Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans la phase précédente de ce didacticiel, nous avons installé PyTorch sur votre ordinateur. À présent, nous allons l’utiliser pour configurer notre code avec les données que nous allons utiliser pour créer notre modèle.
Ouvrez un nouveau projet dans Visual Studio.
- Ouvrez Visual Studio et choisissez
create a new project.

- Dans la barre de recherche, tapez
Pythonet sélectionnezPython Applicationcomme modèle de projet.
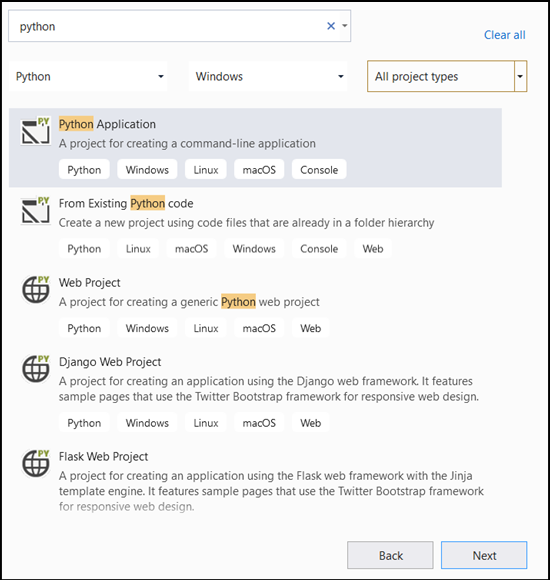
- Dans la fenêtre de configuration :
- Nommez votre projet. Ici, nous l’appelons DataClassifier.
- Choisissez l’emplacement du projet.
- Si vous utilisez VS 2019, vérifiez que la case
Create directory for solutionest cochée. - Si vous utilisez VS2017, vérifiez qu’il
Place solution and project in the same directoryest désactivé.
Appuyez sur create pour créer votre projet.
Créer un interpréteur Python
Maintenant, vous devez définir un nouvel interpréteur Python. Cela doit inclure le package PyTorch que vous avez récemment installé.
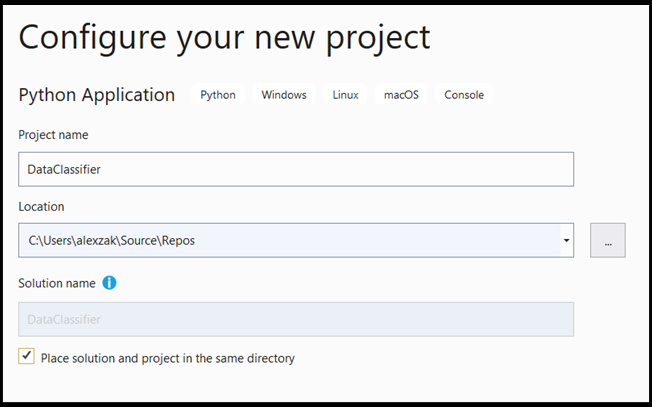
- Accédez à sélection de l’interpréteur, puis sélectionnez
Add Environment:

