if-present exécute un script de génération s’il existe. npm test exécute l’infrastructure de test. Ce modèle inclut à la fois les étapes de génération et de test dans le même travail.
Pour en savoir plus sur npm, consultez la documentation npm :
Une équipe de développeurs peut tirer parti de l’utilisation de flux de travail réutilisables pour simplifier et normaliser les étapes d’automatisation répétées. En utilisant des flux de travail réutilisables, vous pouvez réduire la redondance, améliorer la facilité de maintenance et garantir la cohérence entre vos pipelines d’intégration continue/de déploiement continu (CI/CD).
Éviter la duplication à l’aide de flux de travail réutilisables
À mesure que les équipes évoluent et que les projets augmentent, il est courant de voir les mêmes étapes répétées sur plusieurs fichiers de flux de travail. Ces étapes peuvent inclure l’extraction du code, l’installation des dépendances, le test et le déploiement. Ce type de duplication n’encombre pas seulement votre base de code, mais augmente également le temps de maintenance lorsque des modifications de code sont requises. Les flux de travail réutilisables résolvent ce problème en vous permettant de définir une logique d’automatisation une seule fois, puis d’appeler la logique à partir d’autres flux de travail.
Les flux de travail réutilisables sont des flux de travail GitHub Actions spéciaux que d’autres flux de travail peuvent appeler, similaires aux fonctions de programmation. Vous les créez pour partager une logique répétée comme les étapes de génération, les procédures de test ou les stratégies de déploiement. Après avoir créé un flux de travail réutilisable, vous pouvez le référencer à partir de n’importe quel autre flux de travail dans le même référentiel ou même dans différents référentiels.
Pourquoi utiliser des workflows réutilisables ?
Voici les avantages de l’utilisation de flux de travail réutilisables :
- Cohérence. Teams peut suivre les mêmes normes d’automatisation dans tous les projets.
- Efficacité. Au lieu de copier et coller des étapes, vous pointez simplement vers un flux de travail réutilisable.
- Mises à jour plus faciles. Lorsqu’un processus change, par exemple en ajoutant une étape de test, vous la mettez à jour à un emplacement. Ensuite, tous les flux de travail qui bénéficient du flux de travail sont automatiquement mis en œuvre.
- Scalabilité. Les flux de travail réutilisables sont idéaux pour les équipes de plateforme ou DevOps qui gèrent plusieurs services.
Découvrez ensuite comment utiliser des flux de travail réutilisables pour améliorer vos projets.
Implémenter des flux de travail réutilisables
Pour utiliser des flux de travail réutilisables :
- Dans votre dossier de référentiel, créez un flux de travail réutilisable. Le fichier inclut les étapes d’automatisation que vous souhaitez partager, comme les étapes courantes impliquées dans les tests, la génération et le déploiement.
- Permettre explicitement à un flux de travail d’être réutilisable en le configurant avec l’événement
workflow_call. - Dans vos workflows principaux (workflows appelants), référencez ce fichier réutilisable et fournissez les entrées ou secrets requis.
Pour illustrer les avantages des flux de travail réutilisables, envisagez le scénario réel suivant.
Exemple :
Imaginez que votre organisation a 10 microservices. Toutes les 10 microservices ont besoin des mêmes étapes pour :
- Exécuter des tests
- Code lint
- Déployer dans un environnement spécifique
Sans flux de travail réutilisables, chaque dépôt finit par dupliquer la même logique sur plusieurs fichiers de flux de travail, ce qui entraîne des étapes répétées et une maintenance plus difficile.
Si vous utilisez des flux de travail réutilisables :
- Vous définissez le processus une fois dans un fichier central (par exemple, dans
ci-standard.yml). - Vous appelez ce fichier à partir de chaque flux de travail de microservice, en passant des variables telles que l’environnement ou le nom de l’application.
Si une nouvelle étape de sécurité ou un nouvel outil est ajouté, par exemple pour rechercher des vulnérabilités, vous ne l’ajoutez qu’une seule fois dans le flux de travail réutilisable. Toutes les 10 microservices commencent immédiatement à utiliser le processus mis à jour. Vous n’avez pas besoin de modifier les 10 microservices.
En comprenant comment les flux de travail réutilisables fonctionnent et leurs avantages, vous pouvez adopter les meilleures pratiques pour optimiser leur efficacité et garantir une intégration transparente avec vos pipelines CI/CD.
Meilleures pratiques
- Centralisez vos flux de travail réutilisables dans un dépôt si vous envisagez de les partager entre les équipes.
- Utilisez des branches ou des balises pour versionner vos flux de travail (par exemple, utilisez
@v1), afin de pouvoir facilement restaurer les modifications si nécessaire. - Documentez clairement les entrées et secrets. Les flux de travail réutilisables s’appuient souvent sur les entrées et les secrets. Les équipes doivent savoir quelles informations utiliser.
- Si vous devez réutiliser seulement quelques étapes, combinez des flux de travail réutilisables avec des actions composites au lieu de créer un flux de travail complet.
Les flux de travail réutilisables sont un moyen puissant d’appliquer la cohérence, de réduire la duplication et de mettre à l’échelle les pratiques DevOps dans n’importe quelle équipe d’ingénierie. Que vous gériez un référentiel unique, des microservices ou des bibliothèques open source, des flux de travail réutilisables peuvent simplifier l’automatisation, afin que votre CI/CD soit plus rapide, plus propre et plus facile à gérer.
Personnaliser des modèles de flux de travail
Au début de ce module, vous avez considéré un scénario dans lequel vous devez configurer CI pour votre équipe de développeurs. Le modèle Node.js est un excellent début, mais vous souhaitez le personnaliser pour mieux répondre aux exigences de votre équipe. Vous souhaitez cibler différentes versions de Node.js et différents systèmes d’exploitation. Vous souhaitez également que les étapes de génération et de test soient des travaux distincts.
Voici un exemple de flux de travail personnalisé :
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16.x, 18.x]
Dans cet exemple, vous configurez une matrice de build pour le test sur plusieurs systèmes d’exploitation et versions de langage. Cette matrice produit quatre builds, une pour chaque système d’exploitation jumelée à chaque version de Node.js.
Quatre builds et leurs tests produisent une grande quantité de données de journal. Il peut être difficile de trier tout cela. Dans l’exemple suivant, vous déplacez l’étape de test vers un travail de test dédié. Ce travail exécute les tests sur plusieurs cibles. La séparation des étapes de compilation et de test facilite l’utilisation des données du journal des logs.
test:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16.x, 18.x]
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
- name: npm install, and test
run: |
npm install
npm test
env:
CI: true