- Dans la fenêtre
Add Environment, sélectionnezExisting environment, puis choisissezAnaconda3 (3.6, 64-bit). Cela inclut le package PyTorch.
Pour tester le nouvel interpréteur Python et le nouveau package PyTorch, entrez le code suivant dans le fichier DataClassifier.py :
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
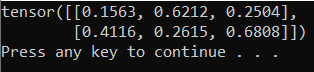
La sortie doit être un tenseur 5x3 aléatoire semblable à celle ci-dessous.
Remarque
Vous voulez en savoir plus ? Visitez le site officiel pyTorch.
Vue d’ensemble des données
Nous allons entraîner le modèle sur le jeu de données de fleurs appelé « Iris de Fisher ». Ce jeu de données célèbre comprend 50 enregistrements pour chacune des trois espèces Iris : Iris setosa, Iris virginica et Iris versicolor.
Plusieurs versions du jeu de données ont été publiées. Vous pouvez trouver le jeu de données Iris dans le référentiel UCI Machine Learning, importer le jeu de données directement à partir de la bibliothèque Python Scikit-learn ou utiliser n’importe quelle autre version précédemment publiée. Pour en savoir plus sur l’ensemble de données de fleurs Iris, visitez sa page Wikipédia.
Dans ce tutoriel, pour montrer comment entraîner le modèle avec le type d’entrée tabulaire, vous allez utiliser le jeu de données Iris exporté vers le fichier Excel.
Chaque ligne du tableau Excel affiche quatre caractéristiques d’Iris : longueur sépale en cm, largeur sépale en cm, longueur pétale en cm et largeur pétale en cm. Ces fonctionnalités serviront d’entrée. La dernière colonne inclut le type Iris lié à ces paramètres et représente la sortie de régression. Au total, le jeu de données comprend 150 entrées de quatre fonctionnalités, chacune correspondant au type Iris approprié.
L’analyse de régression examine la relation entre les variables d’entrée et le résultat. En fonction de l’entrée, le modèle apprend à prédire le type de sortie correct : l’un des trois types Iris-setosa, Iris-versicolor, Iris-virginica.
Important
Si vous décidez d’utiliser un autre jeu de données pour créer votre propre modèle, vous devez spécifier vos variables d’entrée et sortie de modèle en fonction de votre scénario.
Chargez le jeu de données.
Téléchargez le jeu de données Iris au format Excel. Vous pouvez le trouver ici.
Dans le
DataClassifier.pyfichier du dossier Fichiers de l’Explorateur de solutions, ajoutez l’instruction d’importation suivante pour accéder à tous les packages dont nous aurons besoin.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Comme vous pouvez le voir, vous allez utiliser le package pandas (analyse des données Python) pour charger et manipuler des données et un package torch.nn qui contient des modules et des classes extensibles pour la création de réseaux neuronaux.
- Chargez les données en mémoire et vérifiez le nombre de classes. En principe, vous devez voir 50 éléments de chaque type d’iris. Veillez à spécifier l’emplacement du jeu de données sur votre PC.
Ajoutez le code suivant au fichier DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Lorsque nous exécutons ce code, la sortie attendue est la suivante :

Pour pouvoir utiliser le jeu de données et entraîner le modèle, nous devons définir l’entrée et la sortie. L’entrée comprend 150 lignes de caractéristiques et la sortie est la colonne de type Iris. Le réseau neuronal que nous allons utiliser nécessite des variables numériques. Vous allez donc convertir la variable de sortie en format numérique.
- Créez une colonne dans le jeu de données qui représente la sortie dans un format numérique et définissez une entrée et une sortie de régression.
Ajoutez le code suivant au fichier DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Lorsque nous exécutons ce code, la sortie attendue est la suivante :

Pour entraîner le modèle, nous devons convertir l’entrée et la sortie du modèle au format Tensor :
- Convertir en Tensor :
Ajoutez le code suivant au fichier DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Si nous exécutons le code, la sortie attendue affiche le format d’entrée et de sortie, comme suit :

Il existe 150 valeurs d’entrée. Environ 60 % de ces valeurs constituent les données d’entraînement du modèle. Vous conservez 20% pour la validation et 30% pour un test.
Dans ce tutoriel, la taille de lot d’un jeu de données d’apprentissage est définie sur 10. Il y a 95 éléments dans le jeu d’entraînement, ce qui signifie qu’en moyenne, il y a 9 lots complets disponibles par itération (une seule époque) sur le jeu d’entraînement. Vous conservez la taille du lot des jeux de validation et de test sous la forme 1.
- Divisez les données en ensembles d'entraînement, de validation et de test.
Ajoutez le code suivant au fichier DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Étapes suivantes
Avec les données prêtes à être utilisées, il est temps d’entraîner notre modèle PyTorch